Command Palette
Search for a command to run...
Rapport Hebdomadaire Sur l'IA | Microsoft MAI-Thinking Explore l'auto-évolution De l'apprentissage Par Renforcement Pur, Atteignant Une Précision AIME De 97% ; VLM³ Réalise La Généralisation De Tâches 3D À Partir De Coordonnées Textuelles Simples, Sans Modification Architecturale… Un Aperçu Rapide Des Articles De Pointe En IA De La Semaine

Les progrès en intelligence artificielle dépendent non seulement des avancées réalisées dans les modèles individuels, mais surtout de la conception de systèmes capables d'amélioration continue. C'est pourquoi l'équipe IA de Microsoft considère le développement de modèles comme un problème d'optimisation systémique.Un cadre de travail de type « machine à gravir les collines », conçu pour obtenir des améliorations de performance rapides et durables, est proposé."Sur cette base, un modèle d'inférence MoE MAI-Thinking-1 avec un paramètre total de 1T et un paramètre d'activation de 35B a été entraîné à partir de zéro.
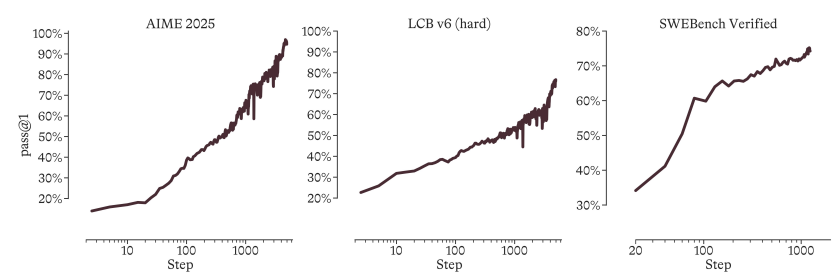
Le modèle rejette complètement les données de distillation provenant de modèles tiers pendant la phase de pré-entraînement et introduit l'algorithme GRPO avec un contrôle d'entropie adaptatif et un mécanisme d'auto-distillation pendant la phase d'apprentissage par renforcement (RL).Les résultats expérimentaux montrent que même en partant de zéro, sans aucune trajectoire d'inférence préalable, MAI-Thinking-1 peut atteindre une croissance des performances log-linéaire stable et à long terme.Finalement, il a atteint des niveaux de pointe en matière d'inférence complexe et de génération de code sur des benchmarks de base tels que AIME 2025 (97.0%) et SWE-Bench Pro (52.8%).
Lien vers le document:https://go.hyper.ai/QeSWd
Derniers articles sur l'IA:https://go.hyper.ai/hzChC
Pour aider un plus grand nombre d'utilisateurs à comprendre les derniers développements dans le domaine de l'intelligence artificielle dans le milieu universitaire,Le site web d'HyperAI (hyper.ai) propose désormais une section « Derniers articles », régulièrement mise à jour avec des articles de recherche de pointe en IA.Voici 9 articles populaires sur l'IA que nous vous recommandons. Jetons un coup d'œil rapide aux dernières avancées en IA cette semaine ⬇️
Recommandation de papier de cette semaine
1. MAI-Pensée-1
Titre de l'article :
MAI-Thinking-1 : Construction d’une machine à gravir les collines
L'équipe IA de Microsoft a proposé une approche d'optimisation par itérations successives, considérant le développement du modèle comme un problème d'optimisation système. Elle a entraîné le modèle d'inférence MoE MAI-Thinking-1 à partir de zéro, avec un total de 1 000 paramètres et 35 milliards de paramètres d'activation. Le pré-entraînement du modèle s'est basé exclusivement sur des données vierges, sans utiliser de données extraites de sources tierces. Lors de la phase d'apprentissage par renforcement, l'équipe a obtenu une croissance stable et durable des performances, sans trajectoire d'inférence initiale, grâce à l'algorithme GRPO avec contrôle adaptatif de l'entropie et mécanisme d'auto-distillation. Le modèle intègre finalement des compétences issues de trois domaines d'expertise : sciences, technologies, ingénierie et mathématiques (STEM), agents logiciels et sécurité, démontrant des performances d'inférence et de code exceptionnelles sur des benchmarks tels que AIME 2025 (97,01 TP3T) et SWE-Bench Pro (52,81 TP3T).
