Command Palette
Search for a command to run...
Obtenez Une « Liberté De Voix off » Avec Seulement 3 Secondes d'audio : Le Modèle De Parole open-source Mistral Voxtral-4B-TTS-2603 ; Établissez Une Nouvelle Référence En Matière De Qualité Des Données : Le Pré-entraînement Sutra 10B.

Actuellement, les modèles vocaux légers peinent souvent à concilier naturel et efficacité de déploiement lorsqu'il s'agit de gérer des contextes multilingues complexes et des doublages longs. En pratique, les agents vocaux et la diffusion de contenu exigent non seulement une compréhension linguistique extrêmement poussée, mais aussi une faible latence en environnement local et une capacité à basculer facilement entre plusieurs langues. Ces exigences mettent à l'épreuve la capacité des modèles open source existants en termes de paramétrage et de fonctionnalités.
Dans ce contexte,Mistral a officiellement lancé le modèle Voxtral-4B-TTS-2603. Voxtral TTS est un modèle de synthèse vocale multilingue sans exemple, basé sur une architecture hybride. Il encode la parole en jetons sémantiques et acoustiques grâce au codec Voxtral. La partie sémantique est alignée sur le texte par distillation ASR. Lors de la génération, un modèle autorégressif, utilisant uniquement le décodeur, génère progressivement des jetons sémantiques pour garantir une cohérence à long terme. Simultanément, un modèle de correspondance de flux est introduit pour générer efficacement des jetons acoustiques dans un espace continu, optimisant ainsi la qualité de la génération et l'efficacité de calcul. Cette architecture hybride « autorégression sémantique + correspondance de flux acoustique » combine efficacement les avantages des modélisations discrète et continue, permettant au modèle de réaliser une synthèse vocale de haute qualité avec seulement 3 secondes de parole de référence et d'offrir une bonne capacité de généralisation dans des contextes multilingues.
Le site web d'HyperAI propose désormais « Voxtral 4B TTS 2603 Multilingual Speech Generation », alors essayez-le !
Utilisation en ligne :https://go.hyper.ai/AoY2t
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 30 mars au 5 avril :
* Ensembles de données publiques de haute qualité : 8
* Une sélection de tutoriels de haute qualité : 10
* Interprétation d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en avril : 6
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Base de données sur la recherche d'emploi des étudiants universitaires
Cet ensemble de données synthétiques porte sur le processus de recherche d'emploi de jeunes diplômés et comprend 100 000 enregistrements. Il détaille les informations démographiques des étudiants (spécialisation, classement de l'université et région), leurs résultats scolaires (moyenne générale et stages) et leur parcours de recherche d'emploi (dépôt de candidature, premier entretien, deuxième entretien et offre d'emploi). Pour les étudiants ayant obtenu une offre, des variables cibles telles que le salaire, la taille de l'entreprise et la pertinence du poste sont également incluses.
Utilisation directe :https://go.hyper.ai/Rj94B
2. Ensemble de données Groundsource sur les événements d'inondation mondiaux
Cet ensemble de données, constitué automatiquement à partir de données d'actualités mondiales, recense les inondations historiques à haute résolution et contient 2,6 millions d'enregistrements couvrant plus de 150 pays. Lors du traitement des données, l'équipe de recherche a utilisé des modèles de langage Gemini (LLM) pour extraire systématiquement des informations structurées, telles que la date et le lieu des inondations, à partir de textes d'actualité non structurés, permettant ainsi la construction automatisée d'événements catastrophiques historiques à grande échelle.
Utilisation directe :https://go.hyper.ai/Aj8bq
3. Ensemble de données d'enseignement et d'entraînement préalables du Sutra 10B
Ce jeu de données est un ensemble de données pédagogiques de haute qualité destiné au pré-entraînement de grands modèles de langage. Généré par le framework Sutra, il crée du contenu pédagogique structuré et optimise le pré-entraînement des modèles de langage. Il s'agit du plus grand jeu de données de la série Sutra, conçu pour démontrer comment des ensembles de données denses et bien organisés peuvent offrir des performances de pré-entraînement optimales pour les petits modèles de langage.
Utilisation directe :https://go.hyper.ai/okKgZ
4. zh-meme-sft-8k Ensemble de données sur la culture des mèmes Internet chinois
Ce jeu de données sert à affiner les instructions relatives à la culture des mèmes internet chinois. Il est principalement utilisé pour entraîner des modèles de dialogue à comprendre et à utiliser les mèmes internet populaires. Ce jeu de données est constitué d'interactions par commentaires sur des plateformes de médias sociaux telles que Douyin, Xiaohongshu et Bilibili, et a fait l'objet de plusieurs cycles de nettoyage et d'amélioration. Il se caractérise par des structures de dialogue issues de sources authentiques, une conservation de haute qualité des mèmes populaires malgré de multiples nettoyages, et une standardisation au format ChatML.
Utilisation directe :https://go.hyper.ai/O0asZ
5. Ensemble de données d'instructions pour les tâches créatives des professionnels créatifs
Ce jeu de données est un ensemble de tâches synthétiques à grande échelle et haute fidélité, conçu pour l'entraînement, l'évaluation et l'optimisation d'agents d'IA multimodaux. Il contient 1 070 917 opérations de commande d'agent, couvrant 36 environnements logiciels créatifs, techniques et d'ingénierie. Ce jeu de données vise à explorer les interactions logicielles complexes et le raisonnement à plusieurs étapes.
Utilisation directe :https://go.hyper.ai/Da6qF
6. Nemotron Personas France (ensemble de données de personnes synthétiques françaises)
Ce jeu de données, publié en 2026 par NVIDIA en collaboration avec Pleias, est un ensemble de données de personnages synthétiques français. Il contient des données de personnages synthétiques générées à partir de données démographiques, géographiques et de traits de personnalité réels de la France. L'objectif est de fournir des données de personnages synthétiques diversifiées afin de faciliter le développement de modèles en reflétant la répartition géographique et démographique de la France.
