Command Palette
Search for a command to run...
Le MIT Et IBM Ont Publié ChartNet, Le Plus Grand Ensemble De Données De Graphiques Synthétiques À Ce Jour, Générant 1,5 Million d'échantillons De Graphiques diversifiés.

Ces deux dernières années, le développement de grands modèles multimodaux a largement dépassé les attentes. De la reconnaissance du contenu d'images à la compréhension de documents complexes et à l'analyse d'informations vidéo, les modèles de langage visuel (MLV) repoussent sans cesse les limites de leurs capacités. Pourtant, un objet visuel en apparence simple, mais extrêmement complexe, continue de provoquer fréquemment des dysfonctionnements chez de nombreux modèles avancés : les graphiques.
Pour les humains, un graphique à barres, un graphique linéaire ou un nuage de points permettent de visualiser rapidement les tendances, les comparaisons et les conclusions principales. Cependant, pour l'IA, les graphiques sont bien plus que de simples images. Les modèles doivent non seulement reconnaître les éléments visuels, mais aussi comprendre les relations entre les axes, les points de données, les légendes et les étiquettes, et effectuer des extractions numériques, des analyses de tendances, voire des inférences causales. En d'autres termes, la compréhension des graphiques est une tâche complexe qui fait appel à des capacités cognitives visuelles, numériques et linguistiques, et les modèles de langage visuel actuels ne peuvent y parvenir que partiellement.
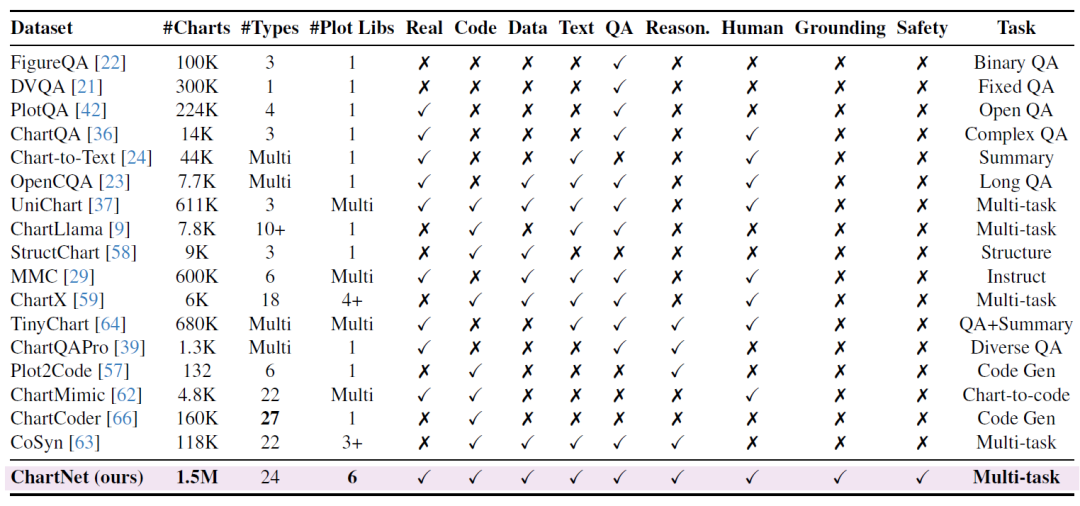
Ces dernières années, certains jeux de données ont stimulé le développement de la recherche dans ce domaine, mais ils souffrent généralement de trois problèmes : leur petite taille, le nombre limité de types de graphes et l’absence d’informations multimodales complètes. De nombreux jeux de données se concentrent sur une seule tâche (comme la réponse à des questions ou la description de graphes) ou ne comportent pas certaines modalités essentielles ; par conséquent, les modèles open source restent en retrait par rapport aux systèmes propriétaires pour les tâches complexes de raisonnement sur les graphes.
Pour combler ce manque,ChartNet a été proposé par de nombreux experts du MIT, du laboratoire de recherche informatique MIT-IBM et d'IBM Research.—Un ensemble de données multimodal de haute qualité, composé de millions d'enregistrements, destiné à la compréhension des graphes et conçu pour améliorer les capacités de compréhension et de raisonnement dans ce domaine.