Document et interprétation détaillée :https://go.hyper.ai/QeSWd
2. VLM³
Titre de l'article :
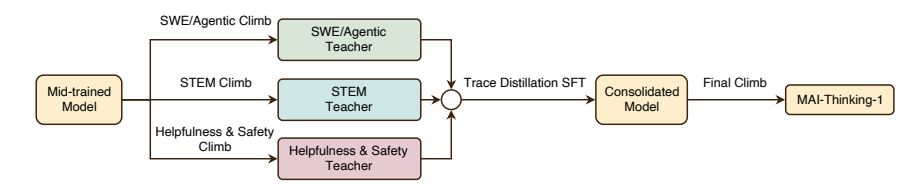
VLM³ : Les modèles de langage visuel sont des apprenants 3D natifs
Meta et son équipe ont découvert, grâce à des expériences à grande échelle, que l'apprentissage 3D efficace des modèles visuels de langage (VLM) ne requiert ni architectures complexes ni conceptions spécialisées ; il suffit d'une focale unifiée, de l'introduction de références textuelles aux pixels et de stratégies judicieuses de mélange et d'expansion des données. Forts de cette découverte, ils ont proposé VLM³, une conception minimaliste permettant aux VLM standard d'effectuer simultanément des tâches telles que l'estimation de profondeur, la correspondance au niveau du pixel, l'estimation de la pose de la caméra et la compréhension 3D au niveau de l'objet. Tout en conservant l'architecture originale et la méthode d'entraînement textuelle, les performances de VLM³ ont atteint, voire égalé, celles des modèles visuels experts, offrant ainsi une voie plus simple et plus évolutive pour l'apprentissage du monde 3D par les modèles visuels généralistes.
Document et interprétation détaillée :https://go.hyper.ai/5ks6r
3. Localiser n'importe quoi
Titre de l'article :
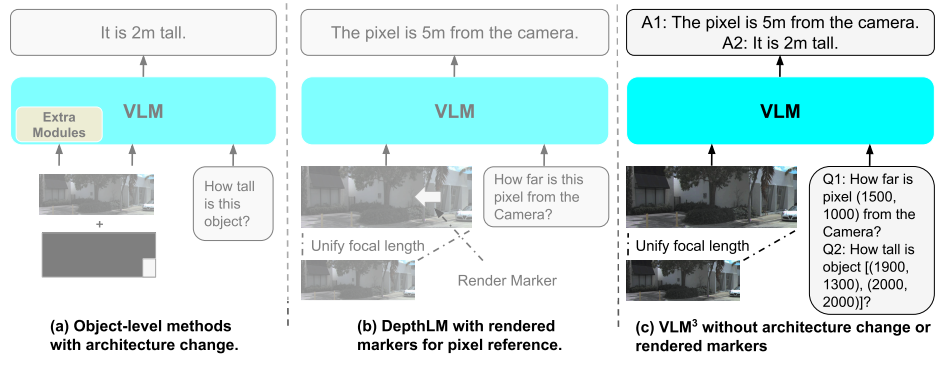
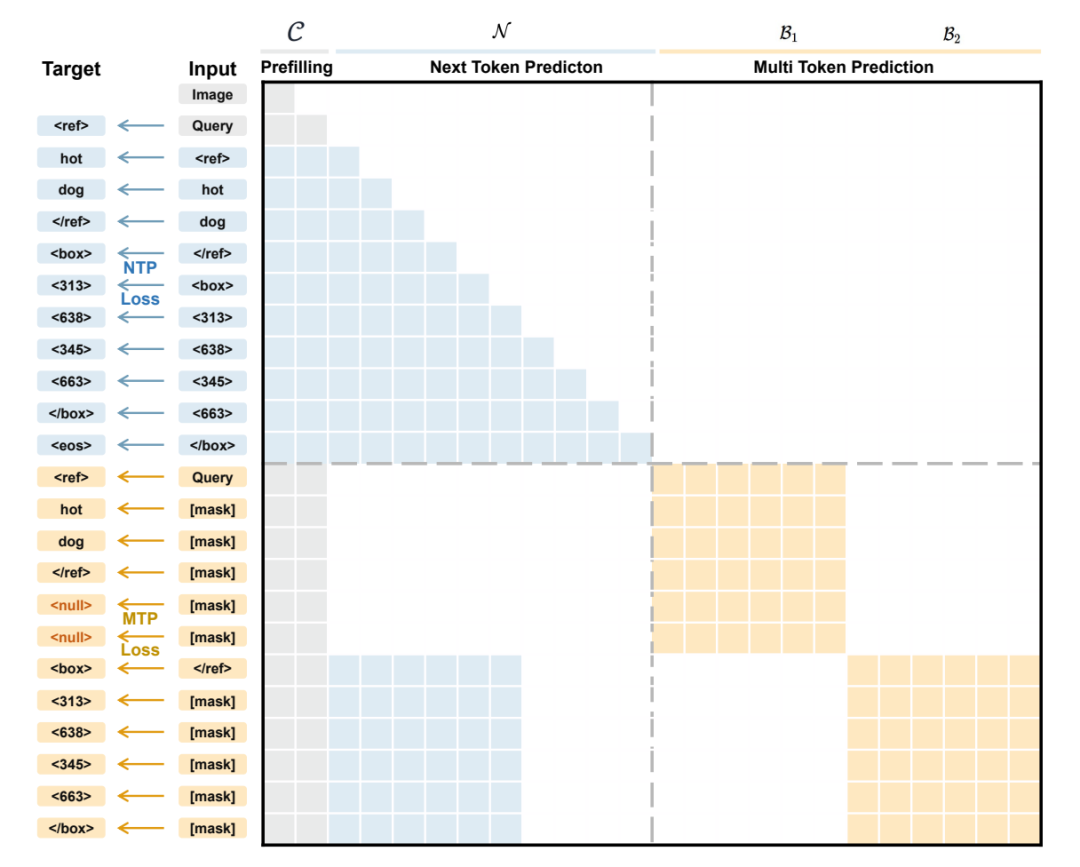
LocateAnything : Mise à l’échelle rapide et de haute qualité du langage visuel avec décodage par boîtes parallèles
