Command Palette
Search for a command to run...
湖南大学/中国科学院大学/ByteDanceは、タンパク質の生成/折り畳み/逆折り畳みをサポートし、全原子設計と機能最適化を実現するAPMモデルを提案した。
生命活動の主たる実行者として、タンパク質はしばしば多重鎖複合体の形でその機能を発揮します。抗体-抗原認識から酵素-基質結合まで、多重鎖タンパク質間の精密な相互作用は、生命のメカニズムを理解する上で核心です。しかしながら、現在のAI駆動型タンパク質モデリング分野には、顕著な「単鎖偏重」が見られます。AlphaFoldやESMシリーズなどのモデルは、単鎖タンパク質のフォールディングと設計において画期的な進歩を遂げていますが、多鎖複合体のモデリングはまだ初期段階にあります。
多重鎖タンパク質を処理する既存の方法では、一般的に「疑似配列接続」戦略が採用されており、多重鎖を強制的に単一鎖として扱っています。この手法は、鎖間相互作用の自然な表現を著しく制限します。実際の生物学的複合体においては、鎖間の空間位置と結合界面(水素結合や疎水性相互作用など)との間の原子レベルの相互作用を、線形接続では正確にモデル化することができません。さらに、全原子構造の生成には二重の課題が伴います。アミノ酸側鎖の複雑なコンフォメーションと、配列と構造の強い依存性により、多鎖複合体のde novo設計は、この分野において困難な問題となっています。
この研究のギャップを埋めるために、湖南大学、中国科学院大学、ByteDance Seedチームは、多重鎖タンパク質複合体向けに特別に設計された全原子タンパク質生成モデルであるAPM(全原子タンパク質生成モデル)を提案しました。 APM は、全原子構造を持つ多重鎖複合体を直接生成できるだけでなく、折り畳みや逆折り畳みなどの基本的なタスクもサポートし、抗体やペプチドなどの機能性タンパク質の設計において優れたパフォーマンスを発揮します。
この研究成果は、「タンパク質複合体の設計のための全原子生成モデル」というタイトルで ICML 2025 に選出されました。
研究のハイライト:
* マルチチェーンネイティブモデリング:疑似シーケンス接続を放棄し、マルチチェーンの独立した空間分布と結合インターフェース間の原子レベルの相互作用を直接学習します。
* 全原子表現の最適化: 計算効率と構造詳細のバランスを取り、アミノ酸の種類、バックボーンフレームワーク、側鎖のねじれ角の共同表現を通じて原子レベルの構造生成を実現します。
