Command Palette
Search for a command to run...
実践体験 | HyperAIクラウドコンピューティングプラットフォームに基づく要素ごとの演算子最適化の実践
HyperAI コンピューティング プラットフォームが正式にリリースされ、開発者に非常に安定したコンピューティング サービスを提供し、すぐに使用できる環境、コスト効率の高い GPU 価格設定、豊富なオンサイト リソースを通じてアイデアの実現を加速します。
以下は、プラットフォームに基づいて要素ごとの演算子を最適化するHyperAIユーザーの経験の共有です⬇️
イベントについてのちょっとしたお知らせです!
HyperAIベータテストプログラムは現在も募集中です。最大$200のインセンティブをご用意しています。プログラムの詳細については、こちらをクリックしてください。最大$200もらえる!HyperAIベータテスト募集正式開始!
主な目的:単純な要素単位の加算演算子 (C = A + B) を基本実装から最適化して、PyTorch のネイティブ パフォーマンスに近づきます (つまり、ハードウェアのメモリ帯域幅の制限に近づきます)。
主な課題:Elementwise は典型的なメモリバインド演算子です。
- 計算能力はボトルネックではありません (GPU は驚くほど高速に加算を実行します)。
- ボトルネックとなるのは、「命令発行側」と「ビデオメモリ転送側」の需給バランスです。
- 最適化の本質は、最小の命令で最大のデータ (バイト) を移動することです。
実験環境と計算能力の準備
Elementwise演算子の最適化は、GPUメモリ帯域幅の物理的な限界にまで達します。最も正確なベンチマークデータを取得するために、この実践的な演習はHyperAI(hyper.ai)のクラウドコンピューティングプラットフォームで実施しました。演算子のパフォーマンスを最大限に引き出すために、特に高スペックのインスタンスを選択しました。
- GPU: NVIDIA RTX 5090(32GB VRAM)
- ラム: 40GB
- 環境: PyTorch 2.8 / CUDA 12.8
ボーナスタイム: RTX 5090 を体験し、この記事のコードを再現したい場合は、app.hyper.ai の登録時に私の専用引き換えコード「EARLY_dnbyl」を使用して、5090 のコンピューティング パワーを 1 時間無料で受け取ることができます (有効期間は 1 か月です)。
RTX 5090インスタンスを素早く起動する
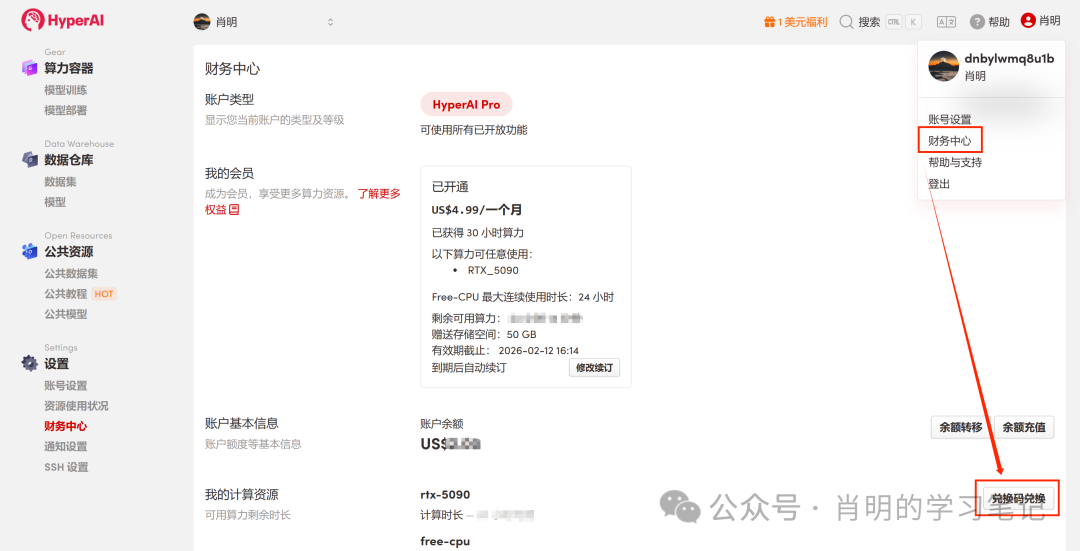
1. 登録とログイン: app.hyper.ai でアカウントを登録した後、右上隅の「金融センター」をクリックし、「コードを引き換える」をクリックして「EARLY_dnbyl」と入力すると、無料のコンピューティング能力を受け取ることができます。
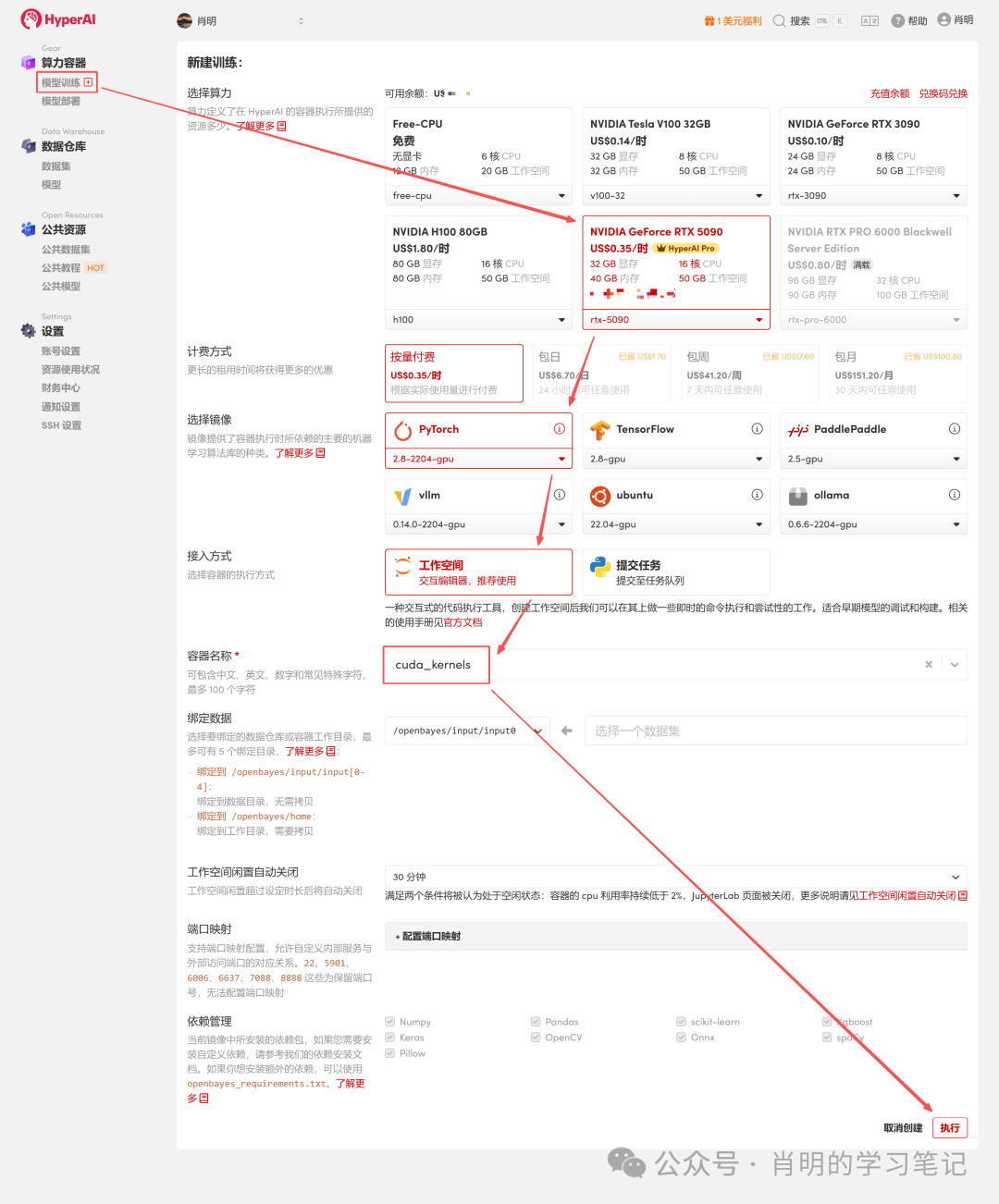
