Command Palette
Search for a command to run...
Meta Propose Des Data Scientists Spécialisés En IA, Et Autodata Crée Des Ensembles De Données d'entraînement/d'évaluation De Haute qualité.

Ces dernières années, l'amélioration continue des capacités des modèles à grande échelle a profondément modifié le développement de l'intelligence artificielle. Toutefois, un consensus se dégage : la performance des modèles évolue progressivement d'une approche axée sur l'innovation algorithmique vers une approche axée sur la qualité des données. Face à la raréfaction et au coût croissant des données annotées manuellement de haute qualité, les données synthétiques s'imposent comme une méthode d'aide essentielle après l'entraînement. Elles permettent de générer des cas marginaux et des scénarios atypiques, relativement rares dans les corpus réels ; de réduire la complexité et le temps d'annotation manuelle ; et, dans certains cas, de produire des exemples d'entraînement dont la distribution est plus complexe que celle des données annotées manuellement.
Avec l'émergence des grands modèles de langage (LLM), l'« auto-apprentissage » a été proposé comme méthode de génération de données synthétiques à partir d'instructions inédites ou très limitées. S'appuyant sur ce principe, l'« auto-apprentissage ancré » intègre des sources externes, telles que des documents, comme contraintes afin de réduire les illusions et d'accroître la diversité. De plus, l'« auto-apprentissage par chaînes de tâches » introduit un raisonnement en chaîne lors du processus de génération pour construire des tâches plus complexes et précises. Enfin, une catégorie de méthodes dites « d'auto-évaluation » permet à un agent d'interagir avec l'outil avant de proposer la tâche et sa fonction d'évaluation. Cependant, aucune de ces méthodes ne permet de contrôler directement la difficulté et la qualité des données, ce qui conduit à des stratégies d'amélioration telles que le filtrage, l'évolution et le raffinement.
Dans ce contexte,L'équipe de recherche en intelligence artificielle fondamentale de Meta (FAIR at Meta) a proposé une méthode générale appelée Autodata.Toutes les méthodes décrites ci-dessus ont été unifiées et généralisées. Dans ce cadre, un agent intelligent, jouant le rôle d'un « data scientist », est chargé de construire et d'organiser les données, en reproduisant le flux de travail d'un data scientist humain afin de générer des données de haute qualité. Ce processus comprend non seulement la génération initiale des données, mais aussi la phase d'analyse (semblable à une « revue humaine »), l'évaluation de leurs performances, la synthèse des enseignements tirés et la génération itérative de solutions de données améliorées à partir de ces évaluations.
Des chercheurs ont mené des expériences sur des tâches de recherche en informatique, de raisonnement juridique et de raisonnement mathématique, obtenant de meilleurs résultats que les méthodes traditionnelles de construction de données synthétiques. De plus, la méta-optimisation de l'agent du data scientist lui-même a permis d'améliorer encore davantage ses performances.
Les résultats de recherche associés, intitulés « Autodata : un agent scientifique des données pour créer des données synthétiques de haute qualité », ont été publiés en prépublication sur arXiv.
Points saillants de la recherche :
* La méthode de génération de données basée sur les agents offre une voie pour transformer les ressources de calcul d'inférence en données d'entraînement de modèles de meilleure qualité.
* L'agent du data scientist lui-même peut également être méta-optimisé, ce qui permet d'obtenir des améliorations significatives des performances sans avoir besoin d'interventions humaines ni d'ingénierie.
Ces recherches pourraient bien changer la façon dont les tâches et les référentiels futurs seront conçus pour propulser le développement de l'IA à l'avant-garde.

Adresse du document :
https://hyper.ai/papers/2606.25996
Ensemble de données : Couvrant trois scénarios de tâches principaux
Le cadre Autodata a couvert trois scénarios de tâches principaux dans les expériences : les problèmes de recherche en informatique, les tâches de raisonnement juridique et les tâches de raisonnement scientifique basées sur des objets mathématiques.Ces tâches sont construites sur différents systèmes de sources de données afin de tester la capacité de généralisation du cadre dans différentes structures cognitives.
