Command Palette
Search for a command to run...
最先端のドキュメント解析プラットフォームが登場!MinerUの新バージョンは、2段階の「粗から細へ」解析戦略を革新。S2Sドメインベンチマークも登場!Tencentの最新ベンチマークデータセットで音声モデルの性能を評価。

デジタル化の波の中で、あらゆる分野で、主に PDF 形式の学術論文、レポート、フォームなどの非構造化文書データが大量に蓄積されてきました。これらのドキュメントを機械が読み取り可能な構造化データに効率的かつ正確に変換することは、自動情報抽出、ドキュメント管理、インテリジェント分析を実現するための重要な前提条件であり、データの価値を引き出すための重要なステップでもあります。
OCRの需要が継続的に増加していることから、OpenDataLabと上海AIラボが共同でビジュアル言語モデルMinerU2.5-2509-1.2Bをリリースしました。PDF などの複雑な形式のドキュメントを構造化された機械可読データ (Markdown、JSON など) に変換することに重点を置いており、高精度かつ高効率のドキュメント解析タスク向けに設計されています。新しいバージョンのモデルでは、「粗いものから細かいものへ」という 2 段階の戦略を通じて効率的な解析を実現します。最初の段階では、効率的なレイアウト分析を使用して構造要素を識別し、ドキュメントのフレームワークの概要を示します。2 番目の段階では、切り取られた領域内で元の解像度で詳細な認識を実行し、テキスト、数式、表などの詳細が復元されるようにします。
MinerU2.5-2509-1.2B は、グローバル レイアウト分析とローカル コンテンツ認識を分離し、強力なドキュメント解析機能を発揮します。複数の認識タスクにおいて、一般フィールド モデルや垂直フィールド モデルよりも優れたパフォーマンスを発揮します。同時に、計算オーバーヘッドにおいても大きな利点を示しています。技術的に優れたモデルであるだけでなく、技術効率を効果的に向上させるツールであり、データ分析、情報検索、コーパス構築といった下流のユーザーニーズを強力にサポートします。
HyperAI公式サイトにて「MinerU2.5-2509-1.2B: ドキュメント解析デモ」を公開しました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/emEKs
10月13日から10月17日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 10
* 高品質なチュートリアルセレクション: 11
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 10月に締め切りを迎えるトップカンファレンス:1
