Command Palette
Search for a command to run...
コストを大幅に削減!Distill-Any-Depthが高精度な水深推定を実現。CVPR 2025に選定!Real-IADDが産業用検知の新たな高みを切り開く

単眼メトリック深度推定は、単一のRGB画像から絶対深度を予測することを目的としたコンピュータービジョン技術です。この技術は、自動運転、拡張現実(AR)、ロボット工学、3Dシーン理解などの分野で幅広い応用が期待されています。
ゼロショット単眼深度推定(MDE)は、深度分布を統一し、大規模なラベルなしデータを活用することで、汎化能力を大幅に向上させます。しかし、既存の手法ではすべての深度値を均一に扱うため、疑似ラベルのノイズが増幅され、蒸留効果が低下する可能性があります。これに基づき、浙江理工大学をはじめとする複数の大学がDistill-Any-Depthを発表しました。
Distill-Any-Depth は、蒸留アルゴリズムを通じて複数のオープンソース モデルの利点を統合し、少量のラベルなしデータのみで高精度の深度推定を実現します。数百万の注釈を必要とする従来の方法と比較すると、このプロジェクトではラベルのない画像が 20,000 枚しか必要ないため、データの注釈コストが大幅に削減されます。
現在、HyperAIは「Distill-Any-Depth: Monocular Depth Estimator」チュートリアルを公開しています。ぜひお試しください。
Distill-Any-Depth: 単眼深度推定装置
オンラインでの使用:https://go.hyper.ai/DNSf5
6月16日から6月20日まで、hyper.ai公式サイトが更新されました。
* 高品質の公開データセット: 10
* 高品質のチュートリアル: 14
* 今週のおすすめ論文:5
* コミュニティ記事の解釈:5件
* 人気のある百科事典のエントリ: 5
* 7月に締め切りを迎えるトップカンファレンス:5
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
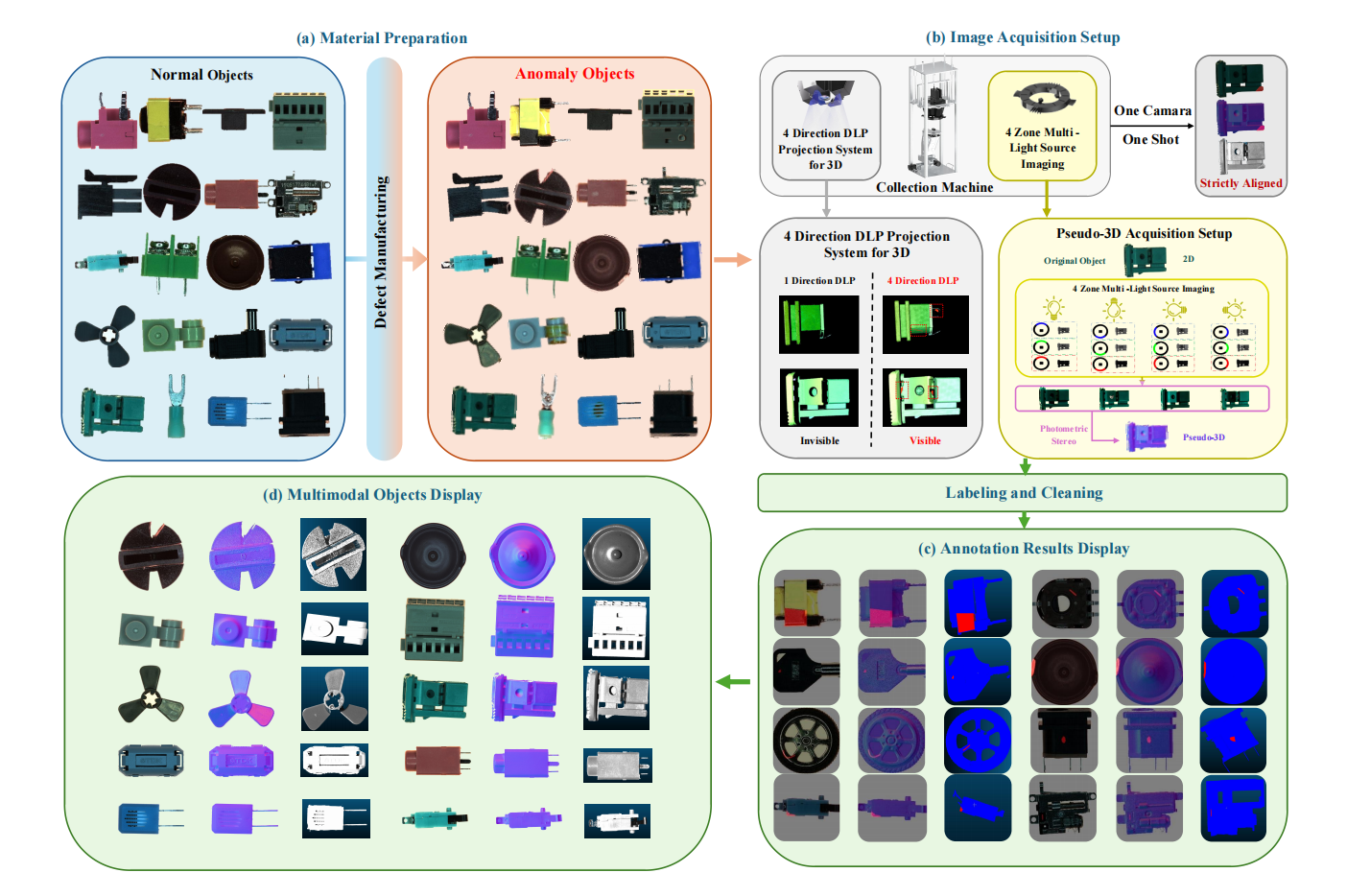
1. Real-IAD D³ 産業異常検知データセット
Real-IAD D³は高精度のマルチモーダルデータセットであり、関連論文はコンピュータービジョンのトップカンファレンスであるCVPR 2025に掲載されています。データセットには、20の工業製品カテゴリ、69の欠陥タイプ、および5,000の正常サンプルと3,450の異常サンプルを含む合計8,450のサンプルが含まれています。
直接使用します:https://go.hyper.ai/i4T8m
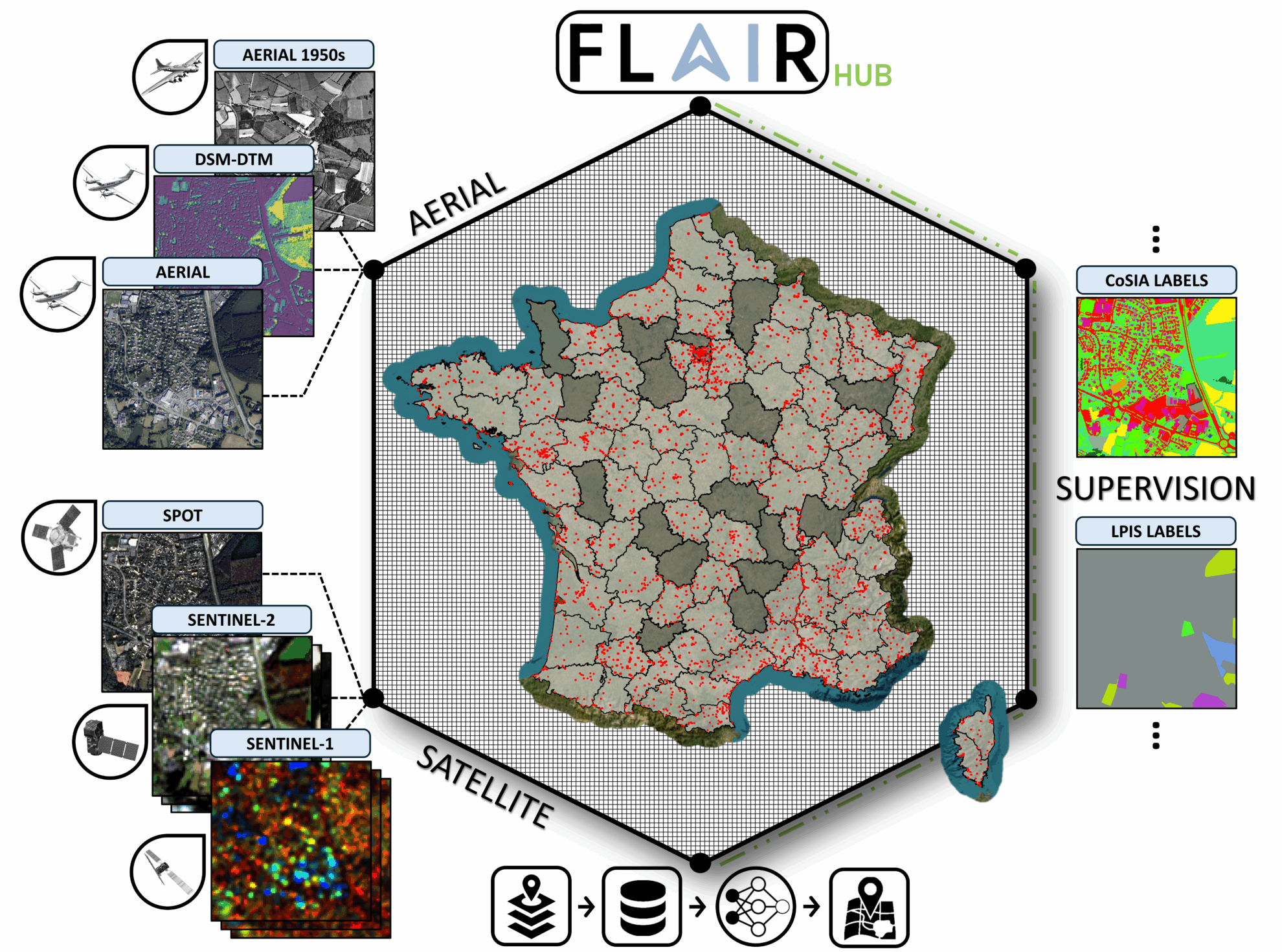
2. FLAIR HUB マルチセンサー フランス陸地データセット
FLAIR-HUB は、19 の土地被覆クラスと 23 の作物カテゴリを網羅し、フランスの多様な生態気候と景観の 2,500 km2 以上をカバーし、補完的なデータ ソースを統合しながら、手動で注釈が付けられた 630 億のピクセルを含んでいます。
