Command Palette
Search for a command to run...
Tutoriel En Ligne | Analyse Contextuelle De 32 000 Mots Sur Des Dizaines De Pages De Documents Simultanément : Baidu Open Sources Unlimited OCR, Refactorisation De Scénarios Complexes Avec Des Documents Longs

Ces dernières années, la reconnaissance optique de caractères (OCR) a progressivement évolué, passant de la simple « reconnaissance de texte dans les images » à une tâche complète de compréhension des documents. Les entreprises et les développeurs ont désormais besoin non seulement d'extraire du texte, mais aussi de modèles capables de reconnaître des mises en page complexes, d'analyser des tableaux et des formules, de comprendre des mises en page à plusieurs colonnes et, au final, de produire des résultats structurés adaptés aux systèmes de gestion des ressources (RAG), aux bases de connaissances ou à la bureautique. Cependant, le traitement de documents volumineux tels que des rapports numérisés, des articles, des présentations PowerPoint, des contrats et des PDF multipages…Les flux de travail OCR traditionnels nécessitent souvent un raisonnement page par page suivi d'un post-traitement et d'un assemblage, ce qui est non seulement inefficace, mais aussi susceptible d'entraîner une fragmentation des informations contextuelles.
Les modèles OCR de bout en bout de nouvelle génération, comme DeepSeek OCR, améliorent considérablement la précision de la reconnaissance et les capacités d'analyse de mises en page complexes en intégrant un modèle de langage étendu comme décodeur et en exploitant pleinement les connaissances linguistiques a priori. Cependant, un nouveau défi se pose : à mesure que le contenu de sortie augmente, le cache clé-valeur du modèle s'agrandit, ce qui entraîne une consommation de mémoire de plus en plus élevée et un ralentissement de la vitesse de génération. Autrement dit,Plus le modèle est proche de la fin du document, plus le coût d'inférence est élevé.
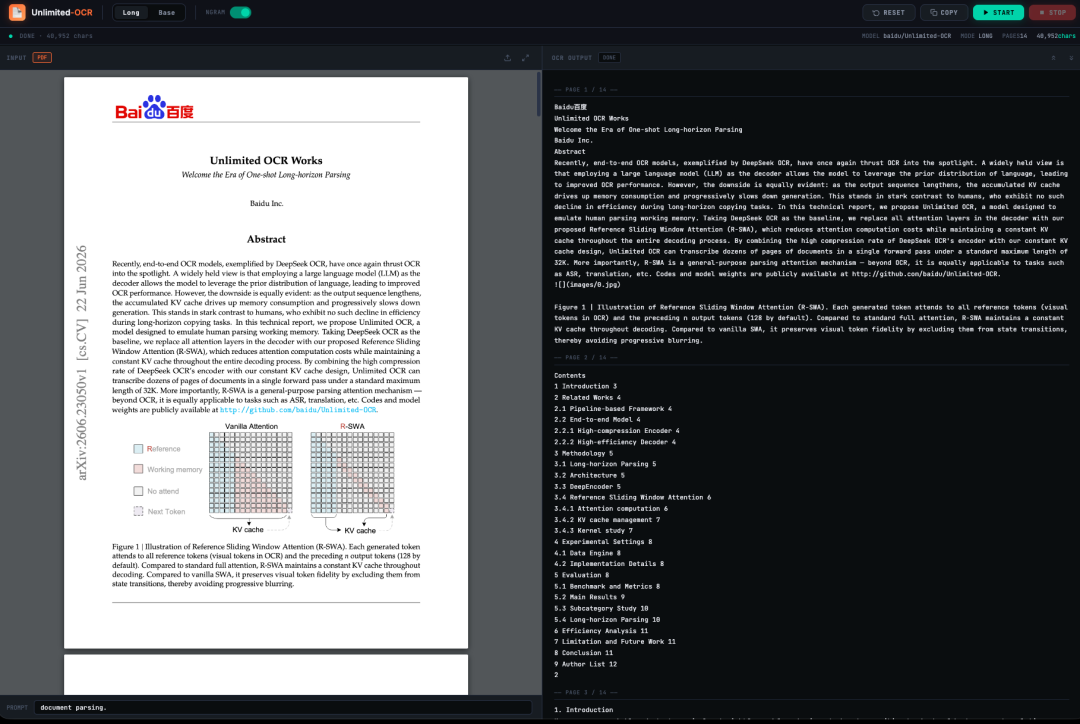
La solution Unlimited OCR de Baidu, récemment mise en open source, répond à ce problème majeur du secteur. Basé sur DeepSeek OCR, le modèle introduit un nouveau mécanisme d'attention par fenêtre glissante de référence (R-SWA), remplaçant le mécanisme d'attention traditionnel du décodeur. Ceci réduit le coût de calcul de l'attention tout en maintenant une taille de cache KV constante durant le processus de décodage. Combiné aux capacités élevées de compression d'informations de l'encodeur DeepSeek OCR,Unlimited OCR peut effectuer la reconnaissance optique de caractères et l'analyse de la mise en page de dizaines de pages de documents en une seule inférence directe, dans la longueur de contexte par défaut de 32 Ko.Cette approche offre une solution inédite et plus pertinente pour le traitement des documents longs. Plus important encore, R-SWA ne se limite pas à la reconnaissance optique de caractères (OCR), mais peut également être étendu à des tâches d'analyse syntaxique de longues séquences, telles que la reconnaissance vocale automatique (ASR) et la traduction automatique.