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. FDAbench-Full異種データ分析ベンチマークデータセット
FDAbench-Full は、南洋理工大学、シンガポール国立大学、Huawei Technologies Co., Ltd. によってリリースされた、データ エージェント向けの初の異種データ分析タスク ベンチマークです。データベース クエリ生成、SQL 理解、財務データ分析におけるモデルの機能を評価することを目的としています。
直接使用します:https://go.hyper.ai/AUjv5
2. PubMedVision医療マルチモーダル評価データセット
PubMedVisionは、様々な医用画像モダリティと解剖学的領域を網羅した、医療マルチモーダル機能を評価するためのデータセットです。医療分野における視覚情報とテキスト理解タスクにおけるマルチモーダル大規模言語モデル(MLLM)の視覚的知識の融合と推論能力をテストするための標準化されたテストリソースを提供することを目的としています。
直接使用します:https://go.hyper.ai/qdvVe
3. Verse-Benchオーディオビジュアル共同生成評価データセット
Verse-Benchは、StepFunが香港科技大学、香港科技大学(広州)などの研究機関と共同で公開した、音声と動画の共同生成を評価するためのベンチマークデータセットです。生成モデルが動画を生成するだけでなく、音声コンテンツ(環境音や音声を含む)との時間的整合性を厳密に維持することを可能にすることを目的としています。
直接使用します:https://go.hyper.ai/mvau0

4. MMMC教育ビデオ生成ベンチマークデータセット
MMMCは、シンガポール国立大学のShow Labが公開した、教育用ビデオ生成のための大規模で学際的な教育用ビデオ生成ベンチマークデータセットです。教育用人工知能モデルのための高品質なトレーニングおよび評価リソースを提供し、構造化コードと教育コンテンツからプロフェッショナルな教育用ビデオを自動生成する研究を支援することを目的としています。
直接使用します:https://go.hyper.ai/AELav
5. T2I-CoReBenchマルチモーダル画像生成ベンチマークデータセット
T2I-CoReBenchは、中国科学技術大学、快手科技のKlingチーム、そして香港大学によって提案された、テキスト駆動型画像生成モデルの包括的な評価ベンチマークです。画像生成モデルの組み合わせ能力と推論能力を同時に測定することを目的としています。
直接使用します:https://go.hyper.ai/SLyED
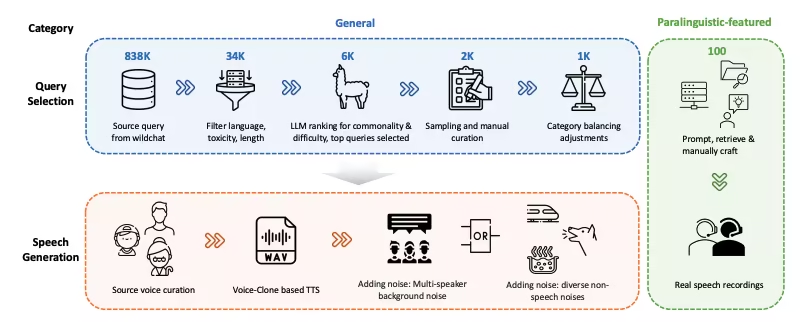
