Command Palette
Search for a command to run...
CVPR 2024 最優秀論文候補!深セン大学と香港理工大学が共同で MemSAM をリリース:「すべてをセグメント化」モデルを医療ビデオのセグメンテーションに適用

世界保健機関 (WHO) の統計によると、心血管疾患は世界中で主な死因となっており、毎年約 1,790 万人の命が奪われ、世界の死亡者数の 32% を占めています。心エコー検査は心血管疾患の超音波診断技術であり、その携帯性、低コスト、リアルタイム性により臨床現場で広く使用されています。しかし、心エコー検査では、経験豊富な医師による手作業による評価が必要であり、評価の質は医師の専門知識と臨床経験に大きく依存します。その結果、多くの場合、評価結果に観察者間および観察者内で大きな差異が生じます。したがって、臨床現場では自動化された評価方法が緊急に必要とされています。
近年、心エコー図のビデオセグメンテーションのために多くの深層学習手法が提案されています。ただし、超音波ビデオの品質が低く、注釈が限られているため、これらの方法では依然として満足のいく結果が得られません。最近、大規模な視覚モデルであるセグメント エニシング モデル (SAM) が大きな注目を集めており、多くの自然画像セグメンテーション タスクで目覚ましい成功を収めています。ただし、SAM を医療ビデオのセグメンテーションにどのように適用するかは依然として困難な課題です。
これに基づいて、深セン大学コンピューターおよびソフトウェア学部と香港理工大学インテリジェントヘルス研究センターで構成されるチームは、CVPR 2024 で「MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation」というタイトルの論文を発表しました。トップコンピュータービジョンカンファレンス。論文では、研究者らは、SAM を医療ビデオに適用するために、新しい心エコー検査ビデオ セグメンテーション モデルである MemSAM を提案しました。

このモデルは、時空間情報を含むメモリを現在のフレームのセグメント化の手がかりとして使用し、メモリを保存する前にメモリ強化メカニズムを使用してメモリの品質を向上させます。公開データセットでの実験では、このモデルが少数のポイント ヒントで最先端のパフォーマンスを達成し、限られたアノテーションで完全に教師ありの手法に匹敵するパフォーマンスを達成し、ビデオ セグメンテーション タスクに必要なヒンティングとアノテーションの要件が大幅に軽減されることが示されています。
