Command Palette
Search for a command to run...
Les Emojis peuvent-ils Contrôler La Génération De La Parole ? Irodori-TTS Est Un Système De Synthèse Vocale Japonais Basé Sur L’architecture RF-DiT ; Ensembles De Données Sur L’eczéma Et La Teigne : Soutien À La Classification D’images Médicales Et À L’apprentissage Par transfert.

Irodori-TTS, un projet open-source publié par le développeur Aratako en 2026, est une nouvelle génération de synthèse vocale japonaise et un modèle de clonage zéro-shot qui combine une qualité audio haute fidélité avec une grande facilité d'utilisation.Son modèle de base, l'Irodori-TTS-500M-v3, avec 500 millions de paramètres, est basé sur l'espace latent DACVAE continu et l'architecture RF-DiT, qui peut produire de manière stable un son de qualité professionnelle à 48 kHz tout en assurant une efficacité de calcul.Dans les applications pratiques, le modèle a réalisé deux avancées majeures : premièrement, il permet un « clonage vocal sans échantillon » extrêmement rapide, où les utilisateurs n’ont besoin de fournir que 3 à 10 secondes d’audio de référence pour reproduire fidèlement le timbre cible sans aucun réglage fin ; deuxièmement, il permet un « contrôle de style multidimensionnel », qui combine des annotations Emoji innovantes avec une prédiction automatique de la durée pour obtenir un réglage fin des émotions, du ton et des expressions non verbales subtiles.
Le site web d'HyperAI propose désormais « Irodori-TTS-500M-v3 : Synthèse vocale japonaise et contrôle du style emoji ». Essayez-le !
Utilisation en ligne :https://go.hyper.ai/pFPM5
Aperçu rapide des mises à jour du site web hyper.ai du 27 juin au 3 juillet :
* Jeux de données publics de haute qualité : 4
* Une sélection de tutoriels de haute qualité : 12
* Analyse d'un article de la communauté : 1 article
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données sur les maladies de la peau comme l'eczéma et la teigne
Le jeu de données Eczema and Tinea Skin Disease est un ensemble d'images médicales consacré aux maladies de la peau telles que l'eczéma et la teigne. Il vise à fournir un support de données plus concis et pratique pour les tâches de classification d'images binaires et est largement utilisé dans la classification d'images de maladies de la peau, l'entraînement et l'évaluation de modèles d'apprentissage profond, la recherche sur l'apprentissage avec peu d'exemples et l'apprentissage par transfert, ainsi que dans l'enseignement et les expériences d'analyse d'images médicales. Ce jeu de données contient 2 147 images de maladies de la peau.
Utilisation en ligne :https://go.hyper.ai/nheob
2. Ensemble de données SASH-VPV pour la reconnaissance des veines palmaires sous-cutanées
SASH-VPV est un jeu de données de référence biométrique proche infrarouge basé sur les veines de la paume, destiné à la reconnaissance biométrique et à la recherche en vision par ordinateur. Il vise à étudier l'authentification d'identité à partir des structures veineuses sous-cutanées de la paume et est largement utilisé dans le développement de systèmes biométriques, l'entraînement de modèles d'apprentissage profond et les recherches sur la robustesse inter-sessions.
Utilisation en ligne :https://go.hyper.ai/B9xrr

3. Ensemble de données ultime pour la classification des animes
Ultimate Anime, publié en 2026, est un ensemble de données de notation et de classification d'anime conçu pour faciliter la création de systèmes de recommandation d'anime, la visualisation des données d'analyse exploratoire des données (EDA) et l'analyse comparative des tendances à long terme et de la popularité dans l'industrie de l'animation japonaise. Cet ensemble de données contient des informations multidimensionnelles provenant de 3 994 œuvres d'anime issues des bases de données AniList et MyAnimeList, telles que le titre, le genre, la note de la communauté AniList, le nombre total d'épisodes, le statut de diffusion, l'année, le synopsis, le studio de production, la source originale, la popularité et le classement, l'image de couverture et la durée de diffusion.
