Command Palette
Search for a command to run...
Revue Hebdomadaire Des Publications Scientifiques | ProgramBench Permet À l'IA De Créer Des Logiciels À Partir De Zéro, Avec 9 Modèles Majeurs Ayant Échoué En Masse ; ExoActor Démontre De Fortes Capacités De Généralisation De Scènes Sans Nécessiter De Données Réelles Supplémentaires… Un Aperçu Rapide Des Publications Scientifiques De Pointe En IA De La Semaine

L'utilisation croissante des modèles de langage dans le développement logiciel à long terme rend les benchmarks existants insuffisants pour évaluer leurs performances en matière de conception d'architecture système, de partitionnement des modules et d'implémentation technique globale. Pour pallier ce problème, l'équipe SWE-Bench a proposé le benchmark ProgramBench : il fournit aux modèles uniquement le fichier exécutable et la documentation d'utilisation, les obligeant ainsi à réécrire le code et à reproduire le comportement du programme.
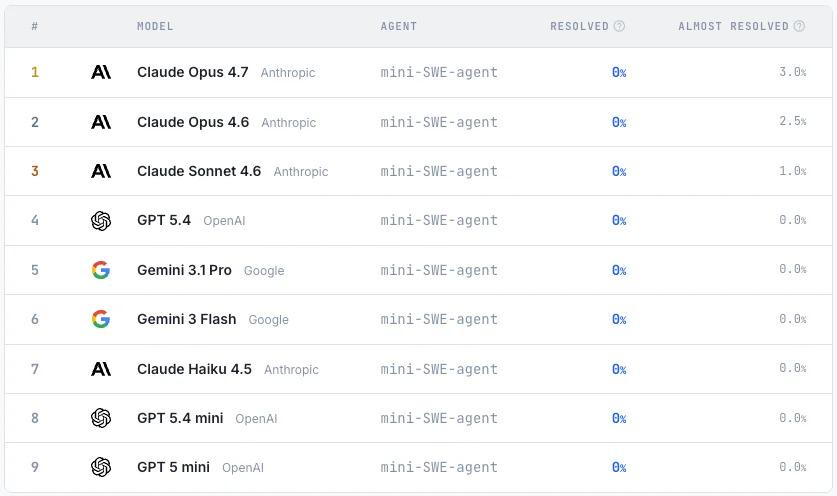
L'étude a construit 200 tâches couvrant divers types de logiciels, notamment des bases de données, des compilateurs et des outils en ligne de commande, et a évalué la cohérence entre le programme généré par le modèle et le programme original au moyen de tests comportementaux.Les résultats expérimentaux montrent que les modèles dominants actuels peinent encore à mener à bien des tâches complexes de reconstruction logicielle, et qu'aucun modèle ne réussit tous les tests.Même le Claude Opus 4.7, pourtant le plus performant, n'a atteint un taux de réussite élevé que sur quelques tâches, ce qui indique que les grands modèles de langage présentent encore des lacunes importantes en termes de capacités globales d'ingénierie logicielle.
Lien vers le document:https://go.hyper.ai/wExzR
Derniers articles sur l'IA:https://go.hyper.ai/hzChC
Pour aider un plus grand nombre d'utilisateurs à comprendre les derniers développements dans le domaine de l'intelligence artificielle dans le milieu universitaire,Le site web d'HyperAI (hyper.ai) propose désormais une section « Derniers articles », régulièrement mise à jour avec des articles de recherche de pointe en IA.Voici 8 articles populaires sur l'IA que nous vous recommandons. Jetons un coup d'œil rapide aux dernières avancées en IA cette semaine ⬇️
Recommandation de papier de cette semaine
1. ProgramBench
Titre de l'article :
ProgramBench : Les modèles de langage peuvent-ils reconstruire des programmes à partir de zéro ?