ChartNet est le plus grand ensemble de données de graphiques synthétiques à ce jour. Il utilise un processus de synthèse novateur guidé par le code pour générer 1,5 million d'échantillons de graphiques variés, couvrant 24 types de graphiques et 6 bibliothèques de tracé. De nombreuses expériences valident la praticité de ChartNet, démontrant que son modèle optimisé surpasse des modèles beaucoup plus grands et GPT-4o sur toutes les tâches.
Utilisez l'ensemble de données en ligne :https://go.hyper.ai/lGPsc
Les résultats de cette recherche, intitulée « ChartNet : un ensemble de données multimodales de haute qualité à l'échelle d'un million d'éléments pour une compréhension robuste des graphiques », seront publiés lors de la conférence IEEE sur la vision par ordinateur et la reconnaissance des formes.
Points saillants de la recherche :
Le processus de synthèse et de génération guidé par le code de ChartNet permet la génération d'échantillons de graphiques à grande échelle, tout en capturant des informations visuelles, structurelles, numériques et textuelles sur la compréhension du graphique.
ChartNet intègre des données réelles et des données étiquetées manuellement, et comprend un sous-ensemble spécialisé qui prend en charge le pointage visuel et l'analyse de sécurité, augmentant ainsi la valeur des ensembles de données dans l'entraînement et l'évaluation des modèles.
L'ajustement précis de cet ensemble de données peut améliorer en continu les performances du modèle de langage visuel dans des tâches telles que la reconstruction de graphiques, l'extraction de données et la synthèse de graphiques.

Adresse du document :
https://hyper.ai/papers/2603.27064
Ensemble de données : composé de 1,5 million d’échantillons synthétiques alignés multimodaux
L'ensemble de données principal de ChartNet se compose de 1,5 million d'échantillons synthétiques multimodaux alignés.Chaque exemple comprend : une image de graphique, le code de tracé, des données tabulaires, une description en langage naturel et une paire question-réponse avec raisonnement chaîné (CoT). La figure suivante présente un aperçu complet des attributs de données, des types de graphiques et des bibliothèques de tracé utilisées :
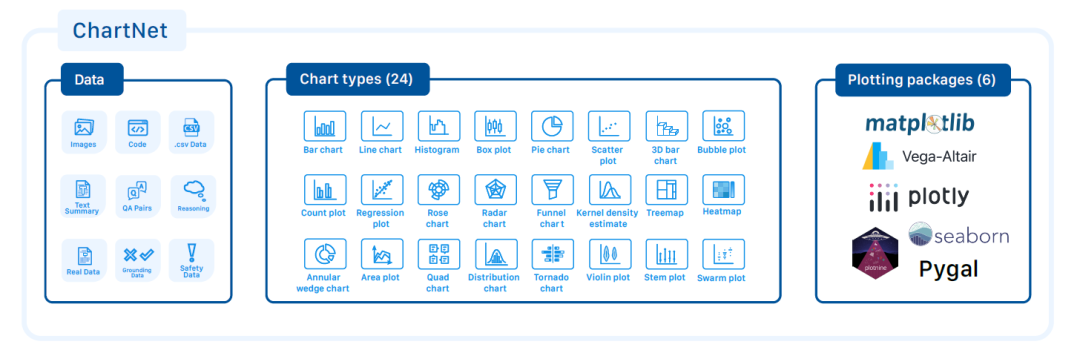
Pour couvrir l'ensemble des capacités de compréhension des graphes, ChartNet inclut également plusieurs sous-ensembles spécialisés : données étiquetées manuellement, graphes du monde réel, données d'ancrage et données de sécurité.
Données du graphique composite étiquetées manuellement :Il contient 96 643 images de graphiques synthétiques alignées, des descriptions et des données tabulaires, qui ont toutes fait l'objet d'une validation et d'une annotation humaines rigoureuses.
Données graphiques de haute qualité issues du monde réel :Pour compléter le corpus de graphiques synthétiques, les chercheurs ont compilé et annoté 30 000 graphiques issus de données réelles provenant de médias internationaux de référence et d’organismes de visualisation de données, tels que la Banque mondiale, Bain & Company, le Pew Research Center, Our World in Data et d’autres éditeurs de renommée mondiale. Cette collection couvre un large éventail de sujets contemporains, notamment l’économie, la technologie, la géopolitique, les sciences de l’environnement et les tendances sociales, tout en garantissant une grande diversité de données et une forte pertinence concrète. Les graphiques présentant un faible contenu informationnel ou une qualité insuffisante ont été explicitement supprimés afin d’en faciliter l’interprétation.
