Command Palette
Search for a command to run...
Tencent Rend open-source Le Modèle De Traduction Hy-MT1.5 : 440MB Atteint Des Capacités De Traduction De Haut Niveau ; Le MIT Publie Conjointement MathNet : Un Banc D’essai D’inférence Mathématique Multimodale Couvrant 27 000 Problèmes Mathématiques Réels Des Olympiades.

Hy-MT1.5-1.8B-1.25bit est un modèle de traduction automatique léger développé par Tencent. Il est basé sur Hy-MT1.5-1.8B et optimisé grâce à un entraînement en plusieurs étapes, comprenant le pré-entraînement, le réglage fin supervisé, la distillation et l'apprentissage par renforcement.Le modèle prend en charge 33 langues, 5 dialectes et langues minoritaires, et 1 056 directions de traduction.Avec seulement 1,8 milliard de paramètres, ses performances de traduction ont surpassé celles de certains modèles open source à plus grande échelle et des API de traduction commerciales courantes.
Le site web d'HyperAI propose désormais « Hy-MT1.5-1.8B-1.25bit : un modèle de traduction multilingue léger ». Essayez-le !
Utilisation en ligne :https://go.hyper.ai/PCK8X
Bienvenue sur notre site web officiel pour plus d'informations :
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 6 au 15 mai :
* 12 jeux de données publics de haute qualité
* Une sélection de tutoriels de haute qualité : 7
* Interprétation d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de compréhension du graphe d'étalonnage quantique QCalEval
QCalEval, publié par NVIDIA en 2026, est un jeu de données de langage visuel destiné à la compréhension des graphes dans les expériences d'informatique quantique. Il vise à évaluer la capacité des modèles de langage visuel (MLV) à interpréter, classifier et raisonner sur les résultats d'expériences d'étalonnage en informatique quantique. Ce jeu de données est largement utilisé dans la recherche sur les modèles de langage visuel et la compréhension d'images scientifiques. Il contient 309 images scientifiques bidimensionnelles au format PNG, 243 entrées de référence et 236 entrées de référence avec peu d'exemples, couvrant 22 séries expérimentales et 87 types de scènes.
Utilisation en ligne :https://go.hyper.ai/Ke7cu
2. Ensemble de données de référence en conditions réelles Claw-Eval
Claw-Eval, développé en 2026 par l'Université de Pékin et l'Université de Hong Kong, est un jeu de données de référence transparent et complet permettant d'évaluer les agents d'IA dans des tâches réelles. Il vise à évaluer les capacités des agents autonomes en matière d'exécution de tâches, d'utilisation d'outils, de compréhension multimodale et d'interactions à plusieurs tours dans des environnements réels. Ce jeu de données prend en charge l'anglais et le chinois et comprend trois groupes de tâches principaux : Général, Multimodal et Interactions à plusieurs tours, couvrant 24 catégories de tâches telles que la communication, la finance, le travail de bureau et les outils de productivité.
Utilisation en ligne :https://go.hyper.ai/Tznpa
3. Ensemble de données de référence multimodales MathNet pour l'inférence mathématique
MathNet est un vaste ensemble de données de raisonnement mathématique multilingue et multimodal, publié en 2026 par l'équipe du MIT en collaboration avec l'Université des sciences et technologies du roi Abdallah et d'autres institutions. Il vise à évaluer et à améliorer les performances des grands modèles dans les tâches de raisonnement mathématique et de recherche structurée de niveau olympique, et est largement utilisé dans l'évaluation du raisonnement mathématique, la recherche sur les algorithmes de raisonnement et d'apprentissage automatique (RAG) et l'entraînement de l'IA multimodale.
Utilisation en ligne :https://go.hyper.ai/HLxNw
4. Ensemble de données de référence pour la compréhension des changements de zone par télédétection du RSRCC
RSRCC, publié par Google Research en 2026, est un jeu de données de référence pour la compréhension des changements sémantiques en télédétection. Il vise à faciliter une compréhension approfondie des changements temporels dans les scènes de télédétection en associant des données d'imagerie multi-temporelles à des questions-réponses en langage naturel, faisant ainsi évoluer la détection binaire traditionnelle des changements vers une description sémantique de ces derniers. Le jeu de données contient 126 000 exemples de questions-réponses pour la détection des changements en télédétection, couvrant des scénarios tels que les nouvelles constructions, les démolitions, les modifications de voirie, les changements de végétation et le développement résidentiel.