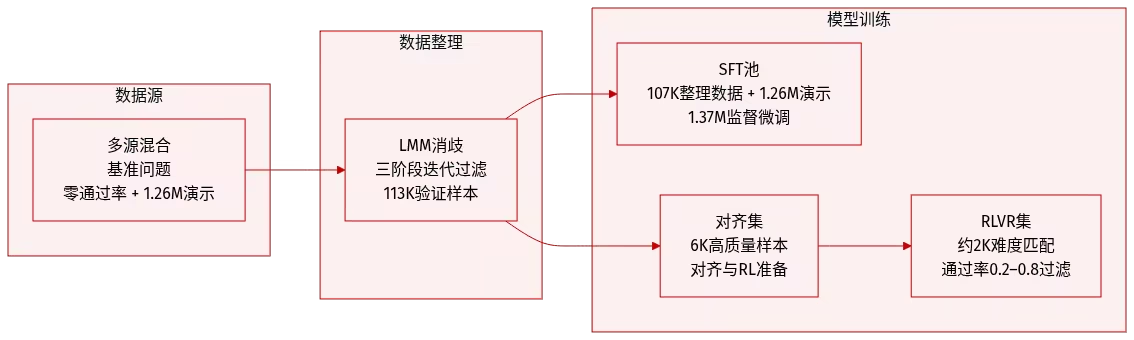
L'équipe de recherche a proposé ProgramBench pour évaluer la capacité des agents de génie logiciel à construire des projets logiciels complets à partir de zéro. Ce test d'évaluation exige de l'agent qu'il implémente un code source dont le comportement est cohérent avec un exécutable de référence, en se basant uniquement sur le programme et sa documentation, et qu'il effectue une évaluation de bout en bout par le biais de tests de robustesse pilotés par l'agent.
ProgramBench comprend 200 tâches couvrant divers types de logiciels, notamment les outils en ligne de commande, FFmpeg, SQLite et les interpréteurs PHP. Des expériences menées sur neuf modèles de langage montrent que les performances globales des modèles actuels sont limitées. Le meilleur modèle n'a réussi le test que de 951 TTP3T pour la tâche 31 TTP3T, et le code généré présente généralement une structure monolithique, contenue dans un seul fichier, ce qui diffère sensiblement des pratiques de développement logiciel traditionnelles.
Document et interprétation détaillée :https://go.hyper.ai/wExzR
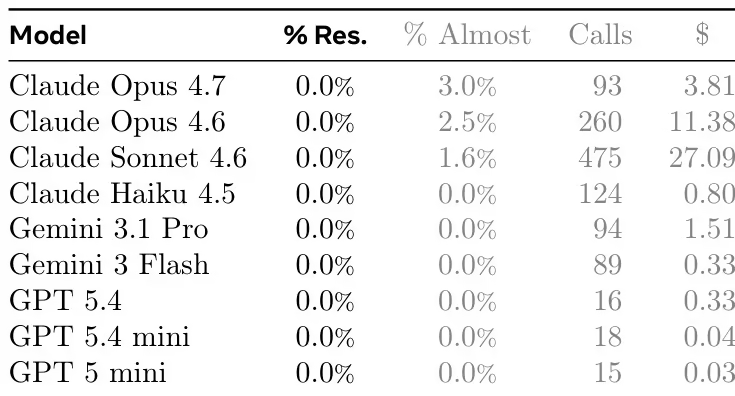
Composition et sources du jeu de données : Les auteurs ont compilé 200 instances de tâches issues de dépôts GitHub open source. Les sources ont été sélectionnées parmi des projets produisant des exécutables autonomes, principalement en Rust, Go ou C/C++. La collection comprend diverses catégories fonctionnelles telles que le traitement de texte, les utilitaires système et les interpréteurs de langages.