* シーケンス構造依存性強化: ノイズプロセスと双方向タスクトレーニング (フォールディング/アンフォールディング) を切り離すことで、シーケンスと構造間の深い関連性を維持します。

用紙のアドレス:
公式アカウントをフォローし、「APM」と返信すると完全なPDFが手に入ります。APM タンパク質生成データセット:
AIフロンティアに関するその他の論文:
データセット: 単一チェーンから複数チェーンまでの豊富なサンプル
APM は、単鎖タンパク質と多重鎖タンパク質の構造と配列情報を統合した、慎重に構築されたマルチソース タンパク質データセットに基づいてトレーニングされ、モデルに豊富な学習教材を提供します。
シングルチェーンデータセットは、マルチソース融合と品質フィルタリングを通じて、インチェーンモデリングのための豊富な基盤を提供します。合計187,494サンプルが含まれており、幅広いタンパク質タイプと機能カテゴリーをカバーしています。データは主に3つの権威あるデータベースから取得されています。
* PDB データベース: MultiFlow データ処理プロセスの後、18,684 個のサンプルがスクリーニングされました。
* Swiss-Prot データベース: pLDDT>85 の高品質構造を選択し、140,769 サンプルを取得しました。
* AFDB データベース: より厳格なスクリーニング基準を使用して、pLDDT > 95 のサンプルが保持され、合計 28,041 サンプルになりました。
マルチチェーンタンパク質データセットには合計11,620サンプルが含まれており、2~6鎖のタンパク質複合体をカバーし、マルチチェーンモデリングの重要なデータサポートを提供します。マルチチェーンタンパク質データは、PDB生物学的アセンブリデータ(Biological Assemblies)から取得されています。下流タスクにおける情報漏洩を防ぐため、研究チームは3種類のサンプルを除外しました。SAbDab抗体データベースに存在するサンプル、長さが30未満の鎖(ペプチドとみなされる)を含むサンプル、長さが2,048を超えるかクラスターIDがないサンプルです。
モデルの一般化能力を向上させるために、研究者らはトレーニング プロセス中にマルチチェーン サンプルをランダムにトリミングしました。384 を超える残基を持つサンプルについては、チェーン間の結合インターフェースにある残基のペアを中心に、最も近い 384 個のアミノ酸が保持されました。このプルーニング戦略により、メモリ オーバーフローの問題を回避しながら、モデルがキー バインディング領域に集中できるようになります。