Utilisation en ligne :https://go.hyper.ai/jtCaK
5. Ensemble de données sur la détection des déchets médicaux
Le jeu de données d'images haute résolution Medical Waste est conçu pour l'identification intelligente et la détection ciblée des déchets médicaux. Il vise à aider les modèles de vision par ordinateur à réaliser la détection et la classification automatiques des déchets médicaux dans des environnements médicaux complexes et est largement utilisé dans des domaines de recherche tels que la santé connectée, la santé publique, le tri automatisé des déchets et la vision robotique.
Utilisation en ligne :https://go.hyper.ai/PrUKd
6. Base de données sur les maladies des feuilles de vigne
GRAPE Leaf Diseases est un jeu de données d'images de feuilles de vigne conçu spécifiquement pour les tâches de détection de cibles en agriculture de précision. Son objectif est d'améliorer la capacité des modèles de vision par ordinateur à détecter, classifier et localiser les maladies dans des contextes agricoles réels. Ce jeu de données contient 4 195 images de feuilles de vigne, réparties en quatre catégories : feuilles saines et trois maladies courantes : la pourriture noire, l'escafé fulva et le mildiou.
Utilisation en ligne :https://go.hyper.ai/tJrkm
7. Atlas de la faune aquatique : un ensemble de données mondial sur la vie aquatique.
L'Atlas de la faune aquatique : Recensement mondial des espèces est une vaste base de données d'observation d'animaux aquatiques conçue pour la recherche en écologie aquatique et l'analyse de la biodiversité. Elle vise à fournir aux chercheurs, aux étudiants et aux spécialistes des données des ressources de données écologiques aquatiques de haute qualité. Cette base de données contient 200 000 observations d'animaux aquatiques, couvrant plus de 100 espèces et englobant les principaux écosystèmes aquatiques du monde, notamment les récifs coralliens, les rivières tropicales, l'océan Arctique et les zones abyssales jusqu'à 7 000 mètres de profondeur.
Utilisation en ligne :https://go.hyper.ai/calNa
8. Séismes mondiaux - M4.5 : Un ensemble de données mondial sur les séismes de magnitude 4,5 et plus.
Le jeu de données « Événements sismiques mondiaux – M4.5+ » est conçu pour l’analyse de l’activité sismique et la recherche géospatiale. Il vise à aider les chercheurs à analyser la fréquence, la distribution et les variations de magnitude de l’activité sismique à long terme. Ce jeu de données contient 230 608 enregistrements de séismes, couvrant les séismes mondiaux de magnitude 4,5 et plus survenus entre 1900 et 2026.
Utilisation en ligne :https://go.hyper.ai/D7j95
9. Ensemble de données sur l'efficacité des médicaments synthétiques
L'ensemble de données sur l'efficacité des médicaments de synthèse est un jeu de données généré à partir de médicaments de synthèse, conçu pour faciliter l'analyse de la sécurité des médicaments et l'évaluation des risques cliniques. Il convient à l'analyse de données, à la modélisation et à la recherche expérimentale. Cet ensemble de données contient des informations médicales structurées sur l'utilisation des médicaments et la surveillance des effets indésirables. Chaque enregistrement est indexé par un numéro de rapport unique et comprend des informations de base telles que l'âge et le sexe du patient, ainsi que des détails sur le traitement, notamment le nom du médicament, la posologie, la durée du traitement et les médicaments concomitants.
Utilisation en ligne :https://go.hyper.ai/1ZaA0
10. Ensemble de données sur la classification des maladies du fond d'œil
Le jeu de données Eye Disease Classification Fundus est un ensemble de données de vision médicale conçu pour la classification d'images du fond d'œil. Son objectif est d'améliorer les performances des modèles de vision par ordinateur dans l'identification des maladies ophtalmiques et le diagnostic assisté. Ce jeu de données contient 6 086 images, réparties en quatre catégories : cataracte, rétinopathie diabétique, glaucome et fond d'œil normal.
