Command Palette
Search for a command to run...
メモリ使用量が最大 751 Tp3T 削減されました: 米国エネルギー省の科学者は、非常に大規模なモデルのマルチチャネル データセットの実行を可能にする、クロスチャネル階層集約方式 D-CHAG を提案しました。

ビジョンベースの科学基盤モデルは、多様なソース(例えば、異なる物理観測シナリオ)から画像データを集約し、Transformerアーキテクチャを用いて時空間相関関係を学習する能力を主な理由として、科学的発見とイノベーションを推進する大きな可能性を秘めています。しかし、画像のトークン化と集約には計算コストがかかり、テンソル並列処理(TP)、シーケンス並列処理(SP)、データ並列処理(DP)といった既存の分散手法では、この課題に十分に対処できていません。
この文脈では、米国エネルギー省オークリッジ国立研究所の研究者らは、基本モデルとして分散型クロスチャネル階層集約(D-CHAG)方式を提案した。この手法はトークン化プロセスを分散し、階層的なチャネル集約戦略を採用することで、非常に大規模なモデルをマルチチャネルデータセットで実行することを可能にします。研究者らは、D-CHAGをハイパースペクトルイメージングと天気予報のタスクで評価し、この手法をテンソル並列処理とモデルシャーディングと組み合わせることで、Frontierスーパーコンピュータ上でメモリフットプリントを最大75%削減し、最大1,024基のAMD GPUで2倍以上の持続的なスループット向上を達成できることを発見しました。
「基盤モデルのための分散型クロスチャネル階層集約」と題された関連する研究成果が SC25 で公開されました。
研究のハイライト:
* D-CHAG は、マルチチャネル ベース モデル トレーニングにおけるメモリのボトルネックと計算効率の問題を解決します。
* TP のみを使用する場合と比較して、D-CHAG は最大 70% のメモリ フットプリント削減を実現できるため、より効率的な大規模モデル トレーニングをサポートします。
* D-CHAG のパフォーマンスは、天気予報とハイパースペクトル植物画像マスキング予測という 2 つの科学的ワークロードで検証されました。
用紙のアドレス:
https://dl.acm.org/doi/10.1145/3712285.3759870
弊社の公式 WeChat アカウントをフォローし、バックグラウンドで「cross-channel」と返信すると、完全な PDF を入手できます。
2つの典型的なマルチチャネルデータセットを使用する
この研究では、D-CHAG 法の有効性を検証するために、2 つの典型的なマルチチャネル データセットを使用しました。植物のハイパースペクトル画像と ERA5 気象データセット。
