Command Palette
Search for a command to run...
「アシスタント」から「ユーザー」へ。Microsoft UserLM-8B は、実際の人間の会話をシミュレートし、LLM 最適化の新たな波を巻き起こします。軽量なパフォーマンスを実現するように設計された Extract-0 は、小さなパラメータを持つモデルで正確な情報抽出を実現します。

大規模言語モデル (LLM) の急速な発展により、ユーザーの明確なニーズを満たすために詳細かつ構造化された応答を提供することに特化した「アシスタント」として機能する強力なモデルが登場しました。存在する実際の会話シーンでは、ユーザーは意図を一度に完全に表現するのではなく、複数回の会話の中で徐々に情報を明らかにしていくことがよくあります。また、ユーザーの言語スタイルは、一般的に断片化、個人化、即時調整といった特徴を示します。対照的に、従来の「アシスタント」モデルはユーザーをシミュレートするのがあまり得意ではありません。さらに、LLMアシスタントが優れているほど、「ユーザー」の擬人化は歪んでしまいます。この限界は、現在のLLM評価システムの重要な問題点を露呈しています。人間の会話を正確にシミュレートできる高品質な「ユーザー」ペルソナが不足しているため、既存の評価環境は過度に理想化され、実際のアプリケーションの複雑なコンテキストに大きく追いついていないのです。
このような状況において、マイクロソフトは最新のユーザー言語モデルUserLM-8Bをリリースしました。アシスタントとして機能する典型的なLLMとは異なり、WildChat会話コーパスで学習されたこのモデルは、会話における「ユーザー」の役割をシミュレートするために使用でき、複数回の対話を行うことで、大規模モデルの能力を評価するための有用なツールとして機能します。UserLMを使用してプログラミングと数学の会話をシミュレートしたところ、GPT-4oのスコアは74.61 TP3Tから57.41 TP3Tに低下しました。これは、より現実的なシミュレーション環境では、ユーザーの表現のニュアンスへの対応が困難になるため、「アシスタント」のパフォーマンスが低下する可能性があることを裏付けています。
UserLM-8Bのリリースにより、大規模モデルを評価するための、より現実的で堅牢なテスト環境が提供されます。ユーザーとの会話をシミュレートすることで、最先端のアシスタントモデルであってもパフォーマンスが大幅に低下する可能性があるため、研究者や開発者は現実世界のインタラクションにおけるモデルの弱点をより正確に特定できるようになります。これにより、LLM の能力評価は、単一の静的なベンチマーク テストとスコアの比較を超えて、現実に近い「実際の戦闘演習」を徐々に重視するようになります。LLM がユーザーの真意をより深く理解し、人間のユーザー エクスペリエンスを継続的に最適化できるようにします。