Utilisation en ligne :https://go.hyper.ai/FFFE7
11. Cancer du sein : ensemble de données de fusion multimodale
Cancer du sein : Fusion multimodale est un jeu de données multimodal prétraité, conçu pour les patientes atteintes d’un cancer du sein invasif (BRCA), et destiné à faciliter la création de réseaux de fusion multimodale. Ce jeu de données aligne rigoureusement les données multi-sources de 122 patientes BRCA, tous les échantillons étant cartographiés entre les modalités à l’aide des identifiants de cas TCGA. Il en résulte une correspondance univoque entre l’imagerie médicale macroscopique (IRM), la pathologie numérique microscopique (histopathologie), les données omiques moléculaires (multi-omiques) et les informations relatives au traitement clinique.
Utilisation en ligne :https://go.hyper.ai/199WV
12. Ensemble de données pour la détection des feux de forêt et de la fumée à longue distance
Le jeu de données de vision par ordinateur « Détection à longue distance des feux de forêt et de la fumée » est conçu pour l'alerte précoce et la surveillance environnementale des feux de forêt. Il vise à améliorer la capacité du modèle à détecter la fumée et les feux de forêt dans le cadre de la surveillance forestière à longue distance. Ce jeu de données est généré par une approche entièrement synthétique, simulant des scénarios de surveillance à grande hauteur et à longue distance, tels que les tours de guet et les caméras de surveillance de crête, en mettant l'accent sur la détection des panaches de fumée, plus facilement observables aux premiers stades d'un incendie.
Utilisation en ligne :https://go.hyper.ai/LnuXC
Tutoriels publics sélectionnés
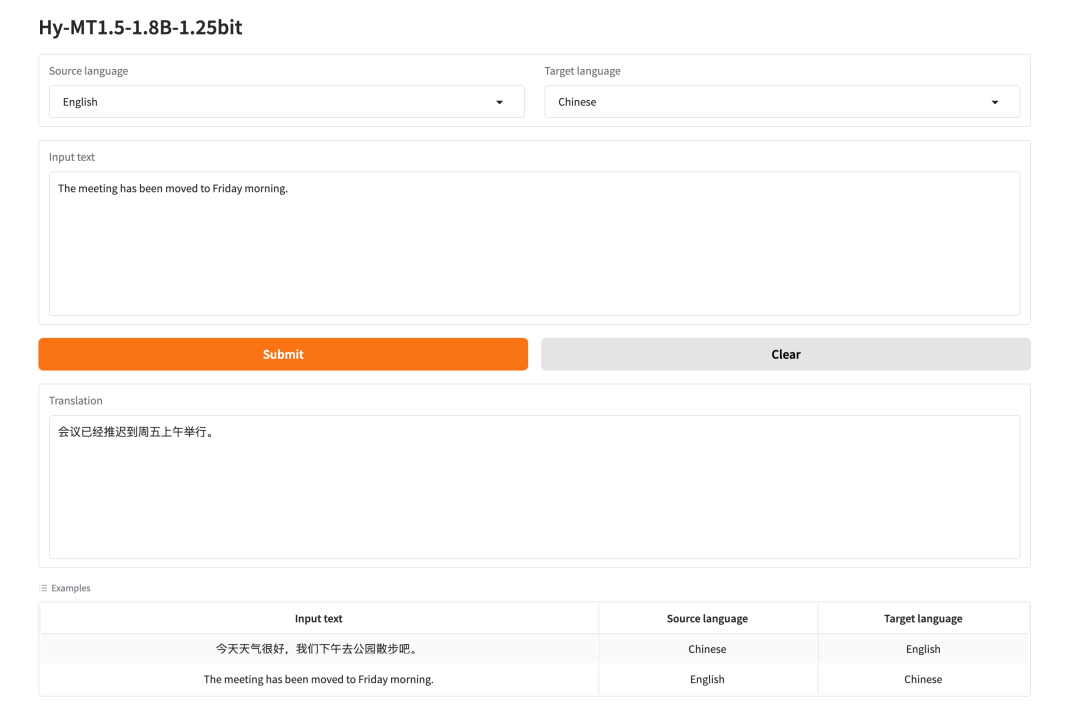
1. Hy-MT1.5-1.8B-1.25bit : Modèle de traduction multilingue léger
Hy-MT1.5-1.8B-1.25bit, publié par Tencent en avril 2026, est un modèle de traduction multilingue quantifié 1,25 bit basé sur Hy-MT1.5-1.8B. Son principal atout réside dans la compression de capacités de traduction multilingue de haute qualité en un format de déploiement plus léger.
