Command Palette
Search for a command to run...
Sortie d'image En 4 étapes/qualité 4K/accélération 6x, PiD Utilise La Diffusion De Pixels Pour Unifier Le Décodage Et La Sortie Super-résolution ; SA-3DAO : Un Ensemble De Données Contenant 1 000 Paires d'images Réelles Associées À Des Maillages 3D Fabriqués À La Main Par Des artistes.

PiD est un nouveau paradigme de décodage d'espace latent développé par NVIDIA. Il redéfinit le processus de décodage VAE traditionnel en générant une diffusion de pixels conditionnelle, unifiant le décodage et le suréchantillonnage à super-résolution en un seul module de génération. Les modèles de diffusion latente traditionnels restaurent les variables latentes de l'image via un VAE, ce qui limite la résolution de sortie. De plus, les décodeurs orientés reconstruction peinent à récupérer les détails haute fréquence et ne peuvent corriger les artefacts dans les variables latentes.PiD introduit un adaptateur de variable latente léger sensible au bruit (adaptateur sensible à Sigma) pour injecter des variables latentes bruitées dans le réseau dorsal de diffusion spatiale des pixels.Cela permet au modèle de traiter à la fois les variables latentes entièrement débruitées et d'interrompre prématurément le processus de diffusion pour les variables latentes partiellement débruitées. Grâce à la technologie de distillation DMD2, l'inférence peut être réalisée en seulement quatre étapes de débruitage.
Le site web d'HyperAI propose désormais « PiD : Génération et édition d'images en super-résolution 4K », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/a34Cx
Bienvenue sur notre site web officiel pour plus d'informations :
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 19 au 26 juin :
* Jeux de données publics de haute qualité : 7
* Une sélection de tutoriels de haute qualité : 14
* Interprétation des articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de reconstruction d'objets 3D SAM Artist Objects
SAM 3D Artist Objects est un jeu de données d'appariement de maillages 3D publié par Meta en juin 2026. Il vise à évaluer les performances des algorithmes de reconstruction 3D pour les formes et les agencements d'objets dans des scènes réelles et est largement utilisé pour tester les performances des algorithmes de conversion d'images en objets 3D, l'optimisation de modèles et la recherche en vision par ordinateur. Ce jeu de données contient 1 000 paires d'images réelles associées à des maillages 3D créés manuellement par des artistes professionnels.
Utilisation en ligne :https://go.hyper.ai/rn2aF
2. Ensemble de données d'évaluation de la mémoire à long terme RHELM
RHELM est un jeu de données d'évaluation de la mémoire à long terme publié par Microsoft en 2026. Il vise à améliorer les capacités de mémoire à long terme, de raisonnement multi-sauts et de synthèse d'informations temporelles des grands modèles dans des scénarios complexes et dynamiques. Ce jeu de données est largement utilisé dans des contextes de recherche tels que l'évaluation de la mémoire temporelle à long terme des grands modèles de langage, la vérification des capacités d'interaction à long terme des assistants IA, le raisonnement multi-sauts des grands modèles, la fusion d'informations temporelles et la détection des hallucinations.
Utilisation en ligne :https://go.hyper.ai/OGkUl
3. Ensemble de données d'évaluation des connaissances culturelles multilingues MAKIEVAL
MAKIEVAL est un jeu de données d'évaluation des connaissances culturelles multilingues, publié en 2026 par le laboratoire de recherche MaiNLP de l'Université de Munich, en collaboration avec le Centre d'apprentissage automatique de Munich. Il vise à fournir un référentiel à grande échelle pour l'évaluation des connaissances culturelles multilingues des grands modèles de langage et est largement utilisé dans la recherche sur la représentation des connaissances multilingues et la modélisation des connaissances culturelles. Ce jeu de données contient des textes générés par sept grands modèles de langage dans 13 langues, 19 pays/régions et 6 domaines culturels, ainsi que leurs entités culturelles extraites automatiquement et les résultats de leur alignement avec Wikidata.
Utilisation en ligne :https://go.hyper.ai/v7zip
4. Ensemble de données d'extraction de preuves de la condition de requête Verbatim Spans
Verbatim Spans, publié en avril 2026 par l'Université technique de Vienne (TU Wien) en collaboration avec KRLabs, est un jeu de données d'extraction de preuves conditionnelles pour les requêtes multi-domaines. Il vise à établir un référentiel général pour l'entraînement des modèles d'extraction de preuves conditionnelles, largement applicable à l'augmentation des données de recherche (RAG) et aux tâches de réponse aux questions par extraction. Le jeu de données contient 174 383 lignes de données d'entraînement et 20 174 lignes de données de validation, couvrant trois principaux types de corpus : articles de traitement automatique du langage naturel, réponses aux questions multi-domaines et résultats de code et d'outils.