Utilisation en ligne :https://go.hyper.ai/tXtT5
4. Ensemble de données sur les maladies des feuilles de rosier
Le jeu de données « Maladies des feuilles de rosier » fournit des images de haute qualité pour le développement et l’évaluation de modèles de détection de ces maladies. Il est largement utilisé dans la mise en place de systèmes de surveillance des plantes. La version originale contient 2 458 images de feuilles de rosier du Bangladesh, classées en cinq catégories : taches noires, mildiou, brûlure des feuilles, feuilles saines et perforations par les insectes.
Utilisation en ligne :https://go.hyper.ai/IuPUO

Tutoriels publics sélectionnés
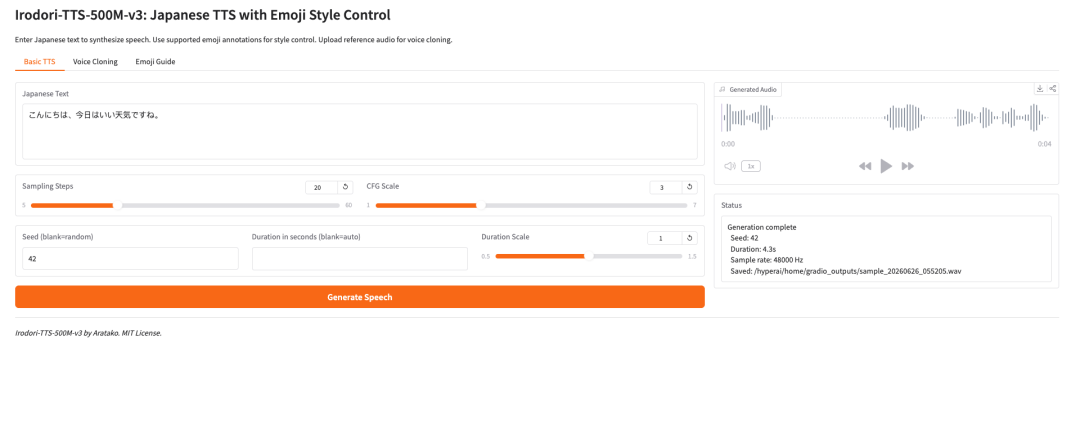
1. Irodori-TTS-500M-v3 : Synthèse vocale japonaise et contrôle de type Emoji
Le projet Irodori-TTS, lancé par le développeur Aratako en mai 2026, est dédié à la synthèse vocale en japonais, au clonage vocal sans échantillon et au contrôle du style vocal par emojis. Son innovation réside dans l'utilisation d'un transformateur à diffusion de courant redressé (RF-DiT) pour générer une parole à 48 kHz dans un espace latent DACVAE continu, combiné à des conditions audio de référence, à la prédiction automatique de la durée et aux subtilités des emojis pour contrôler le timbre, l'émotion et les ornements non verbaux.