Exécutez en ligne :https://go.hyper.ai/PCK8X
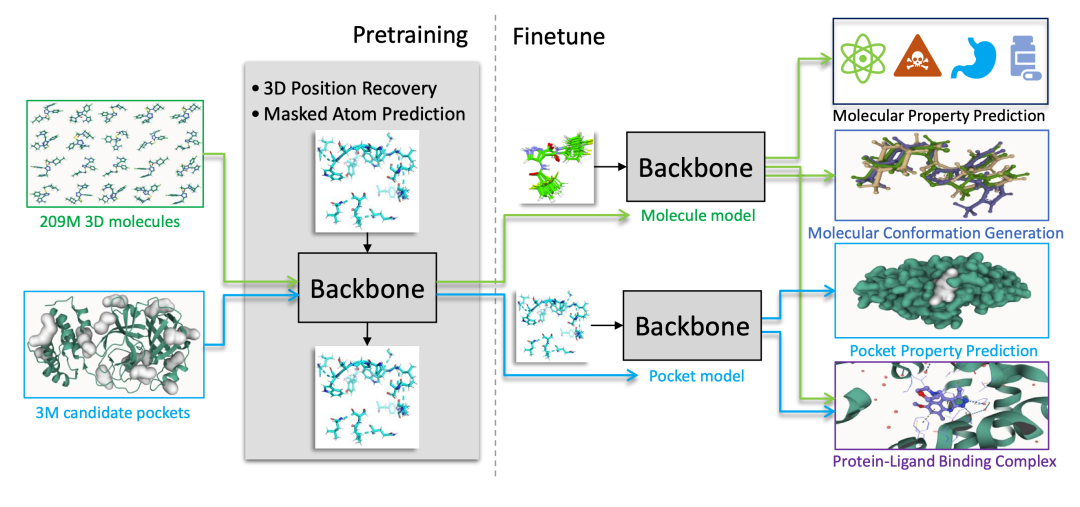
2. Uni-Mol : un cadre d’apprentissage général pour la représentation moléculaire 3D
Uni-Mol est un cadre de pré-entraînement moléculaire 3D à usage général, publié par DP Technology en 2022. Uni-Mol étend les capacités de représentation moléculaire grâce à un pré-entraînement à grande échelle de structures moléculaires 3D et peut être utilisé pour des tâches telles que la conception de médicaments, la prédiction des propriétés moléculaires et la modélisation des interactions protéine-ligand.
Exécutez en ligne :https://go.hyper.ai/RukIx
3. Déploiement en un clic de Mistral-Medium-3.5-128B
Mistral Medium 3.5, publié par Mistral AI en 2025, est un modèle de fusion phare doté de 128 milliards (128B) de paramètres et de 256 000 fenêtres de contexte. Il unifie la conformité aux instructions, l'inférence et les capacités de programmation au sein d'un seul ensemble de pondérations. Ce modèle a remplacé les précédents modèles Mistral Medium 3.1 et Magistral, ainsi que Devstral 2 dans l'agent de programmation Vibe.