自己教師マスク予測に使用される植物ハイパースペクトル画像データは、オークリッジ国立研究所 (ORNL) の Advanced Plant Phenotyping Laboratory (APPL) によって収集されました。このデータセットにはポプラの木のハイパースペクトル画像が 494 枚含まれており、各画像には 400 nm から 900 nm の波長をカバーする 500 個のスペクトル チャネルが含まれています。
このデータセットは主にバイオマス研究に利用されており、植物のフェノタイピングやバイオエネルギー研究においても重要なリソースとなっています。これらの画像は、画像スライスをマスクのトークンとして用いるマスク付き自己教師学習に用いられます。このモデルのタスクは、欠落コンテンツを予測することで、画像に内在するデータ分布を学習することです。注目すべきは、このデータセットは事前学習済みの重みを一切使用せず、完全に自己教師学習のみで学習されていることです。これは、D-CHAGが多チャネル自己教師学習タスクに適用可能であることを示しています。
また、研究チームは天気予報の実験で、ERA5高解像度再解析データセットを使用しました。本研究では、5つの大気変数(ジオポテンシャル高度、気温、風速U成分、風速V成分、比湿)と3つの地表変数(2メートル気温、10メートル風速U成分、10メートル風速V成分)を選択し、10以上の気圧層をカバーし、合計80の入力チャネルを生成しました。モデル学習に適応させるため、元の0.25°解像度データ(770×1440)は、xESMFツールキットと双線形補間アルゴリズムを用いて5.625°(32×64)に再グラインドされました。
モデルタスクは、500 hPa ジオポテンシャル高度 (Z500)、850 hPa 気温 (T850)、10 m u 成分風速 (U10) などの将来の時間ステップの気象変数を予測し、それによって時系列予測タスクにおける D-CHAG メソッドのパフォーマンスを検証することです。
D-CHAG: 階層的集約と分散トークン化の組み合わせ
つまり、D-CHAG 法は 2 つの独立した方法を融合したものです。
分散トークン化方式
順方向伝播プロセス中、各 TP ランクは入力チャネルのサブセットのみをトークン化します。チャネル集約ステップを実行する前に、全チャネルにわたるクロスアテンションを実現するために、AllGather操作を実行する必要があります。理論的には、この手法によりGPUあたりのトークン化計算のオーバーヘッドを削減できます。
階層的なクロスチャネル集約
このアプローチの主な利点は、レイヤーごとに処理されるチャネルが少なくなるため、クロスチャネル アテンション レイヤーあたりのメモリ フットプリントが削減されることです。ただし、層数を増やすとモデル全体のサイズが大きくなり、メモリ使用量も増加します。標準的なクロスチャネルアテンションでは二次メモリのオーバーヘッドが大きくなるため、このトレードオフはチャネル数の多いデータセットではより有利です。