Exécutez en ligne :https://go.hyper.ai/pFPM5
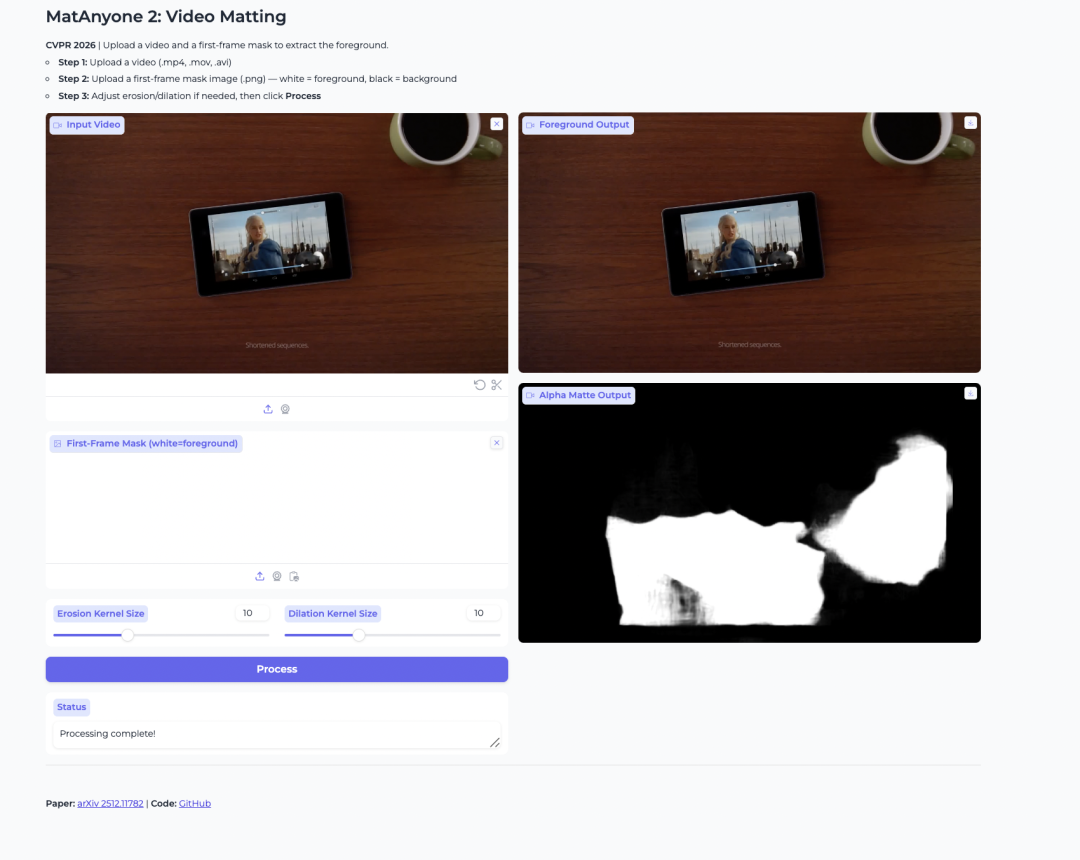
2. Modèle d'incrustation vidéo MatAnyone 2
Le projet MatAnyone 2, développé en 2026 par le S-Lab de l'Université technologique de Nanyang et SenseTime, permet de détourer des personnages, d'extraire le premier plan et d'appliquer un masquage alpha dans les vidéos. Son innovation repose sur un évaluateur de qualité développé en interne, garantissant un détourage stable, l'élimination des artefacts aux limites de l'image, la préservation précise des détails des cheveux et la prise en charge du détourage spécifique de plusieurs personnages.
Exécutez en ligne :https://go.hyper.ai/yNeFK
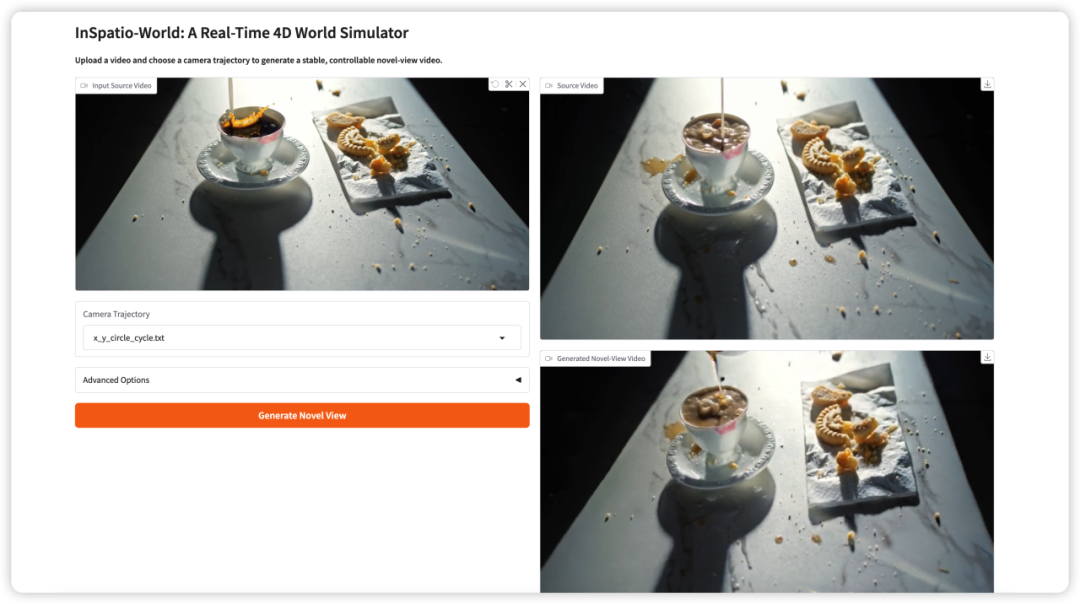
3. InSpatio-World : un simulateur de monde 4D en temps réel
InSpatio-World est un simulateur de monde 4D en temps réel basé sur la modélisation autorégressive spatio-temporelle, publié par l'équipe InSpatio le 19 mars 2026. Il peut générer des vidéos de nouvelles perspectives stables et contrôlables à partir de vidéos d'entrée et de trajectoires de caméra spécifiées, permettant un contrôle libre des trajectoires de caméra et une évolution du monde cohérente dans le temps.
Exécutez en ligne :https://go.hyper.ai/8FRRy
4. DiaMoE-TTS : Un tutoriel sur la synthèse vocale multilingue basée sur l’API
Le projet DiaMoE-TTS, lancé par Giant AI Lab en septembre 2025, est utilisé pour la synthèse vocale multilingue à l'aide de l'alphabet phonétique international (API) comme interface unifiée. Son innovation réside dans l'intégration des connaissances spécifiques à chaque dialecte au sein du système de routage expert Mixture-of-Experts (MoE) et dans l'obtention d'une adaptation rapide, sans échantillon, aux nouveaux dialectes grâce à des méthodes de paramétrage efficaces telles que LoRA/Adaptateur de Conditionnement.