Exécutez en ligne :https://go.hyper.ai/PXiHc
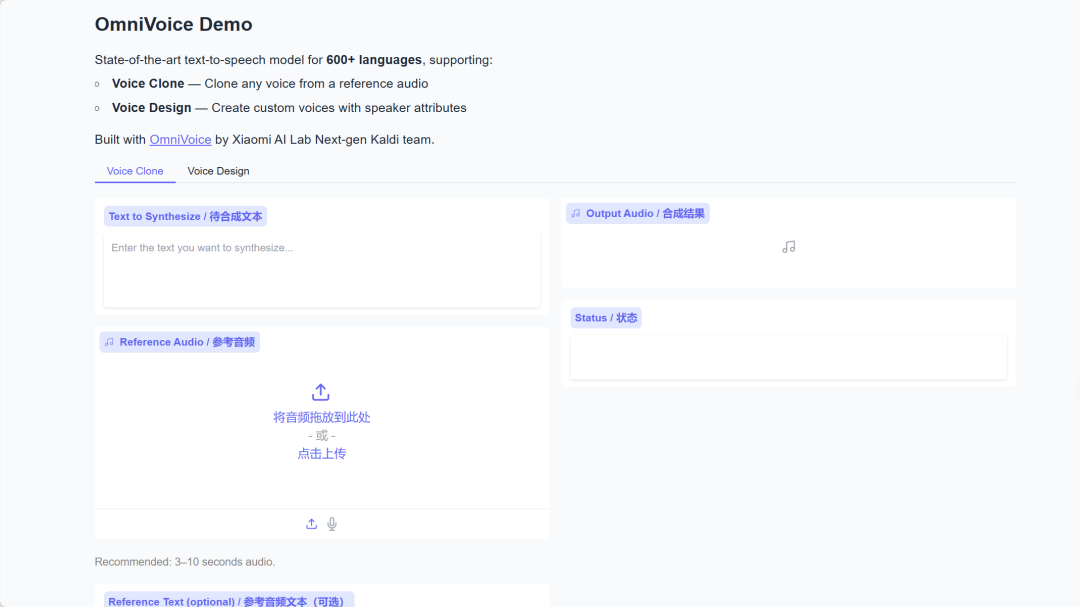
4. OmniVoice : Prend en charge la synthèse vocale de haute qualité dans plus de 600 langues.
OmniVoice est un modèle de synthèse vocale multilingue développé par l'équipe Kaldi nouvelle génération du laboratoire d'IA de Xiaomi, prenant en charge la synthèse vocale de haute qualité dans plus de 600 langues. Basé sur une architecture de décodage itérative non masquée, le projet implémente trois fonctions principales : le clonage vocal, la conception vocale et la voix automatique.
Exécutez en ligne :https://go.hyper.ai/7F7IR
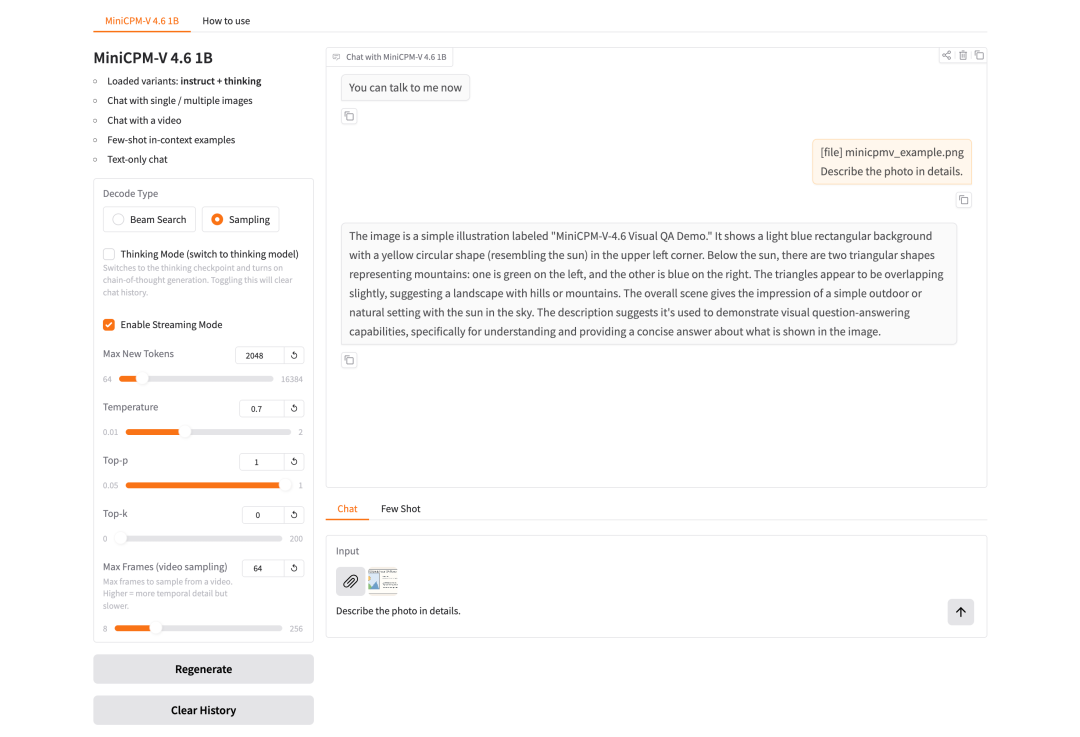
5. MiniCPM-V-4.6 : Modèle de langage visuel multimodal haute performance pour les périphériques de périphérie
MiniCPM-V-4.6, publié en mai 2026 par l'équipe OpenBMB et le Laboratoire de traitement automatique du langage naturel de l'Université Tsinghua, est un modèle de langage visuel multimodal performant, conçu pour la compréhension d'images et de vidéos, la réponse à des questions visuelles, la reconnaissance optique de caractères (OCR) et les dialogues multimodaux à plusieurs tours de parole. Son principal atout réside dans sa capacité à couvrir les tâches courantes de compréhension multimodale avec une taille de modèle relativement réduite, le rendant particulièrement adapté à la réponse à des questions sur des images, au résumé de courtes vidéos, à la compréhension de captures d'écran, à l'OCR d'images de documents et à la validation de dialogues multimodaux à plusieurs tours de parole dans des environnements aux ressources limitées.