Utilisation directe :https://go.hyper.ai/8CmKo
7. Ensemble de données sur la santé mentale des étudiants (Santé mentale et épuisement professionnel des étudiants)
Cet ensemble de données synthétiques à grande échelle est conçu pour analyser et prédire le niveau d'épuisement professionnel des étudiants à partir de facteurs académiques, psychologiques et liés au mode de vie. Il contient 150 000 dossiers d'étudiants et combine des variables numériques et catégorielles, ce qui le rend adapté aux tâches d'apprentissage automatique, de classification et d'analyse de données.
Utilisation directe :https://go.hyper.ai/YL24S
8. Pandémies et épidémies historiques : Ensemble de données épidémiologiques historiques mondiales
Cet ensemble de données constitue un registre exhaustif des principales pandémies mondiales à travers l'histoire, conçu pour fournir une ressource directement exploitable pour l'analyse. Il recense 50 pandémies majeures, de la peste antonine de 165 après J.-C. à la COVID-19 et à la variole du singe en 2023, couvrant toutes les époques, toutes les régions et tous les types d'agents pathogènes.
Utilisation directe :https://go.hyper.ai/AbhHY
Tutoriels publics sélectionnés
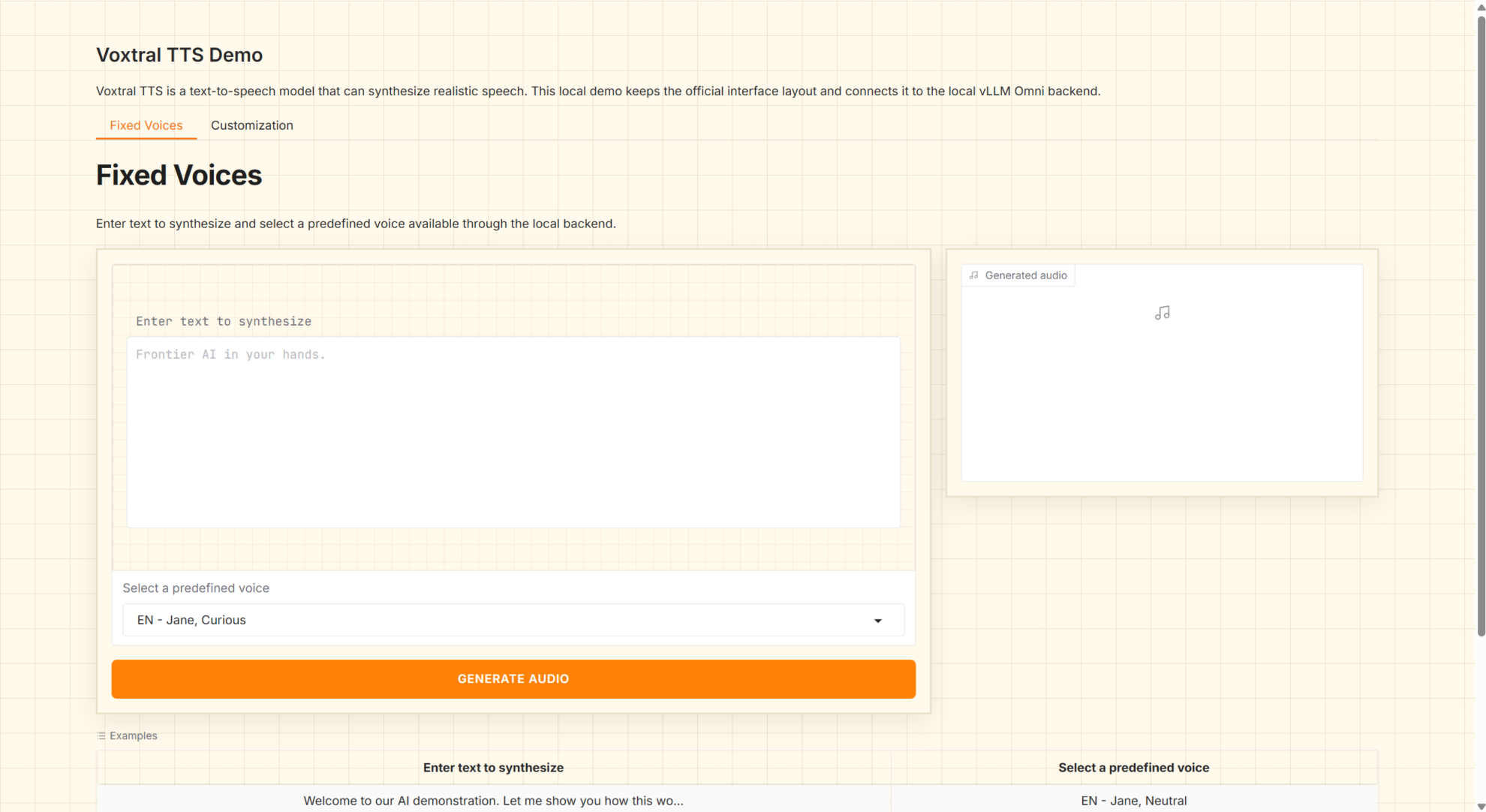
1. Voxtral 4B TTS 2603 Génération de parole multilingue
Voxtral-4B-TTS-2603 est un modèle de synthèse vocale (TTS) de niveau 4B, développé par Mistral AI et publié en mars 2026. Il offre des pondérations ouvertes et des capacités de génération vocale multilingues, permettant la synthèse directe de texte en langage naturel en audio. Ce modèle est conçu pour des applications telles que les agents vocaux, la diffusion vocale, le doublage de contenu et les services TTS localisés. Il est compatible avec un déploiement local et peut être utilisé via des interfaces de service standardisées.
