Command Palette
Search for a command to run...
Prend En Charge La Génération De Vidéos En Prises De Vues réelles/animations/animaux ; Le Framework open-source De Génération Vidéo Audio multi-styles LongCat 1.5 De Meituan Améliore Les Capacités De Reconstruction De Graphiques Et d'extraction De Tableaux De VLM En Utilisant l'ensemble De Données De Compréhension De Graphiques À Un Million De Niveaux ChartNet.

LongCat-Video-Avatar 1.5, lancé par l'équipe Meituan LongCat en mai 2026, est un tout nouveau framework open-source de génération vidéo pilotée par l'audio (AI2V).Il suffit aux utilisateurs de fournir une image de référence statique et un clip audio pour générer une vidéo d'avatar dynamique avec une synchronisation labiale précise.Ce modèle utilise l'extraction de caractéristiques vocales par chuchotement ; la technologie de distillation par étapes compresse le processus de génération DiT en seulement 8 étapes, garantissant ainsi des visuels haute fidélité et la génération de vidéos longues. Sa capacité de généralisation étendue couvre les portraits réalistes, les personnages d'anime 2D/3D et les avatars d'animaux, offrant une solution efficace et fiable pour la génération de vidéos multi-scènes.
Le site web d'HyperAI propose désormais le « LongCat-Video-Avatar 1.5 Digital Human Model », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/NROTv
Bienvenue sur notre site web officiel pour plus d'informations :
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 6 au 12 juin :
* Jeux de données publics de haute qualité : 6
* Sélection de tutoriels de haute qualité : 3
* Interprétation d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Graphique ChartNet : compréhension des ensembles de données multimodaux
ChartNet est un jeu de données multimodal de grande envergure et de haute qualité, publié en 2026 par le MIT en collaboration avec IBM Research et d'autres institutions. Il vise à pallier les insuffisances des modèles existants en matière d'inférence conjointe, en utilisant des motifs visuels géométriques, des données numériques structurées et des descriptions textuelles. Ce jeu de données contient 4,2 millions d'exemples de graphiques synthétiques, 94 643 exemples de graphiques validés manuellement et 30 000 graphiques réels, couvrant 24 types de graphiques et 6 bibliothèques de traçage.
Utilisation en ligne :https://go.hyper.ai/0CNr7
2. Ensemble de données de saillance vidéo panoramique OpenSAL360
OpenSAL360 est actuellement le plus grand ensemble de données complet sur la saillance vidéo, conçu pour soutenir la recherche sur l'attention visuelle, la prédiction de la saillance et l'analyse vidéo multimodale. Cet ensemble de données contient 500 vidéos panoramiques variées issues de YouTube, d'une durée moyenne de 18,1 secondes, et des annotations réalisées par plus de 2 000 observateurs.
Utilisation en ligne :https://go.hyper.ai/u7NqD
3. Ensemble de données sur les émotions liées aux films
Movie Feelings est un ensemble de données sur les émotions au cinéma, conçu pour caractériser de manière systématique les émotions subtiles suscitées par les films, dépassant ainsi les limites des classifications traditionnelles basées uniquement sur les émotions positives/négatives ou les émotions de base. Cet ensemble de données comprend 1 500 films représentatifs et culturellement influents, sortis entre 1920 et 2024, et couvrant 50 états émotionnels.
Utilisation en ligne :https://go.hyper.ai/b4m71
4. FigureBench : Génération d'ensembles de données de référence pour les illustrations scientifiques.
FigureBench est un jeu de données de référence pour la génération d'illustrations scientifiques, publié en 2026 par le Text Intelligence Lab de l'Université de Westlake. Il vise à résoudre le problème de la génération automatique d'illustrations scientifiques de haute qualité à partir de longs textes scientifiques, offrant ainsi une plateforme de test stimulante et diversifiée pour la recherche dans ce domaine.
Utilisation en ligne :https://go.hyper.ai/Agaku
5. Impact de l'IA sur les étudiants : L'apprentissage assisté par l'IA a un impact sur les ensembles de données.
L'ensemble de données AI Student Impact Dataset est un vaste ensemble de données sur les comportements éducatifs, couvrant de multiples dimensions et conçu pour analyser systématiquement l'impact concret des outils d'IA générative dans l'enseignement supérieur. Cet ensemble contient 50 000 échantillons d'étudiants et 16 champs de caractéristiques structurés, couvrant des données telles que le parcours académique des étudiants, leurs habitudes d'utilisation de l'IA, leurs comportements d'apprentissage, le contexte institutionnel, leur état de santé mentale et les scénarios d'application.