6. WildSpeech-Bench音声理解・生成ベンチマークデータセット
WildSpeech-Benchは、TencentがSpeechLLMの音声合成機能を評価するためにリリースした初のベンチマークです。このベンチマークは、実際の音声インタラクションシナリオにおいて、SpeechLLMが音声入力から音声出力(S2S)までの完全な理解と生成能力を測定することを目的としています。
直接使用します:https://go.hyper.ai/Cy63e
7. OmniRetarget グローバルロボットモーションリマッピングデータセット
OmniRetargetは、AmazonがMIT、カリフォルニア大学バークレー校、その他の機関と共同で公開した、ヒューマノイドロボットの全身モーションリマッピングのための高品質な軌跡データセットです。このデータセットには、G1ヒューマノイドロボットが物体や複雑な地形と相互作用する際の軌跡が含まれており、ロボットによる物体の運搬、地形上の歩行、物体と地形の混合相互作用という3つのシナリオをカバーしています。
直接使用します:https://go.hyper.ai/xfZY4

8. Paper2Video 論文ビデオベンチマークデータ
Paper2Videoは、シンガポール国立大学が公開した論文と動画のペアからなる初のベンチマークデータセットです。学術論文からプレゼンテーション動画(スライド、字幕、音声、講演者ポートレートを含む)を自動生成するタスクのための標準的なベンチマークと評価リソースを提供することを目的としています。
直接使用します:https://go.hyper.ai/NeRuV
9. FoMERベンチマルチモーダル評価データセット
FoMER ベンチは、3 つの異なるロボット タイプと複数のロボット モードをカバーする Foundational Model Embodied Reasoning (FoMER) ベンチマークであり、複雑な具体化された意思決定シナリオにおける LMM の推論能力を評価するように設計されています。
直接使用します:https://go.hyper.ai/Tiy5w
10. OCRBench-v2 テキスト認識ベンチマークデータセット
OCRBench-v2は、華中科技大学が華南理工大学、ByteDanceなどの機関と共同でリリースした、マルチモーダル大規模光学式文字認識(OCR)ベンチマークです。様々なテキスト関連タスクにおける大規模マルチモーダルモデル(LMM)のOCR機能を評価することを目的としています。
直接使用します:https://go.hyper.ai/hhGFR
選択された公開チュートリアル
今週は、質の高い公開チュートリアルを 4 つのカテゴリにまとめました。
* OCRチュートリアル: 2
* AI4Sチュートリアル: 2
* 大規模モデルチュートリアル: 1
* マルチモーダルチュートリアル: 6