さらに、研究者らはシングルチェーンデータとマルチチェーンデータを適切な割合で混合し、シングルチェーンデータの豊富さを活用してチェーン内モデリング能力を向上させました。各サンプリング場所には、地理的位置(チェーン間相互作用部位)、構造特性(二次構造の種類など)、配列特性(アミノ酸の種類や保存性など)を含む豊富なメタデータが付与されています。これらの情報は、モデルが配列、構造、機能のマッピング関係を学習するための多次元的な手がかりとなります。
APM タンパク質生成データセット:
モデルアーキテクチャ:3つのモジュールによる共同全原子生成フレームワーク
APM のコア アーキテクチャは、シーケンスおよびバックボーン生成モジュール (Seq&BB モジュール)、サイドチェーン生成モジュール (Sidechain モジュール)、およびリファイン モジュールという明確な機能を持つ 3 つのモジュールで構成されています。革新的な設計により、多重鎖タンパク質のさまざまな設計タスクをサポートしながら、配列から全原子構造までのエンドツーエンドの生成が実現されます。
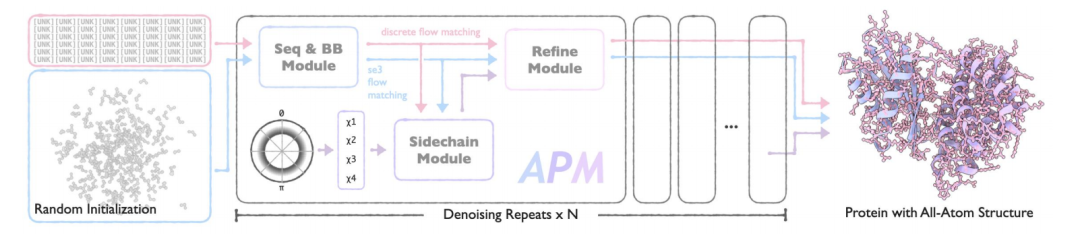
Seq&BBモジュール
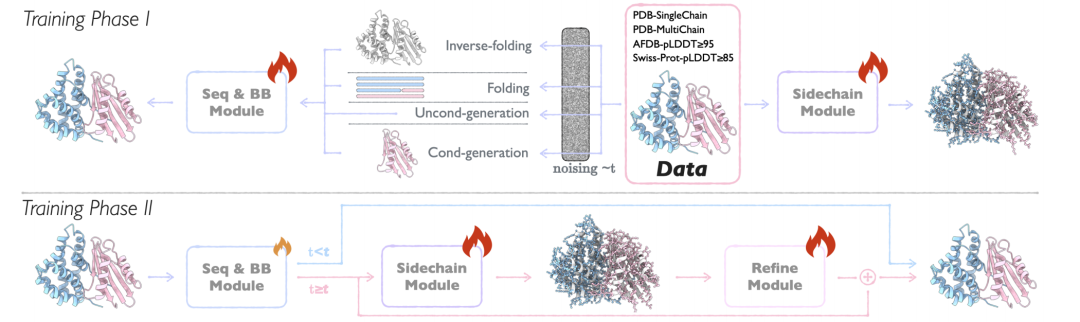
このモジュールはAPMの基盤です。フローマッチング法を採用することで、配列とタンパク質バックボーンの共同生成を実現し、残基レベルでの配列構造協調モデリングタスクを処理できます。配列と構造のノイズプロセスを分離することで、配列と構造の依存関係へのダメージを軽減し、フォールディング/リバースフォールディングタスクを50%の確率で実行することで、双方向の依存関係学習を強化します。このモジュールの核となる革新性は以下のとおりです。
* デカップリングノイズプロセス:シーケンスノイズと構造ノイズのプロセスを分離することで、従来の手法におけるインターモーダル依存性の破壊を回避できます。ノイズシーケンスとノイズバックボーンは異なる時間ステップで独立してサンプリングされるため、モデルは双方向のシーケンス-構造依存性を学習できます。
* SE(3)フローマッチング:タンパク質骨格の空間変換特性を考慮して、並進と回転の部分を別々に処理するために、3次元特殊ユークリッド群(SE(3))フローマッチングを導入した。
* マルチタスク学習:また、無条件生成、条件付き生成、フォールディングおよび逆フォールディングタスクをサポートし、混合タスクトレーニングを通じてモデルの汎化能力を向上させます。損失関数には、フローマッチング損失と一貫性損失が含まれており、生成された軌跡の滑らかさを保証します。