Exécutez en ligne :https://go.hyper.ai/azdHU
6. LingBot-Map : Transformateur de contexte géométrique pour la reconstruction 3D en flux continu
LingBot-Map est un projet de reconstruction 3D en continu, lancé par l'équipe Robbyant en avril 2026. Ce projet prend en entrée des séquences d'images ou des images vidéo et effectue une reconstruction de scène 3D en temps réel, de manière ascendante. Les nuages de points, les trajectoires de la caméra et les résultats image par image sont visualisables via une visionneuse 3D dans un navigateur.
Exécutez en ligne :https://go.hyper.ai/BR4me

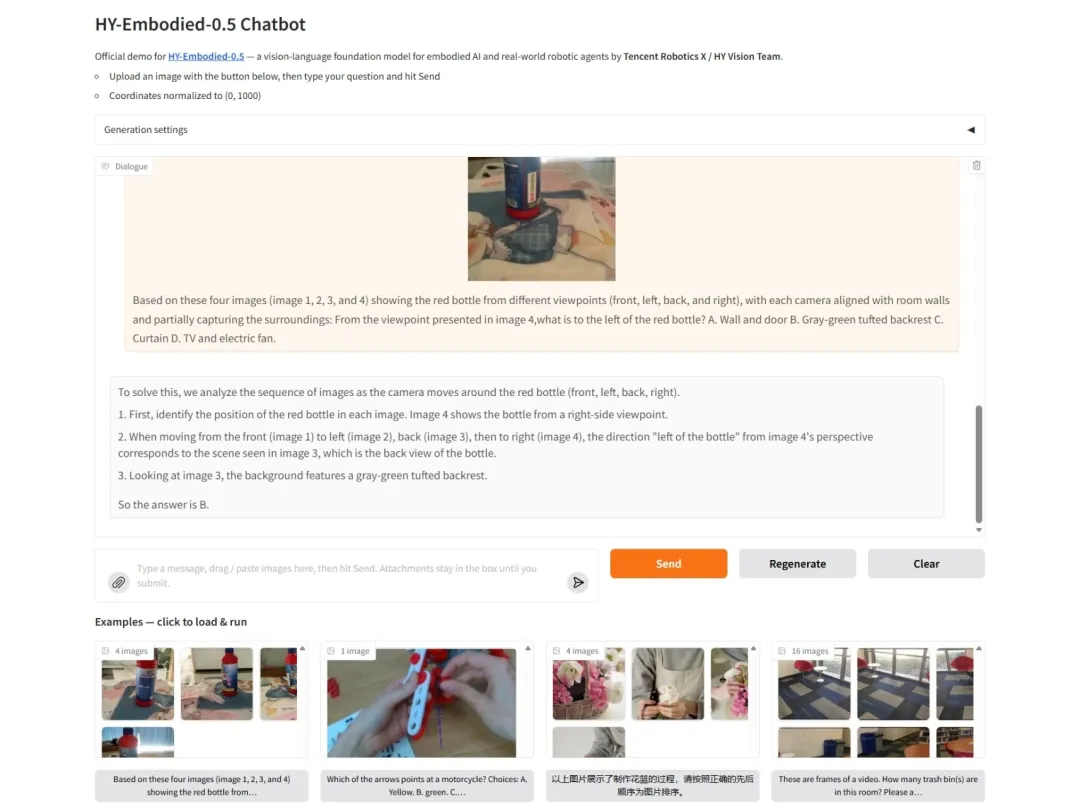
7. HY-Embodied-0.5 : Un modèle de base incarné pour les agents intelligents du monde réel
HY-Embodied-0.5 est un modèle fondamental conçu spécifiquement pour l'intelligence incarnée, publié en open source conjointement par l'équipe Hunyuan de Tencent et le laboratoire Tencent Robotics X en avril 2026. Cette série de modèles ne constitue pas une simple modification d'une base générique, mais une reconstruction complète, de l'architecture au paradigme d'entraînement. L'équipe a simultanément publié deux modèles principaux : MoT-2B (4 milliards de paramètres, 2 milliards d'activations), axé sur la réponse en temps réel côté périphérique, et MoE-32B (407 milliards de paramètres, 32 milliards d'activations), visant des performances d'inférence optimales.