Exécutez en ligne :https://go.hyper.ai/wn9i5
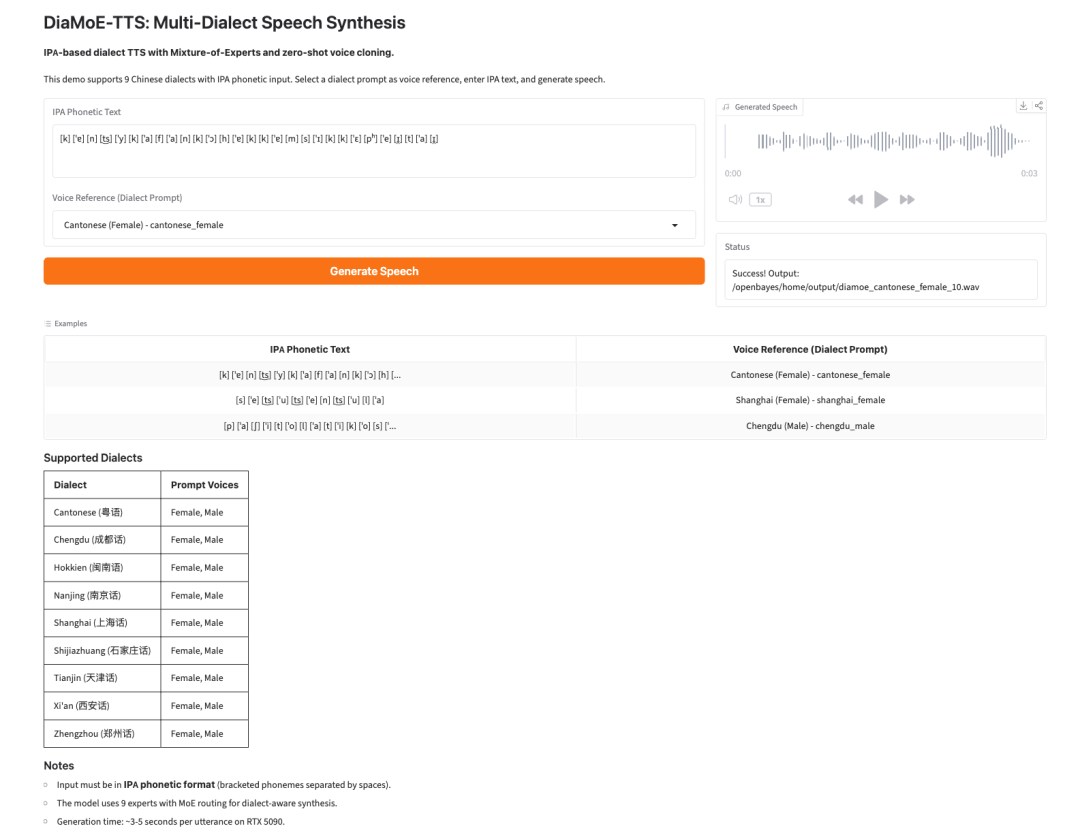
5. SAM-Audio : Sépare les sons arbitraires de l'audio à l'aide du traitement du langage naturel.
SAM-Audio est un modèle fondamental de séparation de sources audio publié par Meta en décembre 2025. Ce modèle est capable de séparer des sons spécifiques de mélanges audio complexes en utilisant des méthodes telles que des descriptions en langage naturel, des indices visuels vidéo ou des segments temporels.
Exécutez en ligne :https://go.hyper.ai/svjXe
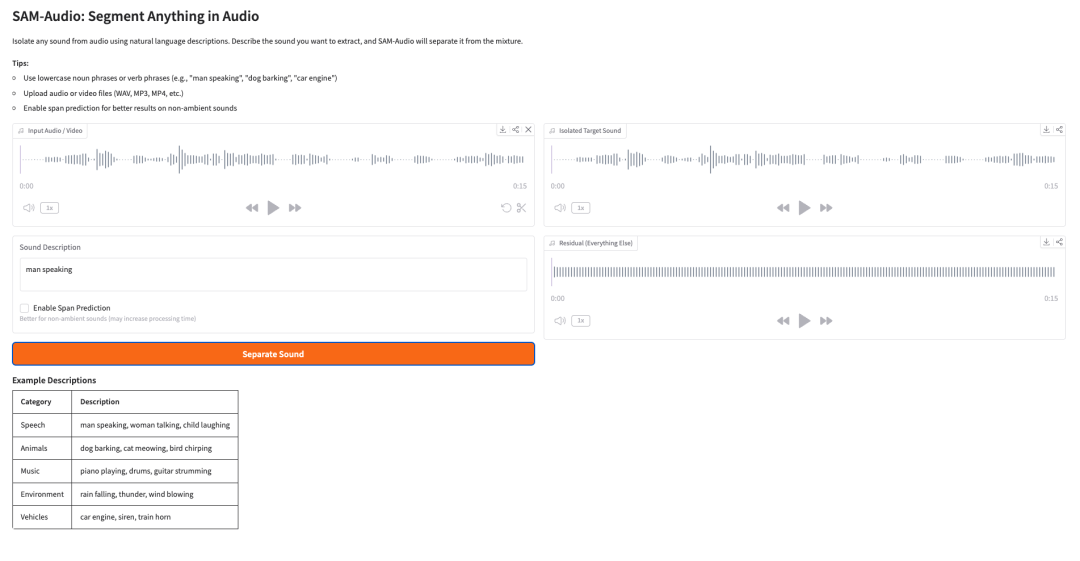
6. PrismAudio : V2A basé sur la décomposition CoT et les récompenses multidimensionnelles
PrismAudio est un modèle de génération vidéo-audio (V2A) développé par Tongyi Labs et publié en novembre 2025. Ce modèle est le premier à intégrer l'apprentissage par renforcement à la génération V2A, s'appuyant sur le mécanisme de planification Chain of Thought (CoT) de ThinkSound. Il décompose un processus de raisonnement unique en quatre modules CoT spécialisés : sémantique, temporel, esthétique et spatial, et associe à chaque module une fonction de récompense ciblée. Cette approche permet une optimisation multidimensionnelle par apprentissage par renforcement et améliore globalement la qualité du raisonnement dans toutes les dimensions perceptives.