HyperAI公式サイトにて「UserLM-8b:ユーザー会話シミュレーションモデル」を公開しました。ぜひお試しください!
オンラインでの使用:https://go.hyper.ai/EHcdQ
10月20日から10月24日までのhyper.ai公式サイトの更新内容を簡単にご紹介します。
* 高品質の公開データセット: 8
* 質の高いチュートリアルの選択: 7
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 10月に締め切りを迎えるトップカンファレンス:1
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
1. CP2K_Benchmark パフォーマンスベンチマークデータセット
CP2Kベンチマークデータセットは、高性能コンピューティング(HPC)環境向けに特別に設計されたパフォーマンステストおよび検証入力のセットです。オープンソースの第一原理シミュレーションソフトウェアCP2Kから派生したこのデータセットは、異なるハードウェアプラットフォーム、並列化戦略(MPI/OpenMP)、およびコンパイル最適化設定における量子化学および分子動力学計算のパフォーマンスを評価するために使用されます。
直接使用します:https://go.hyper.ai/BGnLb
2. Smilei_Benchmark プラズマダイナミクスシミュレーションベンチマークデータセット
Smilei は、極度強度の光によって照射された物質のシミュレーション (Simulation of Matter Irradiated by Light at Extreme Intensities) の略で、レーザープラズマ相互作用、粒子加速、強場 QED、宇宙物理学などの分野向けに、高精度、高性能、スケーラブルなプラズマダイナミクスシミュレーションプラットフォームを提供するように設計された、オープンソースで使いやすい電磁粒子インセル (PIC) コードです。
直接使用します:https://go.hyper.ai/6VCxB
3. Gatk_benchmarkゲノム解析サンプルデータセット
GATK(ゲノム解析ツールキット)は、MITとハーバード大学の合弁会社であるブロード研究所によって開発されたオープンソースのバイオインフォマティクスツールキットです。このプロジェクトは、ハイスループットシーケンシング(NGS)データのための標準化された解析パイプラインを提供することを目的としています。