Utilisation en ligne :https://go.hyper.ai/hbpjR
5. Jeu de données Nemotron-SFT-Math-v4 pour l'inférence mathématique SFT
Nemotron-SFT-Math-v4 est un jeu de données de raisonnement mathématique publié par NVIDIA en mai 2026. Il vise à pallier les problèmes de qualité inégale, de trajectoires de raisonnement non standardisées, de faible précision et de diversité limitée des scénarios rencontrés dans les jeux de données mathématiques traditionnels, améliorant ainsi les capacités de raisonnement structuré, de raisonnement multi-trajectoires et de vérification des réponses du modèle. Ce jeu de données contient 545 431 exemples d'entraînement, dont 285 516 exemples de raisonnement COT (Content-Oriented Reasoning) et 259 915 exemples de raisonnement TIR (Tracking Inference), couvrant des scénarios mathématiques de niveau compétition et recherche en algèbre, géométrie, théorie des nombres, combinatoire et autres disciplines.
Utilisation en ligne :https://go.hyper.ai/6ooPw
6. Impact de l'IA sur l'emploi et le risque de licenciement : ensemble de données sur l'impact de l'IA sur l'emploi
L'ensemble de données synthétiques structurées d'apprentissage automatique « Impact de l'IA sur l'emploi et le risque de licenciement » analyse l'impact de l'intelligence artificielle sur l'emploi. Il vise à explorer l'influence de l'adoption de l'IA, de l'automatisation des tâches, des caractéristiques des emplois et des compétences de la main-d'œuvre sur les résultats en matière d'emploi dans l'économie moderne. Il est largement utilisé pour des tâches telles que la modélisation de la classification, l'analyse de la main-d'œuvre, la recherche sur l'impact de l'automatisation et l'aide à la décision en ressources humaines.
Utilisation en ligne :https://go.hyper.ai/38bZl
7. Transition climatique et énergétique mondiale 2000-2026 : Ensemble de données sur le climat et l’énergie à l’échelle mondiale
L’ensemble de données « Climat et transition énergétique mondiaux 2000-2026 » est un ensemble de données mondial sur le climat et la transition énergétique destiné à la recherche sur le changement climatique, la transition énergétique et la réduction des émissions de carbone. Il vise à décrire de manière systématique les processus mondiaux de changement climatique et de transition énergétique. Cet ensemble de données enregistre ces processus de 2000 à 2026, en couvrant les anomalies de température mondiales et régionales.
Utilisation en ligne :https://go.hyper.ai/ogrSa
Tutoriels publics sélectionnés
1. PiD : Génération et édition d’images en super-résolution 4K
PiD est un décodeur de super-résolution prêt à l'emploi développé par l'équipe NVIDIA. Les modèles de diffusion traditionnels utilisent un décodeur VAE pour restaurer la représentation latente d'une image, la résolution de sortie étant limitée à environ 1024 pixels. PiD remplace l'étape finale de décodage VAE par un processus de diffusion dans l'espace des pixels, ne nécessitant que 4 étapes de débruitage pour générer directement une image 4K nette, sans aucun post-traitement. Il surmonte ainsi le goulot d'étranglement de la résolution des méthodes traditionnelles sans modifier l'architecture du modèle original.
Exécutez en ligne :https://go.hyper.ai/a34Cx
2. Générateur vidéo LTX-2.3-turbo
LTX-2.3-turbo est un modèle de génération vidéo open source publié par Lightricks en mars 2026, conçu pour repousser les limites des capacités de génération vidéo open source. Ce modèle utilise une architecture de transformateur de diffusion avancée et la combine à des capacités de compréhension multimodale pour générer du contenu vidéo multi-résolution de haute qualité.
Exécutez en ligne :https://go.hyper.ai/oepch
3. DiffBrush : Génération de lignes de texte manuscrites
L'université de Nankai et l'institut Kunlun Tech ont conjointement publié le modèle de génération de lignes de texte manuscrit DiffBrush en août 2025, qui a été officiellement accepté par ICCV 2025 en octobre de la même année. Basé sur l'architecture VAE à diffusion stable + UNet, ce modèle prend en charge la saisie de texte anglais arbitraire et 496 styles d'écriture manuscrite issus du jeu de données IAM, et produit une image en niveaux de gris de 1024 × 64 pixels. Le contenu du texte et le style d'écriture sont contrôlables indépendamment. Son déploiement est léger et il peut être utilisé directement pour la génération d'ensembles d'entraînement OCR, l'augmentation de données manuscrites et la simulation de documents.