2. コンテナを作成します。左側のサイドバーで「モデルトレーニング」をクリック -> 「コンピューティングパワーを選択: 5090」 -> 「イメージを選択: PyTorch 2.8」 -> 「アクセス方法: Jupyter」 -> 「コンテナ名: cuda_kernels など、任意の名前を入力」 -> 「実行」。
3. Jupyter を開く: インスタンスが起動したら (ステータスが「実行中」に変わります)、「ワークスペースを開く」をクリックするだけですぐに使用できます。
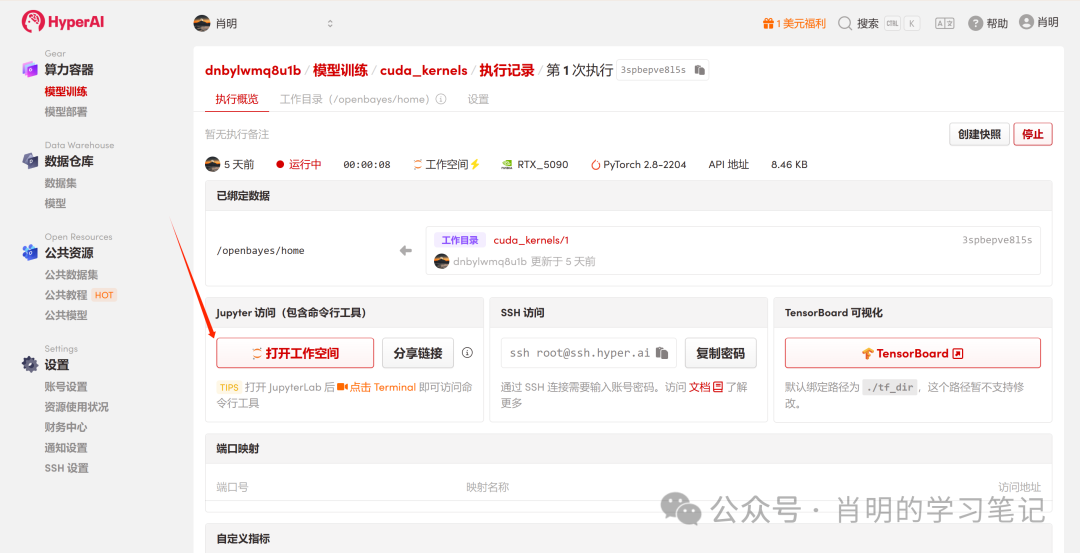
このプラットフォームは、Jupyter または VS Code SSH リモートを使用した接続をサポートしています。私は Jupyter を使用しており、最初のセルで以下のコマンドを実行しました。
import os
import torch
from torch.utils.cpp_extension import loadフェーズ1: FP32最適化シリーズ
バージョン 1: FP32 ベースライン (スカラー バージョン)
これは最も直感的な記述方法ですが、GPU の観点から見ると効率はまあまあです。
原則の詳細な分析:
- コマンドレイヤー:スケジューラは 1 つの LD.E (32 ビット ロード) 命令を発行します。
- 実行層(ワープ)SIMT 原則によれば、ワープ内の 32 個のスレッドすべてがこの命令を同時に実行します。
- データ量:各スレッドは4バイトを移動します。合計データ量 =32スレッド × 4バイト = 128バイト 。
- メモリトランザクション:LSU (ロード ストア ユニット) は、これらの 128 バイトを 1 つのビデオ メモリ トランザクションに結合します。
- ボトルネック分析:メモリマージは活用されているものの、命令効率は低い。128バイトのデータを転送するには、SM(ストリーミングマルチプロセッサ)は1命令発行サイクルを消費する必要がある。データ量が膨大になると、命令発行ユニットが過負荷になり、ボトルネックとなる。
コード(v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}バージョン2: FP32x4 ベクトル化
最適化方法: float4 型を使用して、128 ビットのロード命令の生成を強制します。
原則の詳細な分析(コア最適化ポイント):
- コマンドレイヤー:スケジューラは 1 つの LD.E.128 (128 ビット ロード) 命令を発行します。
- 実行層(ワープ):ワープでは 32 個のスレッドが同時に実行されますが、今回は各スレッドが 16 バイト (float4) を移動します。
- データ量:総データ量 = 32 スレッド x 16 バイト = 512 バイト。
- メモリトランザクション:LSU は 512 バイトの連続した要求を検出すると、4 つの連続した 128 バイトのメモリ トランザクションを開始します。
- 効率比較:ベースライン: 1 命令 = 128 バイト。ベクトル化: 1 命令 = 512 バイト。