Dans les tâches en informatique,Les chercheurs ont traité plus de 10 000 articles d'informatique provenant du corpus S2ORC (2022 et suivants).2 800 échantillons acceptés ont été générés à l'aide d'Agentic Self-Instruct.Une fois la boucle terminée, ces échantillons sont filtrés à l'aide d'un validateur de qualité basé sur Kimi-K2.6 afin d'éliminer ceux présentant des problèmes tels que la divulgation d'informations spécifiques à l'article, un contexte insuffisant ou un format de critères de notation incorrect. Au final, 1 300 échantillons de haute qualité sont conservés pour constituer l'ensemble de données Agentic Self-Instruct destiné à l'entraînement par apprentissage par renforcement (RL).
Dans les tâches de raisonnement juridique,Les données proviennent de documents juridiques accessibles au public, tels que la Pile of Law, incluant les jugements et les avis juridiques, et sont évaluées sur PRBench-Legal et son sous-ensemble difficile PRBench-Legal-Hard. Contrairement aux articles scientifiques,Les textes juridiques présentent des contraintes logiques structurées plus fortes et une dépendance à la jurisprudence plus marquée ; la tâche de génération met donc davantage l'accent sur la capacité à extraire des faits et à appliquer des règles.
Dans les tâches de raisonnement scientifiqueCette recherche s'appuie sur le jeu de données Principia. Ce jeu de données a été constitué à l'aide de la méthode d'auto-apprentissage CoT et couvre un large éventail de contenus de cours des taxonomies MSC2020 et PHYS. Le jeu de données Principia est composé d'un sous-ensemble de questions de référence en mathématiques et en physique, annotées par des humains. Ces questions ont été vérifiées afin de s'assurer que les réponses impliquent des objets mathématiques.
Dans toutes les tâches, l'objectif d'Autodata n'est pas simplement de générer des paires question-réponse, mais de générer des données d'entraînement capables de distinguer efficacement les modèles faibles des modèles forts.
Autodata : Utilisation d’agents intelligents autonomes pour simuler le rôle des data scientists.
La structure générale d'Autodata est illustrée dans la figure ci-dessous.Ce cadre utilise un agent intelligent autonome pour simuler le rôle d'un data scientist.En générant des données de manière itérative, en effectuant des contrôles qualitatifs et des évaluations quantitatives des performances, en analysant de manière exhaustive les connaissances acquises et en mettant à jour la méthode de génération de données en conséquence, différentes formes d'implémentation peuvent être construites sur ce modèle.
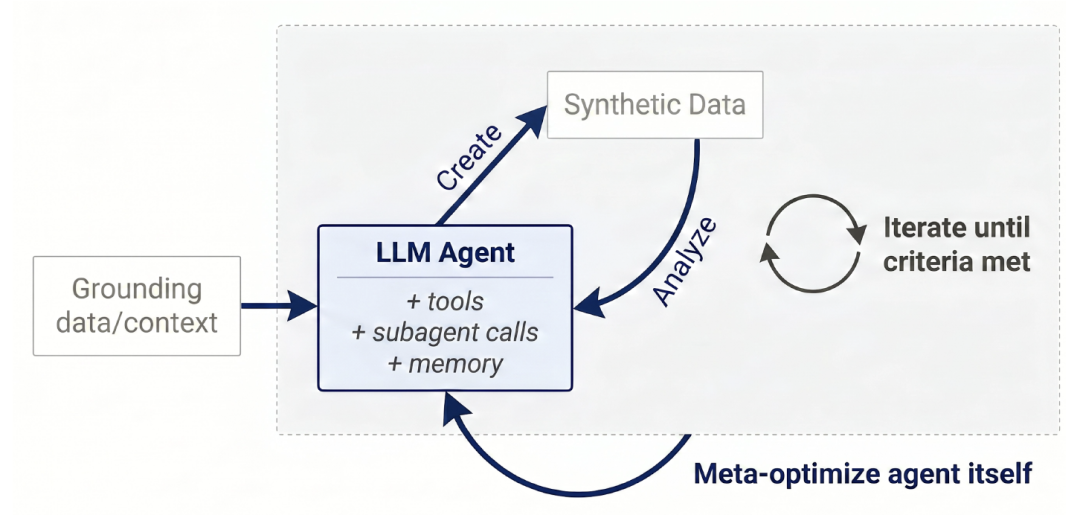
Flux de travail Autodata
La boucle globale se compose des éléments suivants :
① Création de données
L'agent Autodata « ancre » les données fournies (par exemple, des documents spécifiques dans des domaines tels que les mathématiques, le droit ou la programmation, ou d'autres sources de données spécifiques à la tâche) afin de faciliter la génération de données. Cet agent peut utiliser des outils ou ses compétences et son expérience existantes, et exploiter les ressources de calcul de la phase d'inférence, pour générer des données d'entraînement et de référence pour l'entraînement ou l'évaluation du modèle. Cette étape de génération de données peut être répétée après les analyses et l'apprentissage ultérieurs, améliorant ainsi continuellement la qualité des données.
