Command Palette
Search for a command to run...
MiniCPM5-1B, Entraîné À l'aide De RL+OPD, Atteint Des Performances De Pointe (SOTA) Sur De Multiples Tâches Complexes ; l'ensemble De Données CHI-Bench Pour l'évaluation Des Agents Médicaux, Conçu Pour l'automatisation Des Processus De Soins De Santé Complexes, a Été publié.

MiniCPM5-1B est un modèle de langage open source doté d'un milliard de paramètres, conçu pour le déploiement en périphérie et les environnements aux ressources limitées. Premier modèle de la série MiniCPM5, il repose sur l'architecture standard Llama et propose notamment les fonctionnalités suivantes : Un paradigme d'inférence hybride basé sur les étiquettes. De plus, ce modèle exploite des techniques d'entraînement RL+OPD avancées pour améliorer significativement les performances de base tout en éliminant efficacement la redondance des sorties. Il prend en charge nativement les contextes ultra-longs jusqu'à 131 000 caractères.Il a atteint un niveau de pointe open-source (SOTA) de niveau 1B dans des tâches complexes telles que l'invocation d'agents et la synthèse de code.Ce modèle évite efficacement les problèmes de latence et de confidentialité liés à l'inférence dans le cloud, offrant ainsi une solution idéale pour la construction d'une plateforme d'IA locale performante.
Le site web d'HyperAI présente désormais « MiniCPM5-1B : un LLM 1B haute efficacité pour les applications Edge ». Essayez-le !
Utilisation en ligne :https://go.hyper.ai/OBlhv
Bienvenue sur notre site web officiel pour plus d'informations :
Aperçu rapide des mises à jour du site web hyper.ai du 30 mai au 5 juin :
* Jeux de données publics de haute qualité : 6
* Une sélection de tutoriels de haute qualité : 5
* Analyse d'un article de la communauté : 1 article
* Entrées d'encyclopédie populaire : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'évaluation comparative des agents intelligents médicaux chi-bench
Chi-Bench est un jeu de données d'évaluation d'agents de santé publié par Actava AI en 2026. Ce jeu de données construit un environnement de simulation d'activité de santé haute fidélité, intégrant 20 systèmes d'application de santé via l'interface ouverte MCP (Model Context Protocol) et fournissant une base de connaissances contenant 1 279 documents relatifs aux opérations de santé. Les scénarios d'évaluation couvrent trois grands domaines du système de santé américain : la gestion des autorisations préalables, la gestion des citations pour les assureurs santé et les prestataires d'assurance, et la gestion des soins de santé à l'échelle de la population.
Utilisation en ligne :https://go.hyper.ai/j8pCr
2. Ensemble de données parallèles de traduction multilingue SMOL
SMOL est un ensemble de données de traduction professionnelle publié par Google en 2025. Cet ensemble comprend des textes traduits par des professionnels dans 221 langues, dont l'amharique, le swahili et l'afar, ainsi que dans des langues moins fréquemment annotées ou des langues régionales pour lesquelles les données sont rares. Il couvre un large éventail de paires de langues, incluant des traductions professionnelles et des textes fournis par des bénévoles, et ajoute des données verticales et des annotations factuelles relatives au domaine médical pour certaines langues.
Utilisation en ligne :https://go.hyper.ai/84QS4
3. Base de données de connaissances TACK sur les chimères
TACK est une base de connaissances standardisée, un ensemble de données et un jeu de données de référence publiés par le Laboratoire d'IA pour l'ingénierie moléculaire en 2026. Elle vise à pallier les problèmes de rareté des données, de manque d'évaluations rigoureuses et de couverture limitée des jeux de données de référence d'apprentissage automatique PROTAC existants. Elle est largement utilisée dans des domaines tels que la prédiction de l'activité de dégradation des protéines PROTAC, la recherche sur la dégradation ciblée des protéines (TPD), la découverte de médicaments assistée par l'IA (AIDD), la conception de médicaments assistée par ordinateur (CADD), le criblage virtuel de médicaments, l'apprentissage multitâche, la prédiction des propriétés moléculaires, la recherche sur les réseaux neuronaux graphiques et les tests de performance en apprentissage automatique.