OCRチュートリアル
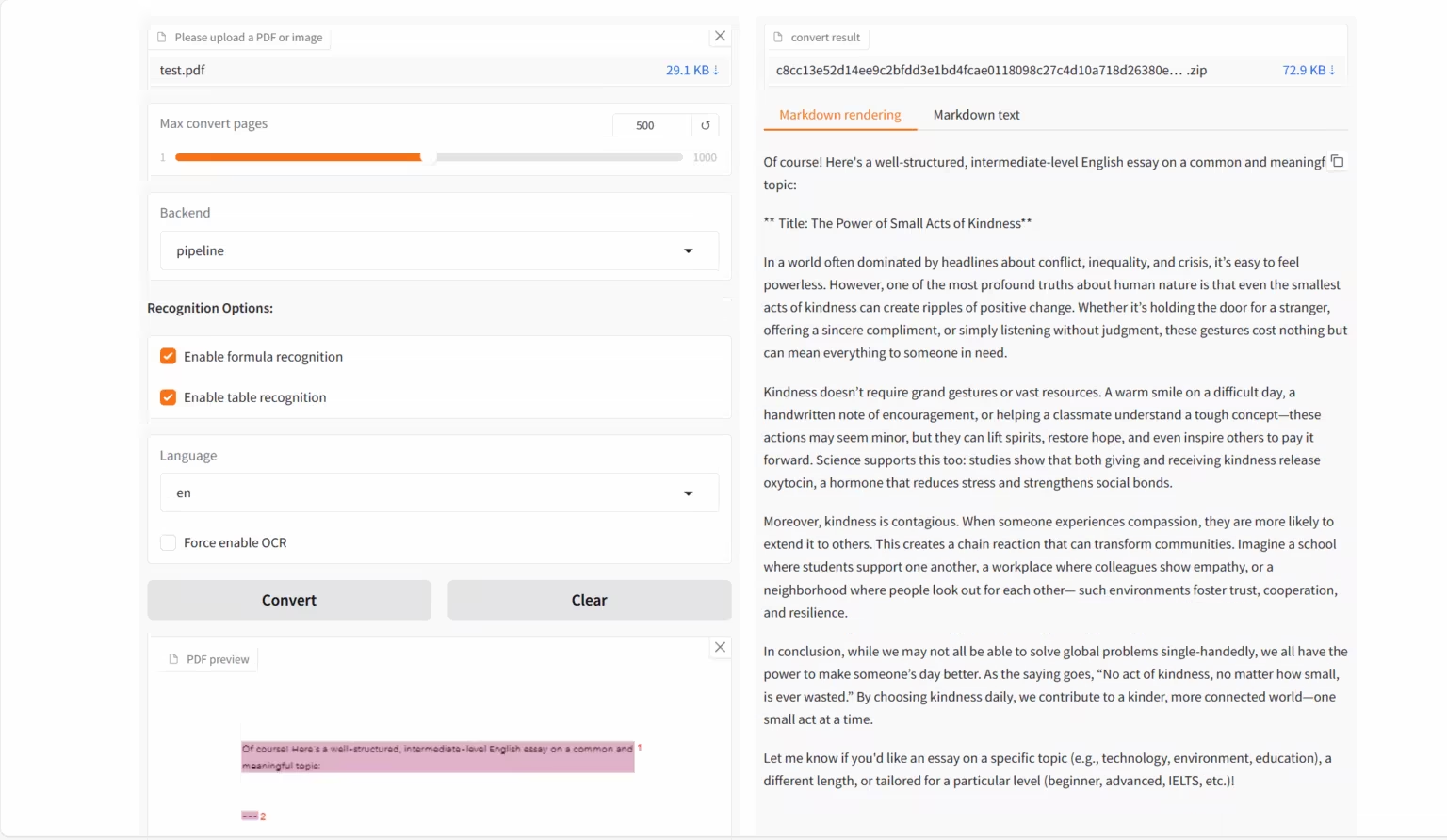
1. MinerU2.5-2509-1.2B: ドキュメント解析デモ
MinerU 2.5-2509-1.2Bは、OpenDataLabと上海AIラボによって開発された視覚言語モデルであり、高精度かつ効率的なドキュメント解析のために特別に設計されています。これはMinerUシリーズの最新版であり、PDFなどの複雑なドキュメント形式を構造化された機械可読データ(MarkdownやJSONなど)に変換することに重点を置いています。
オンラインで実行:https://go.hyper.ai/emEKs
2. ドルフィンマルチモーダルドキュメント画像解析
Dolphinは、ByteDanceチームによって開発されたマルチモーダル文書解析モデルです。このモデルは2段階のアプローチを採用しており、まず構造を分析し、次にコンテンツを解析します。第1段階では文書レイアウト要素のシーケンスを生成し、第2段階ではこれらの要素をアンカーとして用いてコンテンツを並列解析します。Dolphinは、様々な文書解析タスクにおいて優れたパフォーマンスを示し、GPT-4.1やMistral-OCRなどのモデルを凌駕しています。
オンラインで実行: https://go.hyper.ai/lLT6X

AI4Sチュートリアル
1. BindCraft: タンパク質バインダーの設計
Martin Pacesa氏が開発したオープンソースのワンクリックタンパク質結合剤設計パイプラインであるBindCraftは、10~100%という実験的成功率を誇ります。BindCraftは、AlphaFold2の事前学習済み重みを直接利用し、ナノモル親和性のde novo結合剤をin silicoで生成します。これにより、ハイスループットスクリーニングや実験の反復、さらには既知の結合部位さえも必要としません。
オンラインで実行:https://go.hyper.ai/eSoHk
2. Ml-simplefold: 軽量なタンパク質フォールディング予測AIモデル
Ml-simplefoldは、Appleがリリースしたタンパク質フォールディング予測のための軽量AIモデルです。フローマッチング技術をベースとしたこのモデルは、多重配列アライメント(MSA)などの複雑なモジュールを回避し、ランダムノイズからタンパク質の3次元構造を直接生成することで、計算コストを大幅に削減します。
オンラインで実行: https://go.hyper.ai/Y0Us9
大規模モデルのチュートリアル
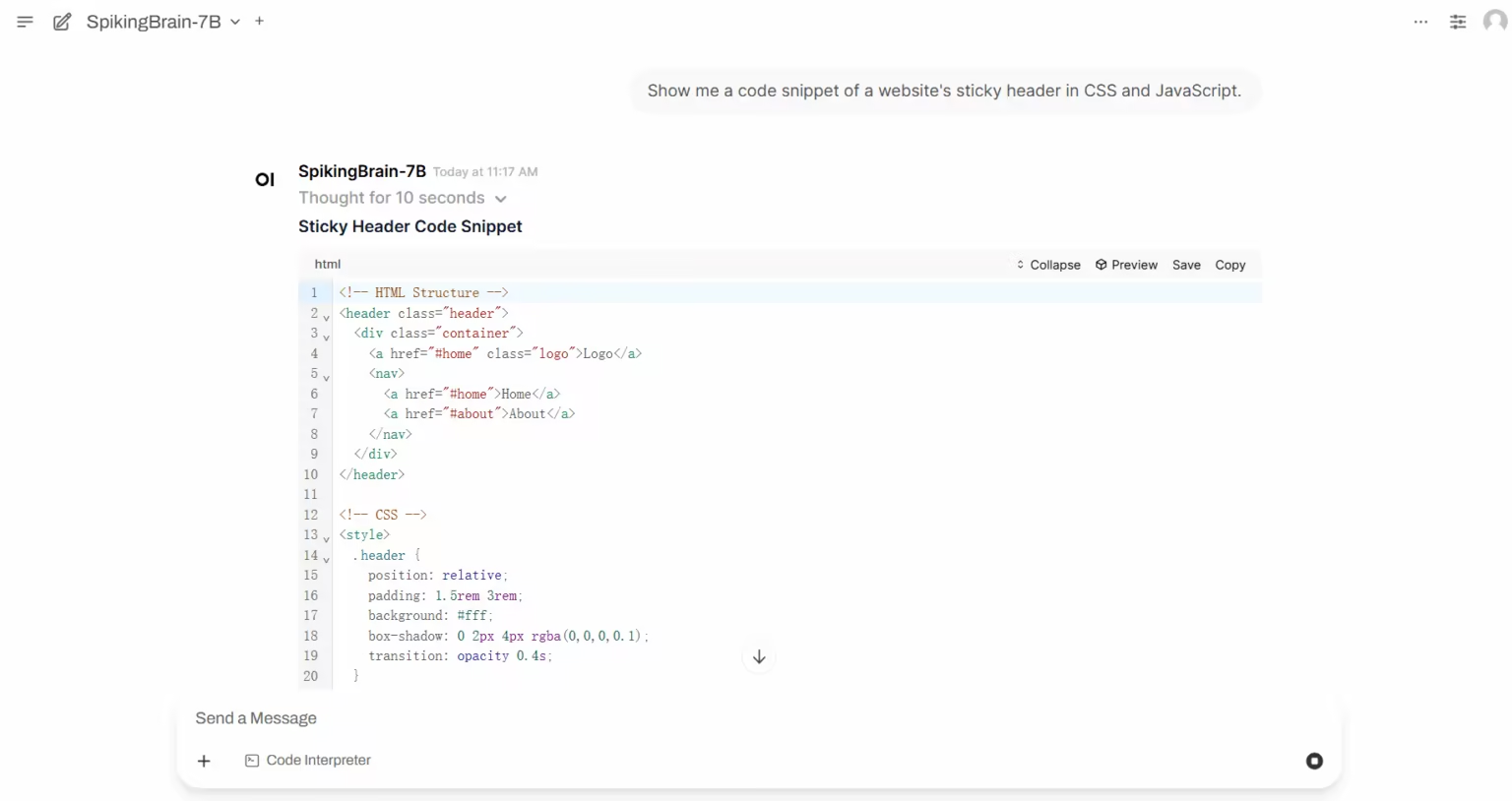
1. SpikingBrain-1.0: 本質的複雑性に基づく大規模な脳型スパイクモデル