② Analyse des données
Après avoir obtenu les données générées par l'agent, le système les analyse afin d'identifier ses points forts et ses points faibles, et de déterminer comment l'améliorer. Cette analyse peut être menée à différents niveaux : au niveau d'un échantillon unique (par exemple, pour évaluer sa pertinence, sa qualité ou sa complexité), ou au niveau de l'ensemble des données (par exemple, pour vérifier la diversité des échantillons et leur potentiel d'amélioration des performances du modèle en tant que données d'entraînement). Les conclusions de ces analyses sont réinjectées dans l'étape de génération de données, permettant ainsi de produire de meilleures données à l'itération suivante, jusqu'à ce que la condition d'arrêt soit atteinte.
③ Boucle globale du data scientist
L'agent alterne en continu entre la génération et l'analyse des données jusqu'à ce que la qualité de ces dernières soit satisfaisante, générant ainsi un jeu de données d'entraînement ou de référence de haute qualité. Des mécanismes de sécurité ou de contrainte spécifiques peuvent être intégrés à la boucle externe pour empêcher toute intrusion dans le système. Cette boucle, basée sur un agent, permet au modèle d'accumuler et d'exploiter en continu ses acquis d'apprentissage tout au long du processus.
④ Méta-optimisation du data scientist
L'agent lui-même peut être optimisé davantage afin de mieux répondre aux exigences d'un data scientist. Une approche consiste à optimiser le cadre de l'agent à l'aide de méthodes similaires à l'autoresearch ou au méta-harness, et à exploiter le même objectif de boucle interne (c'est-à-dire « générer de meilleures données ») pour guider l'optimisation de boucle externe, améliorant ainsi l'ensemble du système.
Dans sa mise en œuvre, l'article propose l'auto-instruction agentique comme méthode d'instanciation d'Autodata, comme illustré dans la figure ci-dessous :
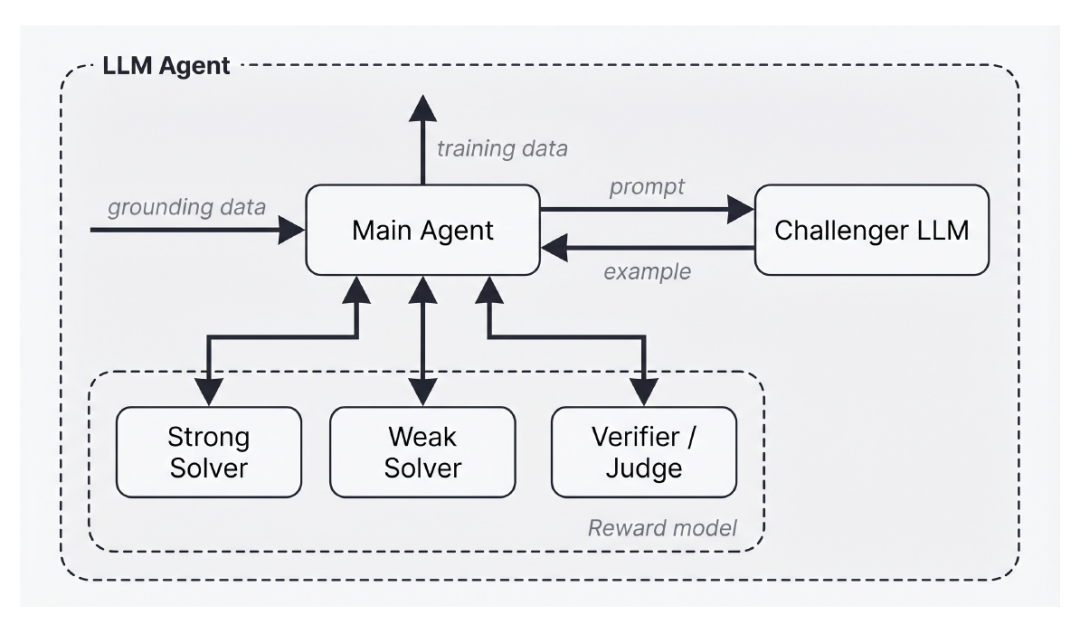
Méthode d'auto-instruction agentique par contraste faible-fort
L'agent orchestrateur principal de cette méthode peut accéder à quatre sous-agents basés sur le Large Language Model (LLM) :
* Challenger : Génère des exemples d’entraînement à partir d’instructions détaillées fournies par l’agent principal ;
* Solveur faible : un modèle qui a généralement du mal à résoudre les données d’entraînement générées ;
* Solveur performant : un modèle capable de résoudre généralement avec succès les données d’entraînement générées ;
* Vérificateur/juge : Après avoir fourni des exemples et des solutions modèles, le vérificateur/juge contrôle la qualité des solutions et renvoie les résultats d’apprentissage à l’agent principal.