Exécutez en ligne :https://go.hyper.ai/AoY2t
2. LingBot-World : un modèle de monde open source
LingBot-World est un simulateur de monde open source basé sur la génération vidéo. Modèle de monde de pointe, il offre un environnement haute fidélité, une mémoire à long terme et une interactivité en temps réel. LingBot-World utilise une architecture de génération vidéo avancée, capable de produire des vidéos de haute qualité avec une cohérence spatio-temporelle à partir d'images, d'invites textuelles et de signaux de position de la caméra.
Exécutez en ligne :https://go.hyper.ai/fzF6R
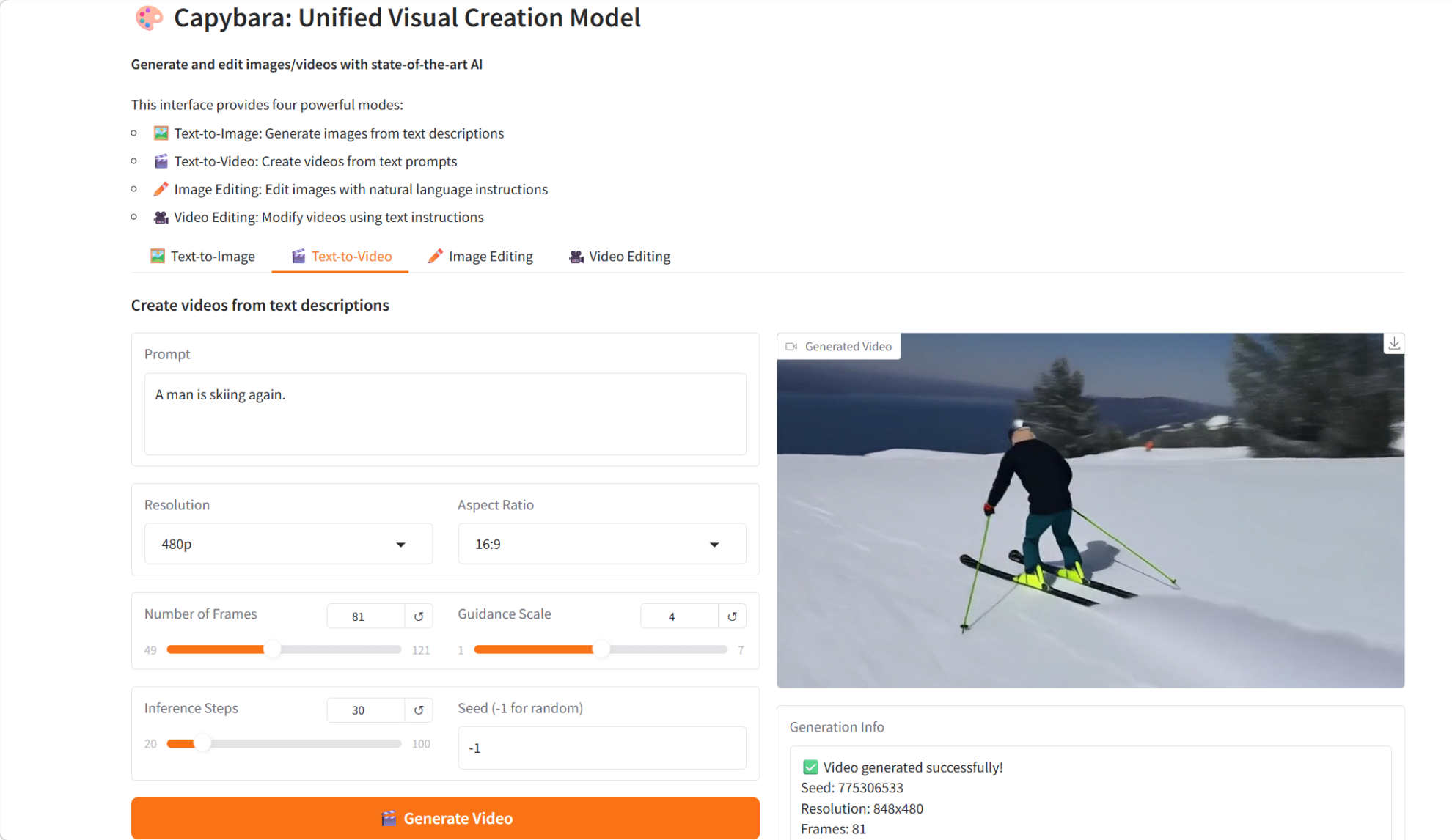
3. Capybara : un modèle de création visuelle unifié
Capybara, développé par l'équipe xgen-universe et sorti en février 2026, est un modèle de création visuelle unifié conçu pour gérer diverses tâches de création visuelle, notamment la génération d'images et de vidéos à partir de texte, ainsi que l'édition d'images et de vidéos guidée par des instructions. Reposant sur un modèle de diffusion avancé et une architecture Transformer, Capybara vise à fournir un cadre unifié et efficace pour la génération et l'édition visuelles.