直接使用します:https://go.hyper.ai/4VvCI
3. MathFusionQA 数学的推論データセット
MathFusionQAは、数学の問題における多段階的な推論と解決に重点を置いています。データセットには、59,000件の高品質な数学質問応答サンプルが含まれており、算術演算、代数方程式、幾何学応用、論理的推論など、様々な種類の問題を網羅しています。豊富な質問シナリオは、日常的な応用から学術的なトレーニングまでを網羅し、大規模言語モデル(LLM)の数学的問題解決能力の向上を目指しています。
直接使用します:https://go.hyper.ai/uGR9C
4. 機関書籍 1.0 書籍データセット
機関図書は、主に19世紀と20世紀に出版された、254言語によるパブリックドメイン図書983,004冊で構成されています。データセットには2,420億トークン、3億8,600万ページのテキストが含まれており、生データと後処理済みOCRエクスポート形式の両方で利用可能です。
直接使用します:https://go.hyper.ai/ZsSI7
5. ReasonMed 医療推論データセット
ReasonMedは、医療に関する質問応答やテキスト生成といったタスクのためのモデルの学習と評価を目的として設計された、最大規模のオープンソース医療推論データセットです。このデータセットには、臨床知識、解剖学、遺伝学など複数の分野を網羅する37万件の高品質な質問応答事例が含まれています。
直接使用します:https://go.hyper.ai/DwGmH
6. Miriad-5.8M 医療質問応答データセット
このデータセットには、基礎科学から臨床実践まであらゆる側面を網羅する582万件の医療に関する質問と回答のペアが含まれています。MIRIADは、RAG、医療情報検索、幻覚検出、指示調整といった様々な下流タスクをサポートするために、構造化された高品質の質問と回答のペアを提供します。
直接使用します:https://go.hyper.ai/Xw8Ph
7. 共通コーパス大規模オープンテキストデータセット
このデータセットは現在、最大のオープンライセンスのテキストデータセットであり、2兆トークンが含まれており、書籍、科学文献、コード、法的文書など、複数の分野のコンテンツをカバーしています。主な言語は英語とフランス語で、100億トークンを超える8言語(ドイツ語/スペイン語/イタリア語など)と10億トークンを超える33言語も含まれています。
直接使用します:https://go.hyper.ai/PnbfK
8. HLE 人間の質問推論ベンチマークデータセット
HLEは、人類の知識のフロンティアを網羅する究極のクローズドエンド型評価システムの構築を目指しています。データセットには、数学、人文科学、自然科学など数十の分野を網羅する2,500問の設問が含まれており、自動採点に適した多肢選択式問題や短答式問題も含まれています。
直接使用します:https://go.hyper.ai/Lq7mE