Fonder l'assurance qualité sur les données :La modélisation visuelle moderne (MVM) peine encore à identifier les régions graphiques et les éléments syntaxiques pertinents pour des questions spécifiques. Afin d'améliorer cette capacité, des chercheurs ont conçu un système de questions-réponses ancrées. Ils ont d'abord extrait des annotations géométriques des éléments de code du graphique (axes, graduations, lignes de la grille, légendes et blocs graphiques) pour générer des annotations d'ancrage denses. Une méthode basée sur l'entropie a ensuite été utilisée pour filtrer les boîtes englobantes. Enfin, à partir de ces annotations, un ensemble de questions-réponses standardisées a été créé pour chaque graphique, permettant ainsi de faire correspondre la disposition spatiale attendue des éléments visuels et le contenu réel du graphique.
L'emplacement attendu est encodé dans la chaîne de réponse à l'aide d'une représentation sérialisée de la boîte englobante. Les modèles comprennent des éléments visuels uniques et récurrents, combinant indices, étiquettes textuelles du graphique et attributs visuels tels que la couleur des éléments pour générer des expressions de citation. Le générateur prend en charge les réponses courtes et longues et peut inclure, en option, des informations d'ancrage. L'ensemble de données final génère une paire question-réponse par graphique en effectuant un échantillonnage uniforme sur tous les types de modèles et modalités de sortie. De plus, des paires question-réponse avec ancrage basé sur l'inférence sont générées à l'aide de gpt-oss-120b.
Données de sécurité :Pour répondre aux préoccupations en matière de sécurité, les chercheurs ont étendu le processus de génération de données afin de produire des données conformes aux normes de sécurité relatives aux graphiques, réduisant ainsi le contenu nuisible dans les résultats du modèle et le risque de « jailbreak ».
L'idée centrale de ChartNet : la synthèse de graphiques guidée par le code pour une génération automatique.
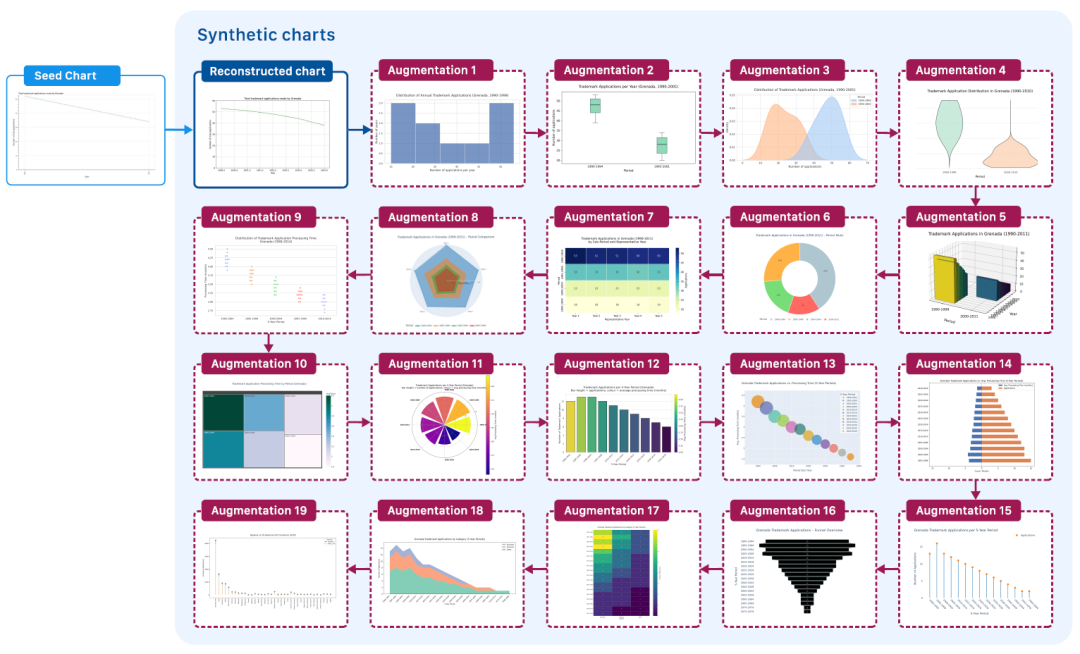
L'idée fondamentale de ChartNet pour la génération de données est que les graphiques peuvent être générés par programmation, le code de tracé exécutable servant de représentation intermédiaire structurée pour la visualisation des données. Des chercheurs ont proposé un processus automatisé de génération de graphiques à grande échelle, guidé par le code (voir figure ci-dessous). Ce processus part d'une quantité limitée de données d'images de graphiques (« graines ») et utilise un modèle de langage visuel (MLV) pour produire un code capable de reconstruire approximativement ces graphiques.