研究のハイライト:
- この研究では、時空間情報を含むメモリを現在のフレームのセグメンテーションの手がかりとして使用し、表現の一貫性とセグメンテーションの精度を向上させます。
- 研究者らはさらに、メモリを保存する前にメモリを強化し、それによってメモリキューイング中のスペックルノイズやモーションアーティファクトの悪影響を軽減するメモリ強化モジュールを提案しました。
- 新しいモデルは、既存のモデルと比較して最先端のパフォーマンスを示し、特に、限定されたアノテーションを備えた完全教師ありメソッドに匹敵するパフォーマンスを実現します。

用紙のアドレス:
https://github.com/dengxl0520/MemSAM
データセット: 2 つの公的に利用可能な心エコー検査データセット
研究者は、広く使用されている公的に入手可能な 2 つの心エコー検査データセットを調査しました カミュ そのアプローチは EchoNet-Dynamic で評価されました。
- CAMUS データセットには、2D 心尖部 2 腔ビュービデオと心尖部 4 腔ビュービデオを含む 500 の症例が含まれており、すべてのフレームに注釈も提供されます。
- EchoNet-Dynamic データセットには、10,030 の 2D 心尖部 2 腔ビュー ビデオが含まれています。各ビデオでは、左心室の面積が積分として表示され、拡張末期 (ED) と収縮末期 (ES) の位相のみが注釈付きで表示されます。
半教師ありビデオセグメンテーションにおける新しい手法の有効性を包括的に評価するために、研究者らは CAMUS データセットを CAMUS-Full と CAMUS-Semi の 2 つのバリアントに適合させました。 CAMUS-Full はトレーニング中にすべてのフレームに注釈を使用しますが、CAMUS-Semi は拡張末期 (ED) および収縮末期 (ES) フレームにのみ注釈を使用します。テスト中、両方のデータセットは完全なアノテーションを使用して評価されます。
研究者らはデータセットからビデオを均一にサンプリングし、それぞれ 10 フレームにトリミングしました。クロッピングにより、ED フレームが最初のフレーム、ES フレームが最後のフレームになり、解像度が 256×256 に調整されます。そして、CAMUSのデータセットは、トレーニングセット、検証セット、テストセットに7:1:2の比率で分割されています。