- 結論は:指導効率が4倍向上します。 SMでは、同じメモリ帯域幅を最大限に活用するために必要な命令数は、元の4分の1にまで減少します。これにより、命令ディスパッチユニットが完全に解放され、ボトルネックがメモリ帯域幅へと移行します。
コード(v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");フェーズ2: FP16最適化シリーズ
3. バージョン3: FP16 ベースライン (半精度スカラー)
ビデオメモリを節約するために半分(FP16)を使用します。
基礎となる原理の詳細な分析 (なぜこんなに遅いのか?):
- メモリアクセスモード:コードでは idx が連続しているので、32 スレッドによるアクセスが完全にマージされます。
- データ量:32 スレッド × 2 バイト = 64 バイト (1 つのワープに対する合計リクエスト数)。
- ハードウェアの動作:メモリコントローラ(LSU)は、2つの32バイトメモリセクタートランザクションを生成します。注:ここでは帯域幅が無駄にされることはなく、送信されるデータはすべて有効です。
本当のボトルネック:
1. 命令の境界:
これが根本的な理由です。ビデオメモリの帯域幅を埋めるためには、データを継続的に移動させる必要があるのです。このバージョンでは、 1 つの命令で移動できるのは 64 バイトだけです。float4 バージョン (命令ごとに 512 バイトを移動) と比較すると、このバージョンの命令効率はわずか 1/8 です。
の結果としてSMの命令ディスパッチャがフルスピードで動作しているときでも、発行される命令が運ぶデータ量は、膨大なビデオメモリ帯域幅を十分に活用できません。まるで、監督が声を枯らして叫んでいる(命令を発行している)のに、作業員が十分な量のレンガ(データ)を動かせていないようなものです。
2. メモリトランザクションの粒度が小さすぎる:
* 物理層:ビデオ メモリ転送の最小単位は 32 バイトのセクターです。キャッシュ レイヤーは通常、128 バイトのキャッシュ ライン単位で管理されます。
* 現状:Warp によって要求された 64B のデータは 2 つのセクターを埋めましたが、128B のキャッシュ ラインの半分しか使用されませんでした。
* の結果として:この「小売型」の小パケットデータ転送は、float4で行われるような4つのキャッシュライン(512B)を一度に転送する「卸売型」転送と比較して、このスループットでは非常に非効率であり、ビデオメモリの高いレイテンシを隠蔽することもできません。ビデオメモリの帯域幅を埋めるには、データを継続的に転送する必要があります。
コード(v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4.バージョン4: FP16ベクトル化(Half2)
半分紹介2。
原則の詳細な分析:
- データ:half2(4バイト)。
- コマンドレイヤー:32 ビットのロード コマンドを発行します。
- コンピューティング層:__hadd2 (SIMD) を使用すると、1 つの命令で 2 つの加算を同時に実行できます。