Exécutez en ligne :https://go.hyper.ai/yX0Pc
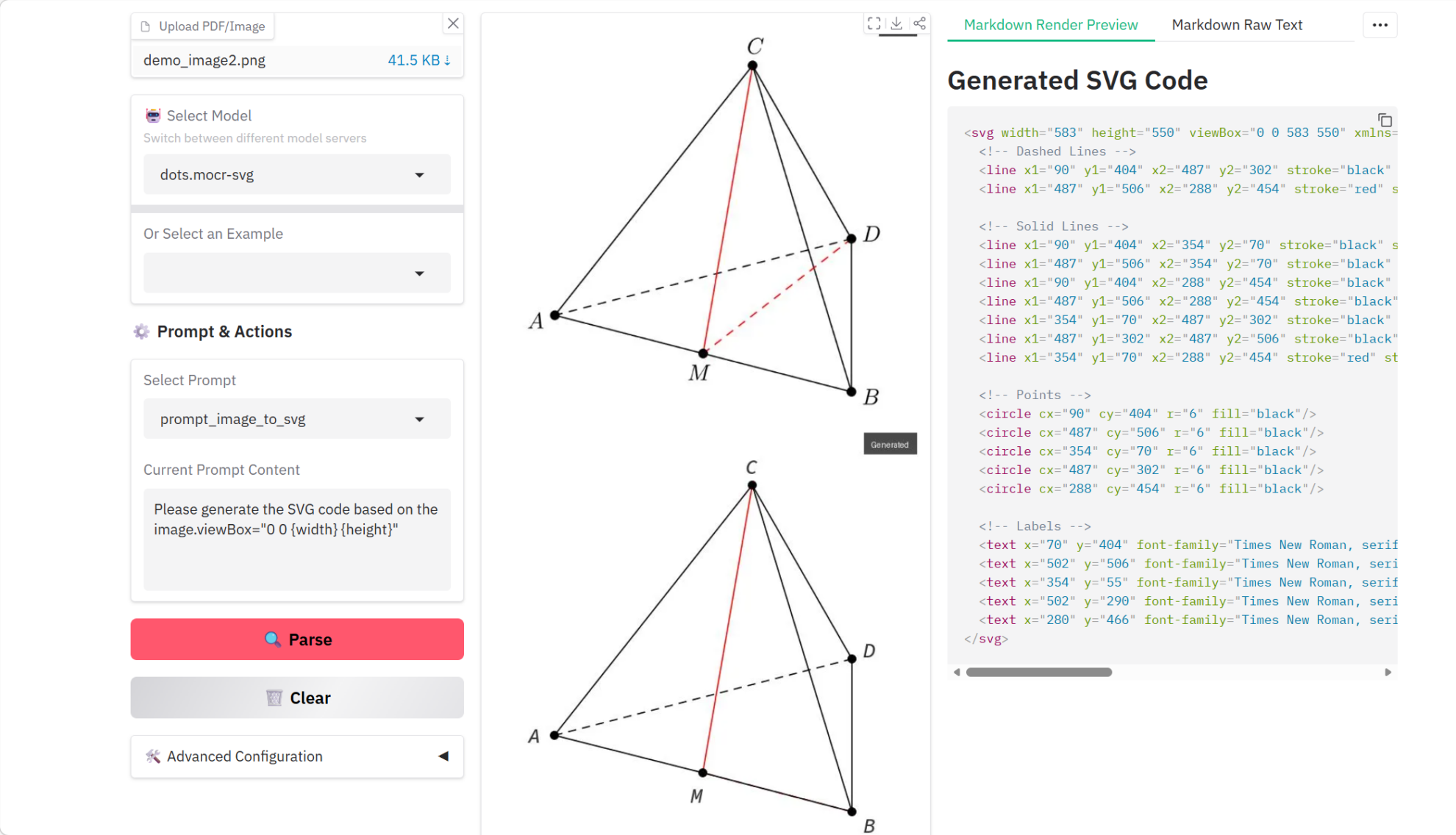
4. dots.mocr Tutoriel sur l'analyse de documents multimodaux
dots.mocr est un modèle d'analyse syntaxique de documents OCR multimodal, développé conjointement par l'Université des sciences et technologies de Huazhong et le laboratoire Xiaohongshu HI-Lab en mars 2026. Parmi les modèles d'envergure similaire, il atteint des performances de pointe sur les tâches d'analyse syntaxique de documents multilingues standard. Outre l'analyse syntaxique de documents, dots.mocr excelle également dans la conversion directe de graphiques structurés (tels que des diagrammes, des interfaces utilisateur, des schémas scientifiques, etc.) en code SVG.
Exécutez en ligne :https://go.hyper.ai/g2oB3
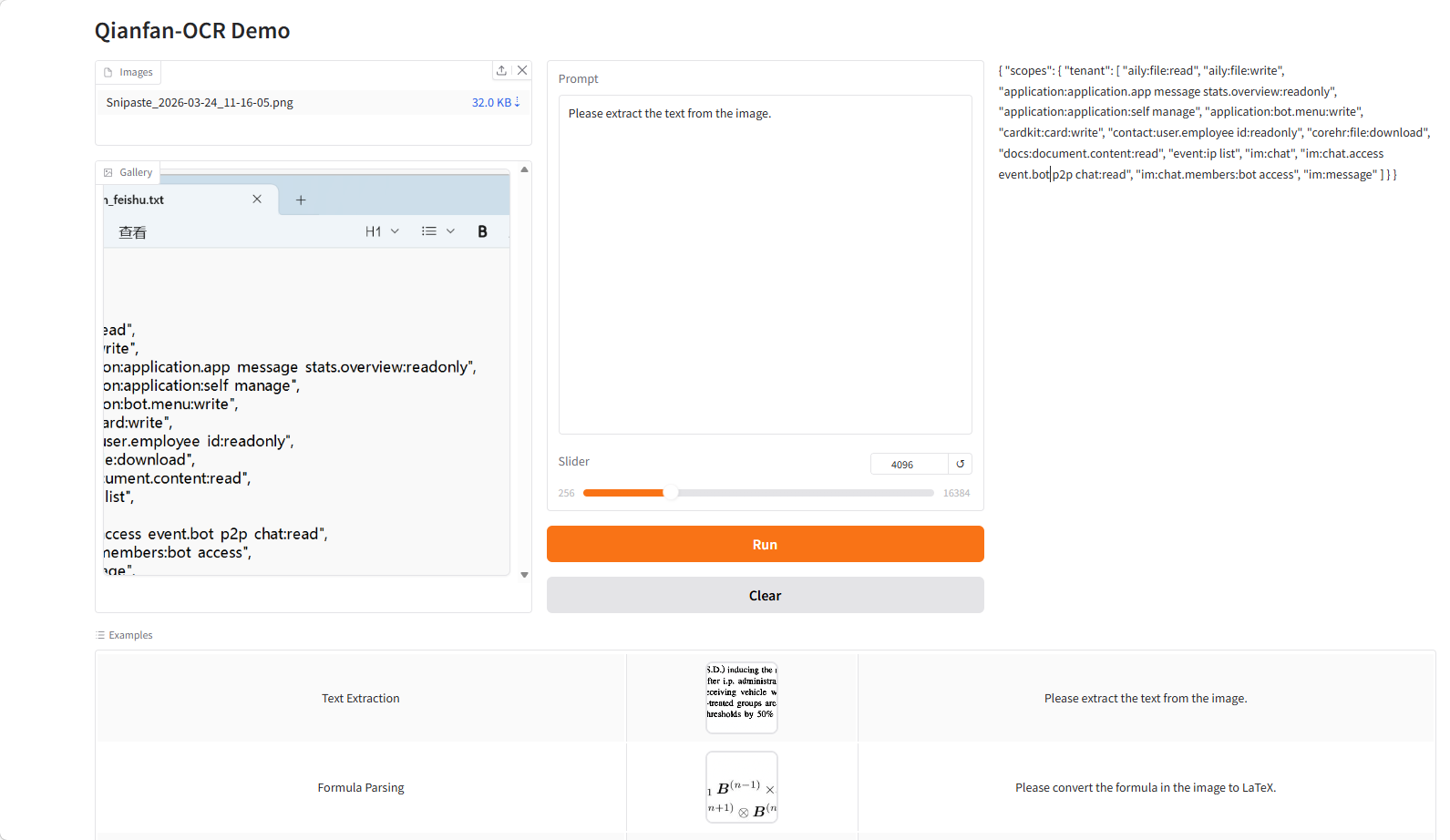
5. Qianfan-OCR : Modèle de document intelligent de bout en bout
Qianfan-OCR est un modèle d'intelligence documentaire de bout en bout, open source et développé par Baidu AI Cloud Qianfan depuis mars 2026. Basé sur une architecture de langage visuel à 4 milliards de paramètres, il intègre l'analyse