2. Consultation externe unitaire
Titre de l'article :
Uni-OPD : Unifier la distillation sur la politique avec une recette à double perspective
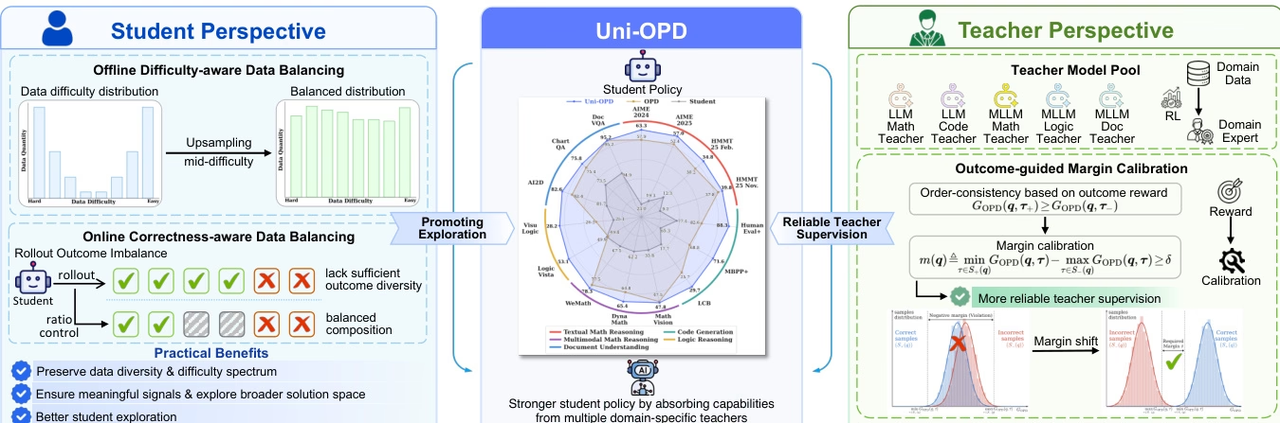
Uni-OPD est un cadre de distillation en ligne unifié pour les modèles d'apprentissage automatique (LLM et MLLM), conçu pour améliorer le transfert des connaissances multi-experts aux modèles étudiants. Les recherches indiquent que les méthodes OPD existantes sont principalement limitées par deux problèmes : une exploration insuffisante des états riches en informations et des signaux de supervision des enseignants peu fiables.
Pour remédier à cela, Uni-OPD emploie une stratégie d'optimisation à double perspective : du côté de l'apprenant, elle introduit une stratégie d'équilibrage des données afin d'enrichir l'exploration des états riches en informations ; du côté de l'enseignant, elle propose un mécanisme de calibration marginale guidé par les résultats pour rétablir la cohérence séquentielle entre les trajectoires correctes et incorrectes, améliorant ainsi la fiabilité de la supervision. Des expériences menées dans cinq domaines et sur 16 bancs d'essai, couvrant divers contextes tels que l'enseignement par un seul enseignant, par plusieurs enseignants, par une approche allant du renforcement positif au renforcement négatif et par distillation intermodale, ont validé l'efficacité de la méthode.
Document et interprétation détaillée :https://go.hyper.ai/8k4du
3. Incertitude fidèle
Titre de l'article :
Les hallucinations minent la confiance ; la métacognition est une voie à suivre.
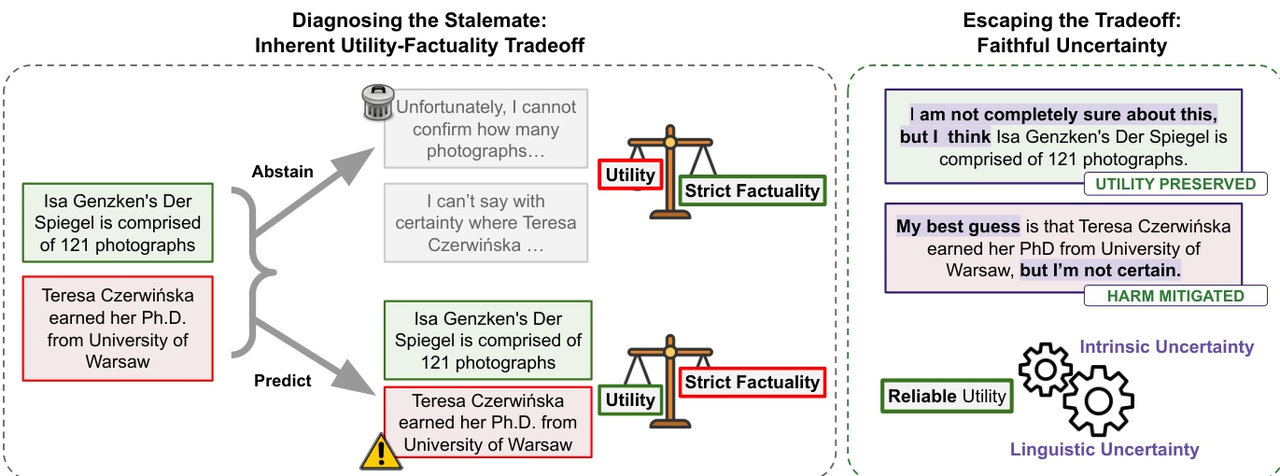
L'équipe de recherche souligne que, malgré l'amélioration constante de la fiabilité factuelle des grands modèles de langage, le problème des illusions demeure fréquent, notamment dans les scénarios de questions-réponses factuelles où les outils externes font défaut. L'étude suggère que les progrès actuels sont davantage dus à l'élargissement du champ de connaissances qu'à la capacité réelle du modèle à distinguer le connu de l'inconnu. Par conséquent, l'élimination complète des illusions pourrait constituer un compromis naturel avec la praticité du modèle.