直接使用します:https://go.hyper.ai/0VAuf
4. LAMMPS-Bench分子動力学ベンチマークデータセット
LAMMPS Benchデータセットは、LAMMPS(分子動力学シミュレーションソフトウェア)の性能を、異なるハードウェアおよび構成でテストおよび比較するために使用されます。これらのデータセットは科学的な実験データではなく、計算性能(速度、スケーリング、効率)を評価するために使用されます。これらのデータセットには、特定のアーキテクチャ、力場ファイル、入力スクリプト、初期原子座標などが含まれています。LAMMPSはこれらのデータセットを`bench/`フォルダに提供しています。
直接使用します:https://go.hyper.ai/L4gye
5. PromptCoT-2.0-SFT-4.8M 教師あり微調整プロンプトSFTデータセット
PromptCoT-2.0-SFT-4.8Mは、大規模言語モデル向けの高品質な推論プロンプト(ファインチューニングまたは自己学習用)を提供するために設計された、大規模な合成プロンプトデータセットです。このデータセットには、推論トレースを含む約480万件の完全合成プロンプトが含まれており、数学とプログラミングという2つの主要な推論領域をカバーしています。
直接使用します:https://go.hyper.ai/f188j
6. Extract-0 文書情報抽出データ
Extract-0は、文書情報抽出タスク向けに特別に設計された高品質なトレーニングおよび評価データセットです。複雑な抽出タスクにおける小規模パラメータモデルの性能最適化研究を支援することを目的としています。
直接使用します:https://go.hyper.ai/z9BQO
7. EmoBench-M感情認識ベンチマークデータセット
EmoBench-Mは、深圳大学、光明研究所、マカオ大学などの研究機関が提案する、マルチモーダル大規模言語モデル(MLLM)の感情理解能力を評価するためのベンチマークデータセットです。動的およびマルチモーダルなインタラクションシナリオにおいて、既存の単モーダルまたは静的な感情データセットのギャップを埋め、実環境における人間の感情表現と知覚の複雑さに近づくことを目指しています。
直接使用します:https://go.hyper.ai/WafXo
8. GeoReasoning-10K 幾何学的マルチモーダル推論データセット
GeoReasoning-10Kは、幾何学における視覚的モダリティと言語的モダリティのギャップを埋めるために設計された、幾何学のためのマルチモーダル推論データセットです。このデータセットには、詳細な幾何学的推論注釈が付与された10,000組の幾何学的画像とテキストのペアが含まれています。各ペアは、幾何学的構造、意味表現、視覚的表現の一貫性を維持しており、非常に正確なクロスモーダルな意味的整合を実現しています。
