Command Palette
Search for a command to run...
Révolution TTS Sans Échantillonnage ! Quelques Secondes D’audio De Référence Suffisent : OmniVoice Vous Permet De Cloner Facilement Des Centaines De Langues ; 17 Langues En Une Seule Fois : MDPbench Résout Le Problème Majeur De L’analyse Syntaxique Des Systèmes De Texte À Faibles ressources.

Les modèles de synthèse vocale (TTS) existants, basés sur le principe du zéro-shot, ne prennent généralement en charge que quelques langues, ignorant un grand nombre de langues à faibles ressources. Pour pallier cette limitation,L'équipe Kaldi de nouvelle génération des laboratoires d'IA de Xiaomi a lancé OmniVoice, un modèle TTS multilingue à grande échelle et sans exemple d'apprentissage, qui prend en charge plus de 600 langues.OmniVoice abandonne l'architecture traditionnelle en cascade à deux étapes, complexe, et adopte un cadre simplifié à une seule étape, discret et non autorégressif (NAR), pour associer directement le texte à des marqueurs acoustiques. Entraîné sur 581 000 heures de données open source, OmniVoice offre la couverture linguistique la plus étendue à ce jour.
Actuellement, le site web HyperAI a lancé [la section/fonctionnalité concernée].OmniVoice : Prend en charge la synthèse vocale de haute qualité dans plus de 600 languesVenez l'essayer !
Utilisation en ligne :https://go.hyper.ai/BvKri
Bienvenue sur notre site web officiel pour plus d'informations :
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 11 au 17 avril :
* 11 jeux de données publics de haute qualité
* Une sélection de tutoriels de haute qualité : 6
* Analyse des articles de la communauté : 2 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en avril : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données sur le risque d'AVC
Stroke Risk est un ensemble de données destiné à l'analyse et à la prédiction du risque d'AVC dans le contexte des soins de santé. Fondé sur des facteurs de risque cliniques courants, cet ensemble de données comprend des informations démographiques, des antécédents médicaux, des facteurs liés au mode de vie et des indicateurs clés de santé. Il reflète la probabilité de survenue d'un AVC selon différentes conditions de santé et de mode de vie, dans le but d'aider les modèles d'apprentissage automatique à prédire et analyser le risque d'AVC, à identifier les principaux facteurs d'influence et, par conséquent, à améliorer les capacités de dépistage précoce et de prévention.
Utilisation en ligne :https://go.hyper.ai/6CTH5
2. Ensemble de données ToolACE Complex Tool Learning Dialogue
ToolACE est un ensemble de données automatisé pour l'apprentissage d'outils, basé sur un pipeline d'agents. Il contient des exemples de conversations complexes, faisant appel à 26 507 API différentes. Les échantillons sont générés par des interactions multi-agents et soumis à un processus d'assurance qualité en deux étapes : vérification des règles et validation du modèle. Chaque dialogue représente une tâche d'extraction et d'analyse d'informations multi-sources et multi-étapes, simulant de manière réaliste des scénarios d'utilisation d'outils et fournissant des données d'entraînement de grande valeur pour l'apprentissage de bas niveau (LLM).
Utilisation en ligne :https://go.hyper.ai/o3E12
3.Ensemble de données de référence culturelles latino-américaines CHOCLO
Le jeu de données CHOCLO est un jeu de données de référence conçu spécifiquement pour évaluer la représentation de la culture latino-américaine dans les modèles de langage. Il vise à évaluer la précision de ces modèles dans la représentation de cette culture et est conçu pour traiter des problèmes concrets tels que la sous-estimation, les omissions et les biais qui la concernent.
Utilisation en ligne :https://go.hyper.ai/pjVQi
4. Ensemble de données de référence pour la recherche interdisciplinaire approfondie DRACO
L'ensemble de données DRACO, publié par l'équipe Perplexity, est un ensemble de données conçu pour évaluer des tâches de recherche complexes et vise à évaluer systématiquement les capacités globales des systèmes de recherche approfondie en termes de précision, d'exhaustivité et d'objectivité.
Utilisation en ligne :https://go.hyper.ai/hIWgS
5. Ensemble de données de référence pour l'analyse syntaxique multilingue de documents MDPBench
MDPBench est un ensemble de données de référence pour l'analyse de documents numériques et photographiques multilingues, conçu pour évaluer et améliorer la capacité des modèles à analyser des documents multilingues dans des scénarios complexes du monde réel.