Partant de ce constat, l’étude propose le concept d’« incertitude fidèle », soulignant que les modèles doivent exprimer fidèlement leur propre incertitude, garantissant ainsi la cohérence entre l’incertitude linguistique et la cognition interne. Cette capacité métacognitive contribue non seulement à améliorer la crédibilité des modèles, mais fournit également un mécanisme de contrôle plus fiable pour la recherche et la prise de décision dans les systèmes d’agents intelligents.
Document et interprétation détaillée :https://go.hyper.ai/G77rj
Composition et source de l'ensemble de données : Les auteurs ont construit un ensemble de données synthétiques contenant 25 000 échantillons pour reproduire les caractéristiques de distribution de confiance empiriques enregistrées par Nakkiran et al. (2025).

4. PRISME
Titre de l'article :
Au-delà de SFT-à-RL : Pré-alignement via une distillation de politiques en boîte noire pour l’apprentissage par renforcement multimodal
Pour résoudre le problème du décalage de distribution affectant l'apprentissage par renforcement ultérieur lors du réglage fin de grands modèles multimodaux, l'équipe de recherche a proposé un processus en trois étapes appelé PRISM. Cette méthode insère une étape d'alignement de distribution basée sur une distillation intra-politique entre le réglage fin supervisé et l'apprentissage par renforcement, et utilise un discriminateur expert hybride (MoE) pour fournir des signaux de correction de découplage.
En utilisant 113 000 ensembles de données de démonstration Gemini de haute qualité, PRISM a considérablement amélioré les performances de l'apprentissage par renforcement en aval dans l'expérience Qwen3-VL, augmentant la précision des modèles 4B et 8B de 4,4 et 6,0 points, respectivement.
Document et interprétation détaillée :https://go.hyper.ai/5fsD3
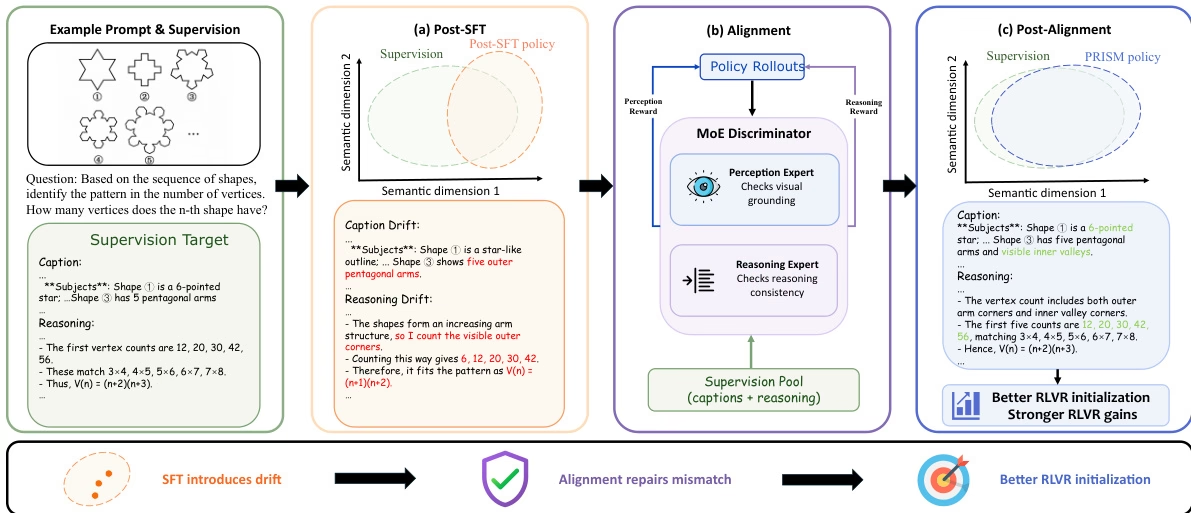
Composition et sources des données : Cet article présente un corpus de raisonnement multimodal constitué de données issues de tests de référence publics couvrant le raisonnement mathématique, la compréhension et l’interprétation de graphes scientifiques, ainsi que le raisonnement spatial. Afin d’en étendre la couverture et d’en améliorer la stabilité, cet ensemble soigneusement sélectionné est complété par 1,26 million de données de démonstration publiques générées par la même série de modèles Gemini.