Utilisation en ligne :https://go.hyper.ai/zWoGM
6. Ensemble de données d'images de documents médicaux bruitées
Noisy Medical Document est un ensemble de données d'images de documents médicaux bruitées, conçu pour les tâches de reconnaissance optique de caractères (OCR) et de compréhension de documents médicaux. Il vise à simuler les interférences complexes dues au bruit rencontrées lors de la numérisation de documents dans des contextes médicaux réels, améliorant ainsi la robustesse et la capacité de généralisation des modèles d'OCR et de compréhension de documents en situation réelle. L'ensemble de données contient 1 000 images synthétiques de documents médicaux haute fidélité, dont 500 factures d'hôpital et 500 résumés de sortie.
Utilisation en ligne :https://go.hyper.ai/kL7gc
Tutoriels publics sélectionnés
1. LongCat-Video-Avatar 1.5 Modèle humain numérique
LongCat-Video-Avatar 1.5, publié par l'équipe Meituan en mai 2026, est une version améliorée d'un framework open source de génération vidéo audio (AI2V). Il permet de générer des vidéos d'avatars dynamiques, très réalistes et parfaitement synchronisées avec les lèvres, à partir d'une simple image de référence statique et d'un extrait audio. Il gère aisément des scènes complexes du monde réel ainsi que des sujets stylisés tels que des animations et des animaux.
Exécutez en ligne :https://go.hyper.ai/NROTv
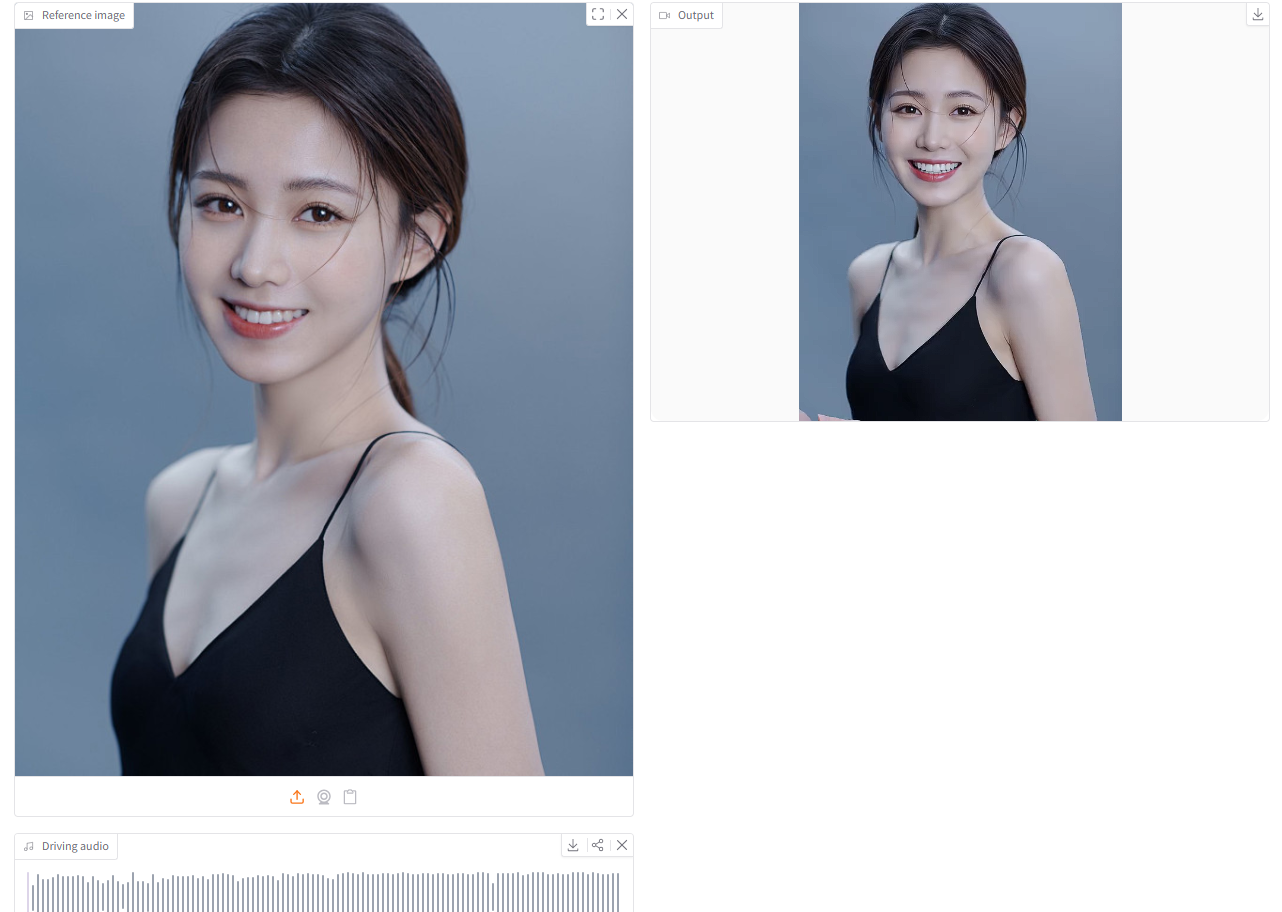
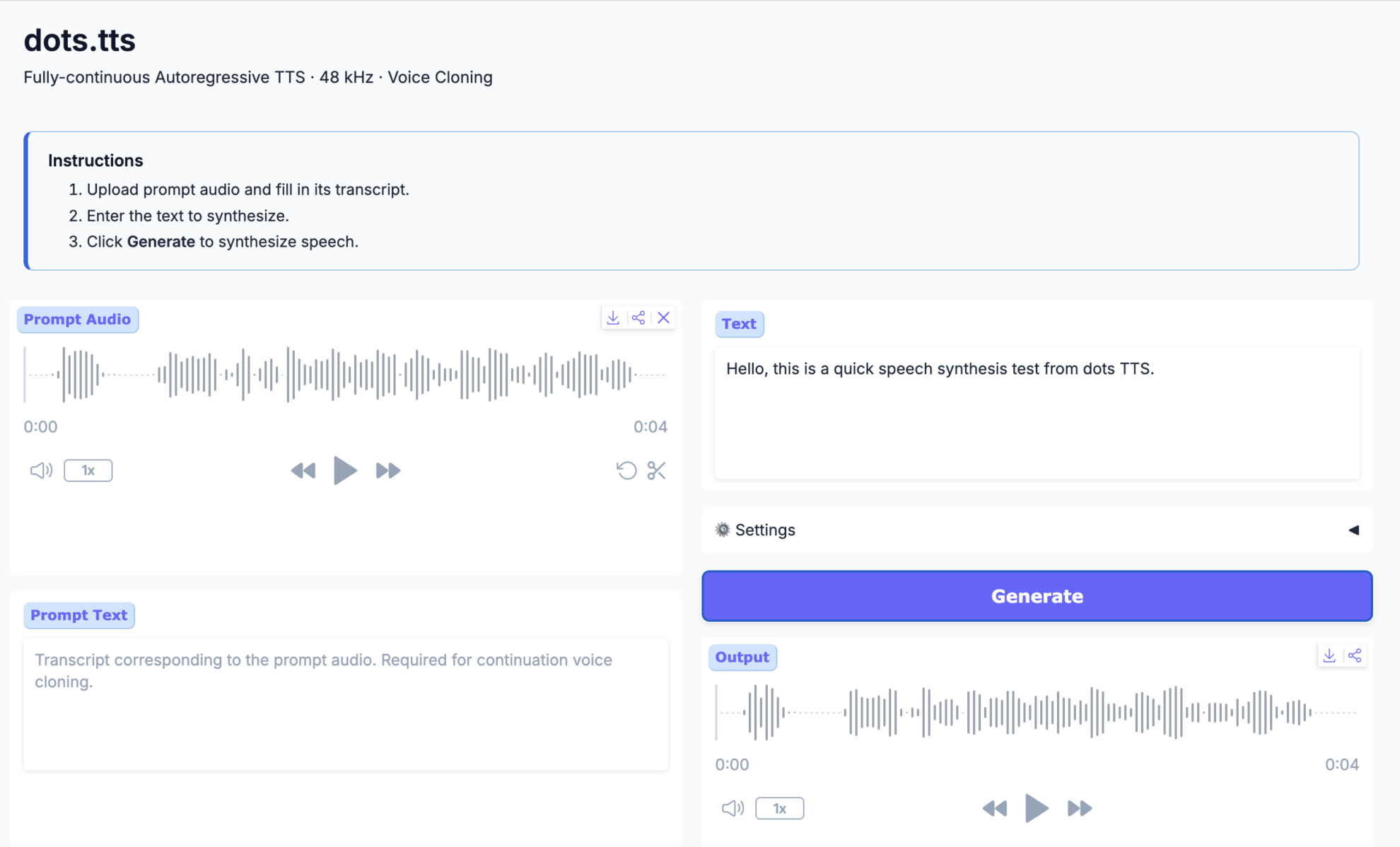
2. dots.tts : Un système de synthèse vocale autorégressif entièrement continu
Développé par rednote-hilab et sorti en juin 2026, dots.tts est un système de synthèse vocale autorégressif de bout en bout, entièrement continu et à 2 milliards de paramètres. Son architecture repose sur un encodeur sémantique, un LLM et une tête acoustique autorégressive d'adaptation de flux. Il modélise directement des représentations audio continues à partir d'AudioVAE 48 kHz, sans utiliser de jetons vocaux discrets.