Les modèles de langage visuel existants modélisent généralement la localisation d'objets comme un processus de génération étape par étape de jetons de coordonnées, nécessitant la prédiction séquentielle des coordonnées des boîtes englobantes. Cette approche ignore non seulement les relations géométriques au sein des boîtes, mais limite également la vitesse d'inférence. Pour pallier ce problème, l'équipe NVIDIA a proposé LocateAnything, qui utilise un mécanisme de décodage parallèle des boîtes (PBD) pour traiter la boîte englobante comme une unité atomique, générant son ensemble complet de coordonnées en parallèle et en une seule étape. Combiné à un vaste ensemble de données contenant 138 millions de requêtes et à un mode d'inférence hybride avec gestion intelligente des erreurs, ce modèle atteint un débit de décodage plus élevé et une meilleure précision de localisation à IoU élevé sur de multiples benchmarks, repoussant les limites de vitesse et de précision des tâches unifiées de localisation et de détection visuelles.
Document et interprétation détaillée :https://go.hyper.ai/C8jXC
Composition et source de l'ensemble de données : L'équipe de recherche a construit LocateAnything-Data, un corpus à grande échelle contenant 12 millions d'images uniques, 138 millions de requêtes en langage naturel et 785 millions de boîtes englobantes étiquetées.