5. ExoActor
Titre de l'article :
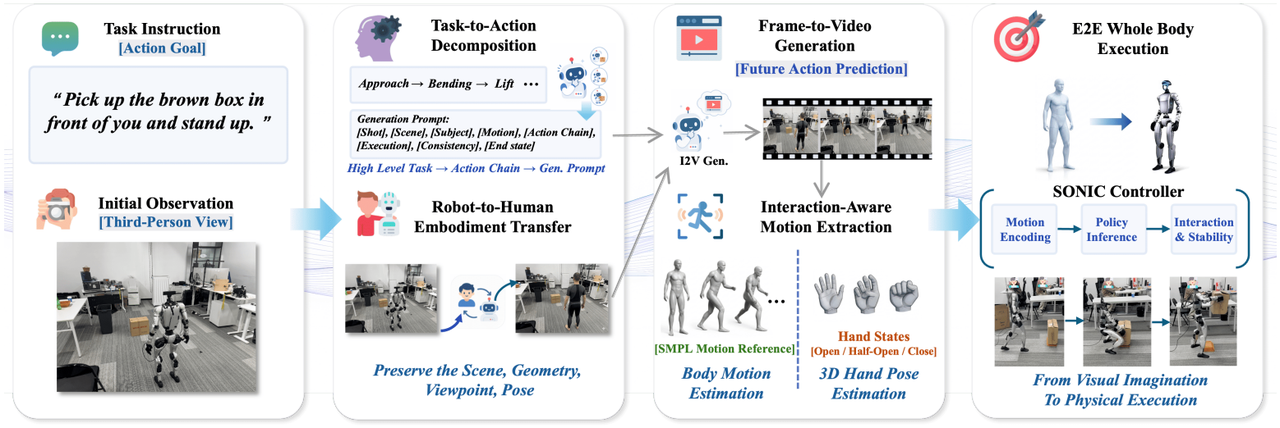
ExoActor : Génération vidéo exocentrique en tant que contrôle humanoïde interactif généralisable
L'équipe de recherche a proposé le cadre ExoActor, qui utilise la génération vidéo exocentrique comme interface unifiée pour encoder implicitement les interactions collaboratives entre le robot, son environnement et les objets. Ce cadre convertit également la vidéo d'exécution synthétisée en comportements robotiques humanoïdes exécutables grâce à l'estimation des mouvements humains et à un contrôleur de mouvement générique, démontrant ainsi sa capacité à s'adapter à de nouveaux scénarios sans nécessiter de collecte de données supplémentaires sur site.
Document et interprétation détaillée :https://go.hyper.ai/OE5IH
6. Édition-R1
Titre de l'article :
Exploiter l'apprentissage par renforcement basé sur un vérificateur dans l'édition d'images
L'équipe de recherche a proposé Edit-R1, un cadre d'apprentissage par renforcement pour la retouche d'images. Contrairement aux modèles de récompense traditionnels qui ne fournissent qu'un score global, Edit-R1 décompose les instructions de retouche en plusieurs principes et vérifie les résultats élément par élément grâce à un raisonnement par chaîne de pensée, générant ainsi des signaux de récompense plus précis et interprétables. La recherche combine également un ajustement supervisé avec des stratégies d'apprentissage par renforcement GCPO afin d'améliorer la capacité du modèle de récompense à modéliser les préférences humaines, et utilise GCPO pour entraîner les modèles de retouche en aval.