Exécutez en ligne :https://go.hyper.ai/YT3g3
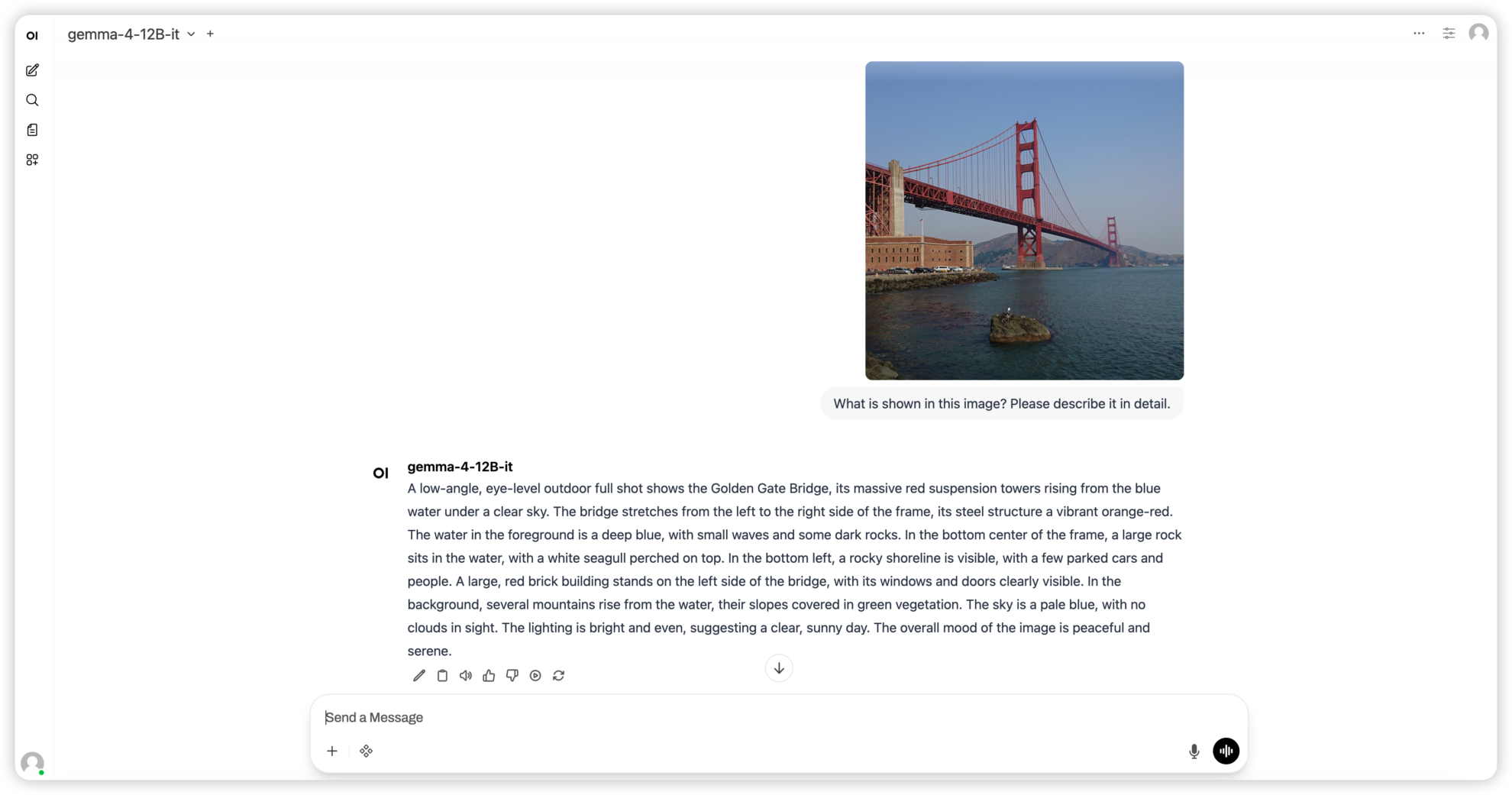
3. Gemma4 12B-it : Un modèle multimodal unifié de graphes, de textes et d'audio.
Gemma 4 12B est un modèle multimodal unifié de la série Gemma 4, développé par Google DeepMind. Son architecture sans encodeur projette directement les images et l'audio dans l'espace d'intégration du modèle linéaire multimodal (LLM). Il peut traiter les modalités texte, image et audio sans encodeur séparé et offre de puissantes capacités d'inférence, d'encodage et de compréhension multimodale au niveau des 12 milliards de paramètres.
Exécutez en ligne :https://go.hyper.ai/0713z
Interprétation des articles communautaires
1. À partir de 220 espèces de bactéries marines, des scientifiques ont reconstitué le système de classification microbienne hétérotrophe à l'aide d'un modèle à l'échelle du génome, identifiant huit types de flore métabolique.
Une équipe de l'Université de Californie du Sud a utilisé une base de données microbienne marine mondiale et des modèles métaboliques à l'échelle du génome pour analyser une quantité massive de génomes bactériens marins. En quantifiant la sensibilité des micro-organismes à l'utilisation de 11 types de substrats organiques, ils ont identifié 8 communautés métaboliques distinctes.
Voir le rapport complet :https://go.hyper.ai/dfq8T
2. La précision de l'estimation de profondeur atteint 0,9 ; Meta propose VLM³, démontrant que les modèles visuels sont intrinsèquement capables d'apprendre la 3D et réalise une modélisation unifiée pour de multiples tâches basée sur Qwen3-VL-4B.