Processus d'augmentation de graphiques guidé par le code
Plus précisément, le processus de génération de données comprend les étapes suivantes :
① Reconstruction du graphique en code :VLM est utilisé pour générer du code Python permettant de reconstruire approximativement un ensemble donné d'images de graphiques. À cette étape, 150 000 images de graphiques uniques issues du jeu de données TinyChart sont sélectionnées comme points de départ, mais le processus n'est pas spécifiquement tributaire de ce choix.
② Augmentation des graphiques guidée par le code :Le code de tracé généré est ensuite réécrit itérativement à l'aide d'un modèle de langage étendu (LLM). Tout en conservant la cohérence avec l'itération précédente, les valeurs et les étiquettes des données sous-jacentes sont modifiées pour mieux correspondre au type de graphique souhaité. La figure ci-dessous illustre le processus d'amélioration itérative du code et de rendu du graphique ; cette étape est cruciale pour la mise à l'échelle de l'ensemble de données, chaque image initiale pouvant générer un nombre quelconque de variantes.
③ Rendu du graphique :Exécutez tout le code de tracé généré pour produire des images graphiques ; les scripts exécutés avec succès seront associés à leurs images générées.
④ Filtrage de la qualité :Chaque image de graphique est évaluée à l'aide de VLM pour détecter diverses catégories potentielles de défauts de rendu (telles que le chevauchement de texte, le rognage d'étiquettes, l'occlusion d'éléments de graphique, etc.), et les images présentant des problèmes visuels ainsi que leur code de tracé seront supprimés.
⑤ Génération d'attributs guidée par le code :Enfin, VLM est utilisé pour générer des attributs sémantiques supplémentaires pour les paires image-code du graphique. Les valeurs et les étiquettes des données sont extraites du graphique en fonction du contexte du code, et une représentation tabulaire des données est générée. De plus, en combinant les informations visuelles, le code et les données tabulaires, une description du graphique contextualisée est générée.
Il permet d'obtenir des améliorations significatives et constantes dans toutes les tâches de compréhension de graphiques.
Pour vérifier l'efficacité de ChartNet dans l'amélioration de la capacité du modèle à comprendre les graphiques, les chercheurs ont entraîné des modèles de langage visuel de différentes tailles sur l'ensemble de données ChartNet, y compris des modèles ultra-compacts (≤1B de paramètres), petits (≤4B de paramètres) et moyens (≤7B de paramètres).
Globalement, le réglage fin sur l'ensemble de données ChartNet donne des améliorations significatives et cohérentes dans toutes les tâches de compréhension des graphiques (voir tableau ci-dessous) – l'uniformité et l'ampleur de ces améliorations sont indépendantes de la taille du modèle.Cela démontre que les VLM existants manquent d'opportunités pour un apprentissage supervisé par graphes multimodaux de haute qualité, tandis que ChartNet comble efficacement cette lacune.