Les résultats expérimentaux montrent qu'Edit-RRM surpasse les puissants VLM tels que Seed-1.5-VL et Seed-1.6-VL dans l'évaluation de l'édition d'images, et améliore considérablement les performances des modèles d'édition tels que FLUX.1-kontext, tout en démontrant des avantages significatifs de l'expansion des paramètres.
Document et interprétation détaillée :https://go.hyper.ai/MtBLB
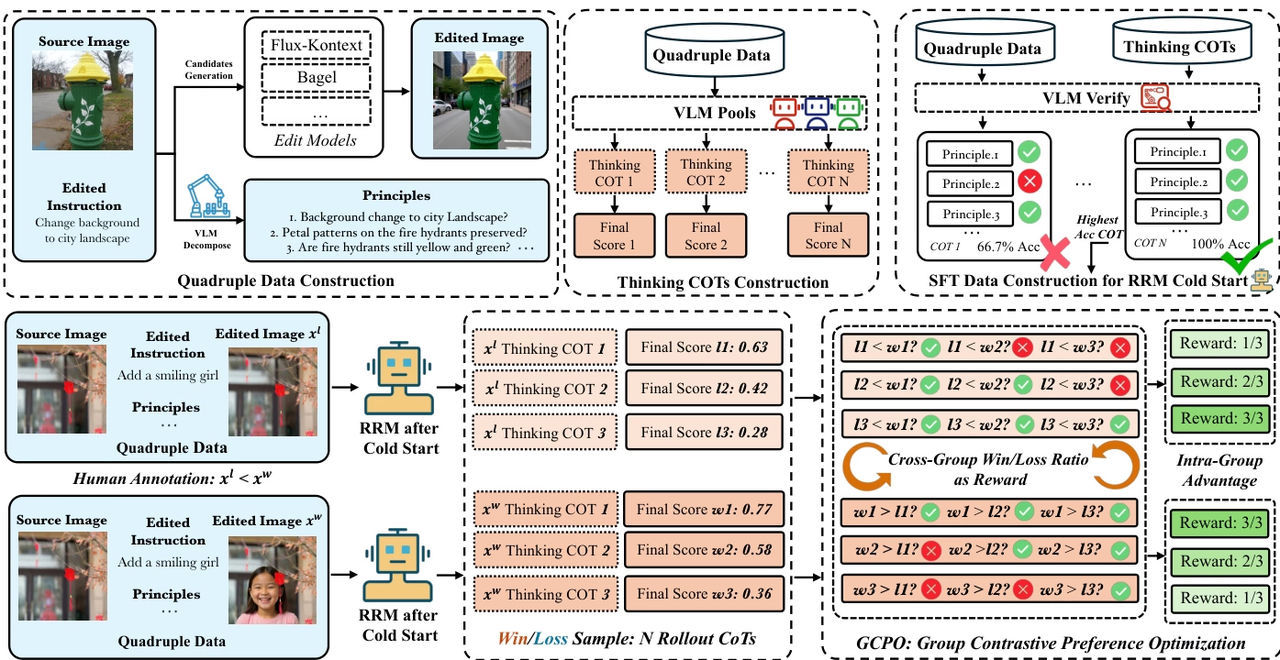
Composition et source du jeu de données : L’équipe de recherche a constitué un jeu de données supervisé pour un modèle de récompense d’inférence à froid en compilant 200 000 échantillons issus de jeux de données de référence pour l’édition d’images disponibles publiquement. Cet ensemble initial a été étendu à environ 2 millions de quadruplets de données grâce à la génération de plusieurs modèles et à une validation systématique.