Exécutez en ligne :https://go.hyper.ai/qVvl5
4. RÉUTILISATION : Un modèle général d'amélioration de la parole
RE-USE est un modèle d'amélioration de la parole à usage général publié par NVIDIA en mars 2026. Basé sur l'architecture Mamba, il peut gérer des signaux vocaux bruités avec différents taux d'échantillonnage et types de dégradation, et est indépendant de la langue.
Exécutez en ligne :https://go.hyper.ai/MJ0p5
5. TADA-1b : Modèle unifié de parole et de langage
TADA-1b est un modèle unifié de parole et de langage, publié par l'équipe HumeAI en février 2026. Conçu spécifiquement pour les tâches de génération audio telles que la synthèse vocale, le clonage vocal et le doublage multilingue, ce modèle, basé sur Llama 3.2-1B, offre des capacités de génération audio légères, rapides et stables. Il est particulièrement adapté à la synthèse vocale en anglais (TTS), au clonage vocal à partir d'un seul exemple, aux longs récits et à la poursuite de la parole.
Exécutez en ligne :https://go.hyper.ai/nCSpT
6. Formation et visualisation Gsplat 3D Gaussian Splash
Gsplat est une bibliothèque de rastérisation 3D open source accélérée par CUDA, développée conjointement par Berkeley, NVIDIA, l'Université ShanghaiTech et d'autres institutions. Fortement optimisée par rapport à l'implémentation originale, elle réduit la consommation de mémoire d'entraînement d'un facteur 4 et le temps d'entraînement de 151 TP3T. Ses principaux atouts techniques sont : un moteur de rastérisation différentielle CUDA haute performance, une stratégie de contrôle adaptatif de la densité gaussienne, un système de gestion des données flexible compatible avec les formats de données courants tels que COLMAP, et une interface de visualisation web en temps réel basée sur Viser. Ses applications couvrent les jumeaux numériques, la perception de l'environnement pour la conduite autonome, la numérisation du patrimoine culturel et la synthèse visuelle pour le e-commerce.
Exécutez en ligne :https://go.hyper.ai/Zihdr

7. DVD : Estimation déterministe de la profondeur vidéo basée sur des a priori génératifs
DVD (Deterministic Video Depth Estimation) est le premier cadre d'estimation de profondeur vidéo déterministe proposé par l'équipe de l'Université des sciences et technologies de Hong Kong (Guangzhou) en mars 2026. En transformant le modèle de diffusion vidéo pré-entraîné (Wan2.1) en un seul régresseur de profondeur à propagation avant, il élimine complètement le problème d'illusion géométrique causé par le hasard tout en maintenant la forte connaissance sémantique a priori du modèle génératif.
Exécutez en ligne :https://go.hyper.ai/AisLp
8. Fondation 1 : Génération d’échantillons de texte structuré en musique
Foundation-1, développé par l'équipe de RoyalCities et sorti en mars 2026, est un modèle de génération audio à partir de texte, conçu pour les flux de production musicale professionnels. La version officielle prend en charge la génération par couches, permettant aux utilisateurs de personnaliser les familles d'instruments, les sous-genres, les timbres, les effets, les accords théoriques, le tempo/la tonalité et la durée des mesures afin de générer des boucles musicales rythmiquement synchronisées et tonalement cohérentes. De plus, le logiciel propose une démo web unifiée offrant des fonctionnalités de génération interactives complètes.