モデル アーキテクチャ: SAM コンポーネントとメモリ コンポーネントは、MemSAM の全体的なフレームワークを構築します。
MemSAM モデルの全体的なフレームワークは次の図に示されています。これは、SAM コンポーネントとメモリ コンポーネントの 2 つの部分で構成されます。
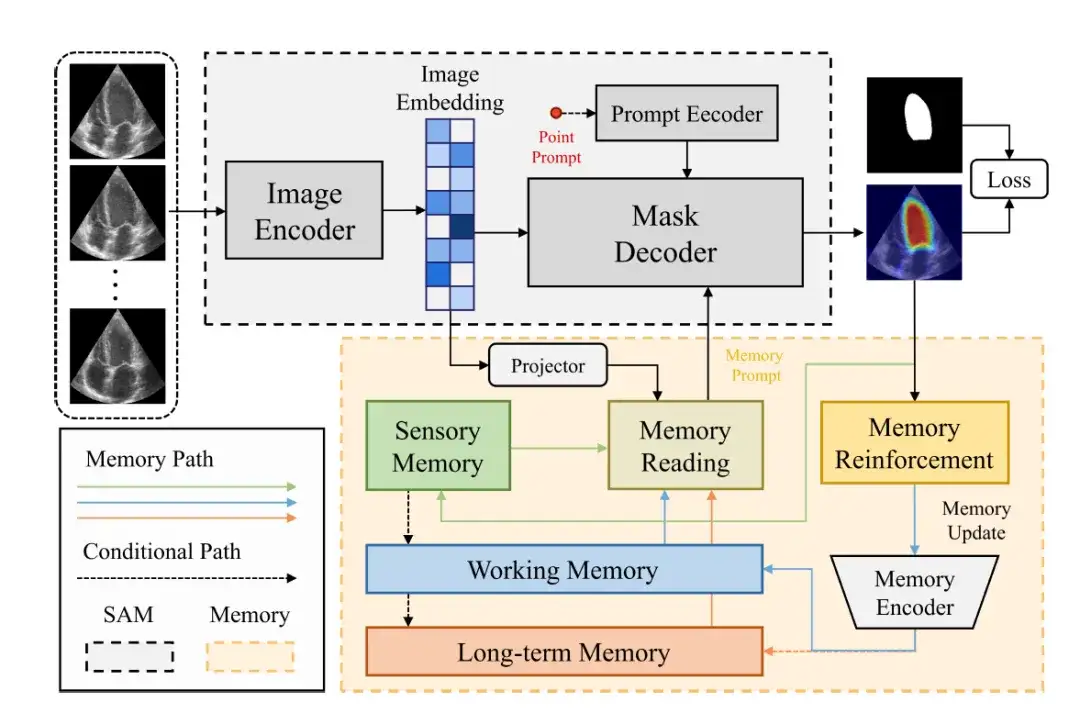
SAM コンポーネントは、元の SAM と同じアーキテクチャを使用します。画像エンコーダー、プロンプトエンコーダー、マスクデコーダーで構成されます。
画像エンコーダーは、入力画像を画像ベクトル (画像埋め込み) にエンコードするバックボーンとして Vision Transformer (ViT) を使用します。
プロンプト エンコーダは、ポイント プロンプト (Point Prompt) などの外部プロンプトを受信し、それらを c 次元ベクトル (c 次元埋め込み) にエンコードします。その後、マスク デコーダが画像ベクトルとキュー ベクトルを組み合わせてセグメンテーション マスクを予測します。
これらのコンポーネントでは、画像ベクトルが投影層 (投影層) を介して記憶特徴空間にマッピングされ、研究者は複数の特徴記憶 (感覚記憶、作業記憶、長期記憶など) から記憶の読み取り (メモリ読み取り) を実行します。 -term メモリ) 長期メモリ) をマスク デコーダに提供します。最後に、Memory Reinforcement と Memory Encoder を通過した後、メモリが更新されます。
次の図は、メモリ読み取り、メモリ拡張、およびメモリ更新 (メモリ更新) プロセスの詳細を示しています。
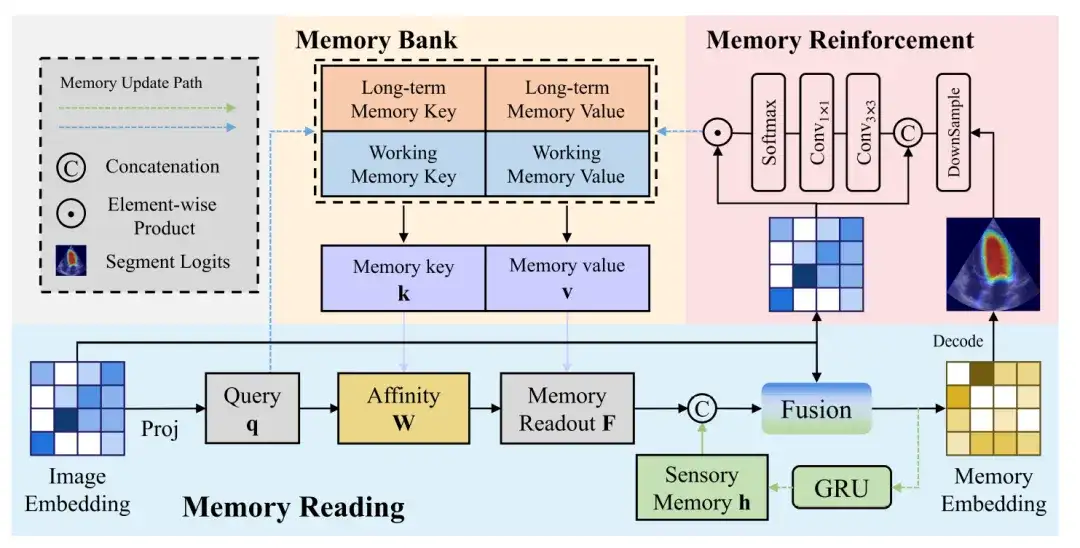
メモリ読み取り
メモリ読み取りブロックは、画像ベクトルからメモリ ベクトルを生成するプロセスを示します。画像ベクトルは射影を通じてクエリ (Query) を生成し、次にメモリ値のアフィニティ (Affinity) をクエリしてメモリ読み出しを取得します。最後に、メモリ読み出しは感覚メモリ (Sensory Memory) および画像ベクトルとマージされて取得されます。メモリベクトル。
記憶力の強化