Utilisation en ligne :https://go.hyper.ai/1Mc9a
6. Ensemble de données World Model Bench
World Model Bench est le premier banc d'essai mondial permettant d'évaluer les capacités cognitives des modèles du monde et des systèmes d'IA incarnée. Il vise à dépasser les évaluations traditionnelles de la qualité d'image et vidéo, en se concentrant sur les capacités cognitives des modèles. Cet ensemble de données est conçu pour évaluer les capacités des modèles du monde, selon trois dimensions fondamentales : la perception, la cognition et l'incarnation. Il est subdivisé en 10 catégories de tâches, incluant la compréhension de l'environnement, la reconnaissance et la classification d'entités, et le raisonnement prédictif. Il comprend 100 scénarios variés conçus pour évaluer systématiquement les capacités cognitives et décisionnelles des modèles dans des environnements complexes.
Utilisation en ligne :https://go.hyper.ai/hY0aP
7. Ensemble de données pour la détection de la fraude à la carte de crédit
Le jeu de données Credit Card Fraud permet de détecter la fraude à la carte bancaire dans les transactions financières. Il vise à aider les modèles d'apprentissage automatique à identifier et modéliser les transactions anormales, en s'attachant à résoudre le problème du déséquilibre extrême des classes dans les scénarios financiers, et ainsi améliorer les capacités de détection des modèles en situation réelle.
Utilisation en ligne :https://go.hyper.ai/3d8nS
8. Ensemble de données pour la détection des courriels indésirables
Le jeu de données de détection de spam est un ensemble de données d'emails étiquetés destiné aux tâches de détection de spam. Ce jeu de données vise à soutenir la recherche en modélisation de classification, en traitement automatique du langage naturel et en ingénierie des caractéristiques, et à améliorer la capacité du modèle à identifier le spam.
Utilisation en ligne :https://go.hyper.ai/HkpX5
9. Ensemble de données de questions vocales simples
Simple Voice Questions est un ensemble de données audio court publié par Google. Cet ensemble multilingue contient de courtes questions audio dans 17 langues, provenant de 26 régions et enregistrées par environ 700 locuteurs. Chaque locuteur fournit jusqu'à 250 échantillons vocaux, couvrant plusieurs langues telles que l'arabe, l'anglais, le japonais, le coréen et l'hindi, et incluant diverses conditions d'enregistrement : environnements calmes, bruits de fond et bruit de la circulation.
Utilisation en ligne :https://go.hyper.ai/lrKpK
10. COCO-2017 - Jeu de données de détection d'images vietnamiennes
COCO-2017-Vietnamese est un jeu de données d'extension de localisation vietnamienne, basé sur le jeu de données Common Objects in Context 2017 proposé par Microsoft, et compilé et publié par la communauté AI Enthusiasm. Ce jeu de données introduit des traductions vietnamiennes de haute qualité en plus des descriptions d'images originales en anglais, fournissant ainsi un référentiel complet dans un cadre bilingue, adapté à des tâches telles que la génération automatique de légendes d'images et l'apprentissage multimodal.
Utilisation en ligne :https://go.hyper.ai/VM6gY
11. Jeu de données GPT-5.4 pour le raisonnement étape par étape
Le jeu de données GPT-5.4, dédié au raisonnement étape par étape, est un ensemble de données de raisonnement synthétique à haute densité conçu pour la modélisation du raisonnement à longue chaîne (CoT) et les tâches de résolution de problèmes complexes. Ce jeu de données contient environ 1 500 exemples de haut niveau couvrant des domaines complexes tels que les mathématiques, la programmation et la médecine, la difficulté des tâches étant uniformément fixée aux niveaux « Grand Maître » et « Au-delà du doctorat ».