4. Qwen-VLA
Titre de l'article :
Qwen-VLA : Unification de la modélisation vision-langage-action à travers les tâches, les environnements et les incarnations robotiques
La recherche sur l'intelligence incarnée s'est longtemps appuyée sur des modèles spécialisés pour des tâches uniques, ce qui a engendré des capacités fragmentées et une généralisation limitée. L'équipe Qianwen propose Qwen-VLA, un modèle fondamental unifié vision-langage-action. Grâce à un décodeur d'actions basé sur la théorie des interactions numériques (DiT), il étend la perception, la compréhension et le raisonnement vision-langage aux actions continues et à la génération de trajectoires. Le modèle utilise un pré-entraînement conjoint à grande échelle, intégrant des trajectoires d'opérations robotiques, des démonstrations en vue subjective, des données de simulation, des tâches de navigation et des signaux vision-langage auxiliaires. Il s'adapte également à diverses plateformes robotiques grâce à un mécanisme de conditionnalisation des indices de perception incarnée. Qwen-VLA intègre l'opération, la navigation et la prédiction de trajectoire dans un cadre unifié, assurant ainsi la transférabilité entre les tâches, les environnements et les formes de robots. Les expériences démontrent que le modèle présente des performances multitâches stables et des capacités de généralisation hors distribution sur de multiples benchmarks d'opérations et de navigation.
Document et interprétation détaillée :https://go.hyper.ai/5x2Tj
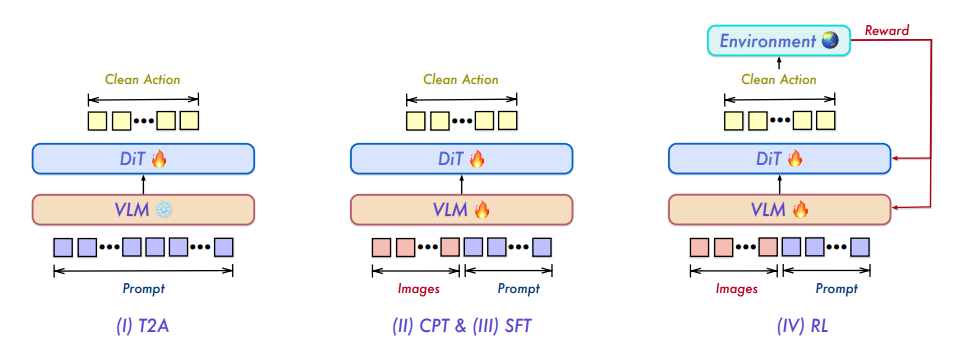
Composition et sources des données : L’équipe de recherche a constitué un vaste corpus hétérogène pré-entraîné afin d’unifier la modélisation visuelle, linguistique et comportementale. Les sources de données comprennent plus de dix jeux de données de robots publics, un important corpus vidéo humain, des données internes propriétaires et des pipelines de simulation générés en interne.