9. MedCaseReasoning 医療ケース推論データセット
MedCaseReasoningには、内科、神経内科、感染症、循環器内科など、複数の分野を網羅する13,000件の症例が収録されています。このデータセットは、複数の専門分野にまたがる臨床症例の診断と治療のプロセスを包括的に統合し、疾患診断、鑑別診断、治療方針決定といった中核タスクを網羅しています。このデータセットは、医療用大規模言語モデルの推論能力評価のための標準化されたリソースを提供することを目的としています。
直接使用します:https://go.hyper.ai/4vqwo
10. FineHARD画像テキストアライメントデータセット
FineHARDは、オープンソースの高品質な画像とテキストのアライメントデータセットです。このデータセットは、1,200万枚の画像と、それらに対応する長文および短文の説明テキストを収録し、4,000万個のバウンディングボックスをカバーする、大規模で精緻なデータセットです。
直接使用します:https://go.hyper.ai/L2TOZ
選択された公開チュートリアル
今週は、質の高い公開チュートリアルを 4 つのカテゴリにまとめました。
*大規模モデル展開チュートリアル: 5
*マルチモーダル処理チュートリアル: 4
*3D再構築チュートリアル: 3
*OCR認識チュートリアル:2
大規模モデルの展開チュートリアル
1. vLLM+Open WebUI の導入 KernelLLM-8B
KernelLLMは、PyTorchモジュールを効率的なTritonカーネルコードに自動変換し、高性能GPUプログラミングのプロセスを簡素化・高速化することを目的としています。このモデルはLlama 3.1 Instructアーキテクチャをベースとし、80億個のパラメータを備え、効率的なTritonカーネル実装の生成に重点を置いています。
オンラインで実行:https://go.hyper.ai/DfoWo
2. vLLM+Open WebUI 導入 MiniCPM4-8B
MiniCPM 4.0は、スパースアーキテクチャ、量子化圧縮、効率的な推論フレームワークなどの技術により、低い計算コストで高性能な推論を実現します。特に、長いテキスト処理、プライバシーに配慮したシナリオ、エッジコンピューティングデバイスの導入に適しています。長いシーケンスを処理する場合、このモデルはQwen3-8Bよりも大幅に高速な処理速度を示します。
オンラインで実行:https://go.hyper.ai/kcANp
3. vLLM+Open WebUI の導入 FairyR1-14B-Preview
FairyR1-14B-Previewは、数学とコードのタスクに重点を置いています。このモデルはDeepSeek-R1-Distill-Qwen-32Bをベースにしており、微調整とモデルマージ技術を組み合わせて構築されています。
オンラインで実行:https://go.hyper.ai/8jwGm
4. Qwen3埋め込みシリーズモデルの比較評価チュートリアル