Utilisation en ligne :https://go.hyper.ai/HjJlT
Tutoriels publics sélectionnés
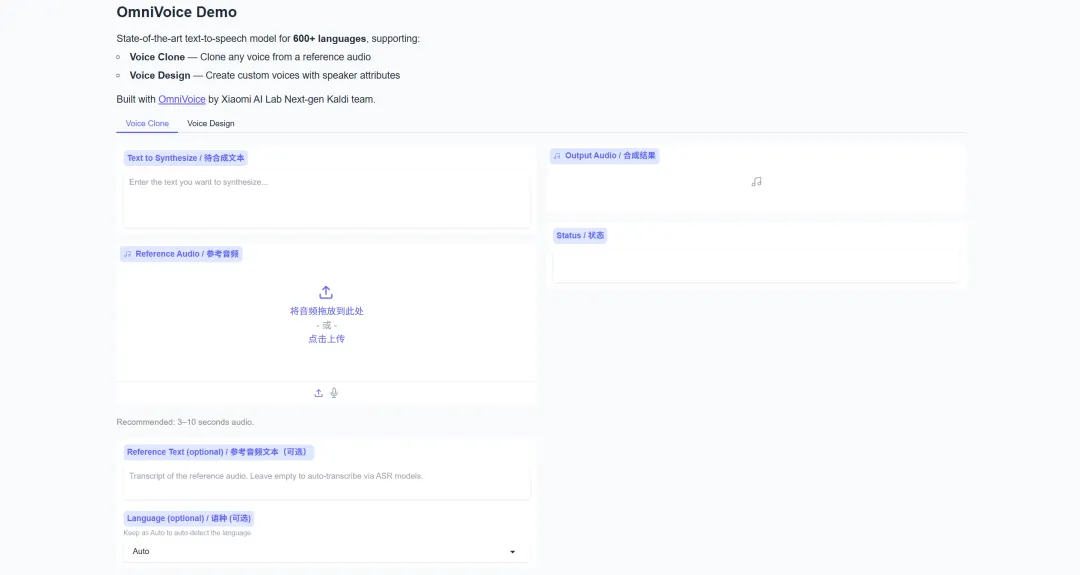
1. OmniVoice : Prend en charge la synthèse vocale de haute qualité dans plus de 600 langues.
OmniVoice est un modèle de synthèse vocale multilingue développé par l'équipe Kaldi nouvelle génération du laboratoire d'IA de Xiaomi, prenant en charge la synthèse vocale de haute qualité dans plus de 600 langues. Basé sur une architecture de décodage itérative non masquée, le projet implémente trois fonctions principales : le clonage vocal, la conception vocale et la voix automatique.
Exécutez en ligne :https://go.hyper.ai/BvKri
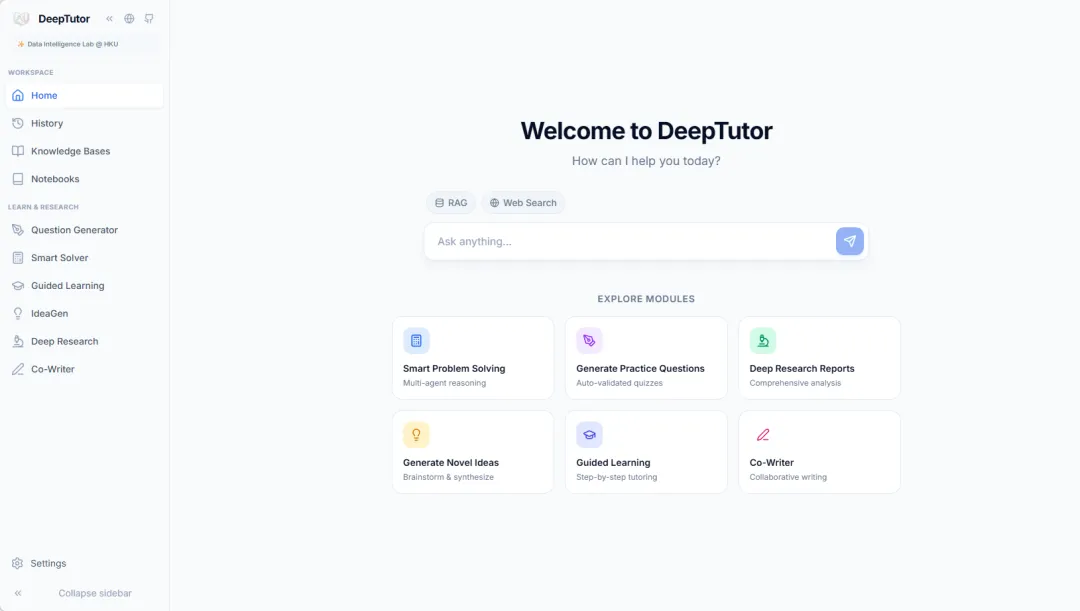
2. Assistant d'apprentissage personnel DeepTutor
DeepTutor, lancé en mars 2026 par le Laboratoire d'intelligence des données de l'Université de Hong Kong, est un système d'enseignement complet basé sur l'IA et un assistant d'apprentissage personnel. Ce projet intègre quatre modules fonctionnels principaux : un système de questions-réponses basé sur une base de connaissances documentaires massive, une visualisation interactive de l'apprentissage, le renforcement des connaissances et la génération de questions d'entraînement, ainsi qu'une recherche approfondie et la création de contenu original, offrant ainsi aux apprenants une expérience d'apprentissage intelligente et intégrée.