HyperAI (hyper.ai) a récemment lancé le tutoriel « Unlimited-OCR : Déploiement en un clic de l’OCR de documents longs et de l’analyse de la mise en page », abaissant ainsi le seuil de déploiement et facilitant la validation rapide des modèles. ⬇️
Exécutez en ligne :https://go.hyper.ai/YfaB5
Voir les articles connexes :https://go.hyper.ai/PZsJo
Plus de tutoriels en ligne :
Essai de démonstration
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels » ou cliquez sur « Voir plus de tutoriels », sélectionnez « Unlimited-OCR : Déploiement en un clic de l'OCR de documents longs et de l'analyse de la mise en page », puis cliquez sur « Exécuter ce tutoriel ».
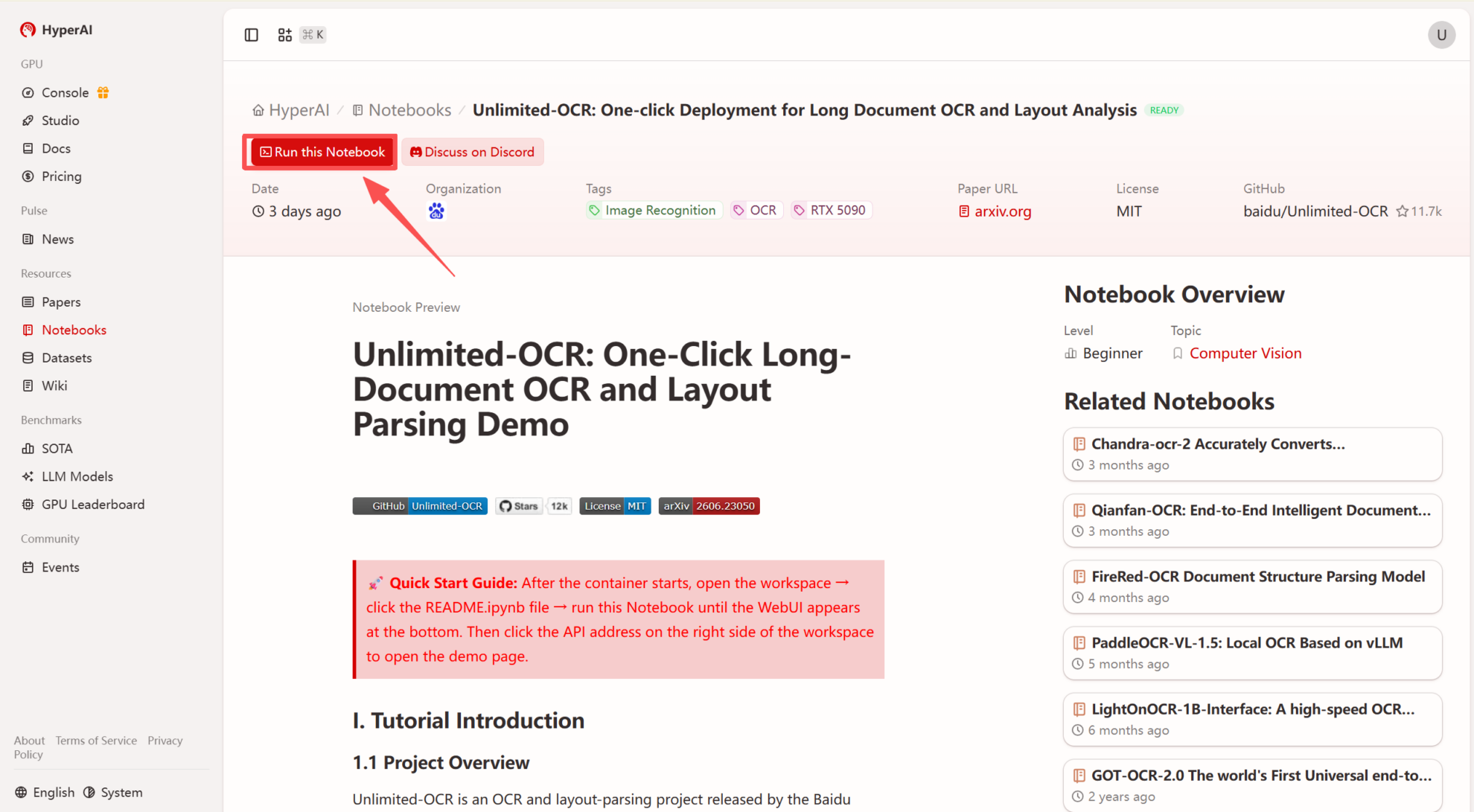
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
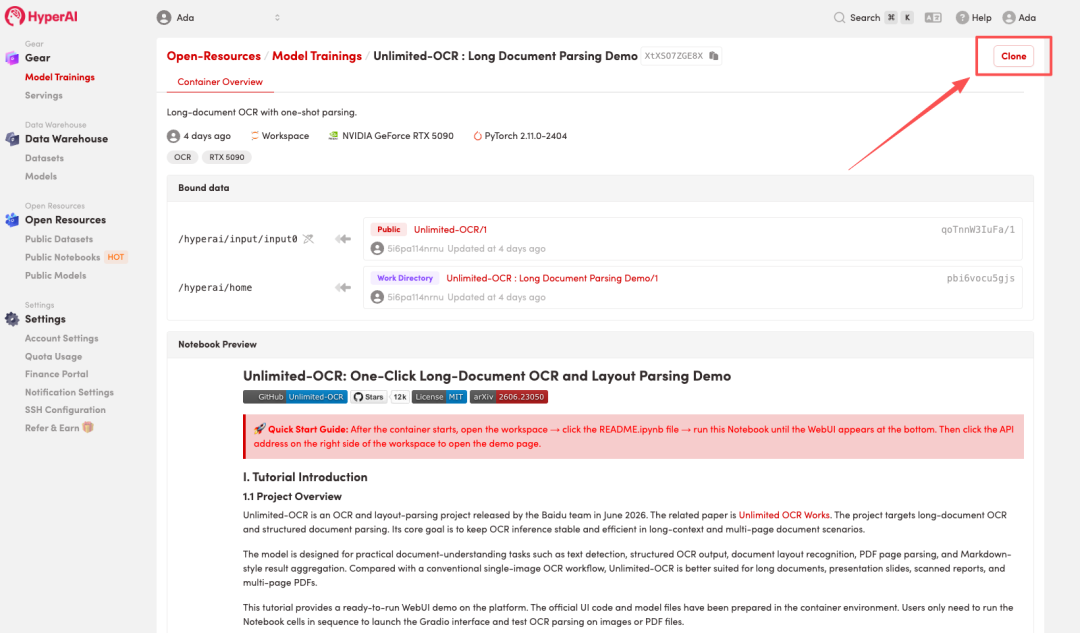
3. Sélectionnez les images « NVIDIA RTX 5090 » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
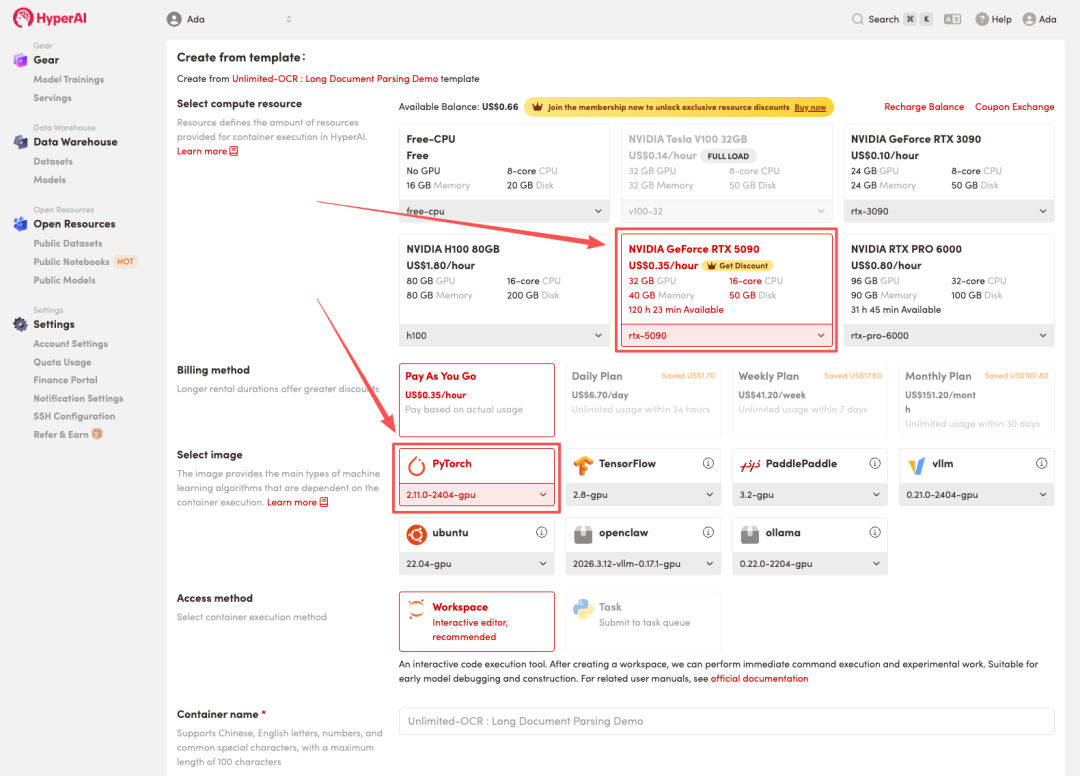
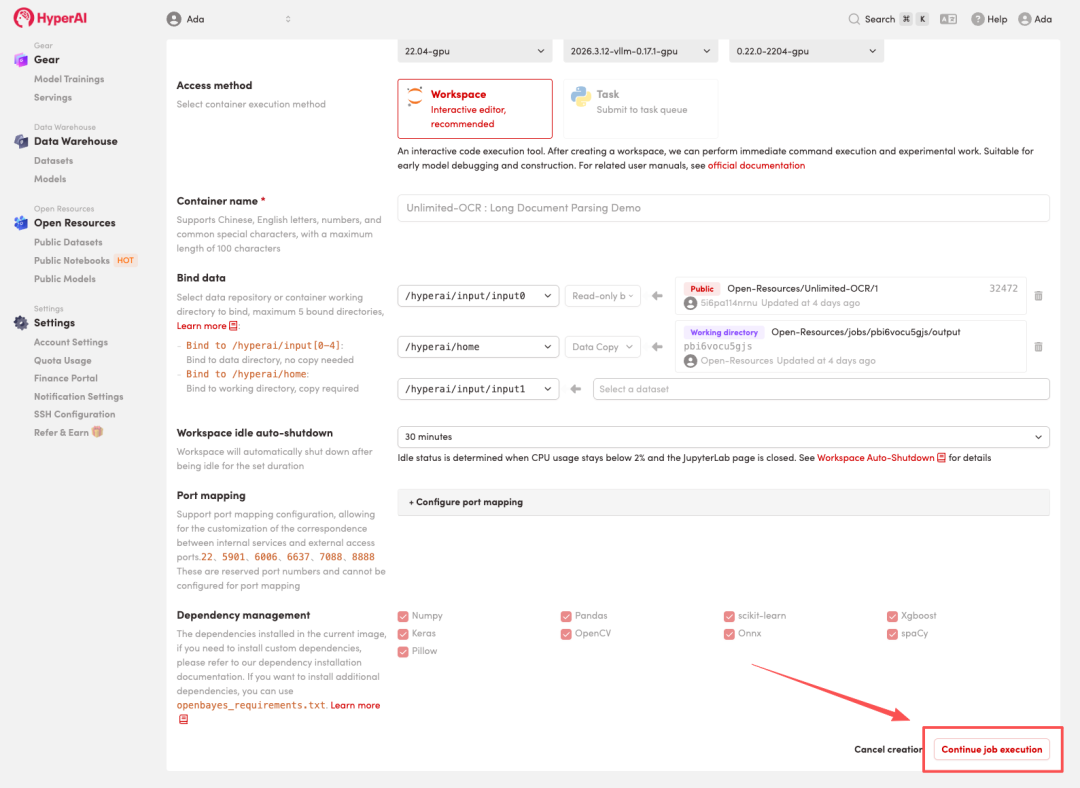