SpikingBrain-1.0は、中国科学院自動化研究所が、国家脳認知・脳型知能重点実験室、Muxi Integrated Circuit Co., Ltd.などの研究機関と共同で発表した、国産の大型制御可能な脳型スパイキングモデルです。脳のメカニズムに着想を得たこのモデルは、ハイブリッド型の高効率注意メカニズム、MoEモジュール、スパイクコーディングをアーキテクチャに統合し、オープンソースモデルエコシステムと互換性のある汎用的な変換パイプラインを備えています。
オンラインで実行:https://go.hyper.ai/i3zHC
マルチモーダルチュートリアル
1. HuMo-1.7B: マルチモーダルビデオ生成フレームワーク
HuMoは、清華大学とByteDanceのIntelligent Creation Labによって開発されたマルチモーダル動画生成フレームワークです。人間中心の動画生成に特化しており、テキスト、画像、音声などの複数のモーダル入力から、高品質で詳細かつ制御可能な人間のような動画を生成できます。
オンラインで実行:https://go.hyper.ai/Xe4dM
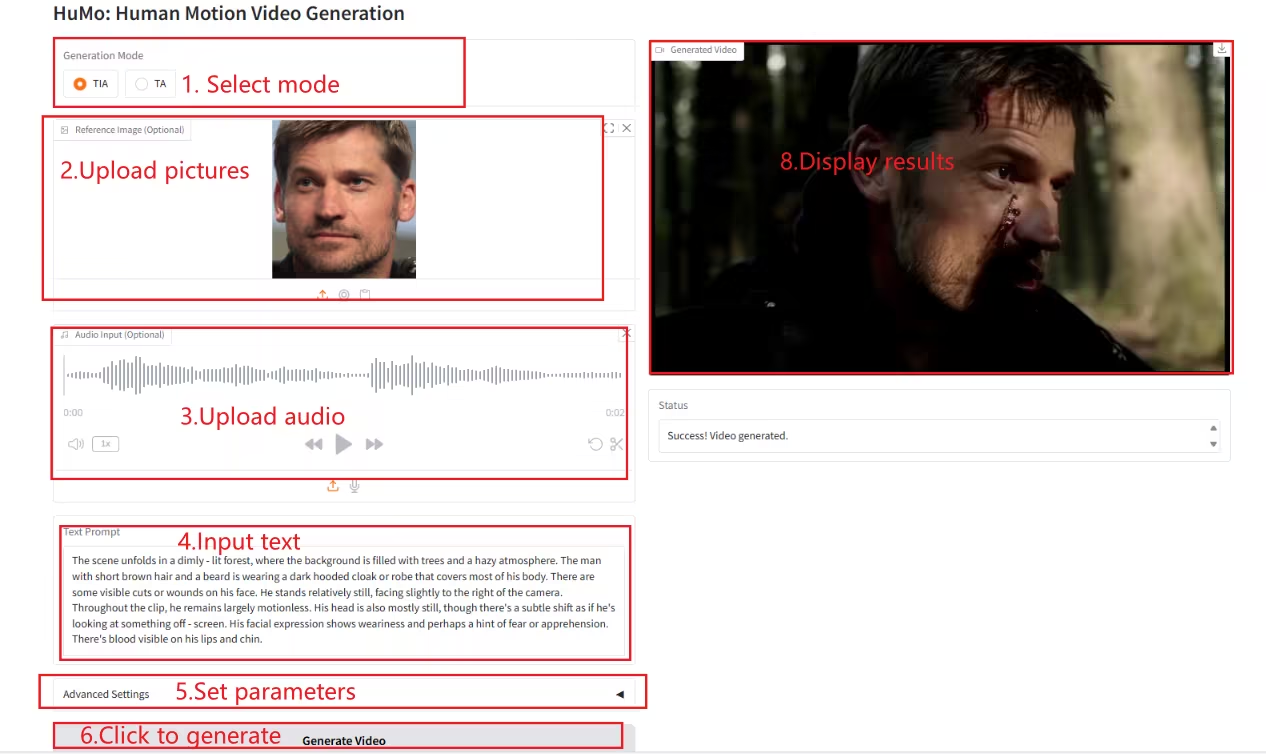
2. NeuTTS-Air: 軽量で効率的な音声複製モデル
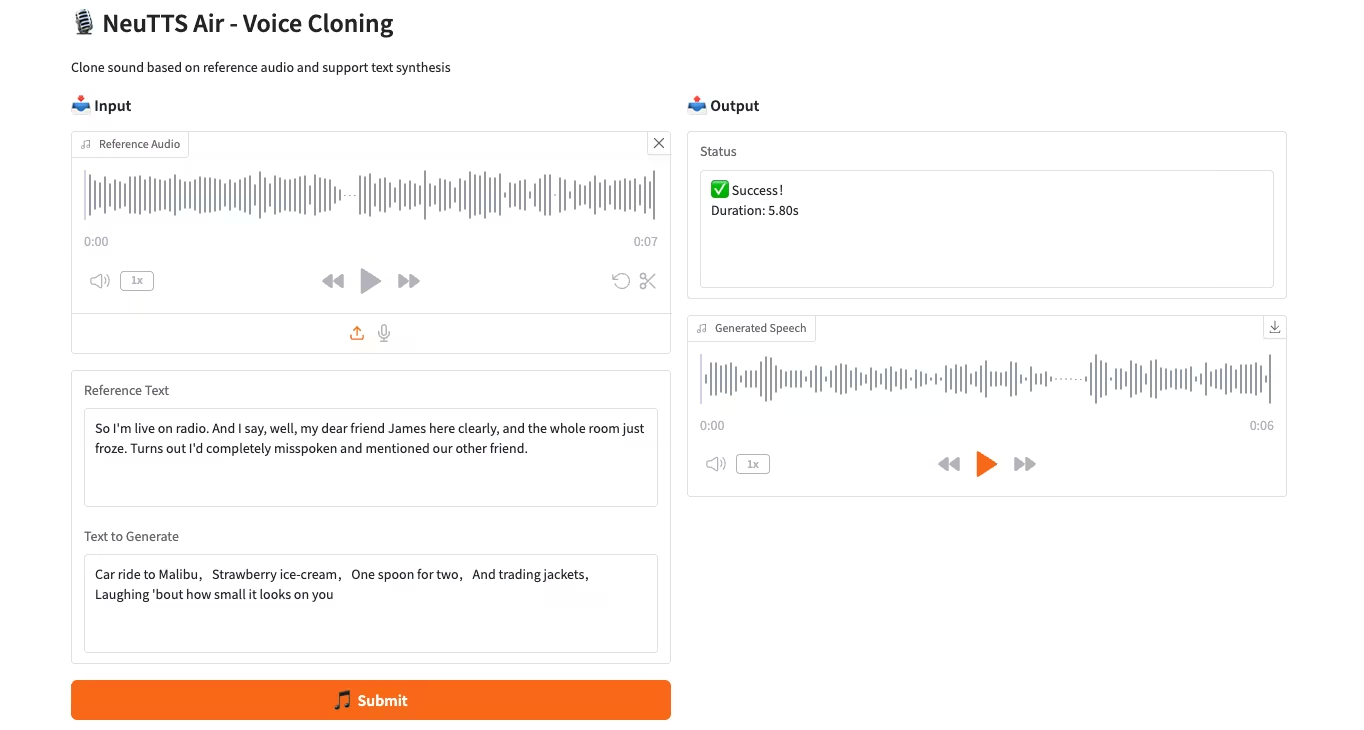
NeuTTS-Airは、Neuphonic社がリリースしたエンドツーエンドのテキスト音声合成(TTS)モデルです。0.5B Qwen LLMバックボーンとNeuCodecオーディオコーデックをベースとし、デバイス上での展開と即時音声クローニングにおいて、数ショット学習機能を備えています。システム評価では、NeuTTS Airはオープンソースモデルの中でも最先端の性能を達成しており、特にハイパーリアリスティック合成とリアルタイム推論のベンチマークにおいて高い性能を発揮しています。
オンラインで実行:https://go.hyper.ai/7ONYq
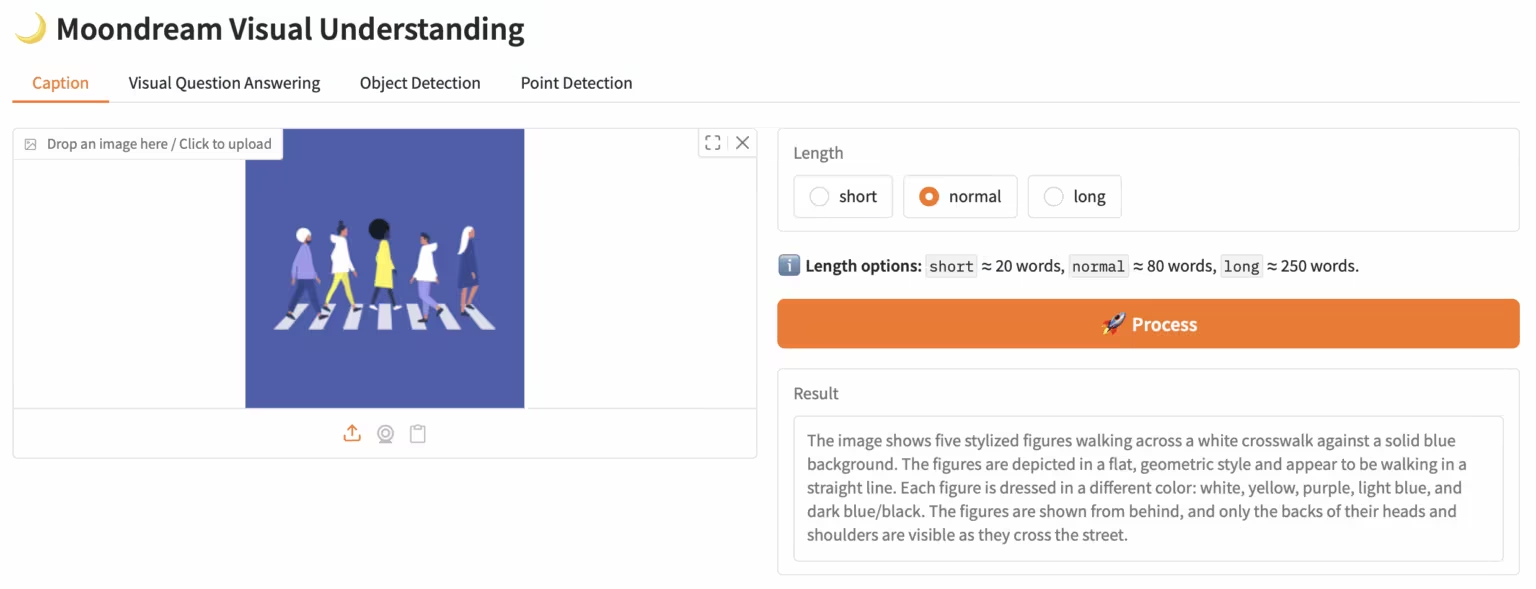
3. Moondream3-preview: モジュラー視覚言語理解モデル
Moondream3は、Moondreamチームが提案するハイブリッドエキスパートアーキテクチャに基づく視覚言語モデルであり、90億個のパラメータ(うち20億個は活性化パラメータ)を誇ります。このモデルは最先端の視覚推論機能を提供し、最大32KBのコンテキスト長をサポートし、高解像度画像を効率的に処理できます。
オンラインで実行:https://go.hyper.ai/eKGcP
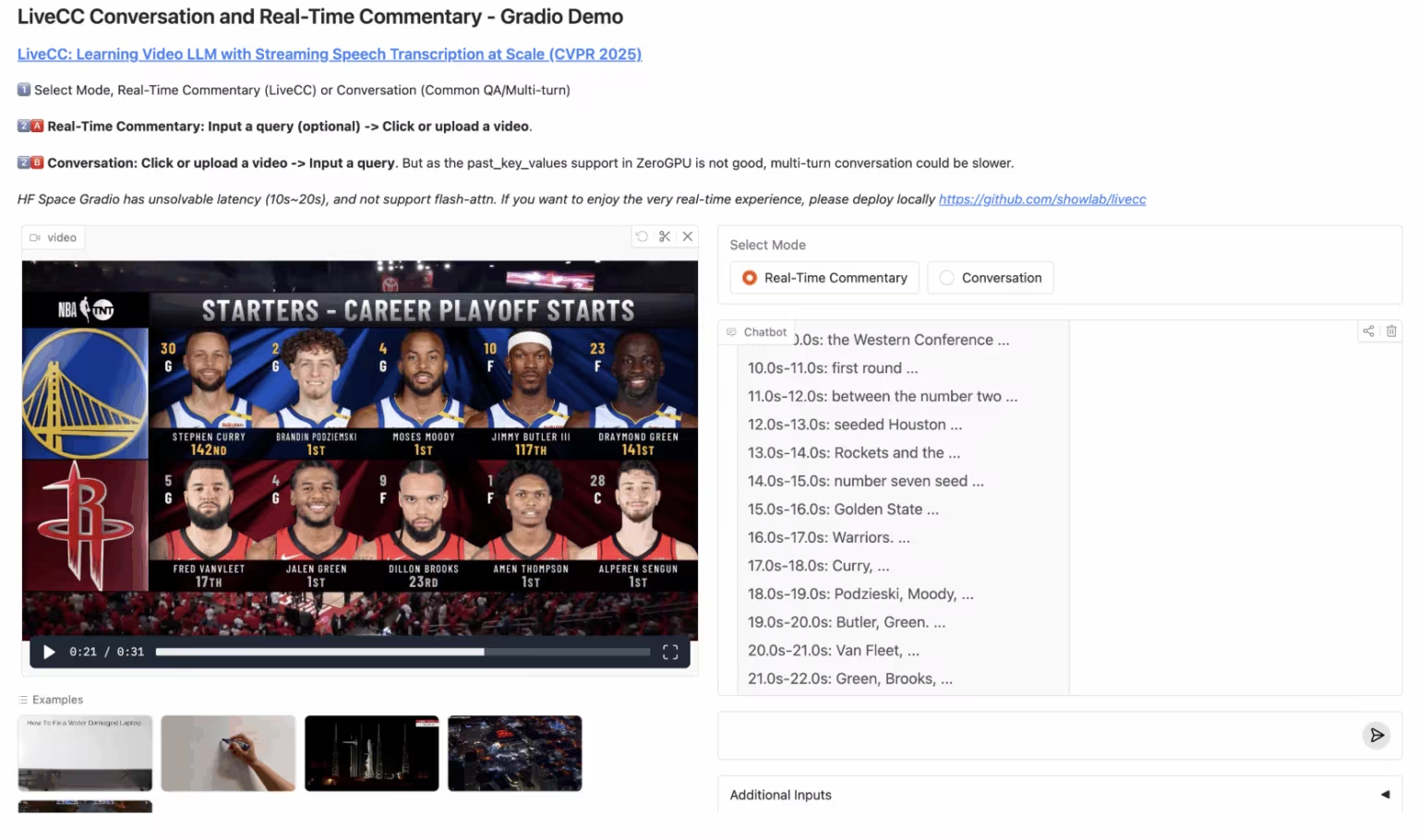
4. LiveCC: リアルタイム動画解説大型モデル