直接使用します:https://go.hyper.ai/7qisY

選択された公開チュートリアル
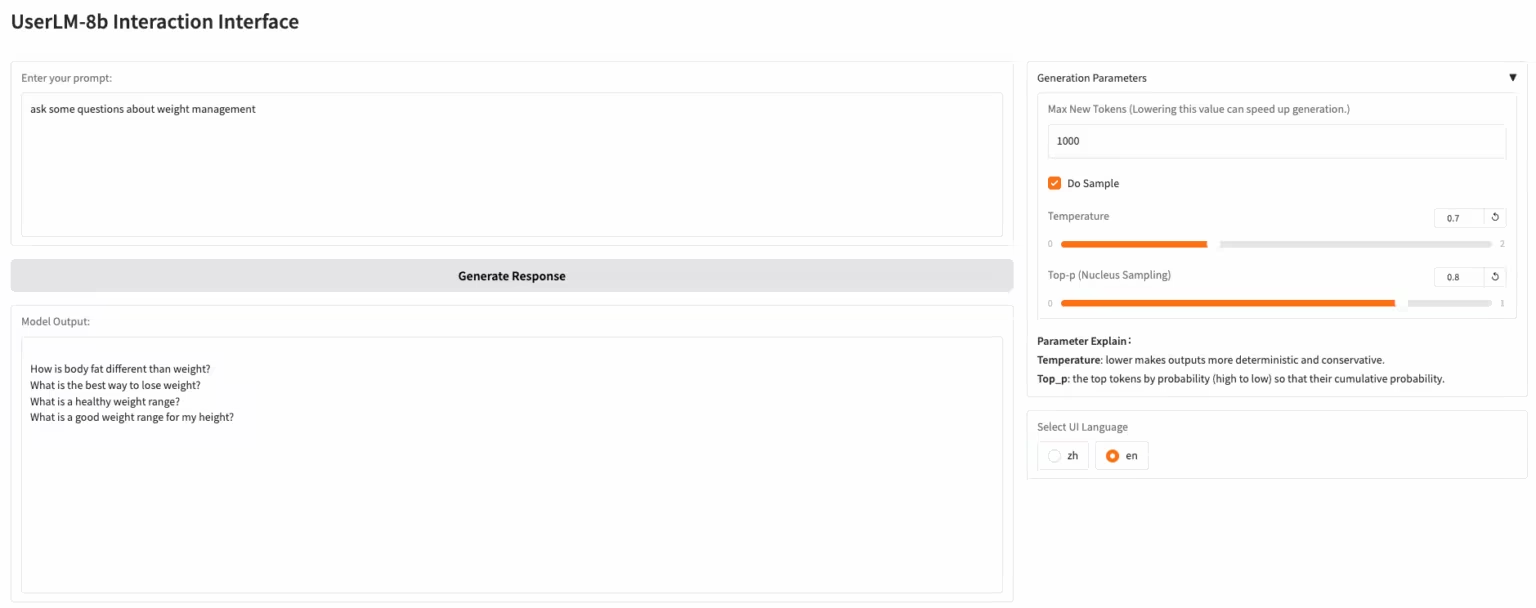
1. UserLM-8b: ユーザー対話シミュレーションモデル
UserLM-8bは、Microsoftが公開したユーザー行動シミュレーションモデルです。会話における「アシスタント」の役割を担う一般的なLLMとは異なり、UserLM-8bは会話における「ユーザー」の役割をシミュレートし(WildChat会話コーパスで学習済み)、大規模アシスタントの能力評価に使用できます。このモデルは一般的な大規模アシスタントとは異なり、より現実的な会話をシミュレートしたり、問題を解決したりすることはできませんが、より強力なアシスタントの開発に役立ちます。
オンラインで実行:https://go.hyper.ai/EHcdQ
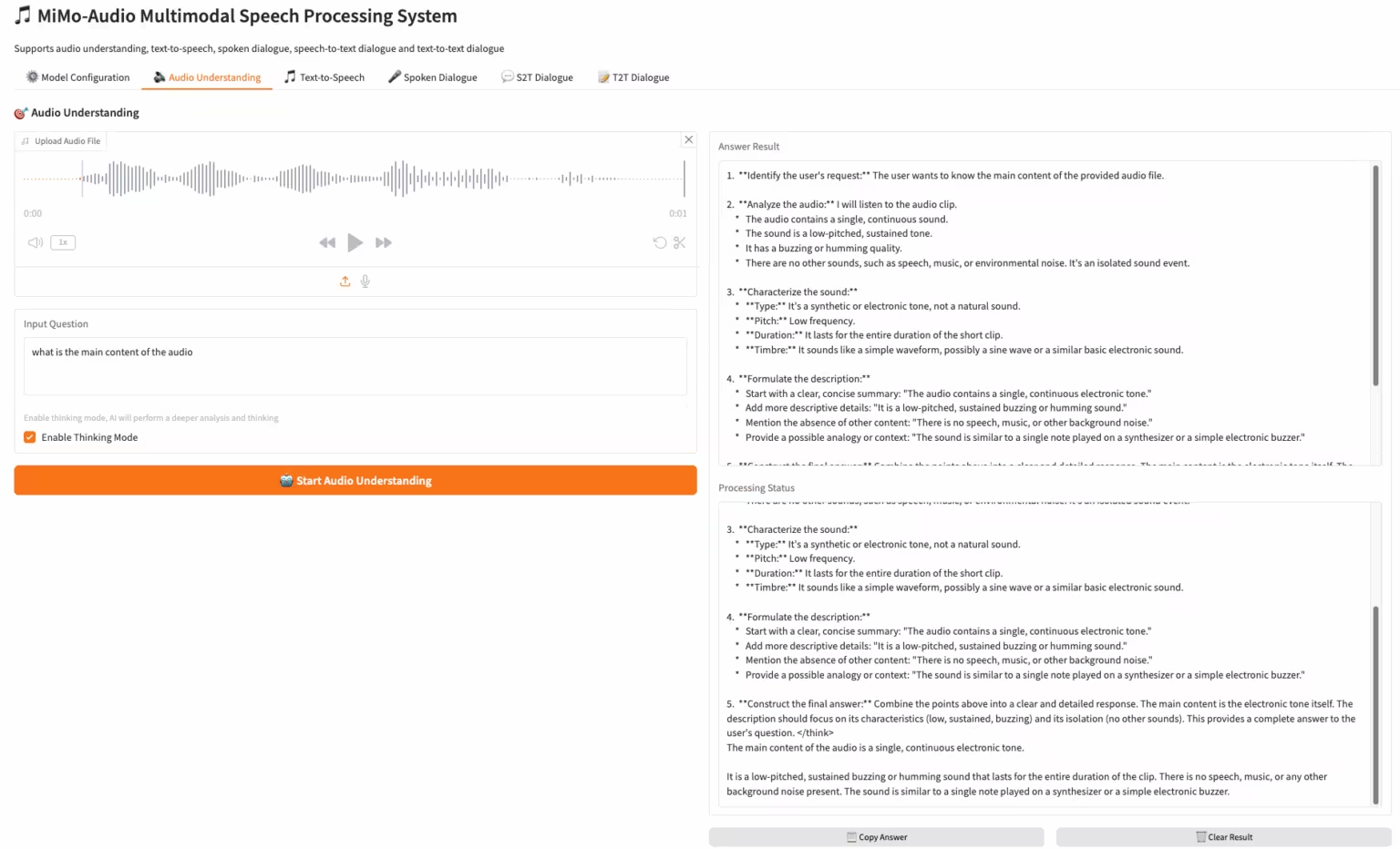
2. MiMo-Audio-7B-Instruct: Xiaomiのオープンソースエンドツーエンド音声モデル
MiMo-Audioは、Xiaomiがリリースしたエンドツーエンドの音声モデルです。事前学習データは1億時間以上に拡張されており、研究者らは、MiMo-Audioが様々な音声タスクにおいて、少ないショットで学習できる能力を発揮していることを観察しています。チームはこれらの能力を体系的に評価し、MiMo-Audio-7B-Baseが、オープンソースモデルの音声知能と音声理解のベンチマークの両方において、最高水準(SOTA)のパフォーマンスを達成したことを明らかにしました。
オンラインで実行:https://go.hyper.ai/3DWbb
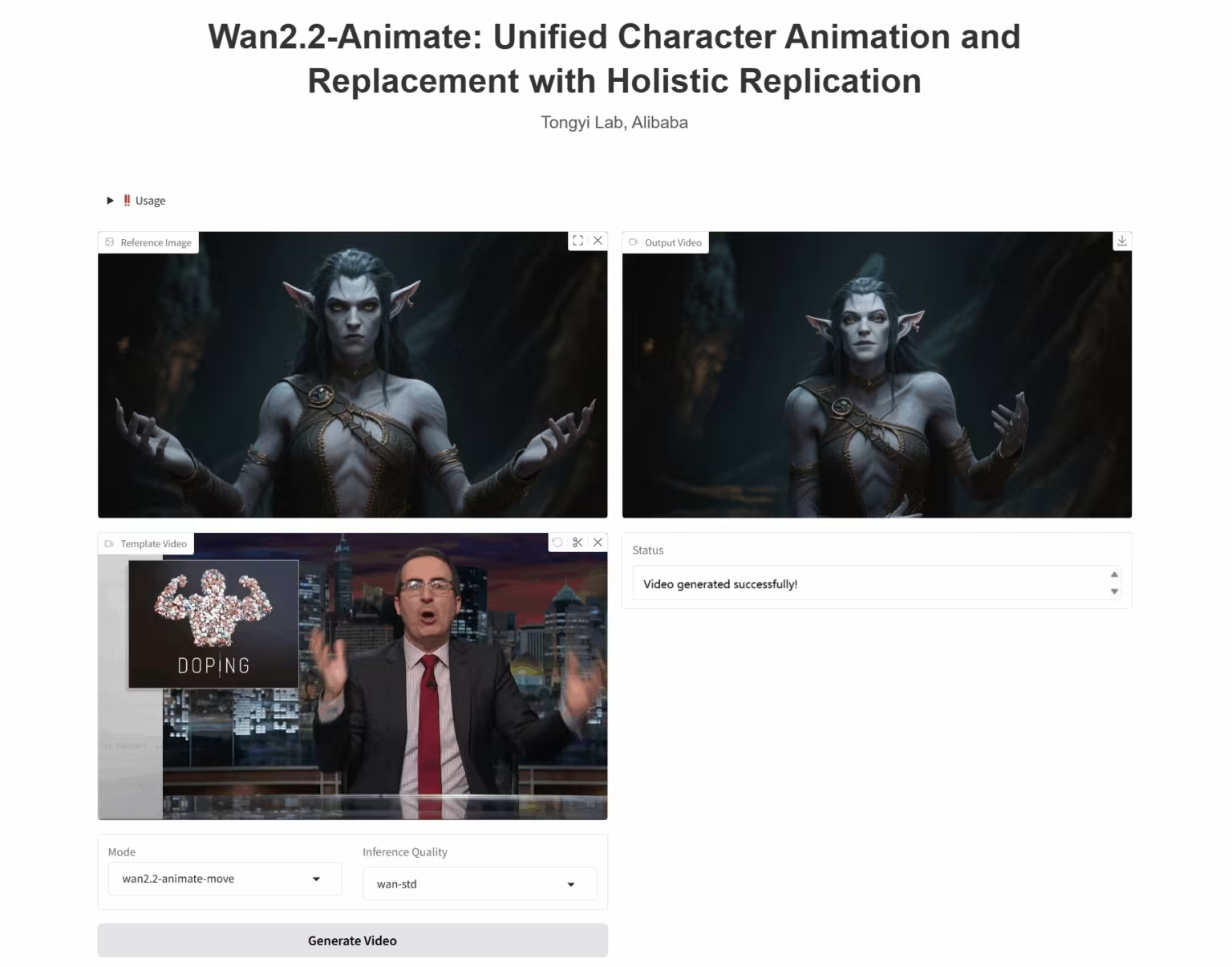
3. Wan2.2-Animate-14B: オープンな大規模ビデオ生成モデル
Wan2.2-Animate-14Bは、アリババ同義万向チームによって開発されたオープンソースのモーション生成モデルです。このモデルは、モーション模倣モードとロールプレイングモードの両方をサポートしています。パフォーマーの動画に基づいて、表情や動きを正確に再現し、非常にリアルなキャラクターアニメーション動画を生成することができます。
オンラインで実行: https://go.hyper.ai/UbtSO
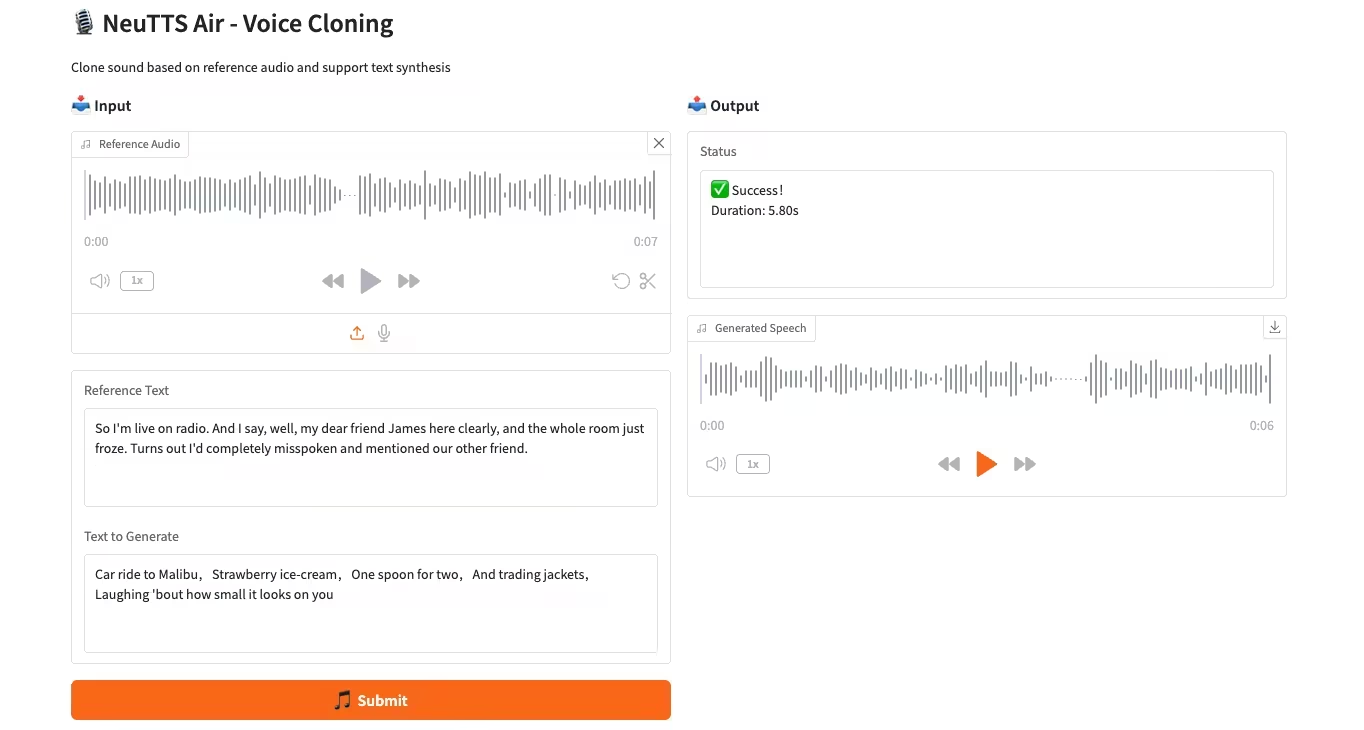
4. NeuTTS-Air音声複製モデルのCPU展開