Exécutez en ligne :https://go.hyper.ai/NxUAC
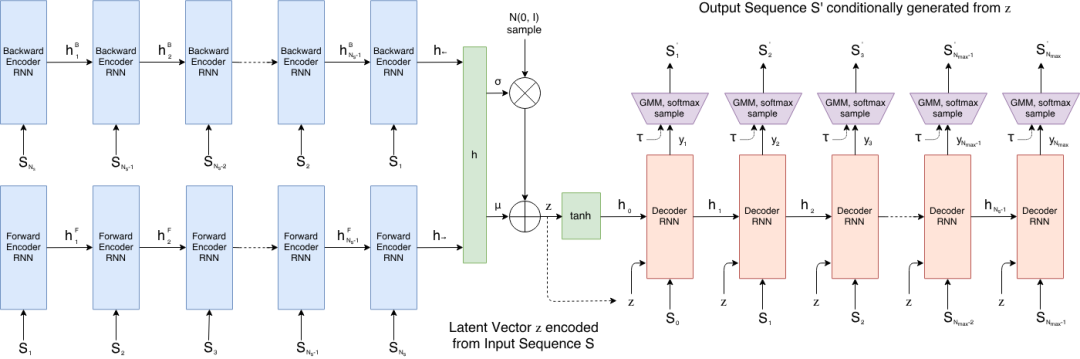
9. Sketch-RNN : Génération de croquis vectoriels et interpolation spatiale latente
Sketch-RNN est un modèle de génération de séquences de croquis vectoriels développé par l'équipe Google Brain en 2017. Cette méthode est spécifiquement conçue pour les données de croquis dessinés à la main, incluant les décalages de traits et l'état du stylet. Elle apprend les représentations latentes successives des croquis et génère de nouvelles séquences de croquis vectoriels. Sketch-RNN utilise une architecture encodeur-décodeur : le croquis d'entrée est projeté dans un espace latent, puis un décodeur de réseau neuronal récurrent génère progressivement les traits.
Exécutez en ligne :https://go.hyper.ai/HmcT9
10. Galaxy-Deconv : un cadre de déconvolution pour les images de galaxies obtenues par lentille gravitationnelle faible
Galaxy-Deconv a été développé par Tianyao Li de l'Université Tsinghua et Emma Alexander de l'Université Northwestern. Ce projet est consacré à la restauration d'images de galaxies faiblement déformées par lentille gravitationnelle. Il utilise l'algorithme ADMM déplié et prêt à l'emploi pour déconvoluer les images de galaxies affectées par le flou de la fonction d'étalement du point (PSF) et le bruit. Ce tutoriel présente les flux de travail courants de déconvolution de galaxies dans un notebook, couvrant la simulation d'images, le chargement des données COSMOS, l'inférence de déconvolution, la vérification du jeu de données HDF5 et des exercices de déconvolution de base.
Exécutez en ligne :https://go.hyper.ai/qGvI1
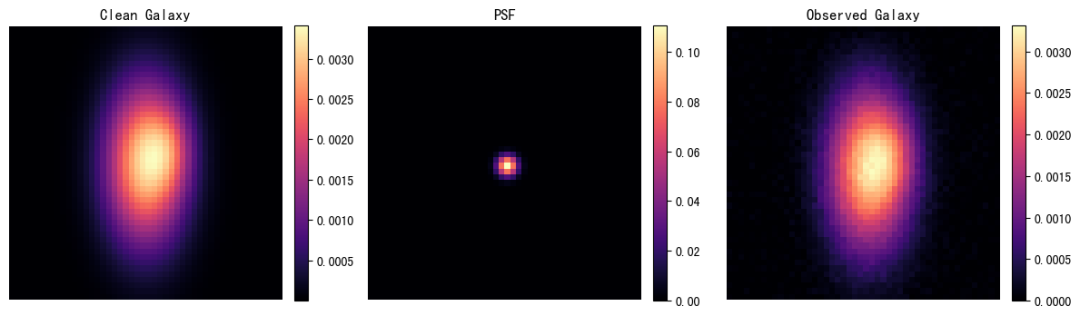
11. NuExtract3 : un modèle multimodal de compréhension de documents et d’extraction d’informations structurées
NuExtract3 est un modèle de langage visuel multimodal à 4 milliards de paramètres, développé par NuMind et publié en juin 2026. Conçu spécifiquement pour la compréhension de documents, il intègre l'extraction d'informations structurées et la conversion d'images de documents en Markdown. Il prend en charge les entrées de texte, d'images et de contenu mixte (texte et image) et peut générer directement des résultats structurés à partir de modèles JSON fournis par l'utilisateur, en préservant intégralement les tableaux, les formules et la mise en page.