5. SDPG
Titre de l'article :
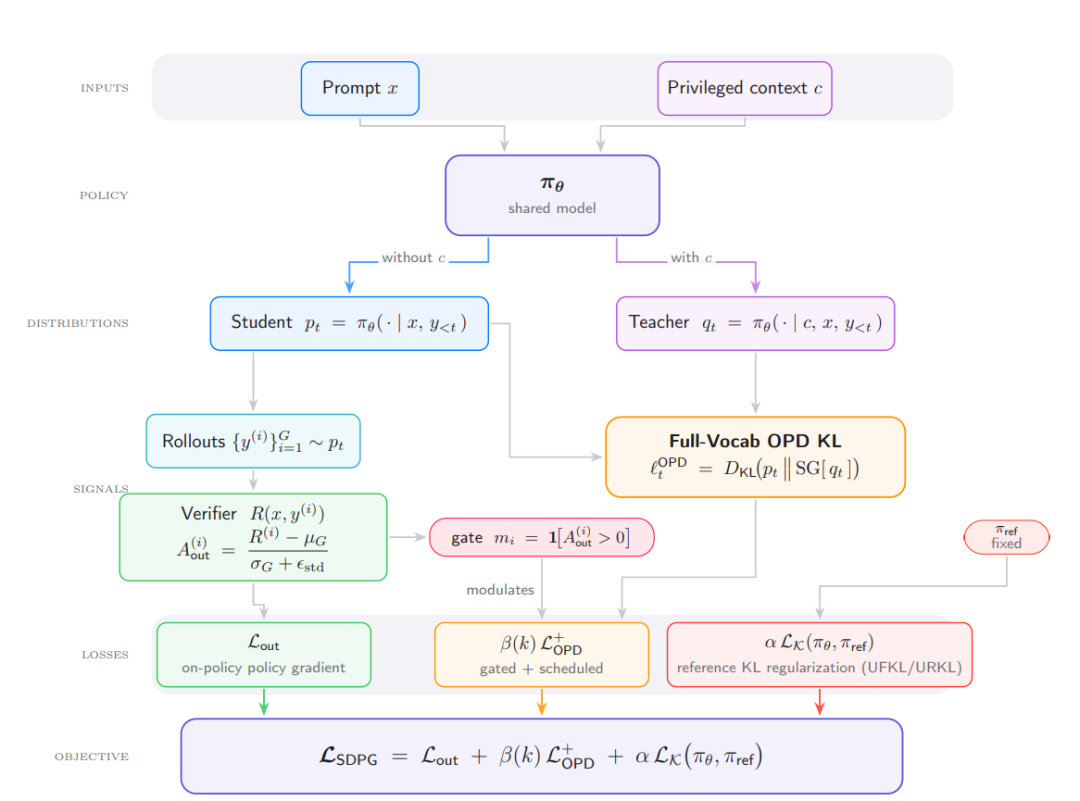
Gradient de politique auto-distillé
L'auto-distillation basée sur les politiques (SDPG) exploite le contexte privilégié du modèle pour superviser ses propres résultats, fournissant ainsi des signaux d'apprentissage plus denses pour l'apprentissage par renforcement à récompenses éparses. Elle peut être formalisée comme une perte élève-professeur de Kullback-Leibler inversée sur l'ensemble du vocabulaire. S'appuyant sur ce principe, des chercheurs de l'UCLA et de l'Université de Princeton ont conjointement proposé le cadre SDPG, combinant l'avantage relatif du validateur de groupe, la normalisation de l'écart type, l'auto-distillation en ligne du vocabulaire complet et la régularisation KL de la politique de référence. Les expériences montrent que SDPG améliore la stabilité et les performances par rapport à RLVR et aux méthodes d'auto-distillation existantes.
Document et interprétation détaillée :https://go.hyper.ai/p5irp
6. GSM-Symbolique
Titre de l'article :
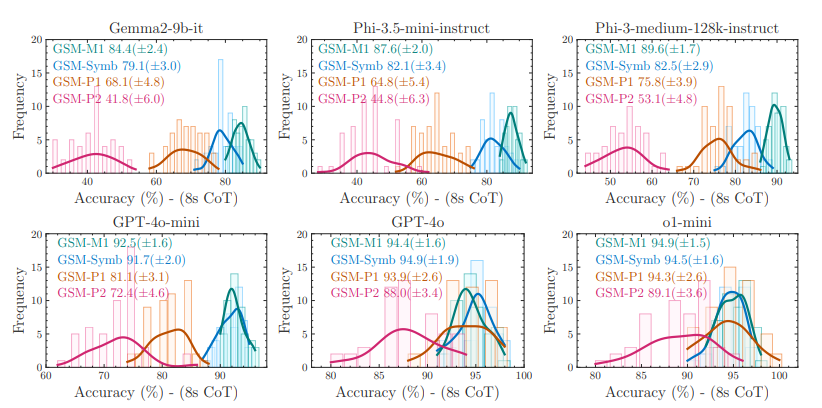
GSM-Symbolique : Comprendre les limites du raisonnement mathématique dans les grands modèles de langage
Les recherches indiquent que les benchmarks GSM8K traditionnels ne permettent pas d'évaluer précisément les performances réelles des modèles. C'est pourquoi l'équipe d'Apple a conçu un benchmark contrôlable, GSM-Symbolic, basé sur des modèles symboliques. Les expériences montrent que la simple modification des nombres ou des noms d'entités dans les questions entraîne des fluctuations importantes des performances des grands modèles ; l'ajout de clauses parasites réduit encore drastiquement la précision. L'équipe de recherche émet l'hypothèse que les modèles de langage (LLM) actuels ne possèdent pas de véritables capacités de raisonnement logique, mais tentent plutôt de reproduire les étapes de raisonnement observées dans leurs données d'entraînement.