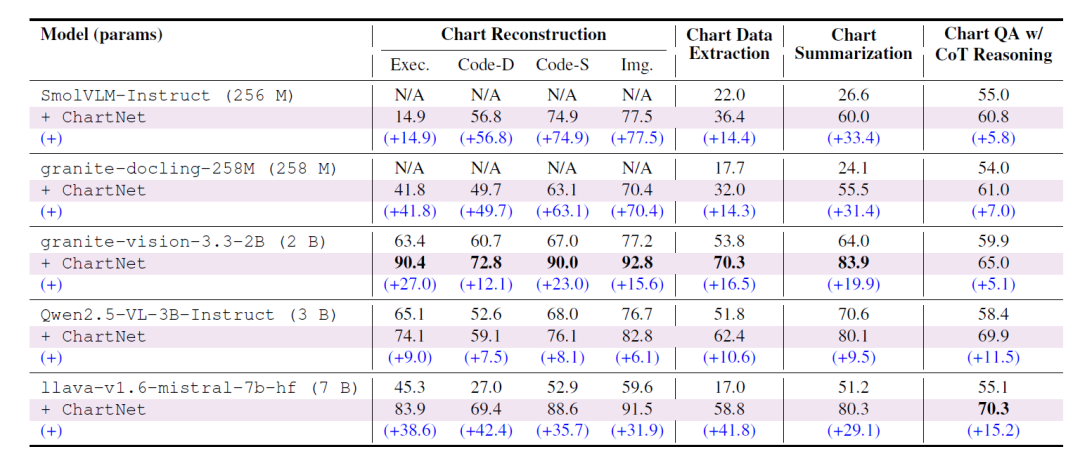
① Reconstruction du graphique
Les modèles entraînés sur le sous-ensemble Chart-to-Code ont permis d'obtenir des améliorations significatives en termes de vitesse d'exécution du code, de cohérence des données, de similarité structurelle/de code et de similarité d'images : des modèles ultra-compacts (SmolVLM-256M, Granite-Docling-258M), auparavant incapables de reconstruire les graphiques, sont désormais pleinement fonctionnels ; des modèles plus petits (comme Granite-Vision-2B) ont atteint une reconstruction quasi parfaite, avec plusieurs métriques dépassant 90% ; le modèle LLaVA-7B a enregistré une amélioration de la cohérence des données allant jusqu'à +42,4 points. Cette tendance, indépendante de l'échelle, indique que l'alignement multimodal de ChartNet entre les images et le code fournit au modèle une supervision structurée qui faisait défaut auparavant dans l'ensemble de données.
② Extraction des données du graphique
ChartNet améliore considérablement la capacité de tous les modèles à extraire directement des tableaux numériques à partir de graphiques. GraniteVision-2B atteint les meilleures performances avec un score de 70,31 TP3T. Le modèle LLaVA-7B, finement optimisé, affiche un gain de performance de 41,8 points, surpassant tous les modèles de référence open source et même GPT-4o (seulement 46,71 TP3T). Ceci démontre l'intérêt du couplage étroit de ChartNet entre les graphiques générés par le code et les données CSV, permettant au modèle d'accéder à la fois à la géométrie visuelle et à la structure numérique sous-jacente.
③ Résumé graphique
La qualité de synthèse de toutes les familles de modèles s'est considérablement améliorée, avec des gains allant de +9,5 (Qwen2.5-VL-3B) à +31,4 (Granite-Docling-2B). Le modèle Granite-Vision-2B, après optimisation, a atteint 83,9%, surpassant GPT-4o et tous les modèles de référence open source du tableau 3, y compris ceux dont le nombre de paramètres est dix fois supérieur. Ceci démontre que la synthèse de ChartNet (construite conjointement par le code et les graphiques rendus) fournit des signaux de supervision structurés et sémantiquement complets, essentiels à la compréhension descriptive des graphiques.
④ Questions et réponses avec raisonnement CoT
Dans les tâches d'inférence complexes à plusieurs étapes, chaque modèle a montré une amélioration constante de la précision - LLaVA-7B a montré la plus grande amélioration (+15,17), atteignant 70,3%, surpassant le modèle d'inférence de graphiques dédié ChartGemma et tous les modèles open-source comparables ou plus grands (y compris GPT-4o).
⑤ Comparaison avec les modèles disponibles sur le marché
Le tableau ci-dessous montre que le modèle optimisé par ChartNet surpasse le modèle standard doté d'un plus grand nombre de paramètres dans presque tous les domaines. Après optimisation, les modèles à 2 ou 7 milliards de paramètres sont systématiquement plus performants que les modèles comportant entre 20 et 72 milliards de paramètres. En particulier, pour les tâches de reconstruction de graphiques et d'extraction de données, le modèle optimisé par ChartNet surpasse largement GPT-4o.