どちらの手法にも利点がある一方で、いくつかの欠点もあります。例えば、分散トークン化手法はTPランク間の通信オーバーヘッドが大きく、チャネルレベルでのメモリ消費量の増加という問題を解決できません。一方、階層型クロスチャネル集約手法はGPUあたりのモデルパラメータ数を増加させます。D-CHAG手法はこれら2つの手法を分散的に組み合わせたものであり、全体的なアーキテクチャを下図に示します。
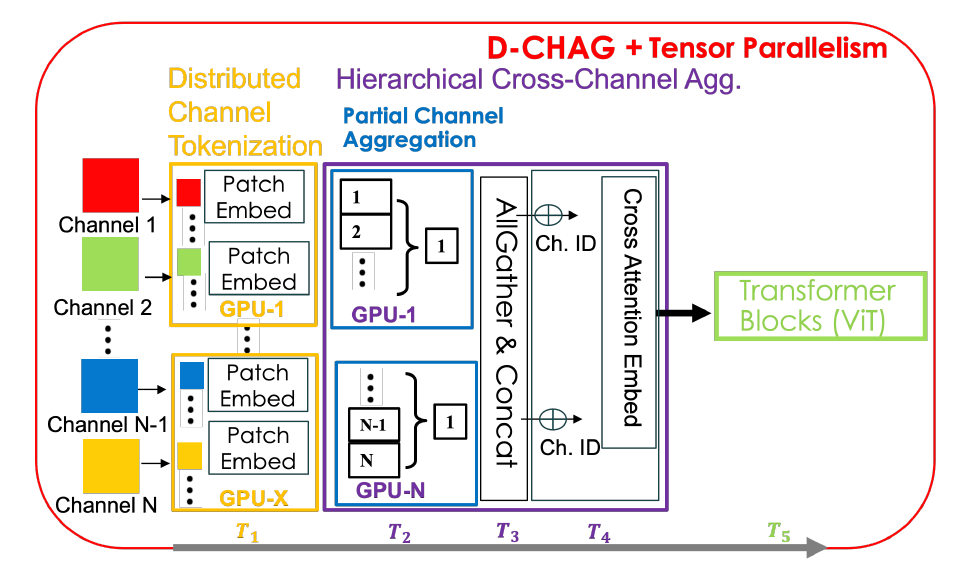
具体的には、各 TP ランクは、合計チャネル サブセット内の 2 次元画像をトークン化します。各GPUは全チャネルのサブセットのみを保持するため、チャネル集約はこれらのチャネル上でローカルに実行されます。このモジュールは部分チャネル集約モジュールと呼ばれます。各TPランク内でチャネル集約が完了すると、出力が収集され、クロスチャネルアテンションを用いて最終的な集約が行われます。順方向伝播中はAllGather演算が1回のみ実行され、逆方向伝播中は各GPUに関連する勾配のみが収集されるため、追加の通信は発生しません。
D-CHAG メソッドは、分散トークン化と階層型チャネル集約の利点を最大限に活用しながら、欠点を軽減できます。研究者らは、階層的なチャネル集約をTPランク全体に分散させることで、AllGather通信をTPランクごとに1つのチャネルの処理のみに削減し、バックプロパゲーション中の通信の必要性を排除しました。さらに、モデルの深度を増やすことで、層あたりのチャネル処理を削減するという利点を維持しながら、追加のモデルパラメータを部分チャネル集約モジュールを通じてTPランク全体に分散させました。
この調査では、2 つの実装戦略を比較しました。
* D-CHAG-L (線形レイヤー): 階層型集約モジュールは線形レイヤーを使用します。線形レイヤーはメモリ使用量が少なく、チャネル数が多い状況に適しています。
* D-CHAG-C (クロス アテンション レイヤー): クロス アテンション レイヤーを使用します。計算コストは高くなりますが、非常に大規模なモデルや非常に高いチャネル数の場合、パフォーマンスが大幅に向上します。
結果: D-CHAG は、高チャネル データセットでの大規模なモデルのトレーニングをサポートします。
D-CHAG を構築した後、研究者らはモデルのパフォーマンスを検証し、ハイパースペクトル画像化と天気予報のタスクにおけるパフォーマンスをさらに評価しました。
モデルパフォーマンス分析
次の図は、さまざまな部分チャネル集約モジュール構成における D-CHAG のパフォーマンスを示しています。
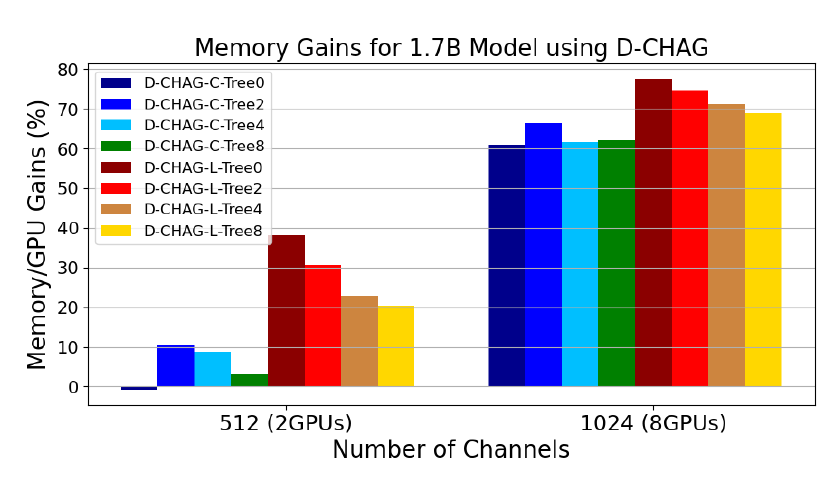
* Tree0 は、一部の集約モジュールに集約レベルが 1 つしかないことを示し、Tree2 は 2 つのレベルがあることを示します。