超音波画像には自然画像よりも複雑なノイズが含まれています。つまり、画像エンコーダによって生成された画像ベクトルには必然的にノイズが含まれます。これらのノイズの多い特徴が何の処理も行わずにメモリに更新されると、エラーの蓄積と伝播につながる可能性があります。
メモリ更新に対するノイズの影響を軽減するには、メモリ拡張モジュールを使用してメモリ内の特徴表現の識別性を強化する必要があります。メモリ強化ブロックは、最初に画像ベクトルと予測確率マップを連結し、次に 3×3 畳み込みを通じて各ピクセルの受容野を制限して、局所的な注意の重み特徴を生成します。
メモリの更新
最後に、メモリ バンクに更新される出力特徴は、Softmax 関数と画像ベクトルのドット積を通じて取得されます。
調査結果: MemSAM は限られたアノテーションで最適なパフォーマンスを実現
MemSAM のパフォーマンスを検証するために、研究者は従来の画像セグメンテーション モデルや医療基本モデルなど、さまざまな種類の比較方法を幅広く選択しました。従来の 3 つの画像セグメンテーション モデルは、CNN ベースの UNet、Transformer ベースの SwinUNet、および CNN と Transformer のハイブリッド H2Former です。医療分野に適した SAM モデルには、MedSAM、MSA、SAMed、SonoSAM、SAMUS などがあります。その中でも、SonoSAMとSAMUSは超音波画像に焦点を当てています。
1 つ目は、以下の表に示す定量的な比較結果です。
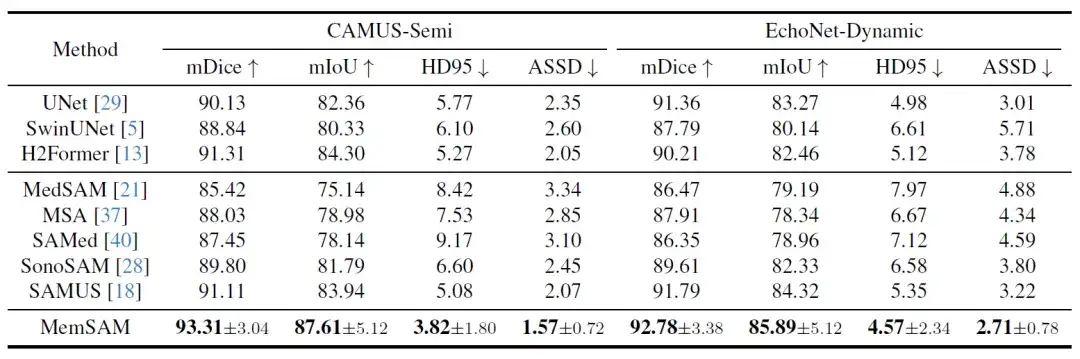
これらの最新の手法の中でも、H2Former と SAMUS は、CNN-Transformer アーキテクチャと超音波画像の最適化により、両方のデータセットで比較的良好なパフォーマンスを発揮します。ただし、アノテーションが少なく、ビデオの時間的属性を利用していない場合、上記のモデルはこの研究で提案した方法よりも遅れています。実験では、MemSAM が限られたアノテーションの下で最高のパフォーマンスを達成することが検証されています。
MemSAM をさらに評価するために、研究者らは同じ設定で CAMUS-Semi と CAMUS-Full データセットも比較しました。結果を以下に示します。
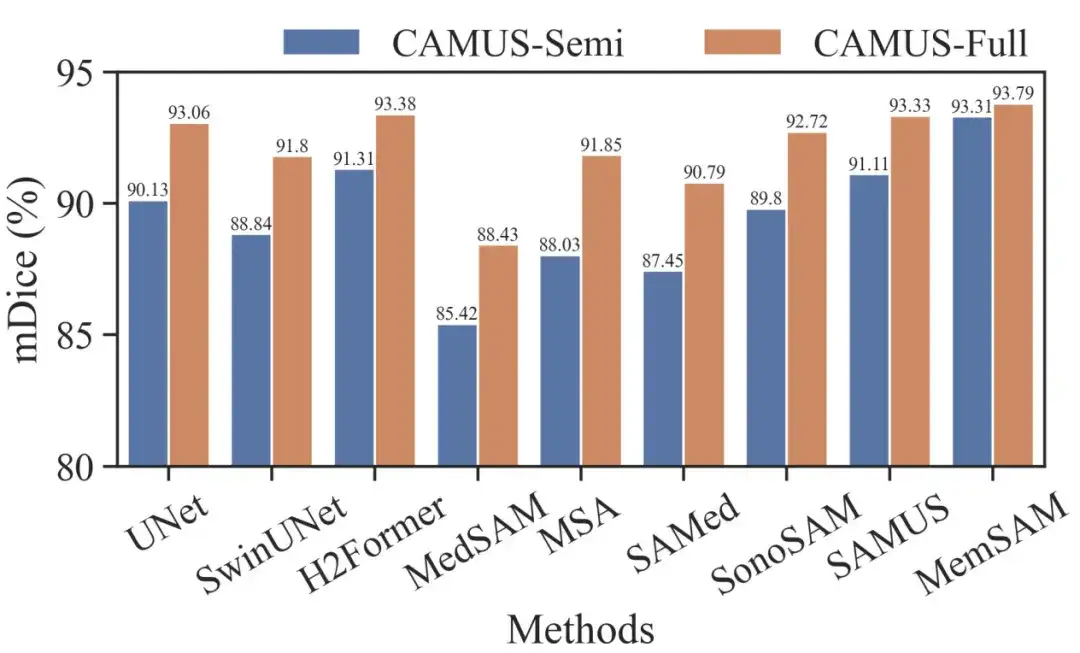