サイドチェーンモジュール
全原子構造生成を実現するために、Sidechain モジュールは、Seq&BB によって生成された配列とバックボーンに基づいてアミノ酸側鎖のコンフォメーションを予測します。

このモジュールでは次の戦略を採用しています。
* ねじれ角とは、側鎖構造は側鎖のねじれ角(最大 4 つの回転可能な結合)によってパラメータ化され、計算効率と原子レベルの詳細のバランスが取られ、すべての原子座標を直接モデリングする複雑さが回避されます。
* 2段階のトレーニング:最初の段階では、側鎖パッキングタスクに焦点を当て、実際の側鎖の立体配座の分布を学習します。2 番目の段階では、予測された構造から実際の側鎖を再構築し、生成シナリオでのモデルの適用性を確保します。
* 軽量設計:Seq&BB モジュールと比較すると、Sidechain モジュールでは、使用する構造ブロックが少なく、非表示のディメンションが小さくなります。
モジュールの改良
APM の最後のリンクとして、Refine モジュールは Seq&BB と Sidechain モジュールの出力を統合し、損失を修正してシーケンスとバックボーンを最適化し、原子の競合を減らして構造の合理性を向上させます。フルアトム情報は、配列と主鎖構造を最適化し、構造上の矛盾を解決し、生成された結果を天然タンパク質に近づけるために使用されます。このモジュールは、入力品質が最適化をサポートするのに十分であることを保証するために、生成後期(t≥0.8)でのみアクティブ化されます。

実験的結論: APMの画期的な性能の多次元検証
APM の実験検証は、シングルチェーンの基本タスク、マルチチェーンのコアタスク、下流の機能設計をカバーしており、結果はすべて優れています。
単鎖タンパク質タスク:プロフェッショナルモデルに匹敵する基本機能
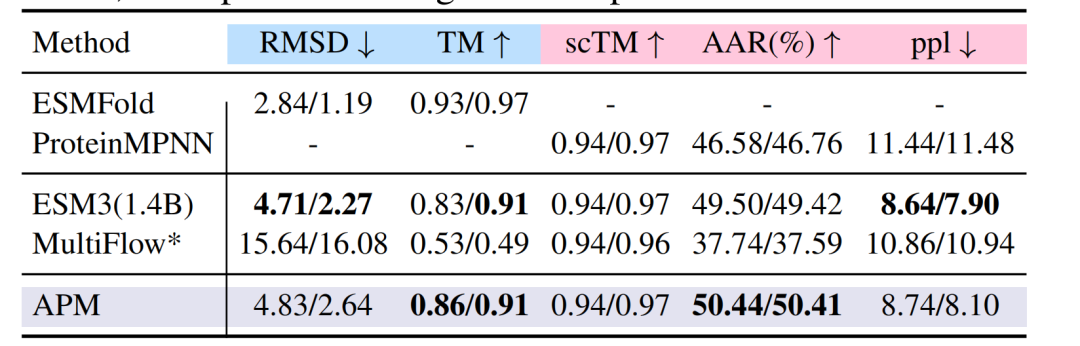
折り畳みタスクでは、PDBデータセット上で、APMのRMSDは4.83/2.64です。TMスコアは0.86/0.91に達し、ESM3、MultiFlowなどのモデルのパフォーマンスに匹敵します。逆折り畳みタスクでは、アミノ酸回収率(AAR)が50.44%に達し、ProteinMPNNの46.58%を上回りました。
さらに、下の図に示すように、100~300残基の長さを持つ無条件に生成されたタンパク質では、APM の scTM は 0.96 (長さ 100) と高く、scRMSD は 1.80 と低くなります。ESM3 (1.4B) や ProtPardelle などの全原子設計モデルよりも大幅に優れています。