- 現状:メモリアクセス効率はFP32ベースラインと同等(1命令 = 128バイト)。V3よりは高速ですが、float4のピークである512バイト/命令には達していません。
コード(v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}ハイパー Jupyter の実行サンプルについては、付録を参照してください。
5. バージョン5: FP16x8 アンロール(手動ループアンロール)
パフォーマンスをさらに調査するために、1 つのスレッドで 8 つの半分 (つまり、4 つの half2) を処理するようにしました。
基礎となる原則の詳細な分析 (V4 と比較して改善された点はどこでしょうか?):
- 練習する:コード内に、half2 読み取り操作の連続する 4 行を手動で記述します。
- 効果:スケジューラは 4 つの 32 ビット ロード コマンドを連続して発行します。
- 所得:ILP (命令レベルの並列性) とレイテンシ マスキング。 V4 (FP16x2) の問題:1つの命令を発行 -> データが返されるのを待つ(ストール) -> 計算を実行する。待機期間中、GPUは何も行いません。 V5 の改良点:4つの命令を連続して発行します。GPUがメモリから最初のデータが返されるのを待っている間に、既に2番目、3番目、4番目の命令を発行しています。これにより、命令パイプラインのギャップが最大限に活用され、メモリレイテンシのコストが隠蔽されます。
- 制限事項:命令密度は依然として非常に高いままです。ILPが利用されていたにもかかわらず、実質的には4つの32ビット「カートトランスポート」が開始されました。128ビットのデータを転送するために、SMは依然として4つの命令発行サイクルを消費しました。命令発行側は非常にビジー状態のままで、「1つの命令で山を動かす」という効果は達成できませんでした。
コード(v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}ハイパー Jupyter の実行サンプルについては、付録を参照してください。
バージョン 6: FP16x8 パック (究極の最適化)
これが要素単位の演算子最適化の限界です。V2の「高帯域幅トランスポート」とV5の「命令レベル並列性」を組み合わせ、レジスタキャッシュ技術を導入しました。
コアマジックの詳細な分析:
1. 住所のなりすまし:
* 質問:データは half タイプであり、GPU にはネイティブの load_8_halfs 命令がありません。
* 対策: float4 型は正確に 128 ビット (16 バイト) を占有し、8 つの半分も 128 ビットを占有します。
* 操作:半分の配列のアドレス (reinterpret_cast) を強制的に float4* にキャストします。
* 効果:コンパイラは `float4*` を見つけると、1 行を生成します。 LD.E.128 手順。ビデオメモリコントローラは、何を移動しているかを気にしません。一度に 128 ビットのバイナリストリームのみを移動します。