UNet や H2Former などの従来の方法だけでなく、SonoSAM や SAMUS などの超音波に特化した方法でも、完全なアノテーションが与えられた場合に良好なセグメンテーション結果を回復できることがわかります。半教師あり設定から完全教師あり設定への私たちの方法の利得は小さくなりますが、それでもどちらの場合でも他の競合他社よりも優れています。
医療ベース モデルでは完全な監視の下でフレームごとのヒントが必要ですが、MemSAM では 1 つのポイント ヒントのみが必要であることは注目に値します。実験では、この研究で提案された方法が、外部からの手がかりがはるかに少ないまばらなラベルの下で完全なアノテーションに匹敵するパフォーマンスを達成することが検証されています。
次に、以下の図に示すように、研究者はいくつかの困難なケースについて、定性的な比較結果を視覚的に示しています。

上図の行 1 ~ 2 の画像には左心室周囲のスペックル ノイズが含まれており、一部の従来の医学ベースのモデルが心室の端として誤って識別するよう誤解を招いています。行 3 ~ 4 には境界が著しくぼやけている例が含まれており、ほとんどすべての比較モデルでは真の心室境界を超える結果が得られますが、この研究で提案された方法は境界の輪郭を正確に示しています。これらの視覚化の結果は、この研究で提案された方法が画質の悪さに対処する際の堅牢性を示しています。
AI は心血管疾患の予防と治療に新しいアイデアをもたらします
心血管疾患は、冠状動脈性心疾患、脳血管疾患、リウマチ性心疾患、その他の疾患を含む心臓および血管疾患のカテゴリーです。現代社会では、人々の不健康な食事、身体活動の不足、喫煙、アルコール乱用により、心血管疾患のリスクがさらに高まっています。
近年、人工知能やビッグデータなどの技術の発展に伴い、心血管疾患の診断や予測など、AIの開発が急速に進んでいます。心電図や心血管画像データとAIを組み合わせて正確な診断を実現し、心血管画像データやその他の臨床データとAIを組み合わせることで、冠動脈疾患、先天性心疾患、心不全などの心血管疾患の早期スクリーニングやリスク予測を実現します。
たとえば、心血管疾患の早期診断と介入の分野では、心音の正確な分類が鍵となります。人工心音聴診の有効性は依然として医師の専門知識に依存していますが、この状況は静かに変わりつつあります。 2023年11月、中国医学院不外病院(不外病院)の潘祥斌氏のチームは、「バイスペクトル特徴とビジョントランスフォーマーモードに基づく心音分類」と題する研究論文をオンラインのAlexandria Engineering Journalに発表した。この研究では、バイスペクトルにヒントを得た特徴抽出および視覚コンバーター モデルに基づいて心音のバイナリ分類を実装しています。