Exécutez en ligne :https://go.hyper.ai/xirTj
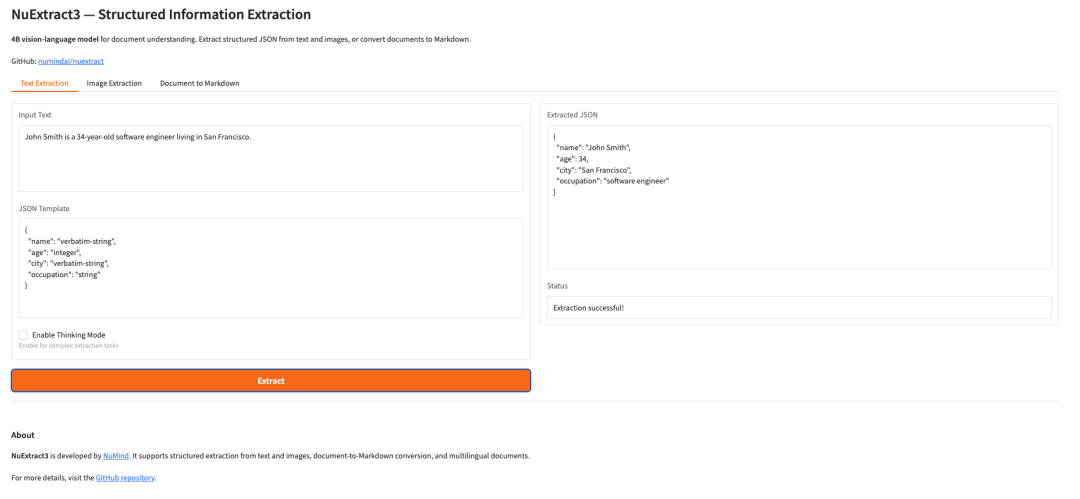
12. DiffusionGemma : un modèle de génération de texte à haute vitesse basé sur la diffusion discrète
DiffusionGemma est un modèle de génération de texte développé par Google DeepMind à l'aide de techniques de diffusion discrète. Il utilise une architecture de type « mix of experts » (MoE) avec 26 milliards de paramètres, pour un total de 25,2 milliards, dont seulement 3,8 milliards sont valides. Grâce à un échantillonnage par diffusion parallèle au niveau des blocs, il atteint des vitesses de génération de texte ultra-rapides, produisant plus de 1 100 jetons par seconde sur un seul GPU H100.
Exécutez en ligne :https://go.hyper.ai/HV3eM
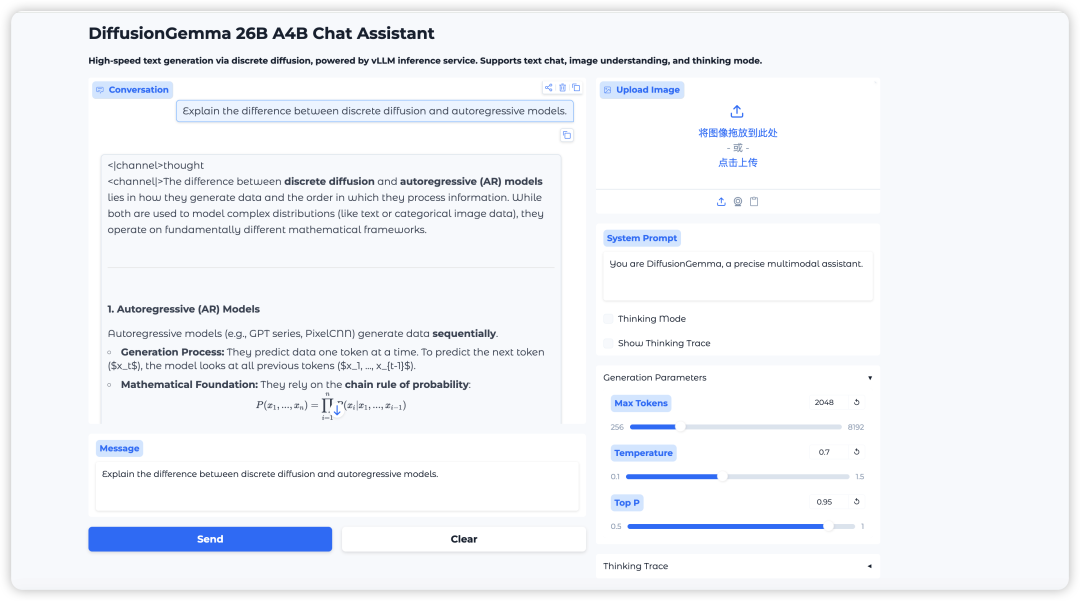
13. TripoSplat : Générez des ressources gaussiennes 3D de haute qualité à partir d'une seule image.
TripoSplat est une méthode de génération de modèles gaussiens 3D à partir d'une seule image, développée conjointement par VAST-AI Research et TripoAI et publiée en mai 2026. Ce modèle convertit une image 2D en un modèle gaussien 3D de haute qualité et permet de contrôler le nombre de distributions gaussiennes. Il utilise la technologie DeG (Density-Sampled Gaussian), qui distribue les centres des gaussiennes de manière adaptative en fonction de la complexité géométrique de l'objet, et VecSeq pour réordonner de manière déterministe les variables latentes désordonnées, améliorant ainsi la stabilité de l'apprentissage.