NeuTTS-Airは、Neuphonic社がリリースしたエンドツーエンドのテキスト音声合成(TTS)モデルです。0.5B Qwen LLMバックボーンとNeuCodecオーディオコーデックをベースとしたこのモデルは、デバイス上での展開と即時音声クローニングにおいて、数ショット学習能力を実証しています。システム評価の結果、NeuTTS Airはオープンソースモデルの中でも最先端の性能を達成しており、特にハイパーリアリスティック合成とリアルタイム推論のベンチマークにおいてその性能が顕著です。
オンラインで実行:https://go.hyper.ai/KMMG1
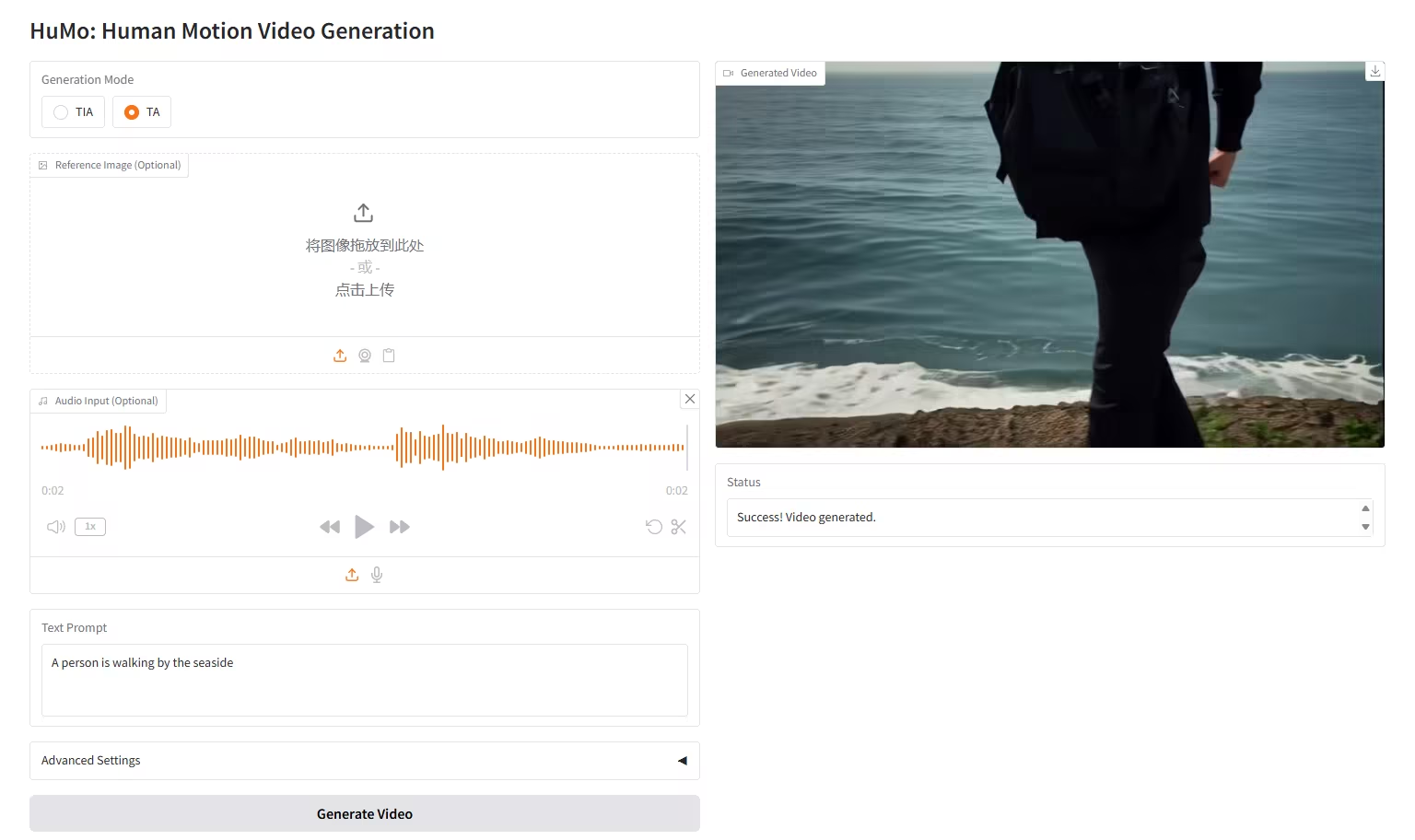
5. HuMo-1.7B: マルチモーダルビデオ生成フレームワーク
HuMoは、清華大学とByteDanceのインテリジェントクリエーションラボが開発した、人間中心の動画生成に特化したマルチモーダル動画生成フレームワークです。テキスト、画像、音声などのマルチモーダル入力から、高品質で詳細かつ制御可能な、人間のような動画を生成します。このモデルは、堅牢なテキストキュー追従、一貫した被写体保持、音声駆動によるモーション同期をサポートしています。
オンラインで実行:https://go.hyper.ai/tnyQU
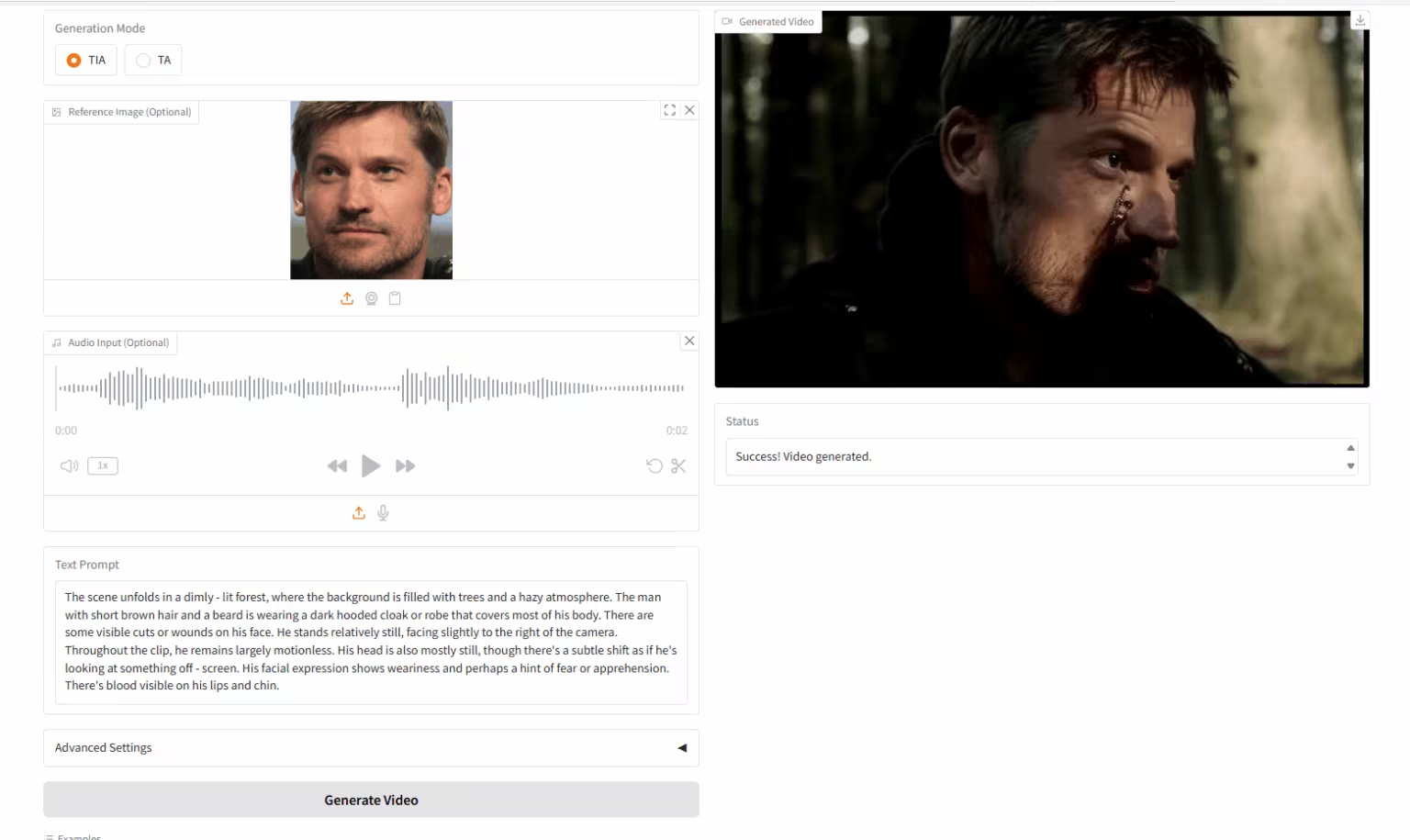
6. HuMo-17B: 三峰性協創
HuMoは、清華大学とByteDance Intelligent Creation Labがリリースしたマルチモーダル動画生成フレームワークです。テキスト画像(テキスト画像からVideoGen)、テキスト音声(テキスト音声からVideoGen)、テキスト画像音声(テキスト画像からVideoGen)からの動画生成をサポートしています。
オンラインで実行:https://go.hyper.ai/liAti
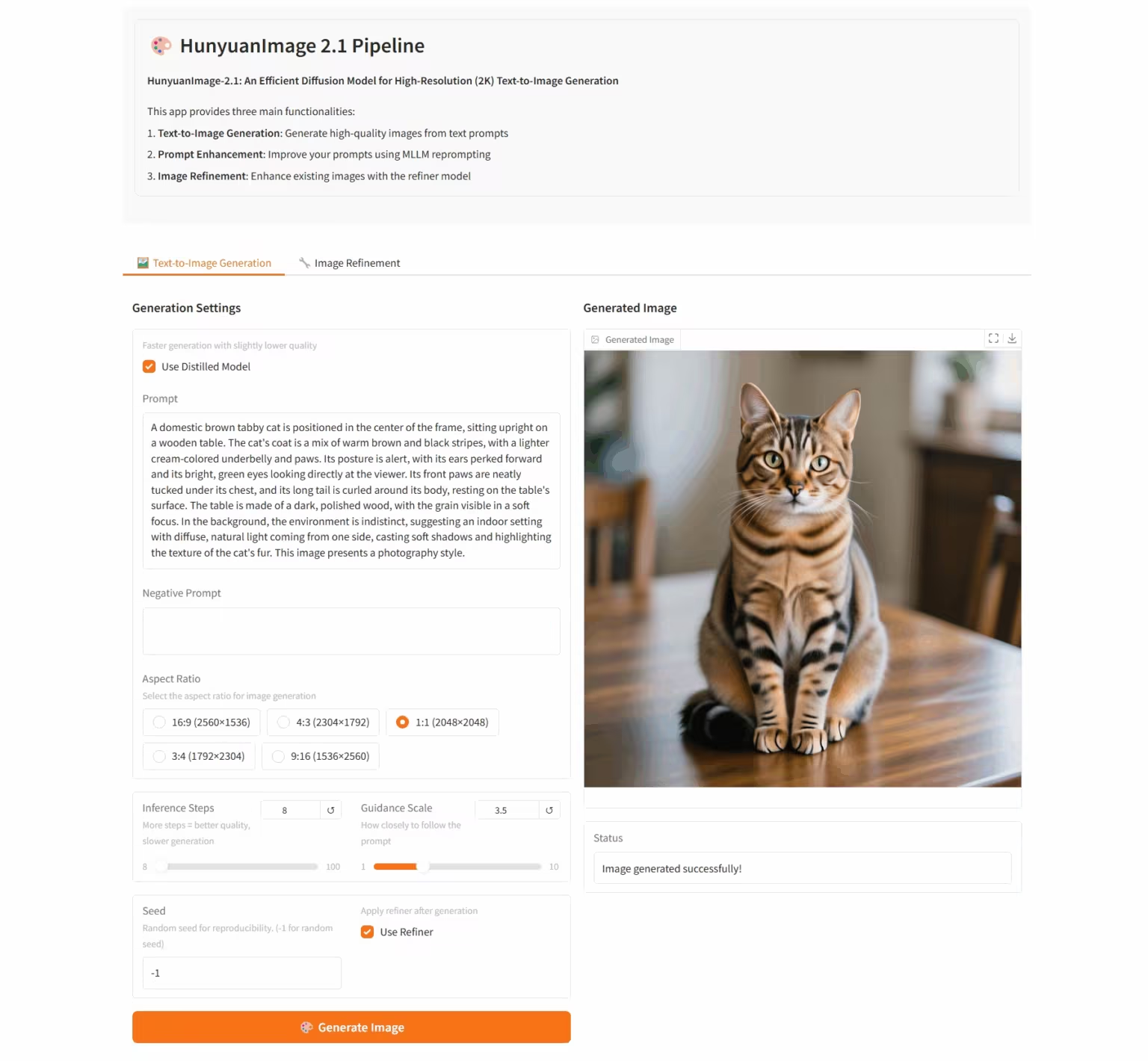
7. HunyuanImage-2.1: 高解像度(2K)Wensheng画像の拡散モデル
HunyuanImage-2.1は、Tencent Hunyuanチームが開発したオープンソースのテキストベースの画像モデルです。ネイティブ2K解像度をサポートし、強力な複雑なセマンティック理解機能を備えており、シーンの詳細、キャラクターの表情、アクションを正確に生成できます。このモデルは中国語と英語の両方の入力をサポートし、コミックやアクションフィギュアなど、様々なスタイルの画像を生成しながら、画像内のテキストやディテールを堅牢に制御できます。
オンラインで実行:https://go.hyper.ai/hpWNA