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
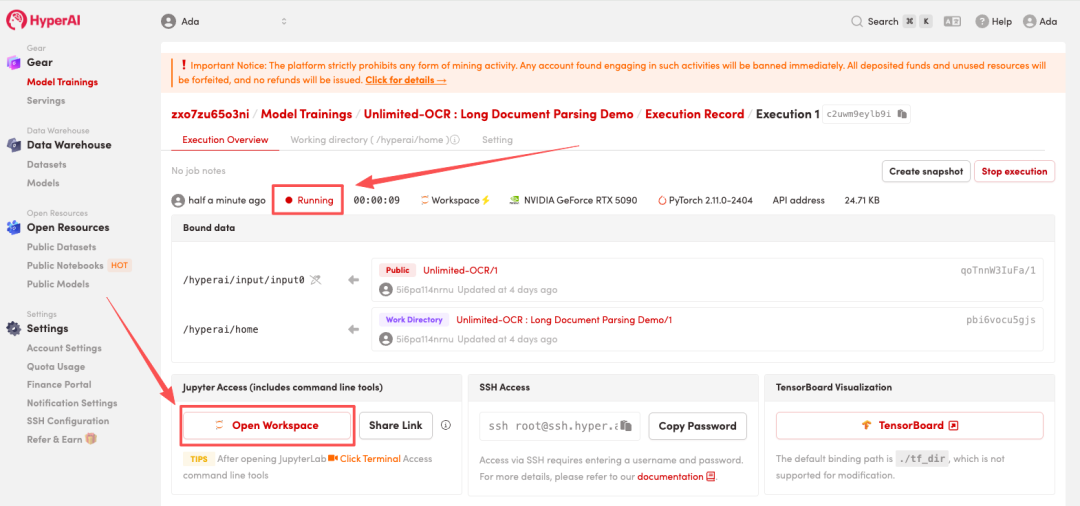
Affichage des effets
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
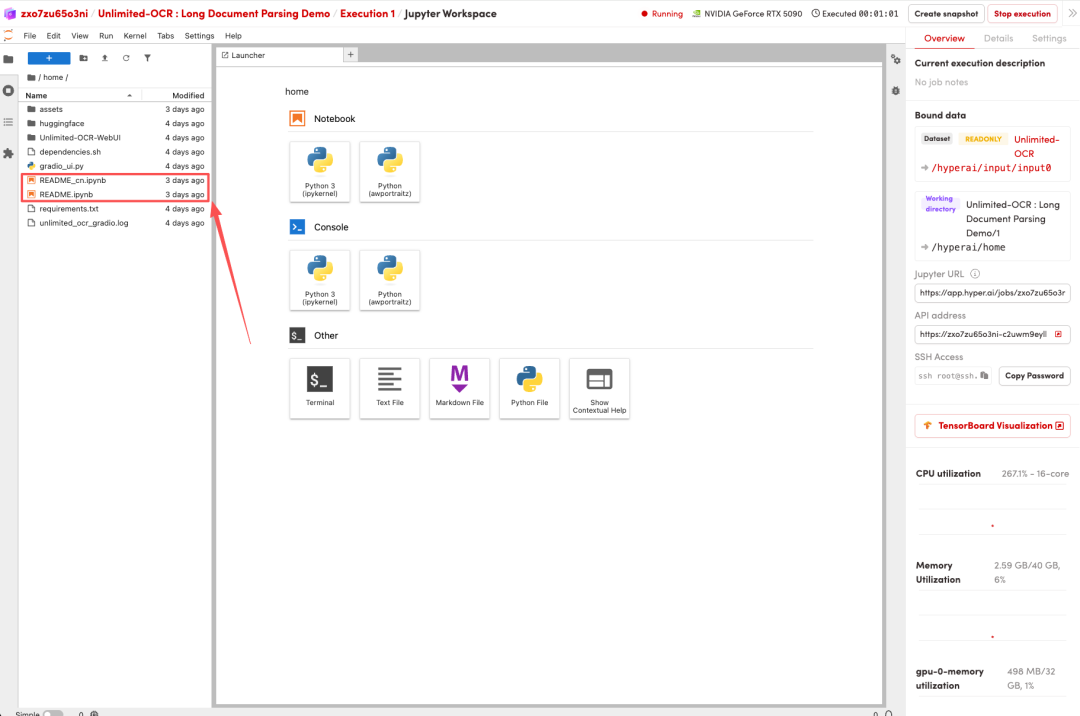
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour ouvrir l'interface de démonstration.