2. レジスタ配列:
half pack_a[8]: この配列はカーネル内で定義されていますが、固定サイズで非常に小さいため、コンパイラは低速なローカルメモリではなく、GPUのレジスタファイルに直接マッピングします。これは、高速キャッシュを「手持ち」で確保するのと同等です。
3. 記憶の再解釈:
マクロ定義 LDST128BITS:これがコードの核心です。任意の変数のアドレスをfloat4*にキャストし、その値を取得します。
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* 右側:グローバルメモリa[idx]に移動し、128ビットのデータを取得します。
* 左この 128 ビットのデータを pack_a 配列に直接書き込みます (0 番目の要素から開始し、8 つの要素すべてを即座に埋めます)。
* 結果:1 つの命令で 8 つのデータ項目の転送が瞬時に完了します。
コード(v6_f16x8_パック.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}フェーズ3: ベンチマークと視覚分析を組み合わせる
最適化の効果を総合的に評価するために、レイテンシに敏感なシナリオ (小さなデータ) から帯域幅に敏感なシナリオ (大きなデータ) までをカバーする完全なシナリオ テスト プランを設計しました。
1. テスト戦略設計
GPU メモリ レベルでの異なるボトルネックに対応する 3 つの代表的なデータセットを選択しました。
- キャッシュレイテンシ(100万要素):データ サイズが非常に小さく (4 MB)、L2 キャッシュが完全にヒットします。テストの中核は、カーネル起動のオーバーヘッドとコマンド発行の効率です。
- L2スループット(16M要素):データ サイズは中程度 (64 MB) で、L2 キャッシュの容量制限に近いです。テストの中核は、L2 キャッシュの読み取りおよび書き込みスループットです。
- VRAM帯域幅(256M要素):データ量が非常に大きく(1GB)、L2キャッシュをはるかに超えているため、ビデオメモリ(VRAM)からデータを移動する必要があります。これは大規模事業者にとっての本当の戦場であり、物理メモリ帯域幅が最大限に活用されているかどうかが重要なテストとなります。
2. ベンチマークスクリプト(Python)
スクリプトは、上記で定義した .cu ファイルを直接読み込み、帯域幅 (GB/秒) とレイテンシ (ミリ秒) を自動的に計算します。
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. 実世界データ: RTX 5090のパフォーマンス
以下は、上記のコードを NVIDIA GeForce RTX 5090 で実行して得られた実際のデータです。
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. データ解釈
このデータは、さまざまな負荷下での RTX 5090 の物理的特性を明確に示しています。