* サフィックス -C と -L は、使用されるレイヤーのタイプを示します。-C はすべてのレイヤーがクロスアテンションであることを示し、-L はすべてのレイヤーが線形であることを示します。
結果は次のとおりです。
512 チャネル データの場合、単層クロス アテンション レイヤーを使用した場合のパフォーマンスはベースラインよりもわずかに低くなりますが、1024 チャネル データの場合は約 60% パフォーマンスが向上します。
階層構造が深くなるにつれて、512 チャネル データでもパフォーマンスが大幅に向上しますが、1024 チャネル データのパフォーマンスは比較的安定しています。
線形層を使用すると、階層が浅い場合でも、512チャンネルおよび1024チャンネルの画像でパフォーマンスが向上する可能性があります。実際、最高のパフォーマンスは、チャンネル集約層を1つだけ含むD-CHAG-L-Tree0で得られました。集約層を追加すると、モデルパラメータが増加し、メモリオーバーヘッドが増加します。512チャンネルの場合、層数を増やすことは有益であるように見えますが、どちらのチャンネルサイズでも、線形層を1つだけ使用する方が、より深い構成よりも優れたパフォーマンスを発揮します。
D-CHAG-C-Tree0 は 2 つの GPU ではパフォーマンスにわずかに悪影響を及ぼしますが、8 つの GPU に拡張すると 60% のパフォーマンス向上を実現できます。
植物ハイパースペクトル画像の自己教師マスク予測
下の図は、ハイパースペクトル植物画像マスクオートエンコーダへの適用におけるベースライン法とD-CHAG法の学習損失を比較したものです。結果は以下の通りです。トレーニング中、単一 GPU 実装のトレーニング損失パフォーマンスは、D-CHAG メソッド (2 つの GPU で実行) のトレーニング損失パフォーマンスと非常に一致しています。
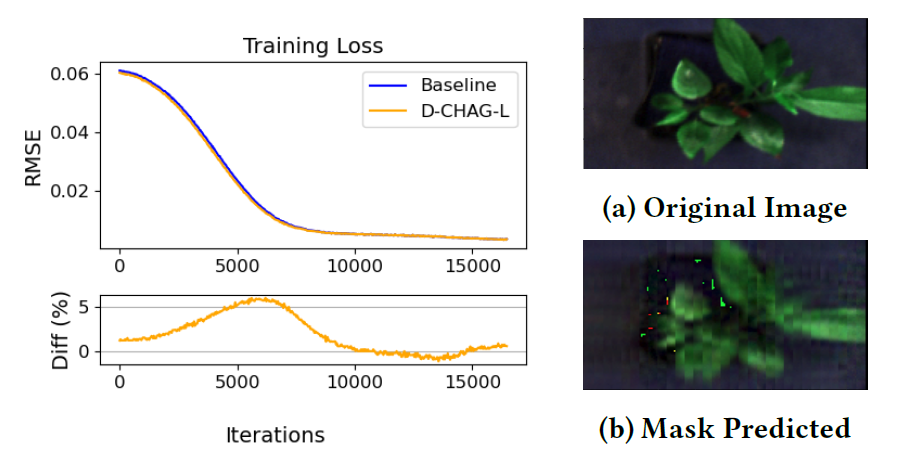
オークリッジ国立研究所の分子細胞イメージンググループの上級研究員ラリー・ヨーク氏は、D-CHAG は、時間と労力を要する手作業による測定に代えて、植物科学者が画像から直接植物の光合成活動を測定するなどの作業を迅速に完了するのに役立つと述べています。
天気予報
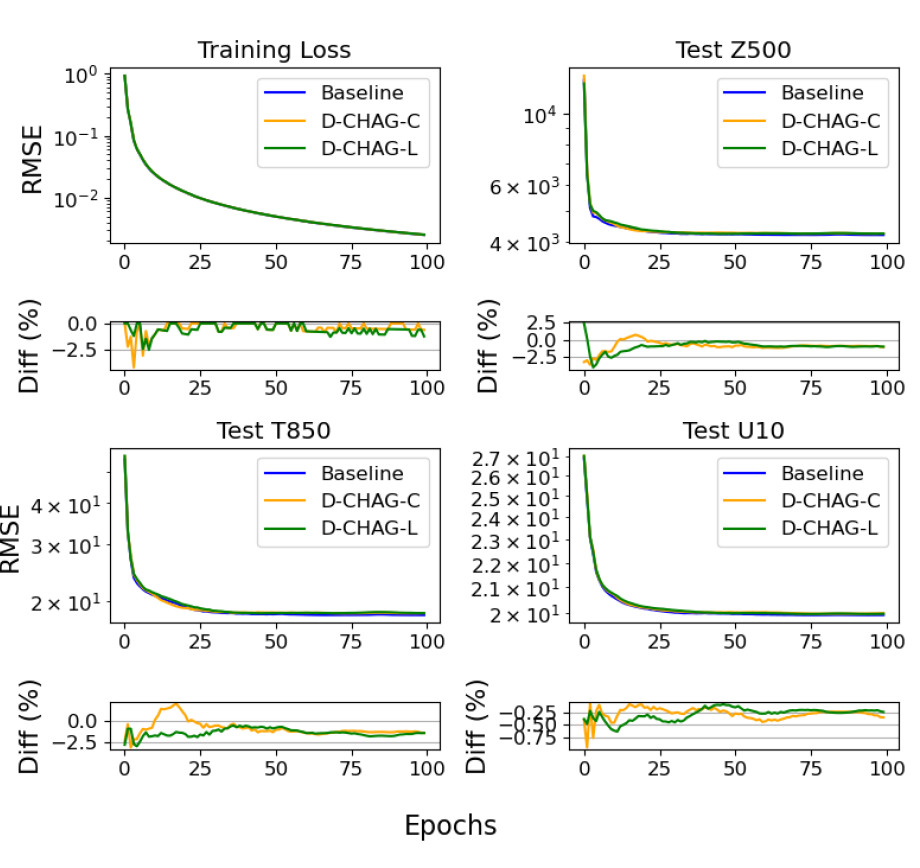
研究者らはERA5データセットを用いて30日間の天気予報実験を実施しました。下の図は、天気予報アプリケーションにおけるベースライン法とD-CHAG法の3つのテスト変数のトレーニング損失とRMSEを比較したものです。
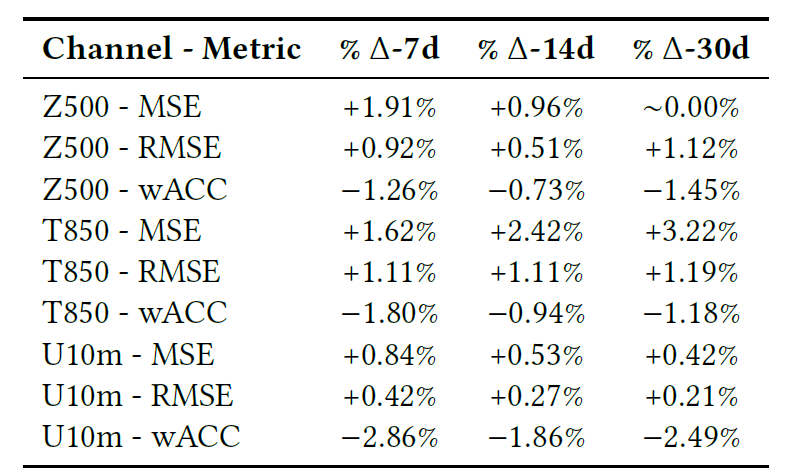
以下の表は、RMSE、MSE、ピアソン相関係数 (wACC) を含む、7 日、14 日、30 日の予測タスクにおけるモデルの最終的な比較を示しています。