Exécutez en ligne :https://go.hyper.ai/u8lJk
Interprétation des articles communautaires
1. EnergAIzer, un framework d'estimation de la puissance GPU développé par le MIT et d'autres, effectue des prédictions en moyenne en 1,8 seconde avec une erreur d'environ 81 TP3T.
Des chercheurs du MIT et du laboratoire d'IA Watson du MIT et d'IBM ont développé EnergAIzer, un framework rapide d'estimation de la consommation énergétique des GPU pour les charges de travail d'IA. EnergAIzer fournit directement aux modèles d'alimentation des informations sur l'utilisation du matériel, sans nécessiter de simulations coûteuses ni d'analyses de performance. Ce nouveau framework réalise une estimation complète de la consommation énergétique en seulement 1,8 seconde en moyenne. Sur les GPU NVIDIA Ampere, EnergAIzer atteint une erreur énergétique d'environ 81 TP3T, ce qui est comparable aux modèles traditionnels qui reposent sur des simulations cycliques complexes ou sur des analyses de performance matérielle.
Voir le rapport complet :https://go.hyper.ai/1PeMV
2. L'utilisation des jetons a diminué de 30%. Eywa, un cadre d'agent intelligent hétérogène inspiré d'"Avatar", combine efficacement des modèles de langage avec des modèles de base spécifiques au domaine.
Une équipe de recherche de l'Université de l'Illinois à Urbana-Champaign (UIUC) a proposé Eywa, un cadre d'agents hétérogènes permettant de connecter des agents langagiers à des modèles fondamentaux spécifiques à un domaine. En combinant ces modèles fondamentaux avec des modèles langagiers, les chercheurs ont conçu EywaAgent, un agent langagier novateur qui guide les processus de raisonnement, de planification et de prise de décision du modèle fondamental dans ses tâches spécialisées.
Voir le rapport complet :https://go.hyper.ai/CzRL4
3. Une centaine d'universités ont lancé la plus grande étude protéogénomique multicohorte au monde, permettant d'identifier des gènes responsables de maladies et de réorienter l'utilisation de médicaments existants grâce aux données de près de 80 000 participants.
Une équipe issue de plus d'une centaine d'universités et d'instituts de recherche, dont l'Université Queen Mary de Londres et l'Université de Cambridge, a publié la plus vaste étude protéogénomique multicohorte jamais réalisée. Fondée sur une méta-analyse à grande échelle de protéoglyphes portant sur 38 cohortes de recherche indépendantes et un total de 78 664 participants, l'étude a identifié de manière systématique 24 738 loci de caractères quantitatifs (QTL) de protéines et les a associés à 1 116 protéines circulantes, révélant ainsi de façon exhaustive les caractéristiques de régulation génétique de proximité et de distance au niveau protéique.
Voir le rapport complet :https://go.hyper.ai/lGD68
Articles populaires de l'encyclopédie
1. Modèles du monde
2. Courbe d'étalonnage
3. Attention contrôlée
4. L'humain au cœur du processus
5. Fusion de rangs réciproques
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