💡安定拡散チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] にメモし、グループに参加してさまざまな技術的な問題について話し合い、アプリケーションの効果を共有してください。

今週のおすすめ紙
1. LLM推論における内部確率と自己一貫性の橋渡しに関する理論的研究
本論文では、理論的知見を統合し、パープレキシティ一貫性と推論枝刈りという2つのコアコンポーネントから構成されるハイブリッドアプローチであるRPC(Perplexity-Consistency and Reasoning Pruning)を提案します。理論分析と7つのベンチマークデータセットを用いた実証結果の両方から、RPCが推論エラーを大幅に削減できる可能性が示されています。特に、RPCは自己一貫性に匹敵する推論性能を達成しながら、信頼性を大幅に向上させ、サンプリングコストを50%削減します。
論文リンク:https://go.hyper.ai/V3reH
2. すべての注意が重要:長期文脈推論のための効率的なハイブリッドアーキテクチャ
この技術レポートでは、Ring-mini-linear-2.0とRing-flash-linear-2.0を含む一連のRing-linearモデルを提案します。どちらのモデルも、線形アテンションとソフトマックスアテンションを効果的に統合したハイブリッドアーキテクチャを採用しており、ロングコンテキスト推論シナリオにおけるI/Oオーバーヘッドと計算負荷を大幅に削減します。
論文リンク:https://go.hyper.ai/xLhP3
3. BAPO: 適応クリッピングを用いたバランス型ポリシー最適化によるLLM向けオフポリシー強化学習の安定化
本論文では、クリッピング境界を動的に調整し、正と負の寄与を適応的に再調整し、ポリシーエントロピーを効果的に維持し、RL 最適化の安定性を大幅に向上させる、シンプルで効率的な方法である適応クリッピングによるバランスポリシー最適化 (BAPO) を提案します。
論文リンク:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: 自律データサイエンスのためのエージェント型大規模言語モデル
本論文では、自律型データサイエンス向けに特別に設計された初の大規模言語モデル「DeepAnalyze-8B」を紹介します。このモデルは、データソースからアナリストレベルの詳細な調査レポートに至るまで、エンドツーエンドのプロセスを自動化します。実験結果では、わずか80億個のパラメータを用いて、このモデルが、最先端のほとんどの独自仕様の大規模言語モデル上に構築された従来のワークフローエージェントよりも優れた性能を発揮することが実証されています。