syntaxique, l'analyse de la mise en page, la reconnaissance de texte et la compréhension sémantique. Son innovation majeure réside dans le mécanisme « Layout-as-Thought » : avant de générer des résultats, le modèle entre dans une « phase de réflexion », modélisant explicitement la structure du document (positions des éléments, types et ordre de lecture) avant de finaliser l'analyse syntaxique. Ceci permet un cadre unifié qui équilibre la prise en compte de la structure et la compréhension sémantique, améliorant ainsi la précision et la stabilité dans les documents complexes.
Exécutez en ligne :https://go.hyper.ai/WZIRF
6. Déploiement de sarvam-30b à l'aide de vLLM + Open WebUI
Sarvam-30B est un modèle de langage open source de grande taille, publié par Sarvam AI en mars 2026. Troisième version de la série de modèles open source de Sarvam, il adopte une architecture de type Mixture-of-Experts (MoE), avec un total de 30 milliards de paramètres et environ 2,4 milliards de paramètres activés par jeton. Il a été optimisé de manière systématique pour le dialogue multilingue, l'inférence, l'encodage et les scénarios de déploiement pratiques.
Exécutez en ligne :https://go.hyper.ai/UUJWe
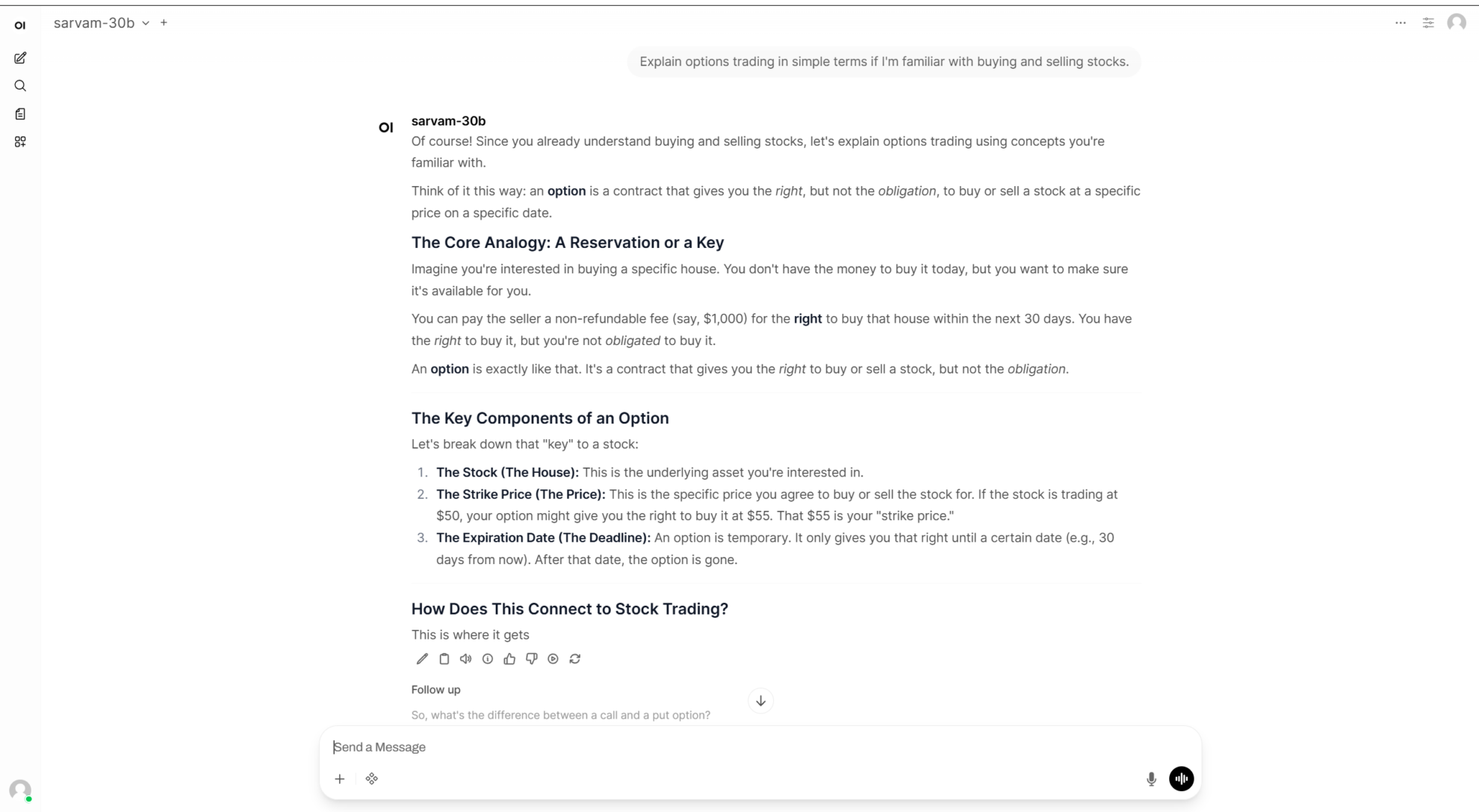
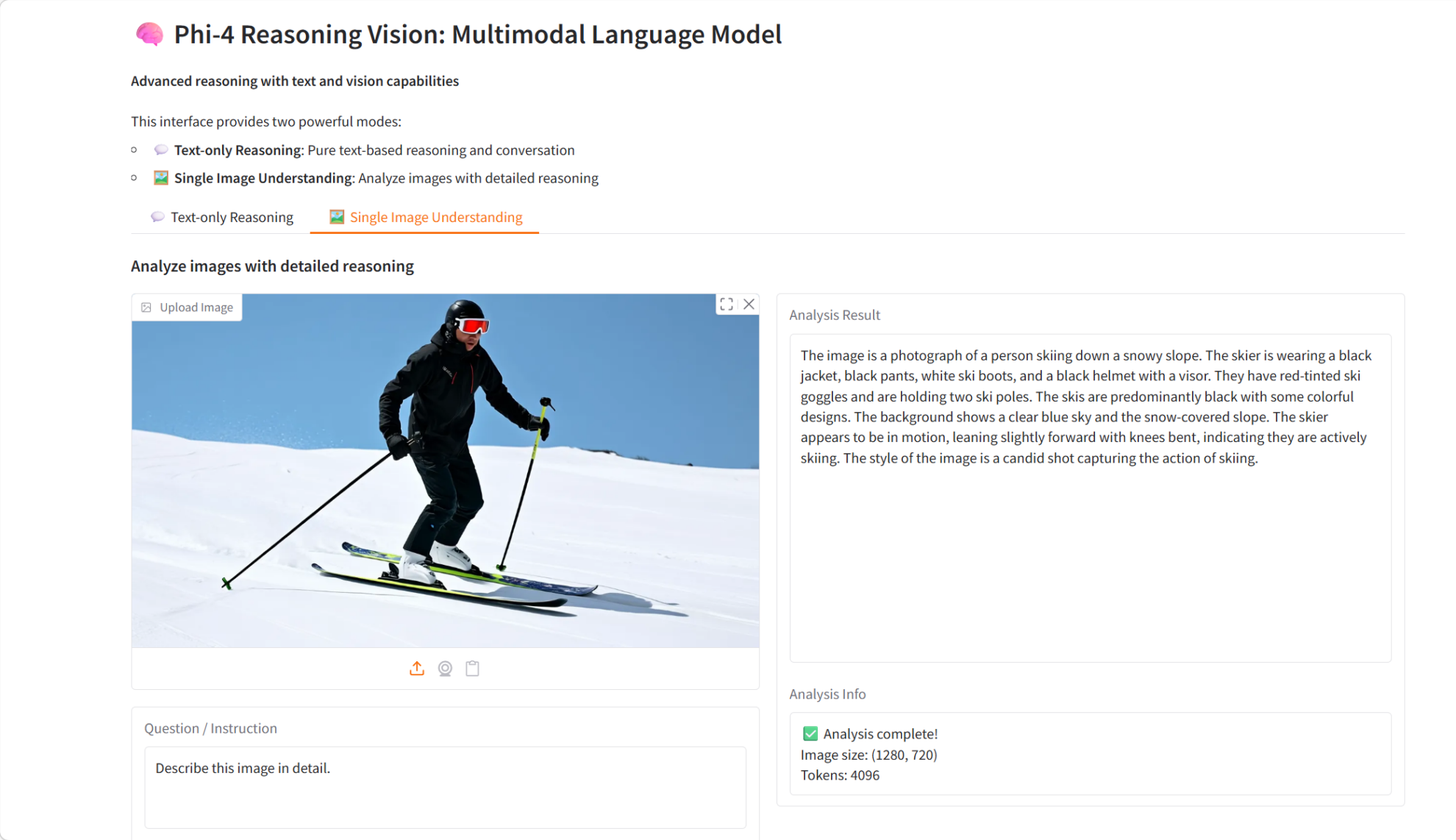
7. Démonstration du modèle visuel de raisonnement multimodal Phi-4-reasoning-vision-15B
Phi-4-reasoning-vision-15B est un modèle de langage visuel de raisonnement multimodal de 15 milliards de paramètres publié par Microsoft en mars 2026. Basé sur l'architecture Phi-4, ce modèle combine de puissantes capacités de raisonnement textuel et de compréhension visuelle, lui permettant de gérer des tâches complexes de raisonnement texte-image.
Exécutez en ligne :https://go.hyper.ai/JQlDE
8. Slime : un framework de post-entraînement SGLang-Native conçu pour la mise à l’échelle par renforcement
Slime est un framework de post-entraînement LLM développé par le Laboratoire d'ingénierie des connaissances (THUDM) de l'Université Tsinghua, conçu spécifiquement pour étendre l'apprentissage par renforcement. Ce framework combine de manière optimale entraînement haute performance et génération de données flexible grâce à l'association de Megatron et SGLang.