Meta, en collaboration avec l'Université de Princeton, a proposé VLM³, qui, basé sur le modèle de langage visuel standard, réalise une modélisation unifiée pour quatre types de tâches : la compréhension 3D au niveau objet, l'estimation de profondeur métrique, la correspondance de pixels et la résolution de la pose de la caméra, grâce à une méthode d'organisation des données et un paradigme d'apprentissage unifiés. Cette approche a également permis d'évaluer systématiquement les limites de capacité du VLM standard en matière de perception 3D fine.
Voir le rapport complet :https://go.hyper.ai/NihJA
3. L’université de Cambridge et d’autres ont proposé un modèle fondamental au niveau du pixel pour les missions d’observation de la Terre, atteignant une précision de pointe (SOTA) dans de multiples missions.
Une équipe de recherche conjointe des universités de Cambridge, d'Aalto et de Bristol a développé un nouveau paradigme d'apprentissage des caractéristiques temporelles basé sur l'algorithme des jumeaux de Barlow. Ce paradigme permet aux modèles d'apprendre de manière autonome les variations spatio-temporelles stables de la surface terrestre, formant ainsi des représentations des caractéristiques de télédétection invariantes à l'échantillonnage temporel. S'appuyant sur ces travaux, l'équipe a également proposé TESSERA, un modèle de base de télédétection au niveau du pixel pour les données temporelles multimodales Sentinel-1/Sentinel-2.
Voir le rapport complet :https://go.hyper.ai/S3KBr
Articles populaires de l'encyclopédie
1. Modèle d'action mondial (WAM)
2. Intelligence artificielle explicable (XAI)
3. Modèle d'action du langage visuel (VLA)
4. Système à base de règles
5. Fusion de rangs réciproques
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