Document et interprétation détaillée :https://go.hyper.ai/n3UfJ
7. MUSE-Autoskill
Titre de l'article :
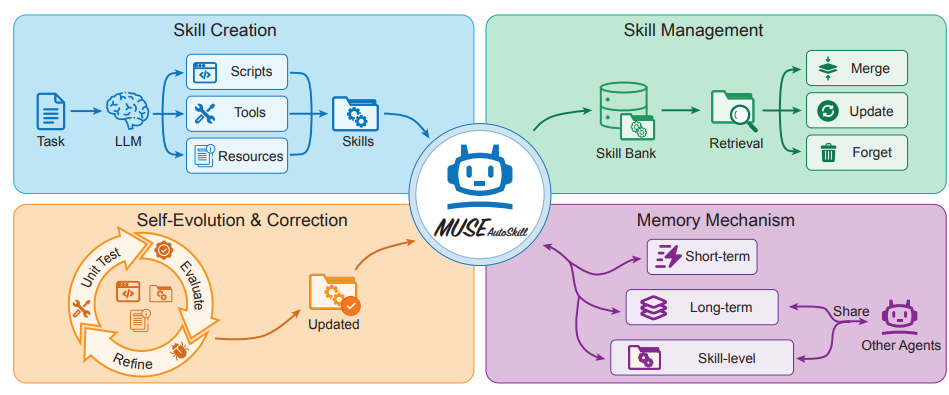
MUSE-Autoskill : Agents auto-évolutifs via la création, la mémorisation, la gestion et l’évaluation des compétences
Des équipes comme ByteDance ont proposé le framework d'agents intelligents MUSE-Autoskill, qui unifie la création, la mémorisation, la gestion, l'évaluation et l'optimisation des compétences au sein d'un cycle de vie complet. Ce framework s'affranchit des limitations des compétences statiques et isolées traditionnelles en introduisant une mémoire au niveau de la compétence permettant d'accumuler l'expérience acquise au fil des tâches. Des expériences menées sur SkillsBench fournissent des preuves préliminaires que les compétences gérées tout au long de leur cycle de vie peuvent améliorer le taux de réussite des tâches, l'efficacité d'exécution, la réutilisabilité et la transférabilité entre agents, soulignant ainsi l'importance de considérer les compétences comme des ressources à long terme, intégrant l'expérience et testables.
Document et interprétation détaillée :https://go.hyper.ai/mdgB2
8. Nemotron 3 Ultra
Titre de l'article :
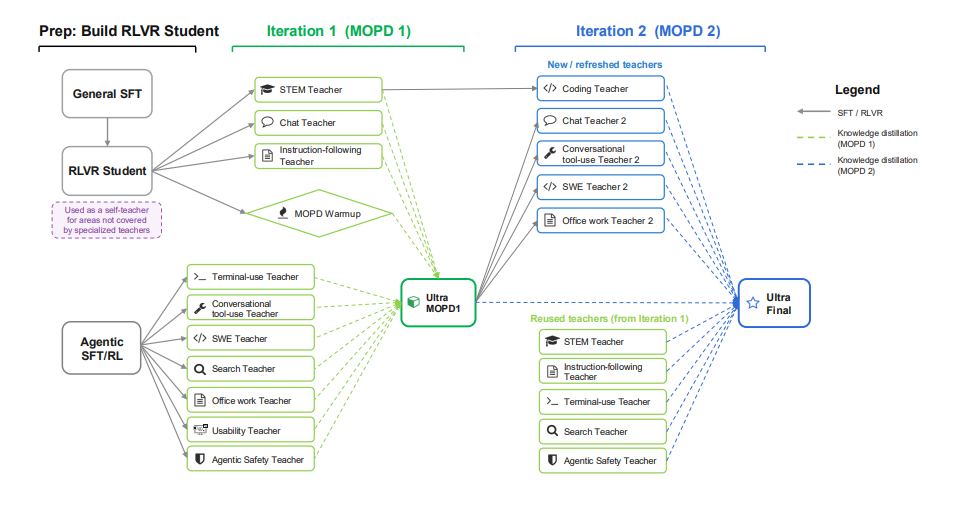
Nemotron 3 Ultra : Modèle hybride Mamba-Transformer ouvert et efficace, basé sur un mélange d’experts, pour le raisonnement agentiel
NVIDIA a lancé Nemotron 3 Ultra, un modèle de langage Mamba-Attention MoE doté de 550 milliards de paramètres et de 55 milliards de paramètres d'activation. Ce modèle est pré-entraîné sur 20 000 milliards de tokens, avec une longueur de contexte étendue à 1 million de tokens, puis post-entraîné à l'aide de SFT, RL et de la distillation de politiques en ligne multi-enseignants (MOPD). Grâce à des techniques telles que LatentMoE, la prédiction multi-tokens, NVFP4, RLVR, MOPD et le contrôle du budget d'inférence, Nemotron 3 Ultra atteint un débit d'inférence environ six fois supérieur à celui des modèles de langage publics existants, tout en conservant une précision élevée. Il est ainsi parfaitement adapté aux tâches d'agents autonomes de longue durée.