Exécutez en ligne :https://go.hyper.ai/Xrxev
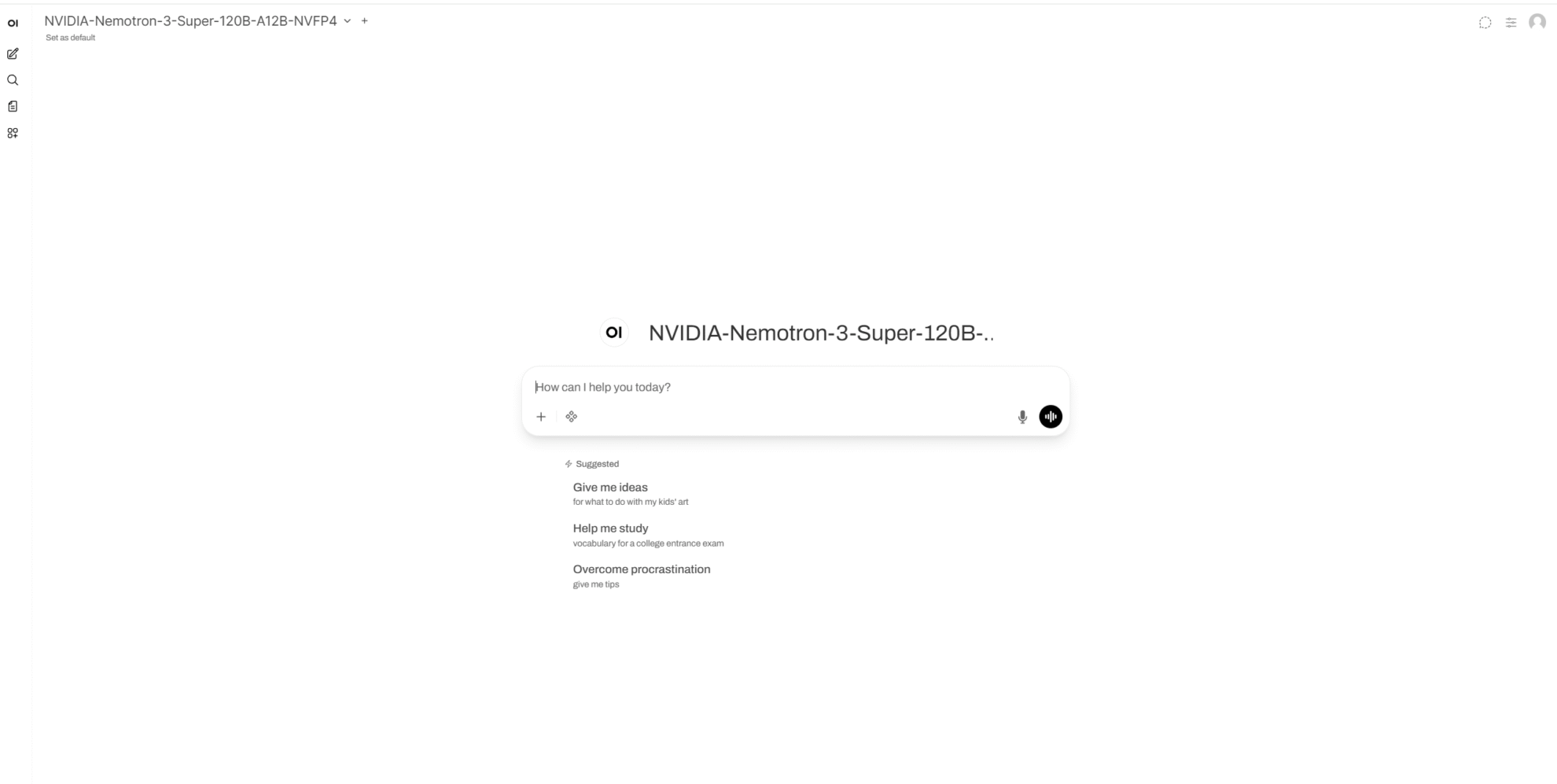
9. Déploiement en un clic de NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
Le modèle NVIDIA Nemotron 3 Super NVFP4 a été lancé par NVIDIA Corporation en mars 2026. Ce modèle de langage de grande taille possède 120 paramètres au total et 12 paramètres d'activation. Il utilise une architecture hybride LatentMoE et prend en charge des contextes allant jusqu'à 1 million de jetons. Il est conçu pour les scénarios impliquant le raisonnement sur des contextes longs, les flux de travail d'agents, les appels d'outils, les RAG (Rational Aggregation Groups) et la réponse aux questions à haut débit. En termes d'interaction, le modèle permet d'activer ou de désactiver un mode de raisonnement et de basculer entre le mode de réponse aux questions standard et le mode de raisonnement amélioré grâce à des paramètres de modèles de conversation standardisés.