Exécutez en ligne :https://go.hyper.ai/wOxUG
14. North Mini Code 1.0 : Un modèle d’agent pour la génération de code et les tâches d’ingénierie logicielle
North Mini Code 1.0 est un modèle de code pondéré ouvert, publié par Cohere et Cohere Labs en juin 2026. Optimisé pour la génération de code, les tâches de points de terminaison et les scénarios d'ingénierie logicielle d'agents, ce modèle prend en charge les longues sessions de codage, le raisonnement sur le code, les appels d'outils et la pensée entrelacée. Il excelle notamment dans l'implémentation de fonctionnalités, l'écriture de scripts, le débogage, la planification des tâches de points de terminaison et les flux de travail d'ingénierie logicielle multi-itérations.
Exécutez en ligne :https://go.hyper.ai/ycCuG

Interprétation des articles communautaires
1. Le MIT et IBM ont publié ChartNet, le plus grand ensemble de données de graphiques synthétiques à ce jour, générant 1,5 million d'échantillons de graphiques diversifiés.
Un groupe d'experts du MIT, du MIT-IBM Computing Research Lab et d'IBM Research a proposé ChartNet, un ensemble de données multimodales de haute qualité contenant des millions d'enregistrements pour la compréhension des graphes, conçu pour faire progresser les capacités de compréhension et de raisonnement des graphes.
Voir le rapport complet :https://go.hyper.ai/Kk87Q
2. Le dernier document de Google DeepMind révèle l'objectif ultime de l'IA : de l'AGI à l'ASI, il existe 4 voies et 6 obstacles.
Google DeepMind, en collaboration avec plusieurs universités de renom, a publié un nouvel article explorant les questions fondamentales liées à l'évolution de l'intelligence artificielle générale (IAG) vers la superintelligence artificielle (SIA). Cette recherche envisage l'intelligence comme un continuum, analysant avec rigueur les trajectoires potentielles et les obstacles que l'IA rencontrera dans son évolution, une fois qu'elle aura dépassé le niveau humain moyen. L'article offre un cadre structuré et objectif pour comprendre la trajectoire à long terme du développement de l'IA.
Voir le rapport complet :https://go.hyper.ai/AOObx
3. Tirant parti des capacités contextuelles étendues de Gemini 1.5, le système de santé conversationnel de Google, AMIE, a atteint le niveau de raisonnement d'un médecin généraliste dans 100 scénarios impliquant de multiples visites de patients.
Une étude récente menée par Google DeepMind et Google Research a permis de développer un nouveau système d'agent intelligent basé sur le modèle LLM et s'appuyant sur leur système de santé conversationnel AMIE. Ce système facilite la gestion clinique et optimise le dialogue médecin-patient pour de multiples scénarios de suivi. AMIE exploite les capacités de contextualisation étendue du modèle Gemini, combinant recherche contextuelle et raisonnement structuré afin de garantir que ses résultats soient conformes aux dernières recommandations de pratique clinique et aux catalogues de prescriptions médicamenteuses.
Voir le rapport complet :https://go.hyper.ai/65aHo
4. L'IA des matériaux se dirige vers une « ère explicable » : une équipe japonaise perce la boîte noire de la spectroscopie à haute dimension, identifiant des caractéristiques clés pour la découverte de nouveaux matériaux.
Une équipe de recherche de l'Institut des sciences de Tokyo, au Japon, a proposé une méthode d'interprétation de données spectrales multidimensionnelles basée sur l'apprentissage profond, en science des matériaux. Les chercheurs ont constitué un jeu de données de calculs ab initio contenant les spectres d'absorption optique de 2 681 oxydes, chalcogénures et composés apparentés. Après correction de l'énergie et de la forme du seuil d'absorption, les résultats obtenus présentent une concordance nettement améliorée avec les spectres expérimentaux publiés, comparativement aux calculs classiques de la théorie de la fonctionnelle de la densité.
Voir le rapport complet :https://go.hyper.ai/VJbaU
Articles populaires de l'encyclopédie
1. Modèle de langage étendu (LLM)
2. Structure
3. Modèle d'action mondial (WAM)
4. Encodage de position rotationnelle (RoPE)
5. Compréhension linguistique multitâche à grande échelle (MMLU)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