Utilisation en ligne :https://go.hyper.ai/7gDJu
4. Ensemble de données EAVSD sur les storyboards vidéo publicitaires pour le commerce électronique
EAVSD est un jeu de données de storyboards vidéo publicitaires pour le e-commerce, publié par une équipe de l'Université de Pékin en 2026. Il vise à faciliter la génération d'images multiples thématiques et la planification narrative. Ce jeu de données est largement utilisé dans ces domaines, notamment pour la génération de storyboards vidéo publicitaires pour le e-commerce et la recherche sur la cohérence visuelle à long terme contrôlable.
Utilisation en ligne :https://go.hyper.ai/hyzLx
5. Ensemble de données de détection de fissures d'infrastructure DeepCrack
DeepCrack est un jeu de données de référence pour la détection des fissures dans les infrastructures, fourni par le Laboratoire de vision par ordinateur et de télédétection de l'Université de Wuhan. Il vise à fournir des données d'apprentissage supervisé standardisées et de haute précision pour la recherche sur les algorithmes de détection de fissures. Il peut être utilisé directement pour l'entraînement et l'évaluation de modèles d'apprentissage profond tels que U-Net, DeepLab et SegNet, et est largement utilisé dans des domaines de recherche comme la surveillance de l'intégrité structurelle, l'inspection des routes et l'identification des défauts de construction.
Utilisation en ligne :https://go.hyper.ai/88zlH

6. Base de données mondiale sur la pollution atmosphérique et l'indice de qualité de l'air (IQA)
Le jeu de données mondial sur la pollution atmosphérique et l'IQA est un ensemble de données sur la qualité de l'air destiné à la recherche et à l'analyse. Il contient des données d'observation mensuelles au niveau des villes, couvrant la période 2014-2025, soit un total de 331 920 enregistrements et 24 pays répartis sur 5 continents : Chine, États-Unis, Royaume-Uni, France, Allemagne, Japon et Corée du Sud. Il comprend 24 indicateurs, notamment les concentrations de polluants atmosphériques, l'indice de qualité de l'air, les variables météorologiques et des indicateurs socio-environnementaux.
Utilisation en ligne :https://go.hyper.ai/QL8VK
Tutoriels publics sélectionnés
1. MiniCPM5-1B : LLM 1B haute efficacité pour applications en bordure
MiniCPM5-1B est le premier modèle de la série MiniCPM5 développé par l'équipe OpenBMB. Conçu pour le déploiement en périphérie et les environnements aux ressources limitées, il repose sur une architecture Transformer à haute densité de paramètres (1 milliard) et offre des performances de pointe parmi les modèles open source de taille similaire. Il excelle particulièrement dans les appels d'outils multi-agents, la génération de code et les tâches d'inférence complexes.
Exécutez en ligne :https://go.hyper.ai/OBlhv
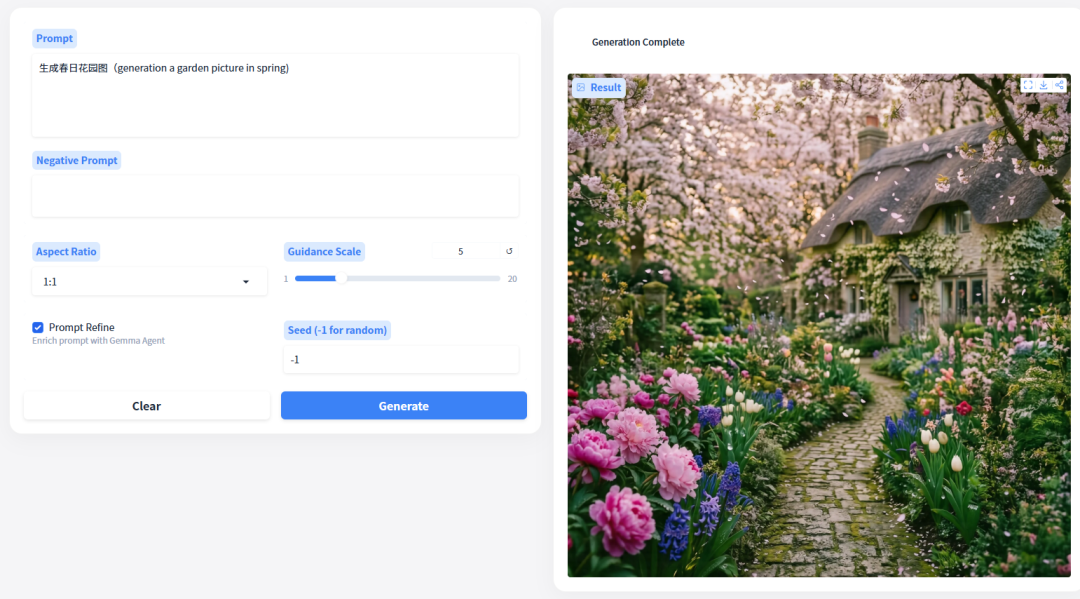
2. Système de génération d'images HiDream-O1
HiDream-O1-Image est un modèle de base natif de génération d'images unifiée, lancé par l'équipe HiDream.ai en 2026. Ce modèle repose sur une architecture Transformer unifiée (UiT) au niveau du pixel. Contrairement aux modèles traditionnels, il ne dépend ni de VAE externes ni d'encodeurs de texte séparés, mais encode nativement les pixels et le texte dans un espace de jetons unique et partagé.