Qwen3 埋め込みファミリは、テキスト検索、コード検索、テキスト分類、テキストクラスタリング、バイテキストマイニングなど、さまざまなテキスト埋め込みおよびランキングタスクにおける大きな進歩を表しています。
このチュートリアルでは、埋め込みモデルと並べ替えモデルの中核概念を体系的に理解し、実際のシナリオでそれらを選択して適用する方法を学びます。
オンラインで実行:https://go.hyper.ai/YtMdH
5. vLLM+Open WebUI の導入 Devstral-Small-2505
Devstralは、ツールを用いたコードベースの探索、複数ファイルの編集、ソフトウェアエンジニアリングエージェントの駆動に優れています。このモデルはSWE-benchで優れたパフォーマンスを発揮し、ベンチマークにおいてオープンソースモデルの中でトップとなりました。
オンラインで実行:https://go.hyper.ai/mnGzy
マルチモーダル処理チュートリアル
1. VideoLLaMA3-7Bのワンクリック展開
VideoLLaMA3は、画像と動画の理解タスクに特化したオープンソースのマルチモーダル基本モデルです。ビジョン中心のアーキテクチャ設計と高品質なデータエンジニアリングにより、動画理解の精度と効率を大幅に向上させます。
このチュートリアルでは、単一の RTX 4090 コンピューティング リソースを使用して VideoLLaMA3-7B-Image モデルをデプロイし、ビデオ理解と画像理解の 2 つの例を示します。
オンラインで実行:https://go.hyper.ai/t2z4d
2. Step1X-Edit: 画像編集ツール
Step1X-Editは、高精度なセマンティック解析、アイデンティティの一貫性維持、高精度な領域レベル制御という3つの主要機能を備えています。テキスト置換、スタイル変換、マテリアル変換、文字レタッチなど、11種類の高頻度画像編集タスクをサポートします。
オンラインで実行:https://go.hyper.ai/MdDTI

3. Chain-of-Zoom: 超解像画像の詳細拡大デモ
Chain-of-Zoomは、チェーンズーム(COZ)フレームワークであり、従来の単一画像超解像(SISR)モデルでは、その範囲をはるかに超えるズームが要求されると機能しなくなるという問題に対処します。COZフレームワークに組み込まれた標準的な4倍拡散SRモデルは、高い知覚品質と忠実度を維持しながら、256倍以上のズームを実現できます。
オンラインで実行:https://go.hyper.ai/7Lixx

4. Sa2VA: 画像と動画の高密度知覚理解に向けて
Sa2VAは、画像と動画の高密度知覚理解のための初の統合モデルです。特定のモダリティやタスクに限定されることが多い既存のマルチモーダル大規模言語モデルとは異なり、Sa2VAは、参照セグメンテーションや会話など、幅広い画像・動画タスクを、最小限の単発微調整でサポートします。
オンラインで実行:https://go.hyper.ai/tj2bX
3D再構築チュートリアル
1. Distill-Any-Depth: 単眼深度推定装置