Ce système a pour but de générer des données d'entraînement permettant aux meilleurs joueurs de réussir les tâches, tandis que les joueurs moins expérimentés rencontrent des difficultés. Le maître LLM analyse les commentaires des évaluateurs et met à jour les indices envoyés aux participants en conséquence. Ce cycle se répète en continu afin de générer des exemples de haute difficulté pour l'entraînement des joueurs les moins expérimentés.
Présentation des résultats : Obtention de résultats supérieurs aux méthodes traditionnelles de construction de données synthétiques
Les expériences des chercheurs ont porté sur trois domaines de tâches, validant ainsi l'efficacité du cadre Autodata selon de multiples dimensions.
Tâches en informatique
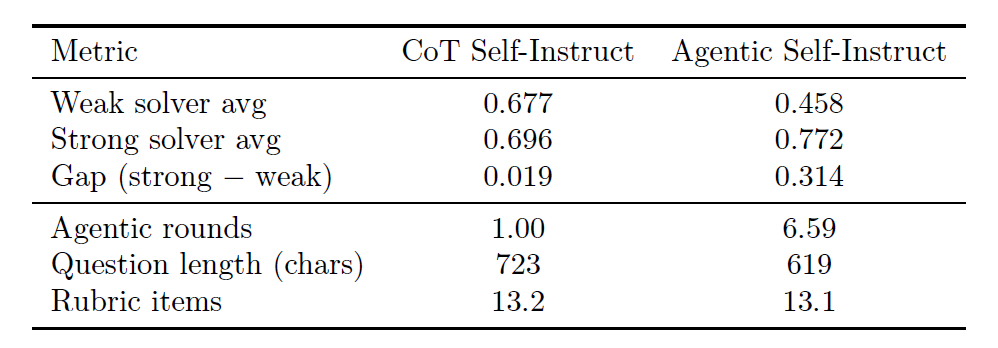
Dans les tâches informatiques, les données générées par Agentic Self-Instruct réduisent considérablement le taux de confusion entre les modèles faibles et forts, rendant le signal d'entraînement plus clair.
Sur les problèmes générés à l'aide de la méthode d'auto-apprentissage CoT de base, le solveur faible a obtenu un score moyen de 0,677. Cependant, sur le même matériel source (articles) de problèmes générés à l'aide d'Agentic Self-Instruct, le score du solveur faible a diminué de 22 points de pourcentage (0,677 → 0,458), tandis que le score du solveur fort a augmenté de 8 points de pourcentage (0,696 → 0,772), comme le montre le tableau ci-dessous.Cela indique que la question finalement acceptée a un effet incitatif plus important sur la capacité de raisonnement approfondi du modèle robuste.
En apprentissage par renforcement (RL), sur le jeu de test plus simple CoT Self-Instruct (partie gauche du tableau ci-dessous), l'entraînement avec les données CoT améliore la moyenne à 3 étapes (mean@3) du modèle 4B de base de 0,630 à 0,727, tandis que l'entraînement avec les données Agentic l'améliore encore à 0,774. Sur le jeu de test Agentic, plus difficile (partie droite du tableau ci-dessous), les résultats correspondants sont : 0,366 (modèle de base) → 0,500 (entraînement CoT) → 0,632 (entraînement Agentic). La différence entre les deux méthodes est nettement plus importante sur ce jeu de test (plus du double de celle observée sur le jeu de test CoT), et la métrique best@3 confirme ce classement.