Exécutez en ligne :https://go.hyper.ai/XkyGK
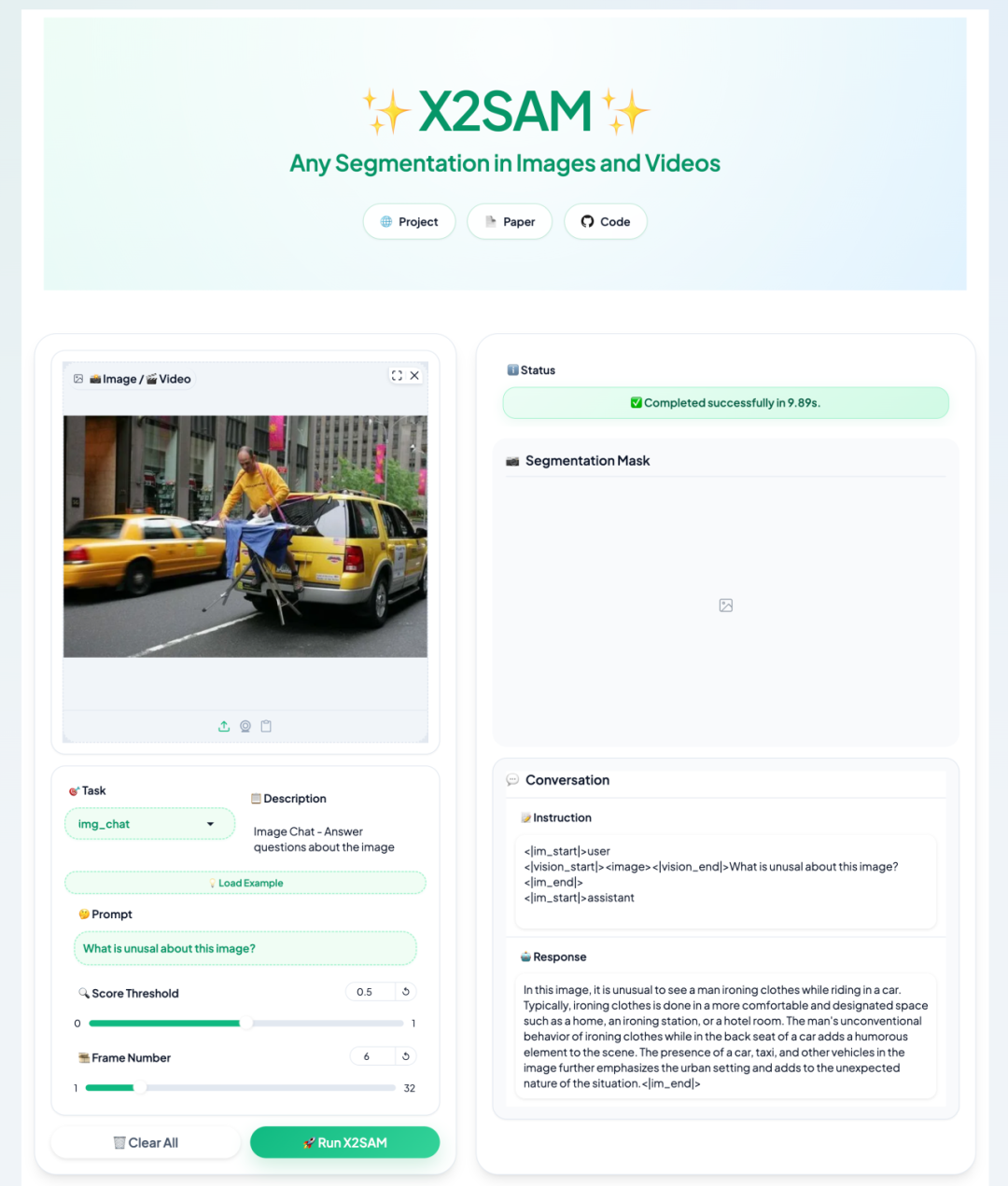
3. X2SAM : Un modèle unifié pour la segmentation d’images et de vidéos arbitraires
X2SAM, développé en avril 2026 par l'Université Sun Yat-sen, le laboratoire Pengcheng et l'équipe Meituan, est un modèle multimodal de grande taille destiné à la segmentation unifiée d'images et de vidéos. Sa principale caractéristique est d'intégrer les instructions textuelles, les instructions visuelles et la segmentation d'images/vidéos au sein d'un processus interactif unique.
Exécutez en ligne :https://go.hyper.ai/OAndb
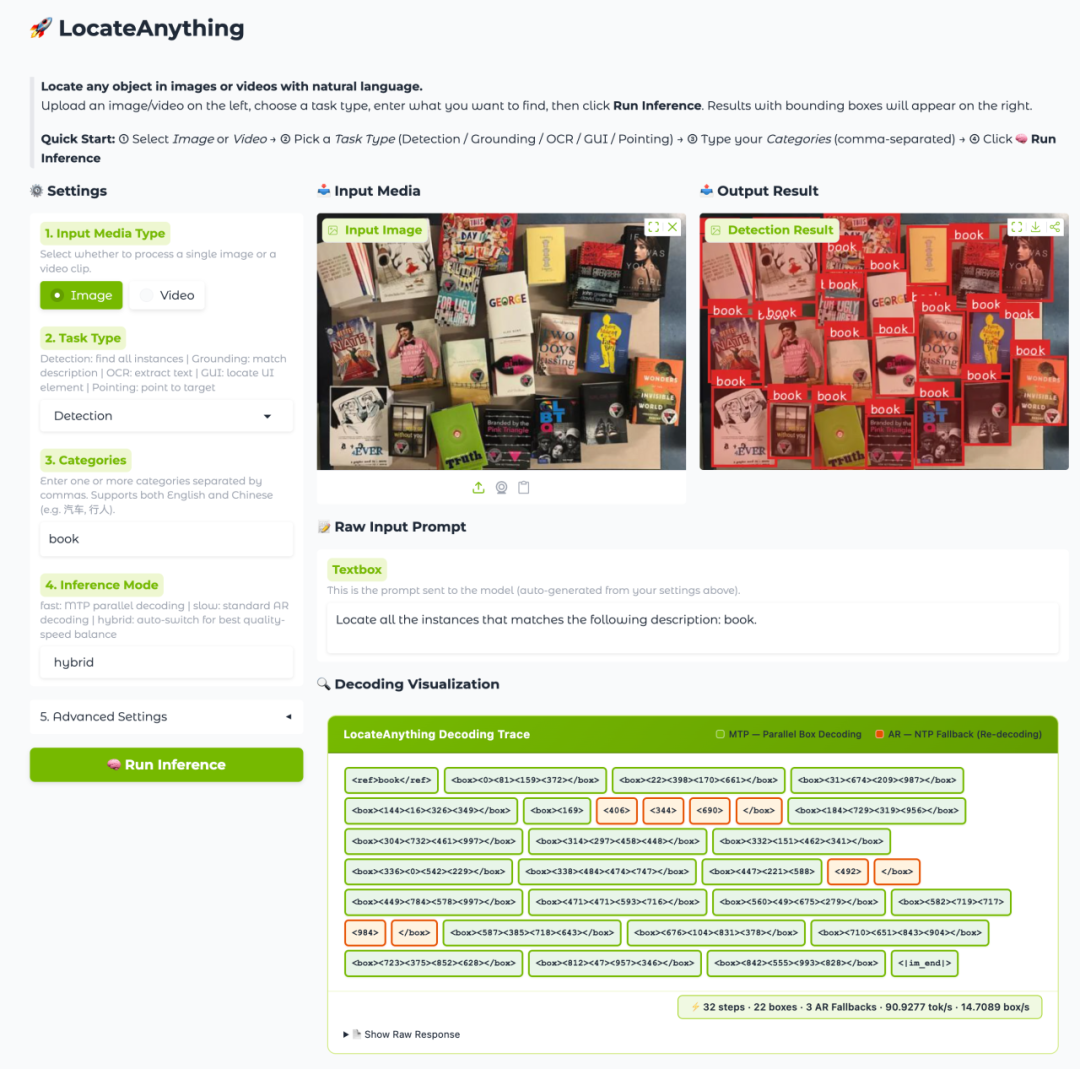
4. LocateAnything-3B : un modèle de localisation visuelle du langage rapide et de haute qualité
Développé par NVIDIA en 2026, LocateAnything-3B est un modèle de localisation visuelle à 3B paramètres de la série Eagle VLM. Il est conçu pour des tâches telles que la détection d'objets ouverts, la localisation d'expressions verbales, la reconnaissance optique de caractères (OCR), la localisation d'éléments d'interface graphique et le pointage dans les images et les vidéos. Sa principale caractéristique est le décodage parallèle des boîtes englobantes : au lieu de générer les coordonnées par autorégression jeton par jeton, il prédit les coordonnées complètes des boîtes englobantes sous forme de blocs structurés en parallèle, améliorant ainsi le débit de localisation tout en préservant la cohérence géométrique.