Exécutez en ligne :https://go.hyper.ai/BRGSk
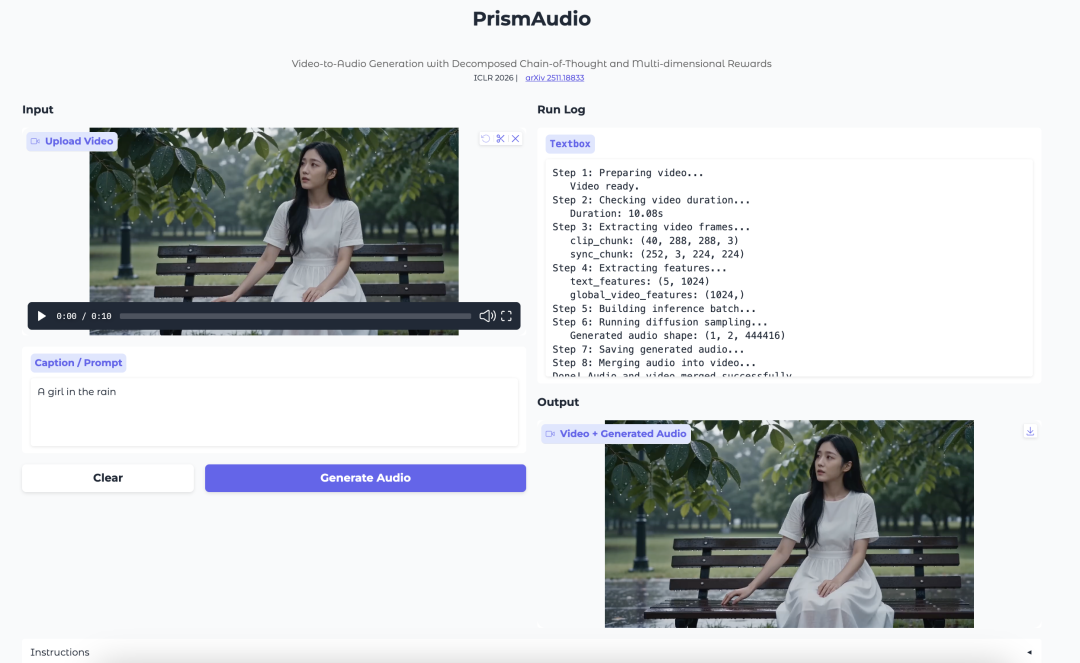
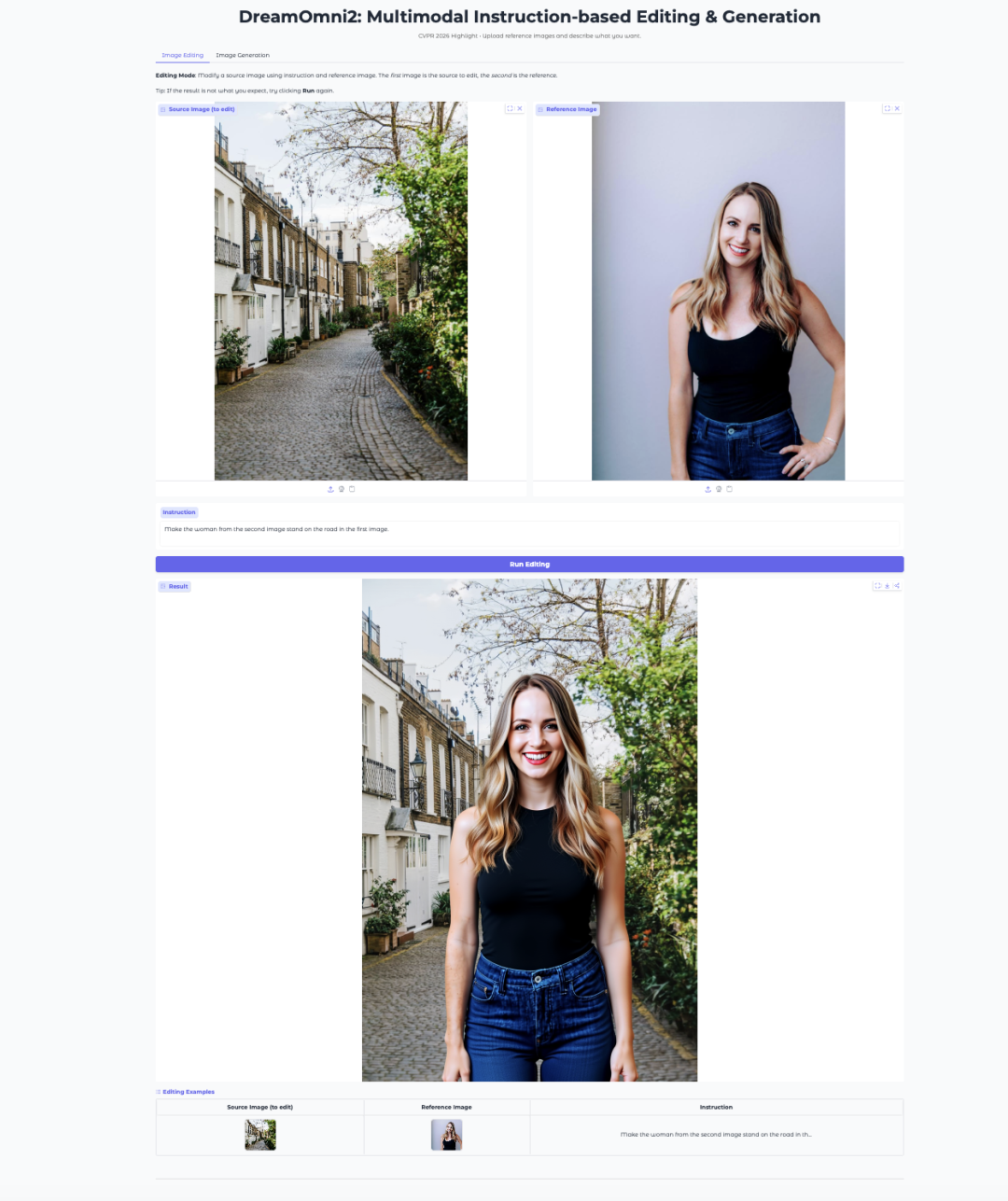
7. DreamOmni2 : Édition et génération d’images multimodales guidées par instructions
DreamOmni2 est un modèle multimodal d'édition et de génération d'images piloté par instructions, développé par le laboratoire JIA de l'Université chinoise de Hong Kong en octobre 2025. L'article a été sélectionné comme article phare de la conférence CVPR 2026. Ce modèle est basé sur le modèle de base FLUX.1-Kontext-dev et le combine avec un modèle de langage visuel Qwen2.5-VL-7B finement paramétré, permettant l'édition et la génération d'images grâce à des instructions en langage naturel associées à des images de référence.
Exécutez en ligne :https://go.hyper.ai/1iqNO
8. PixelRefer : Un cadre unifié pour une compréhension fine des objets dans les images et les vidéos.
Développé par Alibaba DAMO Academy en octobre 2025, PixelRefer vise à permettre une identification précise du centre des objets, la génération de légendes et la réponse aux questions dans les images et les vidéos. Son innovation réside dans l'adoption d'un cadre de modélisation linéaire multiniveau unifié au niveau des régions (MLLM), combiné à un segmentateur d'objets adaptatif à l'échelle (SAOT) et au cadre spécifique aux objets PixelRefer-Lite, pour la construction de représentations d'objets compactes.