このプロジェクトは、蒸留アルゴリズムを通じて複数のオープンソース モデルの利点を統合し、少量のラベルなしデータのみで高精度の深度推定を実現し、現在の SOTA (最先端) パフォーマンスを刷新します。
オンラインで実行:https://go.hyper.ai/DNSf5

2. VGGT: 一般的な3Dビジョンモデル
VGGTは、フィードフォワード型ニューラルネットワークです。シーンの主要な3Dプロパティ(カメラの外部パラメータと内部パラメータ、ポイントマップ、深度マップ、3Dポイントの軌跡など)を、1つ、数個、または数百のビューから数秒で直接推定します。また、シンプルで効率的であり、1秒未満で再構成を実現し、視覚的ジオメトリ最適化技術を用いた後処理を必要とする他の手法よりも優れた性能を発揮します。
オンラインで実行:https://go.hyper.ai/e8xzG
3. UniDepthV2: ユニバーサル単眼メトリック深度推定
UniDepthV2は、単一の画像から複数の領域にまたがるメトリック3Dシーンを再構築できます。既存のMMDEパラダイムとは異なり、UniDepthV2は推論時に入力画像から追加情報なしにメトリック3Dポイントを直接予測することで、汎用性と柔軟性に優れたMMDEソリューションの実現を目指しています。
オンラインで実行:https://go.hyper.ai/JdgZC
OCR認識チュートリアル
1. MonkeyOCR: 構造認識関係のトリプルパラダイムに基づく文書解析
MonkeyOCRは、非構造化文書のコンテンツを構造化情報へと効率的に変換する機能を提供します。このモデルは、学術論文、教科書、新聞など、様々な文書形式に対応し、複数の言語にも対応しているため、文書のデジタル化と自動処理を強力にサポートします。
オンラインで実行:https://go.hyper.ai/s9GE2
2. Nanonets-OCR-s: 文書情報抽出およびベンチマークツール
Nanonets-OCRは、数式、画像、署名、透かし、チェックボックス、表など、文書内の様々な要素を認識し、構造化されたMarkdown形式に整理することができます。この機能により、学術論文、法律文書、ビジネスレポートといった複雑な文書の処理に優れた性能を発揮します。
このチュートリアルでは、リソースとしてRTX 4090カードを1枚使用します。このチュートリアルには、ドキュメントから情報と画像を抽出する機能と、PDFをMarkdownに変換する機能の2つの機能が含まれています。
オンラインで実行:https://go.hyper.ai/1uPym
💡安定拡散チュートリアル交流グループも開設しました。Neural Star(WeChat ID: Hyperai01)を追加し、[SD Tutorial]とコメントしてグループに参加し、様々な技術的な問題について議論したり、応用結果を共有したりしましょう。
今週のおすすめ紙
1.FocalAD: エンドツーエンドの自動運転のためのローカルモーションプランニング