フェーズ 1: 非常に小規模 (100 万要素 / 4 MB)
- 現象:すべてのバージョンで実行時間は 0.0041 ミリ秒と非常に安定していました。
- 真実:これはレイテンシ制限のある状況です。データサイズに関わらず、GPUがカーネルを起動するための起動オーバーヘッドは約4マイクロ秒に固定されています。この時間制限のため、FP16のデータ量はFP32の半分になり、計算される帯域幅も当然半分になります。ここで測定されているのは伝送速度ではなく、「起動速度」です。
フェーズ2: 中サイズ (16M 要素 / 64MB vs 32MB)
これは、L2 キャッシュの機能を最もよく示す領域です。
- FP32(64MB):データ量(A+B+C)の合計は192MBです。これはRTX 5090のL2キャッシュ容量(約128MB)を超えています。データオーバーフローにより、システムはVRAMへの読み書きを余儀なくされ、帯域幅は1700GB/秒(ビデオメモリの物理帯域幅に近い値)まで低下しました。
- FP16(32MB):合計データ量。L2 キャッシュにぴったりフィットします。 データはキャッシュ内を循環し、帯域幅が 2890 GB/秒に急増します。
- PyTorchのダークマジック:PyTorchはFP16で6815GB/秒を達成したことに注目してください。これは、純粋なキャッシュシナリオにおいて、JITコンパイラの命令パイプライン最適化が単純な手書きカーネルよりも優れていることを示しています。
フェーズ3:大規模(268M要素/1024MB)
これは、大規模なモデル (メモリ境界) を使用したトレーニング/推論の実際のシナリオです。
- すべての存在は平等である。FP32 でも FP16 でも、ベースラインでも最適化でも、帯域幅はすべて 1570 ~ 1580 GB/秒に固定されます。
- 物理的な壁:RTX 5090のGDDR7メモリ帯域幅の物理的限界に到達しました。帯域幅には限りがあり、これ以上増加させることはできません。
- 最適化の価値:帯域幅は同じままです。しかし、FP16 時間 (1.02ms) は FP32 時間 (2.04ms) の半分しかないことがわかりました。帯域幅を最大化しながらデータ量を半分にすることで、エンドツーエンドの加速が 2 倍になります。 V6対V3V3はフル稼働しているように見えますが、これはNVCCコンパイラによる自動最適化とGPUハードウェアレイテンシマスキングによるものです。ただし、より複雑な演算子(FlashAttentionなど)では、V6実装によってパフォーマンスが保証されます。
コアFAQ: パラメータ設計のハードコアな導出
この実験のすべてのカーネルで、パラメータを全会一致で threads_per_block = 256 に設定しました。この数値はランダムに選択されたものではなく、ハードウェアの制限とスケジューリング効率の間の数学的に最適なソリューションです。
Q: threads_per_block が常に 128 または 256 に設定されているのはなぜですか?