7. Distillation de politiques coévolutives
Titre de l'article :
Distillation de politiques coévolutives
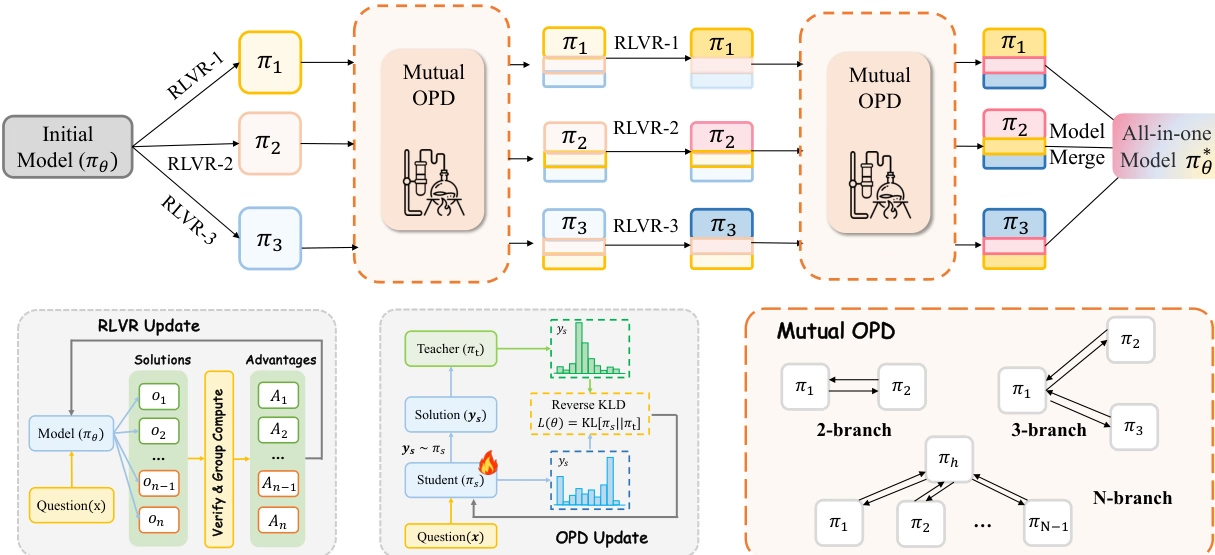
L'équipe de recherche a mené une analyse unifiée des deux principaux paradigmes post-formation, RLVR et OPD, et a souligné qu'ils présentent des limites différentes dans le processus d'intégration de multiples compétences d'experts : le RLVR hybride est sujet à des « coûts de divergence des compétences », tandis que le processus traditionnel consistant à « former d'abord les experts puis à mettre en œuvre l'OPD » évite les conflits de compétences, mais en raison des grandes différences dans les modèles comportementaux entre les enseignants et les étudiants, il est difficile d'hériter pleinement des compétences d'experts.
Pour remédier à ce problème, cette étude propose une stratégie de coévolution, CoPD (Traitement Co-Évolutionnaire), qui introduit simultanément un traitement bidirectionnel dérivé optique (OPD) et l'entraînement continu des experts au RLVR (RLVR basé sur une référence). Ceci permet aux experts de s'entraider et de coévoluer, améliorant ainsi la cohérence comportementale tout en préservant la complémentarité de leurs compétences. Les résultats expérimentaux montrent que CoPD intègre efficacement les capacités de raisonnement sur texte, image et vidéo, surpassant significativement des méthodes de référence performantes telles que le RLVR hybride et MOPD, et même les modèles d'experts du domaine sur certaines tâches.
Document et interprétation détaillée :https://go.hyper.ai/cCyrG

8. ClawGym
Titre de l'article :
ClawGym : un cadre évolutif pour la création d’agents à griffes efficaces
L'équipe de recherche a proposé ClawGym, un cadre évolutif pour l'ensemble du cycle de vie du développement d'agents personnels de type Claw, afin de prendre en charge des flux de travail complexes et à plusieurs étapes impliquant des fichiers locaux, des appels d'outils et des états d'espace de travail persistants.