Exécutez en ligne :https://go.hyper.ai/8YnI3
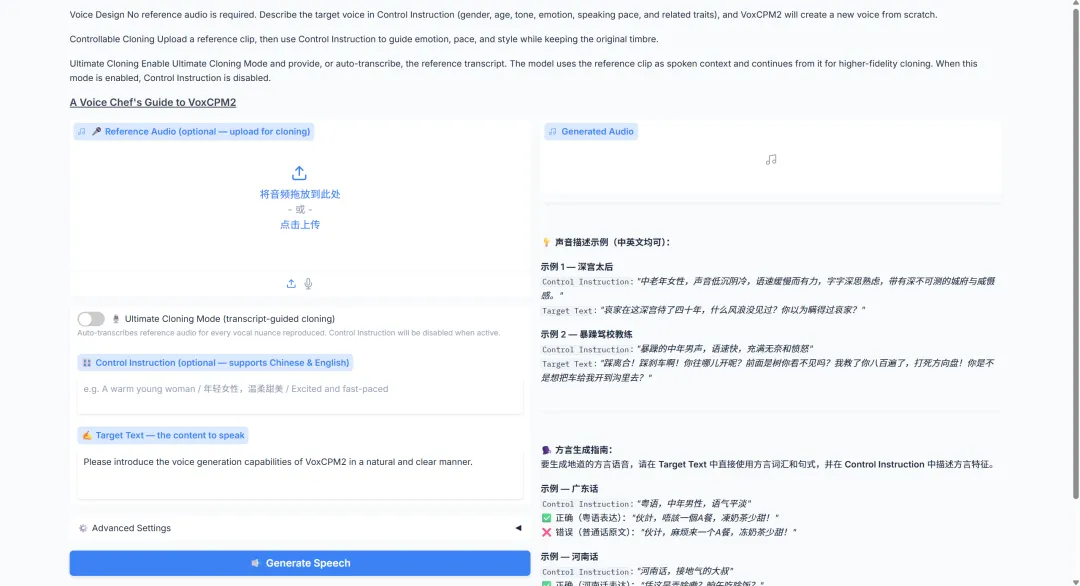
3. Reproduction vocale VoxCPM2 : plus de 30 langues, 9 dialectes
VoxCPM2 est un modèle de synthèse vocale sans tokenizer à 2 milliards de paramètres, publié par OpenBMB en avril 2026. Il prend en charge 30 langues, ne nécessite aucune balise de langue supplémentaire et couvre divers cas d'utilisation, notamment la génération de nouveaux timbres, le clonage contrôlé à partir d'un fichier audio de référence, le clonage extrême par combinaison d'un fichier audio de référence et d'une transcription, ainsi que l'ajustement automatique du ton et de l'expressivité en fonction du contenu textuel. Les spécifications officielles mettent également en avant une sortie à 48 kHz, la compatibilité avec un fichier audio de référence à 16 kHz et une expressivité contextuelle.