Exécutez en ligne :https://go.hyper.ai/ETjjw
9. OCR illimité : Déploiement en un clic de la reconnaissance optique de caractères (OCR) et de l’analyse de la mise en page des documents longs
Le projet Unlimited-OCR a été lancé par l'équipe Baidu en juin 2026. Ce projet cible la reconnaissance optique de caractères (OCR) de documents longs et l'analyse de leur mise en page, avec pour objectif principal de maintenir une efficacité d'analyse stable sur une longue période, permettant ainsi une analyse en une seule étape et à long terme. Le modèle peut traiter des images de documents uniques, des images multipages et des images de pages converties à partir de PDF, ce qui le rend adapté à la reconnaissance de texte et à l'analyse structurée de documents, de rapports, de documents numérisés, de longs tableaux et de documents multipages.
Exécutez en ligne :https://go.hyper.ai/Bp69q
10. EdgeTAM : un modèle de segmentation d’images et de vidéos activé par des indices pour les appareils périphériques.
Le projet EdgeTAM, lancé conjointement par Meta Reality Labs et le S-Lab de l'Université technologique de Nanyang en janvier 2025, est conçu pour la segmentation d'images et le suivi d'objets vidéo assistés par des indices sur des appareils aux ressources limitées. Son innovation majeure réside dans l'utilisation d'un perceptron spatial 2D combiné à un processus de distillation, ce qui réduit le goulot d'étranglement de la mémoire de SAM 2 tout en préservant la qualité de la segmentation, permettant ainsi une interaction efficace de type « Suivi de tout » directement sur l'appareil.
Exécutez en ligne :https://go.hyper.ai/yZoqO
11. Step-Audio-EditX : Clonage vocal sans séquence et montage audio basé sur les expressions, basé sur 3B LLM
Le projet Step-Audio-EditX, lancé par StepFun en novembre 2025, cible le clonage vocal sans exemple et les tâches d'édition audio itératives et expressives. Son innovation réside dans la combinaison d'un vaste modèle de langage comportant 3 milliards de paramètres avec l'apprentissage par renforcement, permettant ainsi de composer des termes de contrôle discrets pour les émotions, le style d'élocution et les événements paralinguistiques. Le modèle prend en charge le mandarin, l'anglais, le sichuanais, le cantonais, le japonais et le coréen.
Exécutez en ligne :https://go.hyper.ai/UL7Hg
12. Nemotron 3.5 ASR Streaming 0.6B : un modèle ASR léger pour la reconnaissance vocale en continu
Nemotron 3.5 ASR Streaming 0.6B est un modèle de reconnaissance vocale automatique et de transcription en flux continu à faible latence, doté de 60 millions de paramètres et publié par NVIDIA en juin 2026. Ce modèle utilise une architecture FastConformer-RNNT optimisée pour le cache, qui réutilise le contexte de l'encodeur lors de l'inférence en flux continu, réduisant ainsi les calculs redondants. Il prend également en charge les conditions d'identification de la langue, permettant la transcription dans plusieurs régions linguistiques.
Exécutez en ligne :https://go.hyper.ai/mFejg
Interprétation des articles communautaires
1. Meta propose des data scientists spécialisés en IA, et Autodata crée des ensembles de données d'entraînement/d'évaluation de haute qualité.
L'équipe de recherche en intelligence artificielle Meta Basic a proposé une méthode générale appelée Autodata, dans laquelle un agent intelligent, jouant le rôle d'un « data scientist », est chargé de construire et d'organiser les données. Son comportement imite le processus d'un data scientist humain pour générer des données de haute qualité. Ce processus comprend non seulement la génération initiale des données, mais aussi la phase d'analyse, l'évaluation de leurs performances, la synthèse des enseignements tirés et la génération itérative de solutions de données améliorées à partir de ces enseignements.
Voir le rapport complet :https://go.hyper.ai/UThkc
Articles populaires de l'encyclopédie
1. Modèle de langage étendu (LLM)
2. Modèle d'action mondial WAM
3. Moyenne harmonique
4. Dépistage virtuel
5. Apprentissage par renforcement basé sur le retour d'information de l'IA (RLAIF)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