論文リンク:https://go.hyper.ai/UTdwP
5. OmniVinci: オムニモーダル理解のためのアーキテクチャとデータの強化 LLM
本論文では、強力かつオープンソースのオムニモーダルな大規模言語モデル(LLM)の構築を目指すOmniVinciプロジェクトを提案します。研究者らは、モデルアーキテクチャの設計とデータ構築戦略について詳細な調査を行い、データ構築・合成プロセスを設計・実装し、2,400万件のユニモーダルおよびオムニモーダル会話のデータセットを生成しました。
論文リンク:https://go.hyper.ai/c3yQW
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. NeurIPS 2025 に選ばれた NVIDIA は、長期予測の問題を解決するための ERDM モデルを提案し、その中期および長期予測は EDM ベンチマークをリードし続けています。
NVIDIA とカリフォルニア大学サンディエゴ校の研究チームは、Elucidated Diffusion Model (EDM) フレームワークをベースに、ノイズ スケジューリング、ノイズ除去ネットワーク パラメータ化、前処理手順、損失重み付け戦略、サンプリング アルゴリズムを体系的に改善し、シーケンス モデリングのニーズを満たし、拡張シーケンス拡散モデル (ERDM) を構築しました。
レポート全体を表示します。https://go.hyper.ai/QZBBl
2. 付属チュートリアル | MITらは、AF2を直接呼び出してタンパク質複合体のインテリジェント設計を実現するBindCraftをリリースしました。
スイス連邦工科大学ローザンヌ校(EPFL)とマサチューセッツ工科大学(MIT)のチームは、タンパク質バインダーをゼロから設計するためのオープンソースの自動化プロセス「BindCraft」を提案しました。その核となるアイデアは、幻覚的なバインダー配列をAlphaFold2の重みを通して逆伝播させ、誤差勾配を計算することです。
レポート全体を表示します。https://go.hyper.ai/LqNeb
3. 2年間で3つのノーベル賞:アルファベットの長期にわたる科学研究の蓄積、AI+量子コンピューティングが技術力と野心を牽引
2025年のノーベル賞が発表され、Googleの親会社であるAlphabetの科学者が再び受賞しました。2年連続でノーベル賞を受賞したテクノロジー大手として、「2年間で3つの賞と5人の受賞者」という同社の業績は偶然ではありません。2024年のAI技術による化学賞と物理学賞の受賞から、今回の物理学賞を受賞した量子研究のブレークスルーまで、10年以上にわたる野心的な計画と研究戦略が、同社の強力な科学研究力を育んできました。