LiveCCは、大規模なストリーミング音声の書き起こしに焦点を当てた動画言語モデルプロジェクトです。このプロジェクトは、革新的な動画自動音声認識(ASR)ストリーミング手法を用いて、リアルタイム解説機能を備えた初の動画言語モデルの学習を目指しています。ストリーミングとオフラインの両方のベンチマークにおいて、現在最先端の性能を達成しています。
オンラインで実行:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part: コンポーネントベースの3D生成モデル
テンセントHunyuanチームが開発した3Dジェネレーティブモデル「Hunyuan3D-Part」は、P3-SAMとX-Partで構成されています。高精度で制御可能なコンポーネントベースの3Dモデル生成の先駆者であり、50種類以上のコンポーネントの自動生成をサポートしています。ゲームモデリングや3Dプリントなどの分野で幅広い応用が可能で、例えば、自動車モデルをボディとホイールに分離してゲーム固有のスクロールロジックを実現したり、ステップバイステップの3Dプリントを実現したりできます。
オンラインで実行:https://go.hyper.ai/1w1Jq

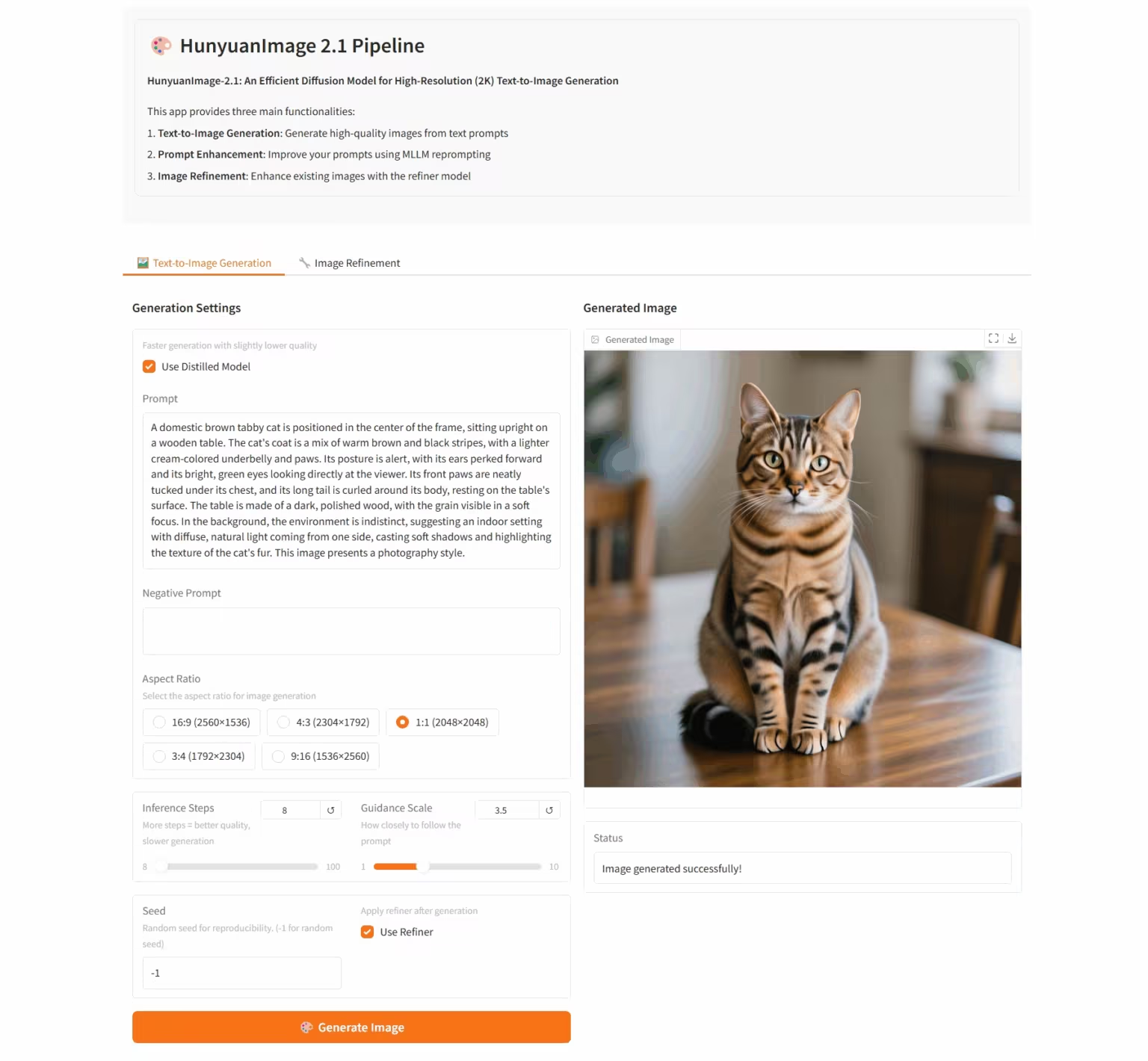
6. HunyuanImage-2.1: 高解像度(2K)Wensheng画像の拡散モデル
HunyuanImage-2.1は、Tencent Hunyuanチームが開発したオープンソースのテキストベースの画像モデルです。ネイティブ2K解像度をサポートし、強力な複雑なセマンティック理解機能を備えており、シーンの詳細、キャラクターの表情、アクションを正確に生成できます。このモデルは中国語と英語の両方の入力をサポートし、コミックやアクションフィギュアなど、様々なスタイルの画像を生成しながら、画像内のテキストやディテールを堅牢に制御できます。
オンラインで実行:https://go.hyper.ai/i96yp
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. QeRL: 効率性を超えて - LLMのための量子化強化学習
本論文では、大規模言語モデル向けの量子化強化学習フレームワークであるQeRLを提案します。NVFP4量子化と低ランク適応(LoRA)を組み合わせることで、このモデルはRLサンプリングフェーズを高速化し、メモリオーバーヘッドを大幅に削減します。QeRLは、320億パラメータ(32B)の大規模強化学習モデルを単一のH100 80GB GPUで学習できる初のフレームワークであり、全体的な学習速度も向上させます。
論文リンク: https://go.hyper.ai/catLh
2. 表現オートエンコーダを用いた拡散変換器