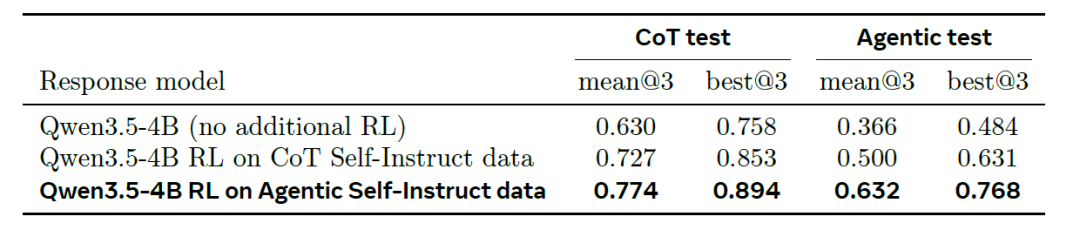
Le modèle entraîné avec Agentic a démontré une transférabilité dans les deux sens (+0,05 sur l'ensemble de test CoT et +0,13 sur l'ensemble de test Agentic, plus difficile). Cet avantage significatif suggère que les données d'entraînement plus discriminantes générées par le pipeline Agentic peuvent se traduire par de meilleures capacités d'inférence.
tâche de raisonnement juridique
Dans le domaine du raisonnement juridique, la recherche a mis en évidence un phénomène contrasté, mais tout aussi important : les données générées par les algorithmes CoT traditionnels sont souvent trop difficiles, ce qui empêche les modèles les plus faibles de fournir des signaux de gradient efficaces (entraînant un grand nombre de résultats nuls). Autodata, grâce à un mécanisme de rétroaction d'évaluation plus fin, ramène la difficulté des données dans une plage d'apprentissage acceptable, améliorant ainsi considérablement la stabilité et l'efficacité de l'entraînement des algorithmes GRPO.
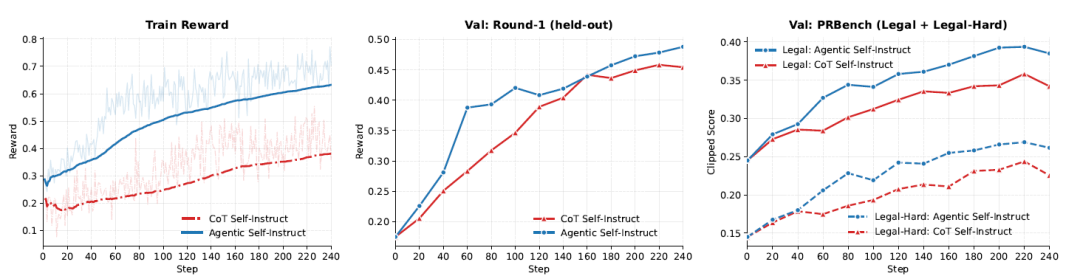
Les chercheurs ont utilisé GRPO pour entraîner Qwen3.5-4B sur deux sources de données : 2 800 paires question-grille d’évaluation juridique (Agentic Self-Instruct et CoT Self-Instruct). Au cours de l’entraînement, toutes les 20 étapes, l’ensemble de données a été testé sur deux ensembles d’évaluation : un ensemble de validation CoT contenant 100 questions et un ensemble PRBench divisé en questions juridiques et questions complexes. Toutes les récompenses et tous les scores ont été évalués à l’aide de Kimi-K2.6. La courbe d’entraînement de la figure ci-dessous montre qu’à chaque point d’évaluation…Les méthodes agentiques sont systématiquement en tête en matière de récompenses de formation, d'ensembles de validation CoT et de PRBench-Legal.
tâche de raisonnement scientifique
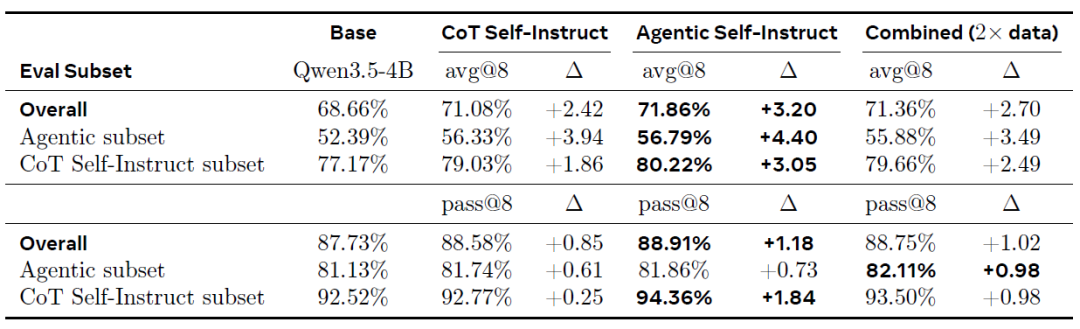
Dans les tâches de raisonnement scientifique, l'auto-instruction Agentic présente également un avantage constant. Sur l'ensemble de validation combiné (comme indiqué dans le tableau ci-dessous), l'entraînement avec les données d'auto-instruction Agentic a permis d'obtenir la plus grande amélioration globale (+3,20% en moyenne à 8), surpassant l'utilisation directe de l'auto-instruction CoT (+2,42%) et les données combinées (+2,70%).