全体的に、グラフと表に基づくと、トレーニング損失はベースライン モデルと非常に一致しており、さまざまな指標の偏差は最小限です。
モデルサイズに応じたパフォーマンスのスケーリング
以下の図は、TP を必要とするチャネル構成を持つ 3 つのモデル サイズで、TP のみを使用した場合と比較した D-CHAG メソッドのパフォーマンス向上を示しています。
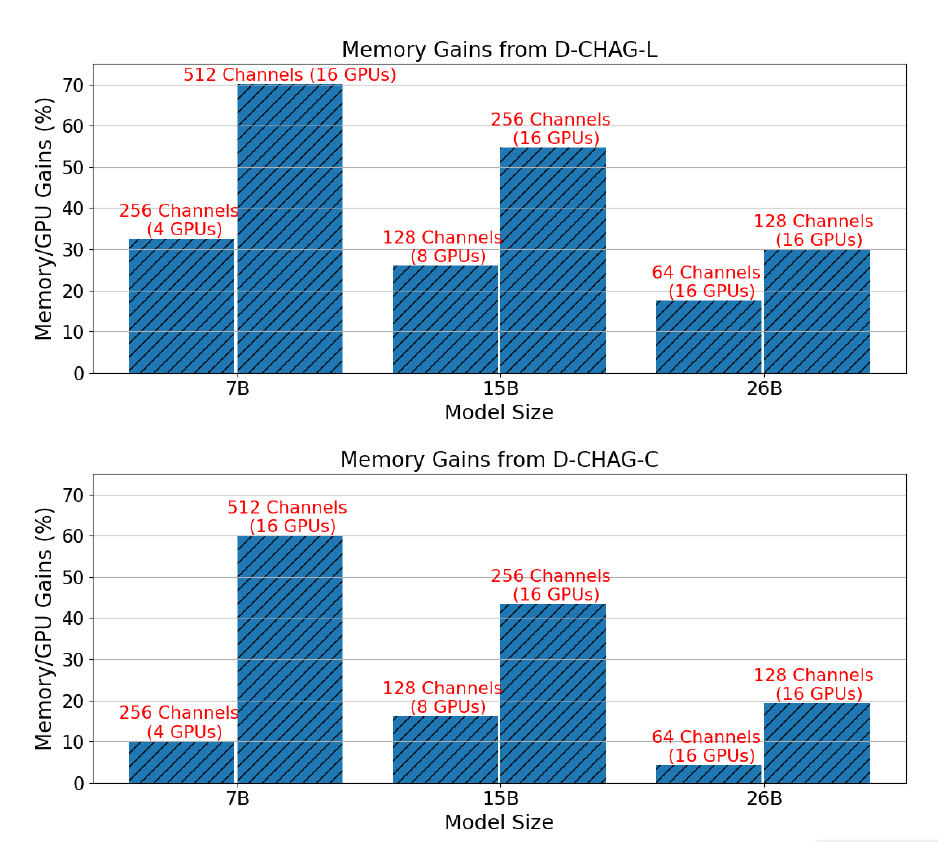
結果は次のようになります。7Bパラメータモデルの場合、部分チャネル集約モジュールで線形レイヤーを使用すると、30% ~ 70% のパフォーマンス向上を実現できます。一方、クロスアテンションレイヤーを使用すると、10% ~ 60% のパフォーマンス向上を実現できます。15Bパラメータモデルの場合、パフォーマンスの向上は 20% を超えて 50% になります。26B パラメータ モデルのパフォーマンス向上は、10% と 30% の間です。
さらに、モデルサイズが固定されている場合、チャネル数が増えるにつれてパフォーマンスの向上がより顕著になります。これは、特定のアーキテクチャでは、チャネル数を増やしてもTransformerブロックの計算コストは増加しませんが、トークン化モジュールとチャネル集約モジュールのワークロードが増加するためです。
一方、TP だけでは 26 個のパラメータと 256 個のチャネルを持つ画像をトレーニングすることはできませんが、D-CHAG メソッドでは 80% 未満の使用可能メモリを使用して 26 個のパラメータと 512 個のチャネルを持つモデルをトレーニングできます。これは、このメソッドが高チャネル データセットでの大規模なモデルのトレーニングをサポートできることを示しています。
ViT: ビジュアルAI - 知覚モデルから汎用ビジュアル基盤モデルまで
過去10年間、コンピュータビジョンモデルは主に「単一タスク最適化」を中心に展開され、分類、検出、セグメンテーション、再構成はそれぞれ独立して発展してきました。しかし、Transformerアーキテクチャが自然言語処理分野においてGPTやBERTといった基礎モデルを生み出したように、ビジョン分野でも同様のパラダイムシフトが起こっています。つまり、タスク特化型モデルから汎用的なビジョン基礎モデルへと移行しているのです。この潮流において、Vision Transformer (ViT)はビジョン基礎モデルの重要な技術的礎石と考えられています。
Vision Transformer (ViT) は、Transformer アーキテクチャをコンピュータービジョンのタスクに本格的に導入した最初の研究です。ViT の核となるアイデアは、画像をパッチトークンのシーケンスとして扱い、畳み込みニューラルネットワークの局所受容野モデリングを自己注意メカニズムに置き換えることです。具体的には、ViT は入力画像を固定サイズのパッチに分割し、各パッチを埋め込みトークンにマッピングします。そして、Transformer Encoder を用いてパッチ間のグローバルな関係性をモデル化します。