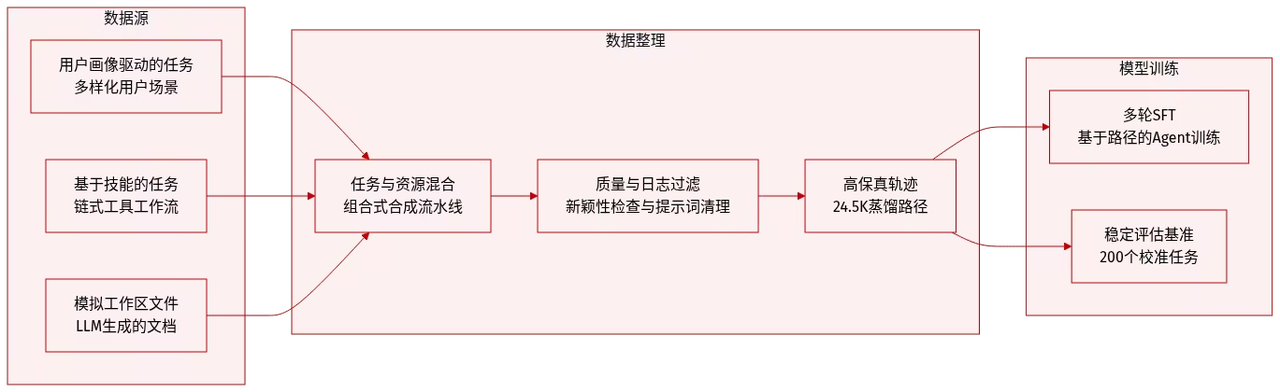
Le cadre de travail comprend le jeu de données synthétiques ClawGym-SynData, couvrant 13 500 tâches sélectionnées, et combine intention humaine, exécution de tâches, espace de travail simulé et mécanismes de vérification hybrides. Les agents ClawGym sont entraînés à partir de trajectoires de déploiement « boîte noire » et leurs capacités sont améliorées grâce à un pipeline d'apprentissage par renforcement léger. De plus, un ensemble de référence, ClawGym-Bench, sélectionné automatiquement, examiné et calibré conjointement par des humains et un modèle d'apprentissage léger (LLM), est constitué pour une évaluation fiable.
Document et interprétation détaillée :https://go.hyper.ai/yZwa5
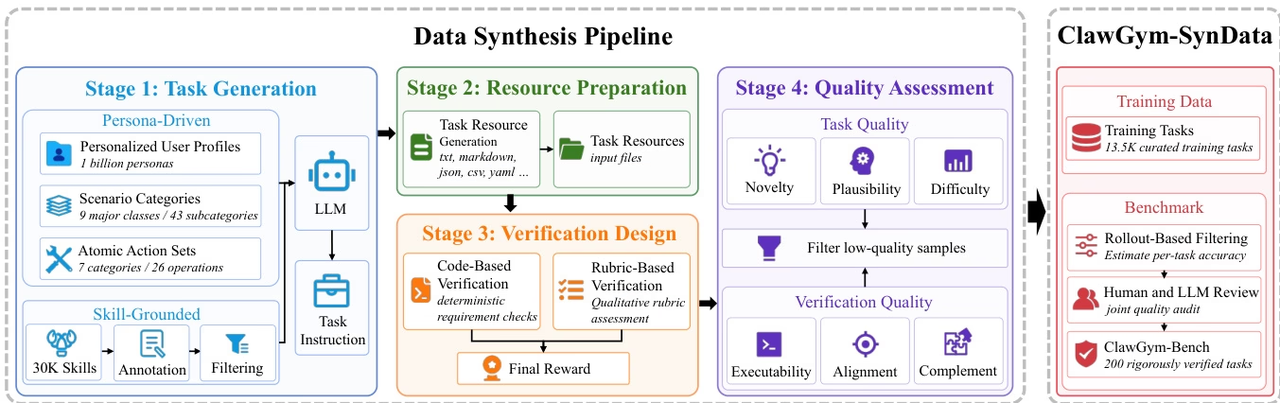
Source des données : L'équipe de recherche a généré des données d'entraînement à l'aide du cadre ClawGym-SynData, qui combine une synthèse descendante axée sur la personnalité pour divers scénarios d'utilisateurs avec une synthèse ascendante basée sur la technologie de connexion des capacités d'OpenClaw dans un flux de travail réel.
Voici l'intégralité du contenu de la recommandation d'article de cette semaine. Pour découvrir d'autres articles de recherche de pointe en IA, veuillez consulter la section « Derniers articles » du site officiel d'hyper.ai.
Nous invitons également les équipes de recherche à nous soumettre des résultats et des articles de haute qualité. Les personnes intéressées peuvent ajouter leur compte WeChat NeuroStar (identifiant WeChat : Hyperai01).
À la semaine prochaine !