本論文では、重要な局所近傍に着目し、局所的な動作表現を強化することで計画を最適化する、エンドツーエンドの自動運転フレームワーク「FocalAD」を提案する。具体的には、FocalADは、自律ローカルエージェントインタラクタ(ELAI)とフォーカルローカルエージェントロス(FLAロス)という2つのコアモジュールから構成される。
論文リンク:https://go.hyper.ai/vjBZy
2. Biomni:汎用バイオメディカルAIエージェント
Biomniは、複数の生物医学分野にまたがる幅広い研究タスクを自律的に実行するように設計された、汎用生物医学AIアシスタントです。生物医学の行動空間を体系的にマッピングするために、Biomniはアクション発見エージェントを活用し、25の生物医学分野にわたる数万件の論文から主要なツール、データベース、プロトコルをマイニングすることで、世界初の統合エージェント環境を構築します。
論文リンク:https://go.hyper.ai/zTFzy
3.SeerAttention-R: 長時間推論のためのスパースアテンション適応
本稿では、推論モデルの長文デコード向けに設計されたスパースアテンションフレームワーク、SeerAttention-Rを紹介します。このフレームワークはSeerAttentionを拡張し、自己蒸留ゲーティングメカニズムによるアテンションスパース性の学習設計を維持しながら、クエリプーリングを排除することで自己回帰デコードに適応します。軽量な挿入ゲーティングメカニズムを備えたSeerAttention-Rは柔軟性が高く、元のパラメータを変更することなく既存の事前学習済みモデルに容易に統合できます。
論文リンク:https://go.hyper.ai/8XHpf
4.拡散モデルを用いたテキストを考慮した画像復元
本論文では、マルチタスク拡散フレームワークTeReDiffを提案する。これは、拡散モデルの内部特徴をテキスト検出モジュールに組み込み、両方のコンポーネントが共同学習の恩恵を受けることを可能にする。これにより、後続のノイズ除去ステップで手がかりとして使用できるリッチテキスト表現を抽出できるようになる。
論文リンク:https://go.hyper.ai/3YDSf
5.電気応答の統合微分学習
本論文では、一般化ポテンシャル関数と印加外部電場との正確な微分関係から応答特性を導出する等変機械学習フレームワークを実装する。この手法は電場への応答に焦点を当て、電気エンタルピー、力、分極、ボルン電荷、分極率を、正確な物理的制約、対称性、保存則を全て適用する統一モデルで予測する。
論文リンク:https://go.hyper.ai/AO8dM
AIフロンティアに関するその他の論文:https://go.hyper.ai/iSYSZ
コミュニティ記事の解釈
1. ハーバード大学は、石英から強誘電体まで、材料の大規模な電界シミュレーションを加速するための等価機械学習フレームワークを提案した。
ハーバード大学とボッシュの共同研究チームは革新的なソリューションを提案し、電気応答のための統合微分学習フレームワークを開発しました。このフレームワークは、一般化ポテンシャルエネルギーと外部刺激に対する応答関数を単一の機械学習モデルで同時に学習できるため、従来の独立モデルに内在する欠陥を克服し、結晶、無秩序物質、液体物質の誘電特性および強誘電特性に関する高精度研究への新たな道を切り開きます。