従来の CNN と比較して、ViT は科学データに対して特に有利です。高次元のマルチチャネル データ (リモート センシング、医療画像、スペクトル データなど) に適しており、非ユークリッド空間構造 (気候グリッドや物理場など) を処理でき、D-CHAG 論文で取り上げられている中核的な問題でもあるクロス チャネル モデリング (異なる物理変数間の関係の結合) に適しています。
上記の研究で言及されたシナリオ以外にも、ViTはさらに多くのシナリオでそのコアバリューを発揮しています。2025年3月、北京大学国際病院皮膚科主任医師の韓剛文医師と彼のチームは、AcneDGNetと呼ばれるディープラーニングアルゴリズムを開発しました。このアルゴリズムは、Visual Transformerと畳み込みニューラルネットワークを統合し、より効率的な階層的特徴テーブルを取得し、より正確なグレーディングを実現します。前向き評価では、AcneDGNetのディープラーニングアルゴリズムは、ジュニア皮膚科医よりも正確であるだけでなく、シニア皮膚科医に匹敵することが示されています。このアルゴリズムは、さまざまな医療シナリオでニキビ病変を正確に検出し、その重症度を判定できるため、オンライン相談とオフラインの診察の両方で、皮膚科医と患者がニキビを診断および管理するのに効果的に役立ちます。
論文のタイトル:
オンラインおよびオフラインのヘルスケアシナリオにおける中国人集団のニキビ病変検出および重症度評価モデルの評価
用紙のアドレス:
https://www.nature.com/articles/s41598-024-84670-z
業界の観点から見ると、Vision Transformerは、視覚AIが知覚モデルから汎用的な視覚基盤モデルへと進化する上で、重要な転換点となります。統合されたTransformerアーキテクチャは、クロスモーダル融合、スケーラブルな拡張、そしてシステムレベルの最適化のための普遍的な基盤を提供し、視覚モデルをAI for Scienceの中核インフラとしています。将来的には、ViTを取り巻く並列化、メモリ最適化、そしてマルチチャネルモデリング機能が、視覚基盤モデルの産業展開のスピードと規模を左右する重要な競争要因となるでしょう。
参考文献:
1.https://phys.org/news/2026-01-empowering-ai-foundation.html
2.https://dl.acm.org/doi/10.1145/3712285.3759870
3.https://mp.weixin.qq.com/s/JvKQPbBQFhofqlVX4jLgSA