このモデルは、母集団全体 (妊娠中および非妊娠患者を含む) で優れた分類結果を示し、その診断性能は人間の専門家よりも優れており、大きな応用可能性を示しています。
2023 年 10 月に臨床医学誌に発表された新しい研究データは、石灰化や閉塞などの冠動脈疾患の兆候や過去の心臓発作の証拠を特定することで、ECG-AI が現在のリスク計算ツールよりも優れた性能を発揮できることを示しました。数年前にいくつかのリスクを指摘しました。
つい最近、Caristo Diagnostics という英国の会社が画期的な臨床研究の結果をランセット誌に発表しました。同社の CaRi-Heart AI テクノロジーは、冠動脈炎症の重症度を定量化し、心臓病を正確に予測します。
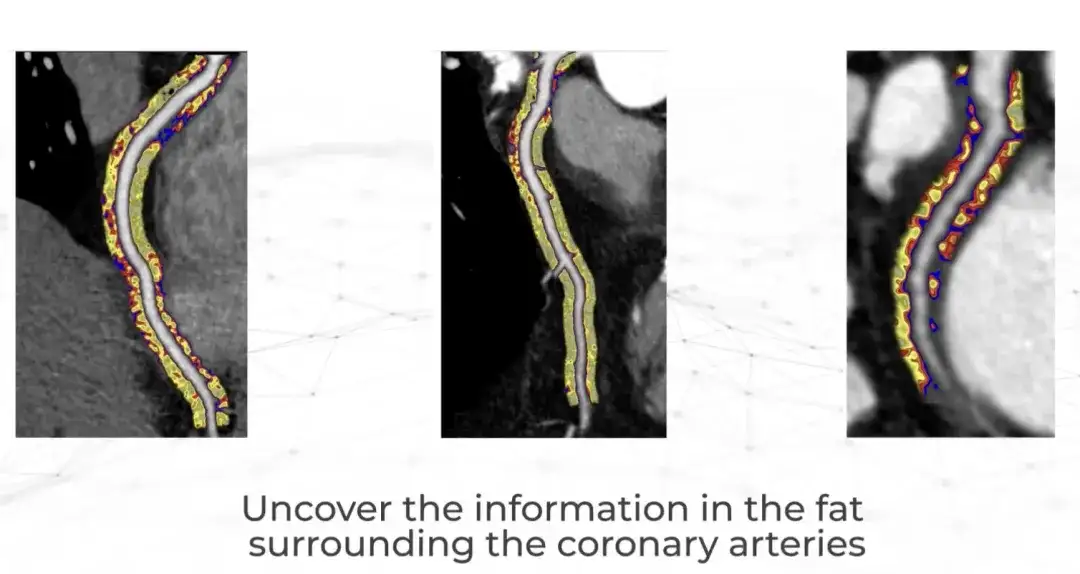
カリストはオックスフォード大学の心臓専門医によって2018年に設立され、50年以上前に心臓発作が冠動脈の炎症によって引き起こされるという大発見を行ったが、臨床医は定期的な心臓検査ではそれを観察できなかった。そして炎症を測定します。そして現在、CaRi-Heart テクノロジーを使用して患者の心臓から血液を抽出できるようになりました。 CTTA スキャン中にこの情報を抽出し、これは、心臓病の予測、予防、管理に対する従来のアプローチを根本的に変える科学的な進歩を示しています。 CaRi-Heart は英国、ヨーロッパ、オーストラリアで臨床使用されていると報告されています。
将来に目を向けると、人工知能は臨床診断と治療、特に心血管疾患の予防と治療において大きな発展の可能性を秘めており、医師が患者に正確な診断とアドバイスをより効率的かつ確実に提供できるようになるでしょう。
参考文献:
1.https://m.chinacdc.cn/jkzt/mxfcrjbhsh/jcysj/201909/t20190906_205347.html
2.https://mp.weixin.qq.com/s/daqoXwnxeZxw7xC6iw1h3A
3.https://www.drvoice.cn/v2/article/12166
4.https://36kr.com/p/280080595174