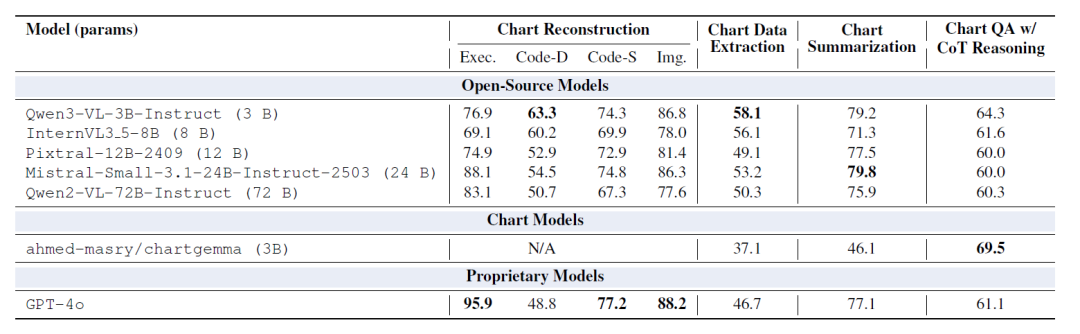
Cela suggère que, dans les domaines où la vision, les données numériques et le langage sont étroitement liés, comme la compréhension des graphes, fournir une supervision multimodale de haute qualité et alignée sur le code est plus efficace que d'augmenter simplement la taille du modèle.
⑥ Généralisation aux indicateurs publics
Comme le montre le tableau ci-dessous, après un réglage fin sur le jeu de données ChartNet principal, tous les modèles ont enregistré des améliorations significatives sur les benchmarks publics : Granite-Vision-2B est passé de 1,6 à 12,4 points BLEU sur ChartCap et de 30,8 à 58,4 sur ChartMimic-v2 ; même le modèle ultra-compact (SmolVLM-256M) a bénéficié d’un gain de performance considérable. Cette amélioration s’est avérée constante pour les tâches de résumé de graphiques et de génération de code à partir de graphiques, démontrant ainsi que la supervision d’alignement multimodal de ChartNet peut être efficacement appliquée à des benchmarks réels, et pas seulement à des distributions d’entraînement synthétiques.
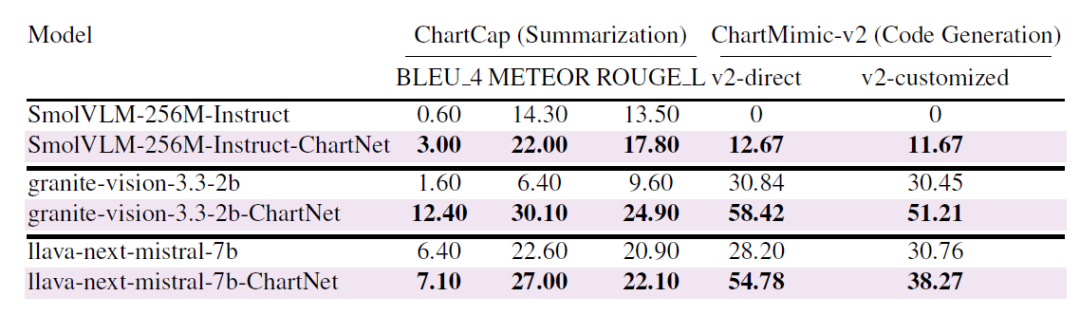
Améliorer la capacité de généralisation des données synthétiques ChartNet sur deux benchmarks publics réels
Conclusion
ChartNet vise à résoudre un problème majeur dans le domaine de la compréhension des graphiques : le manque de signaux de supervision à grande échelle et de haute fidélité pour l’alignement d’images, de code tracé, de données numériques, de descriptions textuelles et de trajectoires d’inférence. Cette plateforme évolutive et ouverte constitue un socle pour la recherche en modélisation multimodale dans les domaines du raisonnement numérique, de la compréhension visuelle, de l’intelligence documentaire et de l’alignement de code. Elle permet ainsi à la modélisation visuelle (VLM) de passer de la simple description des graphiques à la compréhension des informations structurées qu’ils contiennent.
« De nombreux jeux de données d'entraînement précédents se limitaient à répondre à des questions simples sur les graphiques », explique Jovana Kondic, doctorante au département de génie électrique et d'informatique (EECS) du MIT et première auteure de l'article relatif à ChartNet. « Avec ChartNet, nous avons cherché à aller plus loin en générant des données permettant une compréhension approfondie et complète des graphiques. »
À l'avenir, les chercheurs prévoient de continuer à développer ChartNet en y intégrant des données plus complexes, créant ainsi une valeur concrète pour un plus grand nombre de secteurs.
Références :
https://arxiv.org/abs/2603.27064
https://news.mit.edu/2026/mit-researchers-teach-ai-models-to-interpret-charts-0603