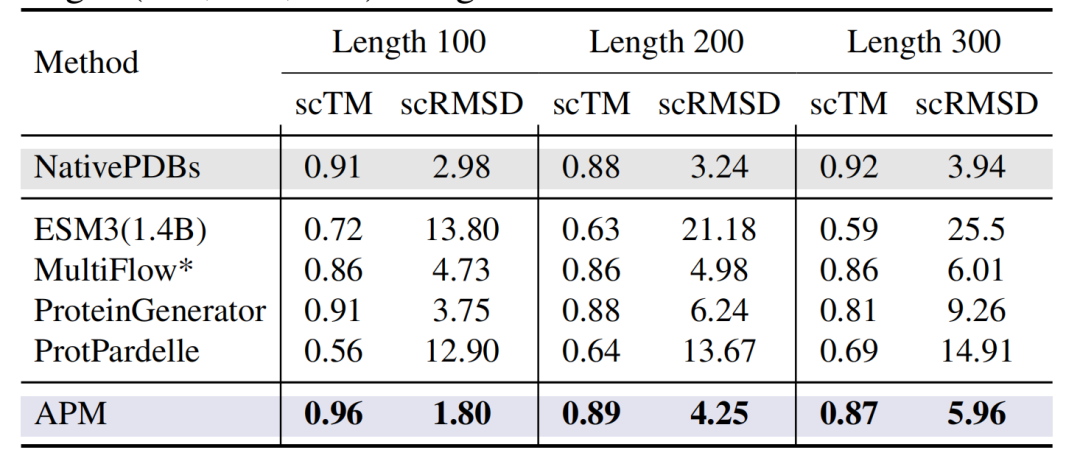
マルチチェーンタンパク質タスク:ネイティブモデリングの核となる利点
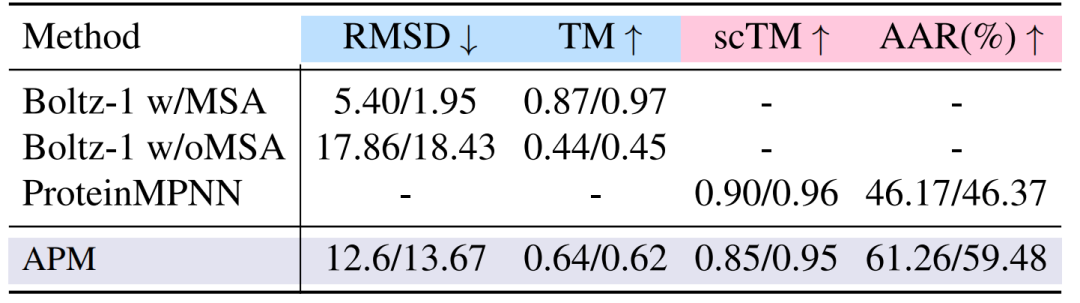
折り畳みと展開の実験では、2-6鎖複合体において、APMのフォールディング性能は12.6/13.67で、Boltz-1より低いものの、MSAを含まないBoltz-1を大きく上回っています。逆フォールディングscTMは0.85/0.95に達し、MSAを含むBoltz-1に近づき、配列と構造の関連性の妥当性を証明しています。実験結果は下の図に示されています。
第二に、多重鎖複合体は強い結合親和性を持っています。鎖長 50-100 を例にとると、全原子緩和後の結合エネルギー ΔG_RAA は -112.65/-116.98 に達し、これは主鎖のみを使用した Chroma (-83.96/-86.66) および APM_BB (-114.94/-114.45) よりも大幅に優れており、鎖間相互作用をモデル化するには全原子情報が必要であることが証明されています。
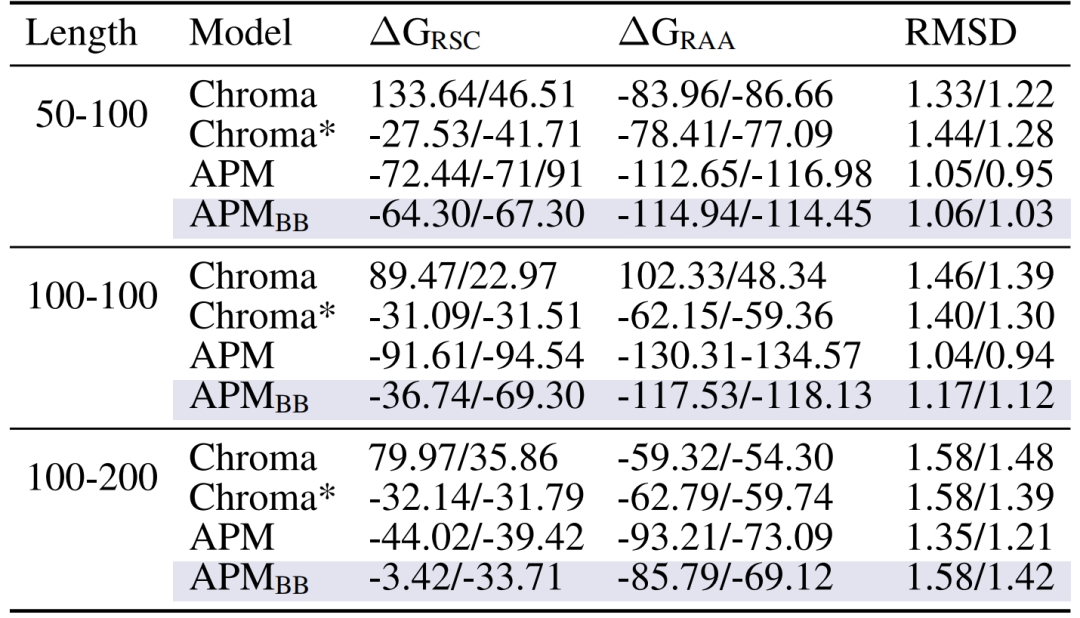
生成された複合体間の鎖間結合親和性
下流機能設計:抗体とペプチドの応用におけるブレークスルー
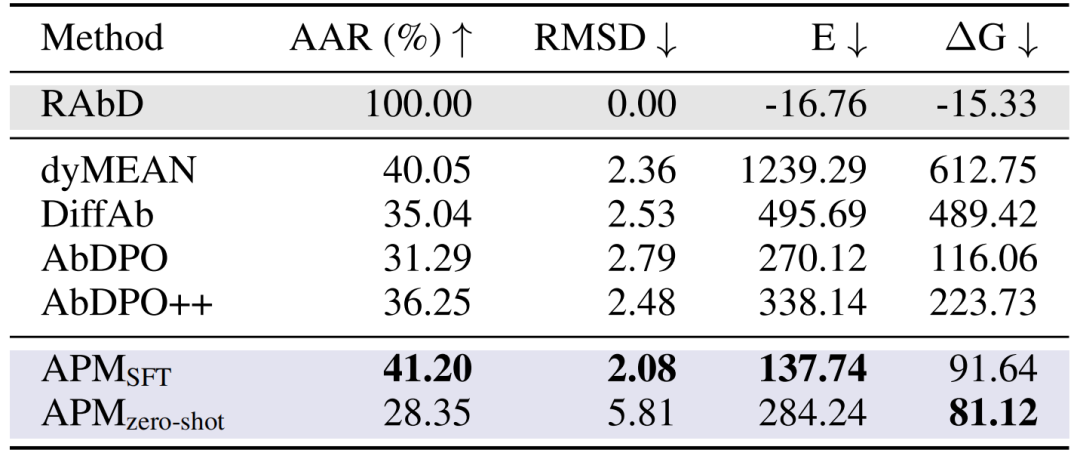
抗体CDR-H3設計:RAbDベンチマークテストにおいて、APMのAARは41.20%、RMSDは2.08、結合エネルギーΔGは91.64に達し、dyMEANやDiffAbなどの手法を上回りました。ゼロサンプルで生成された抗体の配列は天然のものと大きく異なりますが、結合エネルギーはより優れており(ΔG 81.12)、その普遍的な結合能力を証明しています。
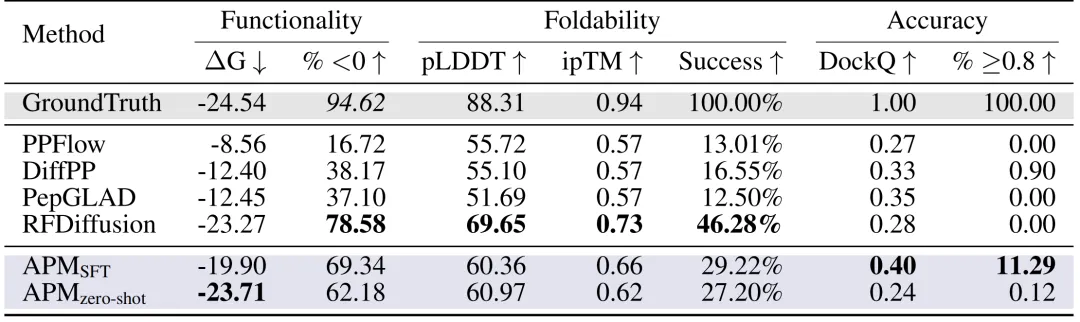
ペプチド設計:PepBenchとLNRデータセットにおいて、研究者らは機能性、折り畳み性、精度という3つの主要な側面からペプチド設計手法を総合的に評価しました。下図に示すように、APM (SFT) の結合エネルギーΔGは-19.90に達し、ΔG < 0のサンプル数は69.34%に達しました。また、DockQ ≥ 0.8の割合は11.29%に達し、PPFlow、PepGLADなどの他の手法をはるかに上回りました。また、折り畳み安定性(pLDDT 60.36、ipTM 0.66)も良好でした。