Exécutez en ligne :https://go.hyper.ai/RLgK9
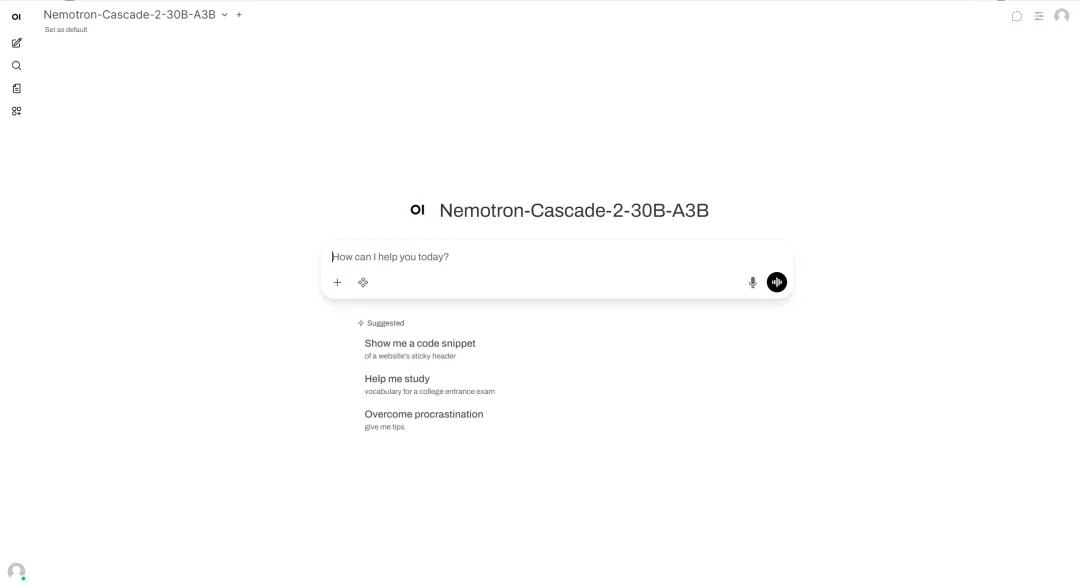
4. Déploiement en un clic du Nemotron-Cascade-2-30B-A3B
Publié par NVIDIA en mars 2026, Nemotron-Cascade-2-30B-A3B est un modèle de langage open source de grande taille, doté de 30 milliards d'éléments d'apprentissage (MoE) et d'environ 3 milliards de paramètres activés. Il a été entraîné sur Nemotron-3-Nano-30B-A3B-Base. Ce modèle est principalement conçu pour offrir de puissantes capacités d'inférence, de dialogue, de traitement du code et d'interaction, tout en prenant en charge simultanément les modes de pensée et d'instruction.
Exécutez en ligne :https://go.hyper.ai/GoEaW
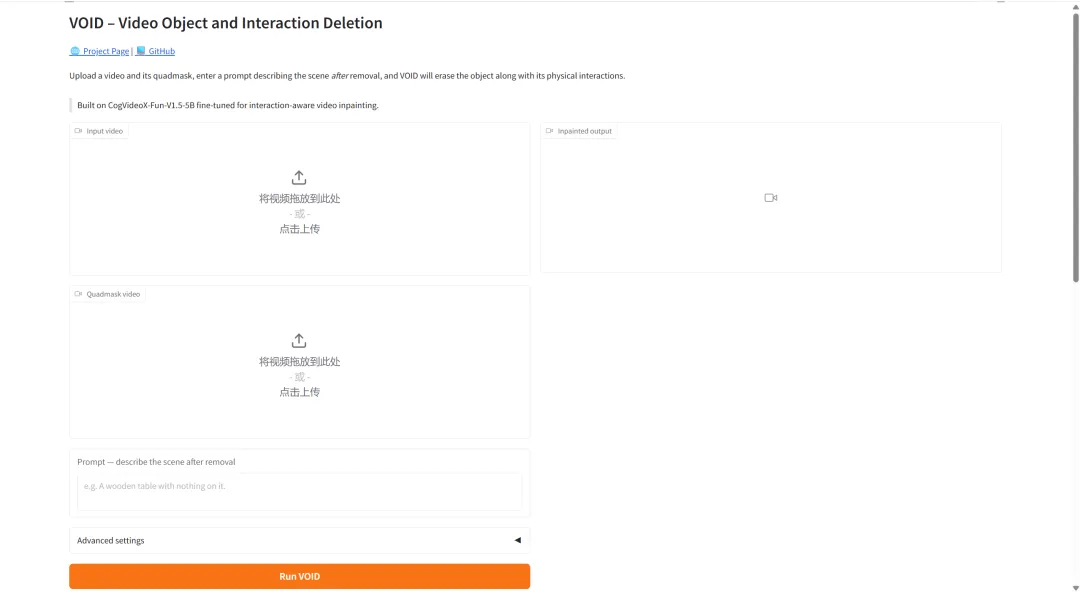
5. Netflix VOID : Une technologie révolutionnaire de suppression d'objets vidéo avec prise en compte physique.
Netflix VOID est un modèle de montage vidéo open source mis à disposition conjointement par l'équipe Netflix et l'Université de Sofia en avril 2026. Avec 5 milliards de paramètres, le modèle Netflix VOID est conçu pour résoudre le problème de la cohérence physique dans la post-production cinématographique, visant à surmonter les limitations des techniques traditionnelles de finalisation vidéo dans la gestion de la logique causale des interactions complexes entre objets.