Exécutez en ligne :https://go.hyper.ai/DxUFC
5. Granite 4.1 8B : Prend en charge les dialogues, l'encodage, RAG et les appels d'outils.
Les modèles de langage Granite 4.1 constituent une nouvelle génération de modèles fondamentaux open source lancés par IBM en 2026. Ils intègrent des architectures de décodeurs denses à trois échelles : 3B, 8B et 30B. Granite 4.1 8B, version haute performance de cette série, offre les performances supérieures requises pour les applications d'entreprise tout en conservant un nombre réduit de paramètres. Ce modèle prend en charge nativement le multilinguisme, un large éventail de tâches d'encodage, la génération d'améliorations de la recherche (RAG), l'utilisation d'outils et la sortie JSON structurée, assurant ainsi un support technique robuste pour les applications concrètes.
Exécutez en ligne :https://go.hyper.ai/Fpzl7
Interprétation des articles communautaires
1. L'Université nationale de Singapour propose un processus collaboratif IA-chimie computationnelle pour accélérer le repositionnement des médicaments pour la cicatrisation des plaies diabétiques, réduisant le cycle de R&D de plus de 701 TP3T !
Une équipe de recherche de l'Université nationale de Singapour a proposé un processus de recherche collaboratif en nanomédecine computationnelle, combinant intelligence artificielle et chimie computationnelle (IA-CC). Ce processus associe étroitement l'exploration de la littérature scientifique, guidée par de vastes modèles de langage (analyse qualitative), à la simulation moléculaire multi-étapes, dominée par la chimie computationnelle (vérification quantitative). Il en résulte un système de recherche en boucle fermée pour l'étude des nano-interactions médicament-protéine, permettant d'accélérer le repositionnement et le développement de médicaments pour la cicatrisation des plaies diabétiques.
Voir le rapport complet :https://go.hyper.ai/OXs3N
Articles populaires de l'encyclopédie
1. Modèle d'action mondial (WAM)
2. Modèle d'action du langage visuel (VLA)
3. L'humain au cœur du processus
4. Apprendre en déployant
5. Fusion de rangs réciproques
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournit des nœuds de téléchargement accéléré nationaux pour plus de 2100 jeux de données publics
* Comprend plus de 700 tutoriels en ligne classiques et populaires
* Analyse de plus de 300 études de cas sur l'IA au service de la science
* Permet de rechercher plus de 700 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