レポート全体を表示します。https://go.hyper.ai/d3cAc
HyperAIは7月5日に北京市中関村で第7回Meet AI Compiler Technology Salonを開催します。このイベントでは、AMD、Muxi Integrated Circuit、ByteDance、北京大学から4名の上級専門家を招き、低レベルのコンパイルから高レベルのアプリケーションまで、AIコンパイラの最先端の実践を多角的に探求しました。
レポート全体を表示します。https://go.hyper.ai/elNCA
3. 山東理工大学と他の研究者は、複数の植物トランスクリプトームデータを統合し、種間lncRNA予測精度が最大96%のPlantLncBoostモデルを構築した。
山東理工大学は、北京林業大学、広東省農業科学院、ブラジルのサンパウロ大学、英国のロザリンド・フランクリン医学大学、スウェーデンのウメオ大学の研究チームと共同で、植物lncRNA識別の一般化問題に体系的なソリューションを提供するPlantLncBoostモデルを構築しました。
レポート全体を表示します。https://go.hyper.ai/M88RZ
4. MITチームは大型モデルを使用して、セメントクリンカーの代替材料25種類をスクリーニングしました。これは、温室効果ガス排出量を12億トン削減することに相当する。
MIT の材料科学および工学部は、複数の部門のチームと連携して、大規模言語モデル (LLM) とマルチヘッド ニューラル ネットワーク アーキテクチャに基づく新しいデータ駆動型アプローチを開発し、セメント代替材料の反応性の大規模な予測とスクリーニングを実現しました。
レポート全体を表示します。https://go.hyper.ai/rtvf4
学術界における人工知能分野の最新の動向をより多くのユーザーに知ってもらうために、HyperAI の公式サイト (hyper.ai) に「最新論文」セクションが開設されました。このセクションでは、機械学習、計算言語、コンピューター ビジョンとパターン認識、人間とコンピューターの相互作用など、複数の垂直分野を網羅した最先端の AI 研究論文が毎日更新されます。
レポート全文はこちら:https://go.hyper.ai/ttAl7
人気のある百科事典の項目を厳選
1. DALL-E
2. 相互ソート融合RRF
3. パレートフロント
4. 大規模マルチタスク言語理解MMLU
5. 対照学習
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
サミットの締め切りは7月
7月2日 7:59:59 2026年
7月11日 7:59:59 ポピュラリティ 2026
7月15日 7:59:59 ソーダ2026
7月18日 7:59:59 シグモッド 2026
7月19日 7:59:59 ICSE2026
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!