産業界と研究開発機関の連携により、全原子タンパク質生成技術のブレークスルーが推進される
全原子タンパク質生成という生物学の最先端分野では、学界や産業界が探求を止めたことはなく、一連の画期的な成果が注目を集め続けています。
学術界では、DeepMind チームが立ち上げた AlphaFold3 が、マルチスケールの構造情報と進化配列データを統合することで、全原子タンパク質生成の分野で強力な能力を発揮しました。複雑なタンパク質の折り畳みパターンの正確なモデリングを実現し、特に、補因子と金属イオンを含む全原子複合体の生成において、従来の手法と比較して構造精度とエネルギー合理性が大幅に向上しました。スタンフォード大学の研究チームが開発したESM-IF1は、異なるアプローチを採用しています。膨大な進化配列データで学習した暗黙的なフォールディングモデルに基づき、自然なコンフォメーション特性を持つ全原子タンパク質構造を直接生成することができ、酵素活性中心の精密構築において卓越した性能を発揮します。
産業界もこの分野に積極的に進出し、技術革新によって産業応用を促進しています。北京バイオジオメトリーバイオテクノロジー株式会社は、世界初のフルシナリオの原子レベルタンパク質モデル「GeoFlow V2」をリリースしました。これは、タンパク質原子の精密な制御を可能にするエンドツーエンドの拡散生成フレームワークを構築しました。抗体CDR領域の全原子設計において、親和性と安定性を同時に最適化できるため、医薬品開発の効率が大幅に向上します。アメリカのバイオテクノロジー企業であるInsilico Medicineは、医薬品標的タンパク質の設計に重点を置いたタンパク質生成システムを開発しました。このシステムは、多重制約生成戦略を採用しており、全原子構造の合理性を確保しながら、タンパク質と低分子医薬品の結合部位を方向性を持って最適化することができ、候補薬剤の効率的なスクリーニングのための強固な基盤を提供します。
学術界におけるこれらの理論的ブレークスルーとビジネス界における応用革新は、我々は協力して、全原子タンパク質生成技術を研究室から産業実践へと推進し、精密医薬品開発、新しい生体触媒の設計、合成生物学における飛躍的進歩の中核的なサポートを提供し、将来的には疾患治療とバイオ製造に大きな価値を生み出すことを期待しています。
参考リンク:
1.https://mp.weixin.qq.com/s/a0bl9ek90t_-y8wy69Yu6Q
2.https://mp.weixin.qq.com/s/P-5o-R1qZY52Pq1yK5j6cQ