Document et interprétation détaillée :https://go.hyper.ai/lm6S1
9. Cosmos 3
Titre de l'article :
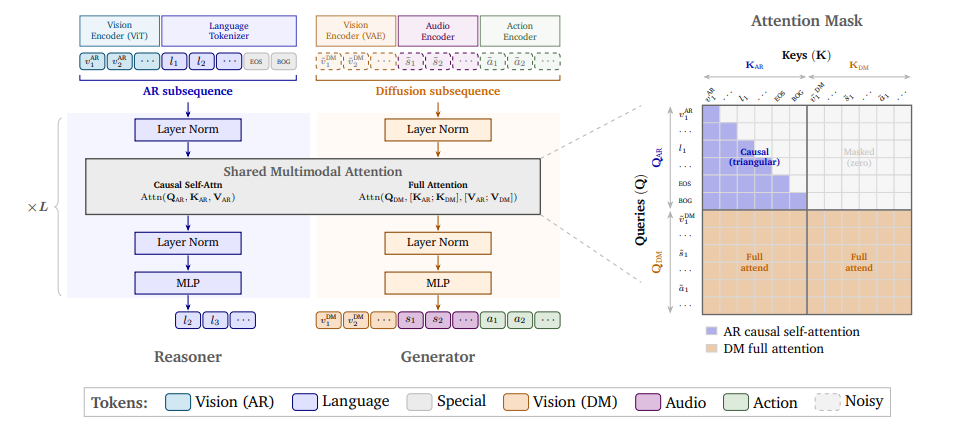
Cosmos 3 : Modèles du monde omnimodaux pour l’IA physique
NVIDIA a lancé Cosmos 3, une suite de modèles de monde multimodaux qui traitent et génèrent du langage, des images, de la vidéo, de l'audio et des séquences d'actions au sein d'une architecture Transformer hybride unifiée. Cosmos 3 prend en charge des configurations d'entrée/sortie très flexibles, intégrant des modèles de langage visuel, des générateurs vidéo, des simulateurs de monde et des modèles d'actions dans un cadre unique. Les évaluations montrent qu'il atteint des performances de pointe dans diverses tâches de compréhension et de génération, validant ainsi les modèles de monde multimodaux comme réseaux de base généraux pour les agents incarnés. Les modèles post-entraînés ont été classés parmi les meilleurs modèles open source de conversion texte-image/image-vidéo et parmi les meilleurs modèles de politiques.
Document et interprétation détaillée :https://go.hyper.ai/RoY2u
Voici l'intégralité du contenu de la recommandation d'article de cette semaine. Pour découvrir d'autres articles de recherche de pointe en IA, veuillez consulter la section « Derniers articles » du site officiel d'hyper.ai.
Nous invitons également les équipes de recherche à nous soumettre des résultats et des articles de haute qualité. Les personnes intéressées peuvent ajouter leur compte WeChat NeuroStar (identifiant WeChat : Hyperai01).
À la semaine prochaine !