Exécutez en ligne :https://go.hyper.ai/WJmbe
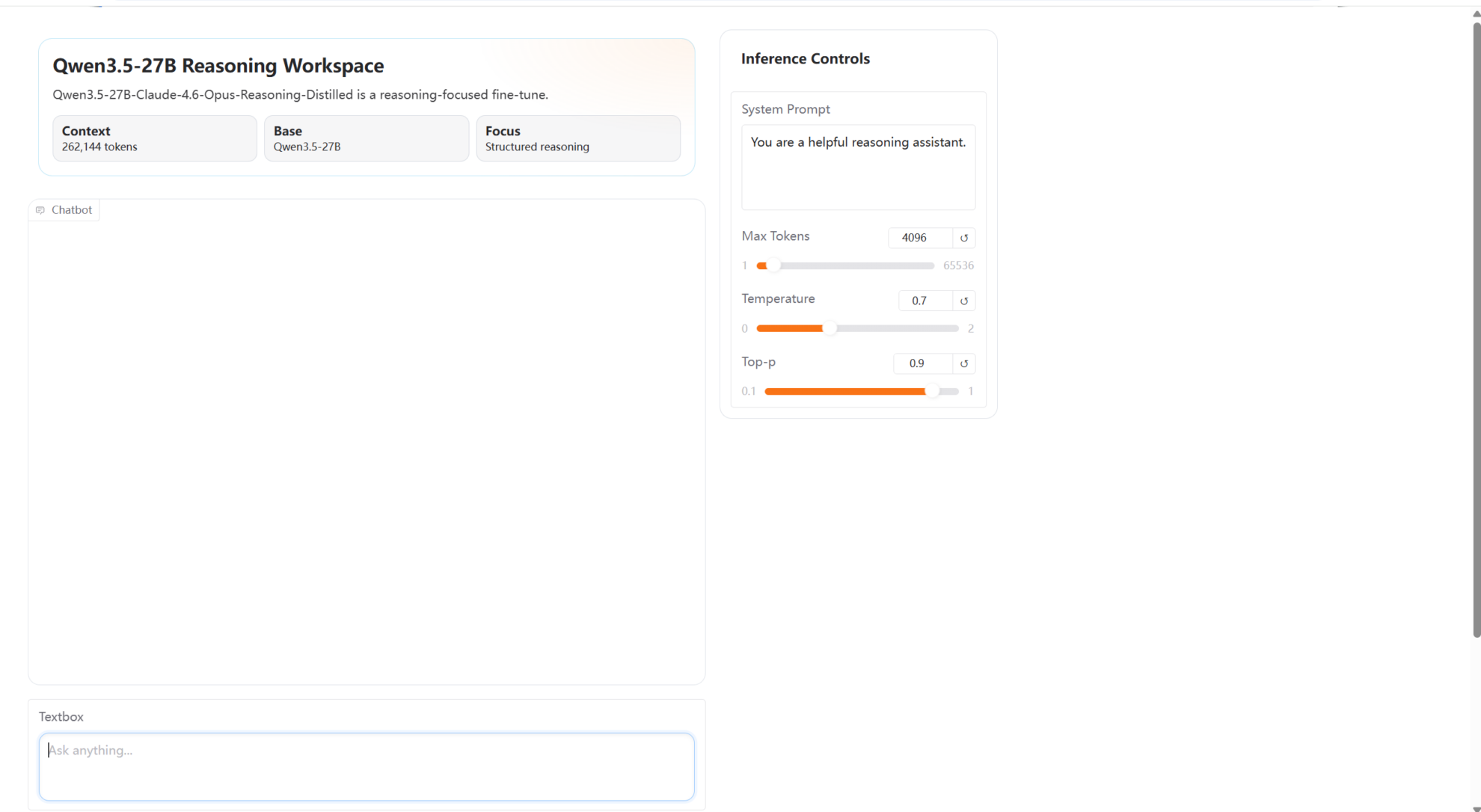
10. Déploiement en un clic de Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled est un modèle de dialogue haute performance développé par Jackrong en mars 2026. Basé sur la plateforme Qwen3.5-27B, il intègre les capacités de raisonnement Claude-4.6 et Opus pour l'extraction des connaissances. Ce modèle améliore considérablement les capacités de raisonnement complexe et l'expérience de dialogue interactif, tout en préservant la compréhension du langage d'origine.
Exécutez en ligne :https://go.hyper.ai/SNlOk
Interprétation des articles communautaires
1. Sur la base de données spectrales simulées de 2 000 matériaux semi-conducteurs, une équipe du MIT a proposé DefectNet, qui peut analyser six défauts de substitution coexistants.
Une équipe de recherche du MIT a proposé DefectNet, un modèle d'apprentissage automatique fondamental capable de prédire directement les types chimiques et les concentrations de défauts ponctuels de substitution à partir de spectres vibrationnels, même en présence de plusieurs éléments. Ce modèle présente une bonne capacité de généralisation sur des cristaux inconnus contenant 56 éléments et peut être affiné grâce à des données expérimentales.
Voir le rapport complet :https://go.hyper.ai/4qtAH
2. L'IA découvre 118 nouvelles exoplanètes ! Une équipe de l'Université de Warwick a proposé RAVEN, permettant une comparaison directe des scénarios planétaires avec chaque faux positif.
Une équipe de recherche de l'Université de Warwick a proposé RAVEN, un nouveau processus de sélection et de validation des candidats TESS. Ce processus utilise un jeu de données d'entraînement synthétiques, s'affranchissant ainsi de la seule dépendance aux données de dépassement de seuil (TCE) générées par la tâche elle-même. Cette amélioration élargit et enrichit considérablement l'espace des paramètres des scénarios planétaires et de faux positifs couverts par le modèle d'apprentissage automatique. Sur un jeu de test externe indépendant contenant 1 361 candidats TESS pré-classés, le processus a atteint une précision globale de 91%, démontrant son efficacité pour le classement automatique des candidats TESS.
Voir le rapport complet :https://go.hyper.ai/phEO5
3. Le MIT a proposé VibeGen, le premier modèle de génération de protéines dynamique de bout en bout, qui réalise une correspondance bidirectionnelle entre la séquence et la vibration.
Une équipe de recherche du MIT et de l'Université Carnegie Mellon a proposé VibeGen, un modèle d'agent intelligent générateur de protéines qui permet la conception de novo de protéines en combinant la génération de séquences et la prédiction de la dynamique vibrationnelle. Les résultats montrent que les protéines conçues par cet agent génératif peuvent non seulement se replier en structures stables et inédites, mais aussi reproduire les caractéristiques de distribution des amplitudes vibrationnelles cibles au niveau de la chaîne principale.
Voir le rapport complet :https://go.hyper.ai/jDaSW
Articles populaires de l'encyclopédie
1. Tri inverse combiné au RRF
2. Réseaux de neurones artificiels (RN)
3. Modèle de langage visuel (VLM)
4. Encodage de position rotationnelle (RoPE)
5. Mémoire à long terme bidirectionnelle (Bi-LSTM)
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