本論文では、VAEを事前学習済みの表現エンコーダ(DINO、SigLIP、MAEなど)と事前学習済みのデコーダーに置き換え、表現オートエンコーダ(RAE)と呼ばれる新しいアーキテクチャを構築する方法を検討します。これらのモデルは、高品質な再構成を実現するだけでなく、意味的に豊富な潜在空間を持ち、スケーラブルなTransformerベースのアーキテクチャ設計をサポートします。
論文リンク: https://go.hyper.ai/fqVs4
3. D2E: デスクトップデータによるビジョンアクション事前学習のスケーリングと、身体化AIへの転送
本論文では、D2E(Desktop to Embodied AI)フレームワークを提案し、デスクトップインタラクションがロボットによる具現化AIタスクの効果的な事前学習基盤として機能し得ることを実証します。特定の領域に限定された、あるいはデータが閉鎖的な従来のアプローチとは異なり、D2Eはスケーラブルなデスクトップデータ収集から具現化領域の検証および移行に至るまでの包括的な技術チェーンを構築します。
論文リンク: https://go.hyper.ai/aNbE4
4. カメラで考える:カメラ中心の理解と生成のための統合マルチモーダルモデル
本論文では、カメラ次元に沿って空間認識を拡張し、言語回帰と拡散ベースの生成手法を融合し、任意の視点からシーンを解析および生成できる、統合されたカメラ中心のマルチモーダル モデルである Puffin を提案します。
論文リンク: https://go.hyper.ai/9JBvw
5. DITING: ウェブ小説翻訳のベンチマークのためのマルチエージェント評価フレームワーク
本論文では、オンライン小説翻訳のための初の包括的な評価フレームワークであるDITINGを提案する。DITINGは、慣用句翻訳、語彙の曖昧性の扱い、用語のローカライズ、時制の一貫性、ゼロ代名詞の解決、文化的安全性という6つの側面から、翻訳の物語的一貫性と文化的忠実性を体系的に評価する。また、専門家による注釈が付された18,000以上の中国語と英語の文対に基づいて評価する。
論文リンク:https://go.hyper.ai/KRUmn
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. 香港科技大学などが提案した増分気象予報モデルVA-MoEは、751個のパラメータを簡素化しながらも最先端の性能を実現しています。
香港科技大学と浙江大学の研究チームは、可変適応型エキスパート混合モデル(VA-MoE)を開発しました。このモデルは、段階的な学習と変数インデックス埋め込みを用いて、複数のエキスパートモジュールを特定の気象変数に焦点を絞るよう誘導します。新しい変数や観測所が追加されても、モデルを完全に再学習することなく拡張できるため、精度を維持しながら計算オーバーヘッドを大幅に削減できます。