Évaluation des résultats de l'entraînement par renforcement sur des tâches de raisonnement scientifique
Un résultat clé est que, même sur le sous-ensemble de validation CoT non optimisé, Agentic Self-Instruct offre une amélioration des performances supérieure (+3,05% contre +1,86% pour CoT). Cela suggère que…L'entraînement sur des tâches plus difficiles peut être transféré à des tâches plus simples : en itérant sur des exemples de haute difficulté générés par un processus agentiel, des capacités de raisonnement généralisables peuvent être apprises, au lieu d'être limitées à une distribution de difficulté spécifique.
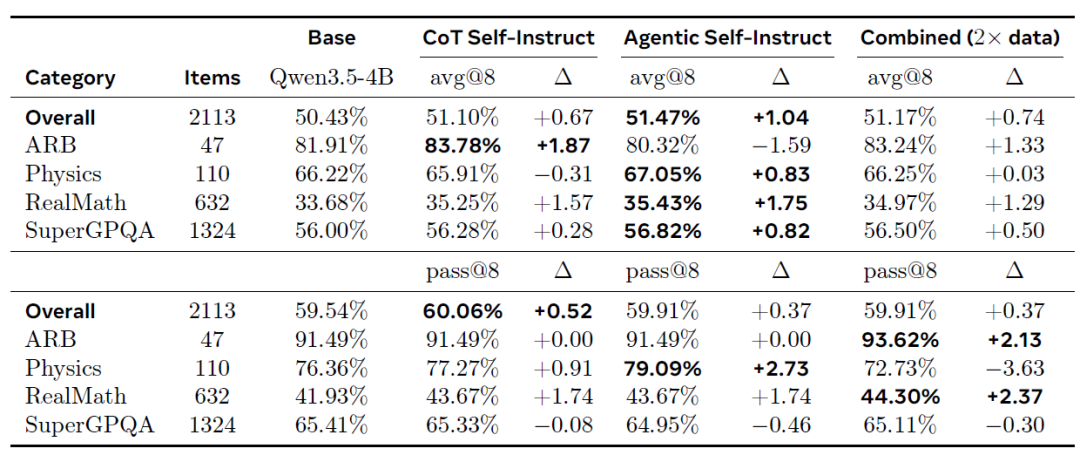
Sur le benchmark Principia hors distribution (comme indiqué dans le tableau ci-dessous), Agentic Self-Instruct a également obtenu la meilleure amélioration moyenne (+1,041 TP3T en moyenne à 8) et s'est constamment distingué dans plusieurs catégories, notamment RealMath (+1,751 TP3T) et SuperGPQA (+0,821 TP3T). Cet effet de transfert démontre une fois de plus que les problèmes plus complexes générés par Agentic Self-Instruct peuvent améliorer les capacités de raisonnement robuste.
Conclusion
En résumé, Autodata propose un nouveau paradigme de génération de données : modéliser le processus de génération comme une boucle d’analyse de données pilotée par un agent intelligent. Dans ce cadre, la génération, l’évaluation, l’analyse des défaillances et l’optimisation des politiques de données sont unifiées au sein d’un système unique en boucle fermée. Des expériences de méta-optimisation complémentaires démontrent que l’agent d’analyse de données lui-même peut être optimisé, améliorant ainsi la qualité des données sans intervention humaine.
Globalement, la contribution majeure de cette recherche réside dans la mise au point d'un mécanisme permettant de transformer les ressources de calcul utilisées lors de la phase d'inférence en une capacité à générer des données d'entraînement de meilleure qualité. Ce domaine offre encore un potentiel de développement important, notamment pour l'adaptation à des tâches à plus grande échelle, une collaboration plus complexe entre agents à plusieurs tours et une optimisation globale au niveau de l'ensemble de données. Par ailleurs, la réintroduction du retour d'information humain dans le processus, afin de former un mécanisme d'optimisation collaborative avec l'agent, constitue également une piste de développement importante.