A: 4 層のスクリーニングを経て得られた「ゴールデンレンジ」です。
block_size の選択プロセスを漏斗として捉え、レイヤーごとにフィルタリングします。
1. ワープアライメント -> 32の倍数である必要があります
GPU における最小の実行単位はワープ (スレッド バンドル) であり、これは 32 個の連続したスレッドで構成されます (SIMT アーキテクチャ、単一命令マルチスレッド)。
- ハード制限:31 個のスレッドを要求した場合でも、ハードウェアは 1 つの完全なワープをスケジュールします。残りのスレッド位置はアイドル状態ですが、同じハードウェアリソースを占有します。
- 結論は: 計算能力の無駄を避けるために、block_size は理想的には 32 の倍数にする必要があります。
2. 占有階数 -> 96以上である必要があります
占有率 = SM で現在実行中の同時スレッド数 / SM でサポートされるスレッドの最大数。
- 背景:メモリレイテンシをマスクするには、十分な数のアクティブなワープが必要です。ブロックサイズが小さすぎると、SMの「最大ブロック数」制限が「最大スレッド数」制限に達する前に達してしまいます。
- 推定:主流のアーキテクチャ(Turing/Ampere/Adaなど)では通常、block_size > (SM内の最大スレッド数 / SM内の最大ブロック数) という値が必要です。一般的な比率は64または96です。
- 結論は:理論的に 100% の占有率を達成するには、ブロック サイズは 96 未満であってはなりません。
3. スケジューリングのアトミック性 -> ロック 128, 256, 512
ブロックは、SMにスケジュールされる最小のアトミック単位です。SMは整数個のブロックを完全に消費できる必要があります。
- 割り切れるかどうか:SM の容量の無駄を避けるには、block_size が SM の最大スレッド容量で割り切れることが理想的です。
- フィルター:主流アーキテクチャの SM の最大容量は、通常 1024、1536、2048 などです。それらの公約数は通常 512 です。前の 2 つのステップ (>=96 かつ 32 の倍数) を組み合わせると、候補リストは 128、192、256、384、512 に絞り込まれます。
4. 圧力を登録 -> 512以上を除外
これが最終的な「天井」です。
- ハード制限:各ブロックで使用できるレジスタの合計数は制限されています (SM 内のレジスタの合計数は通常 64K 32 ビットです)。
- リスク:block_size が大きい場合 (たとえば 512)、カーネルが少し複雑 (各スレッドが複数のレジスタを使用する) な場合は、512 * Regs/Thread > Max_Regs_Per_Block という状況が発生します。
- の結果として:起動に失敗しました: 直接的なエラー メッセージ。レジスタ スピル: レジスタが低速のローカル メモリにオーバーフローし、パフォーマンスのカスケードを引き起こします。
- 結論は:安全上の理由から、通常は 512 または 1024 の使用は避けます。 128 と 256 は最も安全な「砂漠エリア」です。
要約する
4 回の敗退を経て、残った出場者は 2 人だけになりました。
- 128最も汎用性が高いです。複雑なカーネル(多くのレジスタを使用)でも、正常な起動と良好な占有を保証できます。
- 256:要素ごとの演算子が推奨される要素単位のような単純な演算子の場合、レジスタの負荷は最小限です。256 は 128 よりもメモリ結合の可能性が高く、ブロック スケジューリングのオーバーヘッドが削減されます。
これは、単純な実装において、threads_per_block = 256 を決定すると、grid_size も決定される理由も説明しています (合計量が N をカバーする限り)。
付録: Jupyter 実行例