レポート全体を表示します。https://go.hyper.ai/nPWPN
2. NeurIPS 2025 | 華中科技大学などがOCRBench v2をリリース。Geminiは中国ランキングで優勝したが、合格点しか得られなかった。
華中科技大学の白翔氏のチームは、華南理工大学、アデレード大学、ByteDanceと共同で、次世代OCR評価ベンチマークOCRBench v2を発表しました。これは、2023年から2025年にかけて、世界中で主流のマルチモーダルモデル58種類を中国語と英語の両方で評価するものです。
レポート全体を表示します。https://go.hyper.ai/AL1ZJ
3. NeurIPS 2025に選ばれたトロント大学らは、特定の細胞における遺伝子発現の「標的制御」を実現するためのCtrl-DNAフレームワークを提案しました。
トロント大学のチームは、チャンピン研究所と共同で、Ctrl-DNAと呼ばれる制約強化学習フレームワークを開発しました。これにより、標的細胞でのCREの調節活動を最大化し、非標的細胞での活動を厳密に制限することができます。
レポート全体を表示します。https://go.hyper.ai/eVORr
4. AIがプラズマ暴走を予測。MITなどの研究チームは機械学習を活用し、少量のサンプルでプラズマのダイナミクスを高精度に予測しています。
MITを率いる研究チームは、科学的機械学習を用いて物理法則と実験データをインテリジェントに融合しました。彼らは、最小限のデータを用いて、トカマク構成可変(TCV)のランプダウン過程におけるプラズマのダイナミクスと潜在的な不安定性を予測できるニューラル状態空間モデルを開発しました。
レポート全体を表示します。https://go.hyper.ai/HQgZx
5. MOF構造が36年ぶりにノーベル賞を受賞:AIが化学を理解すると、金属有機構造体は生成研究の時代へと移行します。
2025年10月8日、北川進、リチャード・ロブソン、オマール・ヤギの3名は、金属有機構造体(MOF)分野への貢献によりノーベル化学賞を受賞しました。過去30年間、MOF分野は構造設計から産業化へと発展し、計算化学の基盤を築きました。今日、人工知能(AI)は生成モデルと拡散アルゴリズムを用いてMOF研究を再構築し、化学設計の新たな時代を切り開いています。
レポート全体を表示します。https://go.hyper.ai/U5XgN
人気のある百科事典の項目を厳選
1. DALL-E
2. ハイパーネットワーク
3. パレートフロント
4. 双方向長短期記憶(Bi-LSTM)
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
会議の締め切りは10月

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