Exécutez en ligne :https://go.hyper.ai/uZoMl
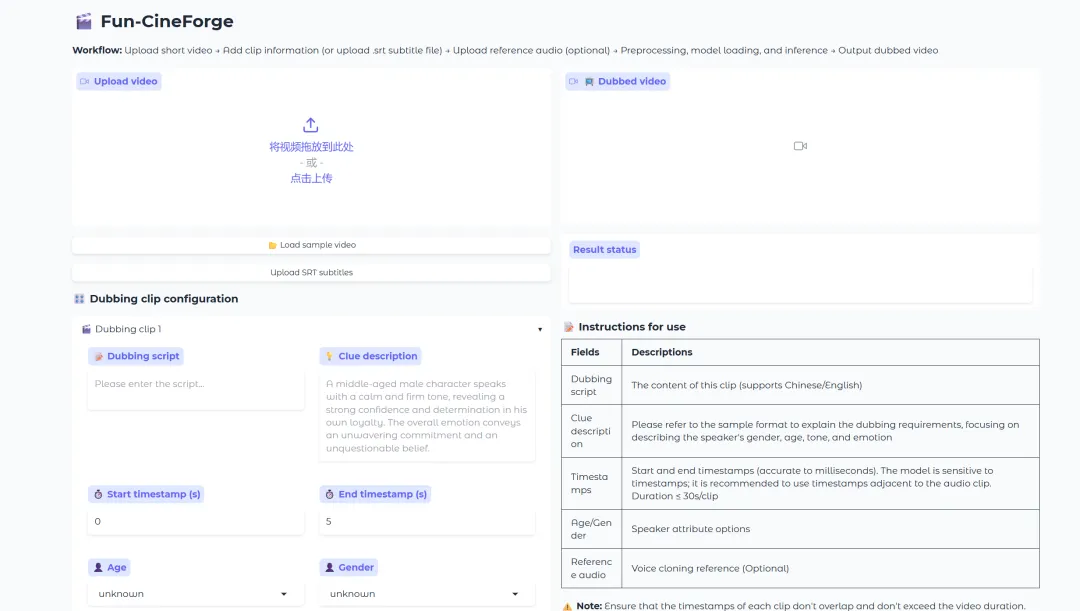
6. Fun-CineForge : Un modèle unifié pour le doublage sans échantillon dans divers contextes cinématographiques et télévisuels
Fun-CineForge est un projet de doublage de films sans prise de vue, lancé conjointement par l'équipe vocale de Tongyi Labs et l'Université des sciences et technologies de Chine en janvier 2026. Le projet comprend un pipeline de données de bout en bout pour la production d'ensembles de données de doublage à grande échelle et un modèle de doublage basé sur un modèle multimodal étendu (LMM), conçu pour divers scénarios de films.
Exécutez en ligne :https://go.hyper.ai/DyQKk
Interprétation des articles communautaires
1. Conception de novo, pilotée par l'IA, de diverses protéines de liaison à de petites molécules : une équipe sud-coréenne a découvert une protéine capable de reconnaître sélectivement les hormones du stress.
Une équipe de recherche du Département des sciences biologiques de l'Institut supérieur coréen des sciences et technologies (KAIST) a utilisé des méthodes de génération de structures protéiques et de conception de séquences basées sur l'apprentissage profond pour concevoir de novo diverses protéines de liaison à de petites molécules. Ces protéines utilisent le repliement de type NTF2 comme squelette universel et sont ensuite transformées en capteurs similaires à la dimérisation chimiquement induite (CID). Les chercheurs ont ainsi conçu avec succès une protéine capable de reconnaître sélectivement le cortisol, une hormone du stress, et ont développé un biocapteur d'intelligence artificielle basé sur cette protéine.
Voir le rapport complet :https://go.hyper.ai/FpAXm
2. Une équipe française a prédit avec succès 2,39 millions de protéines antiphages et a utilisé un modèle d'apprentissage profond pour cartographier l'immunité antivirale bactérienne.
Des chercheurs de l'Institut Pasteur en France ont développé et optimisé trois modèles d'apprentissage profond complémentaires pour la prédiction à grande échelle de la résistance aux phages. Le modèle ALBERT_DF s'appuie exclusivement sur le contexte génomique local pour l'inférence ; ESM_DF utilise un modèle de langage protéique pour analyser les séquences d'acides aminés ; et GeneCLR_DF intègre les informations de séquence au contexte génomique.
Voir le rapport complet :https://go.hyper.ai/J5Oz3
Articles populaires de l'encyclopédie
1. Compétences
2. Vérité de base
3. L'humain au cœur du processus
4. Compréhension du langage multitâche à grande échelle (MMLU)
5. Fusion de rangs réciproques
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