レポート全体を表示します。https://go.hyper.ai/mY9Z3
MIT は、物理的な事前分布に基づいて生成 AI モデルを構築し、単一のスペクトル モダリティ入力のみで、最大 99% の実験的相関を持つクロスモーダル スペクトル生成を実現します。
MITの研究チームが、物理的事前分布に基づく生成AIモデル「SpectroGen」を提案しました。単一のスペクトルモダリティを入力として用いるだけで、実験結果と99%の相関を持つクロスモーダルスペクトルを生成できます。このモデルは2つの重要な革新を導入しています。1つ目は、スペクトルデータを数学的な分布曲線として表現すること、2つ目は、物理的事前分布に基づく変分オートエンコーダ生成アルゴリズムを構築することです。
レポート全体を表示します。https://go.hyper.ai/OsYY2
5. Google チームは Earth AI で協力し、3 つのコア データ ポイントに焦点を当てて、地理空間推論機能を 64% 向上させました。
Googleの複数のチームが共同で、地理空間人工知能モデルとインテリジェント推論システムである「Earth AI」を開発しました。このシステムは、相互運用可能なGeoAIモデル群を構築し、カスタマイズされた推論エージェントを通じてマルチモーダルデータの共同分析を可能にします。画像、人口、環境という3つのコアデータタイプに焦点を当て、Geminiベースのエージェントを用いてこれら3つのモデルを連携させます。このシステムは、単一ポイントモデルの限界を克服し、専門家でないユーザーでもクロスドメインのリアルタイム分析を実行できるようにすることで、地球システムの研究を、実用的なグローバルな洞察へと発展させます。
レポート全体を表示します。https://go.hyper.ai/djq48
人気のある百科事典の項目を厳選
1. DALL-E
2. ハイパーネットワーク
3. パレートフロント
4. 双方向長短期記憶(Bi-LSTM)
5. 相互ランク融合
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
会議の締め切りは10月

主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1800以上の公開データセットの国内高速ダウンロードノードを提供
* 600以上の古典的で人気のあるオンラインチュートリアルが含まれています
* 200 以上の AI4Science 論文ケースを解釈
* 600 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








