Command Palette
Search for a command to run...
Tutoriel En Ligne | Un Ordinateur Portable De 16 Go Atteint Des Performances De Près De 26 Milliards De MoE : Gemma 4 12B, Basé Sur Une Architecture Innovante Pour Le Traitement Unifié Des Modalités texte/image/son

Bien que la concurrence autour des grands modèles reste axée sur la taille des paramètres, Google DeepMind a une fois de plus démontré que les améliorations de performances ne dépendent pas nécessairement uniquement de la taille des modèles.
Récemment, Google DeepMind a officiellement lancé Gemma 4 12B, le dernier-né de la famille Gemma 4. Ce modèle multimodal unifié, doté de seulement 12 milliards de paramètres, affiche des performances proches de celles d'un modèle expert hybride (MoE) de 26 milliards de paramètres dans de nombreux tests de référence. Les données officielles montrent que les performances de Gemma 4 12B dans des tâches telles que l'inférence, la génération de code et la compréhension multimodale sont comparables à celles de Gemma 4 26B.Dans le même temps, il atteint le niveau de pointe (SOTA) parmi les modèles open-source actuels du même niveau dans certaines tâches de compréhension visuelle et d'agent.Plus important encore, ce modèle ne nécessite que 16 Go de mémoire vidéo ou de mémoire unifiée pour fonctionner nativement sur les ordinateurs portables grand public, ce qui représente un équilibre rare entre performances et coût de déploiement.
Premier modèle de taille moyenne de la série Gemma à prendre en charge nativement l'entrée audio, la principale innovation du Gemma 4 12B ne réside pas dans la taille de ses paramètres, mais dans son architecture novatrice. Pendant longtemps, les modèles multimodaux ont généralement adopté une approche « encodeur + modèle de langage » : les images sont traitées par un encodeur visuel, l'audio par un encodeur vocal, et les résultats sont ensuite transmis à un modèle de langage complexe pour l'inférence. Bien que cette architecture soit éprouvée,Cependant, cela engendre des coûts de calcul supplémentaires, une utilisation accrue de la mémoire et une latence d'inférence plus importante.
Pour résoudre ce problème, Google DeepMind a conçu une architecture entièrement nouvelle sans encodeur pour Gemma 4 12B. Les images sont directement intégrées à l'architecture LLM après être passées par un module d'intégration léger, tandis que l'audio est directement projeté dans le même espace de représentation que les jetons de texte.Le même transformateur décodeur traite uniformément les modalités texte, image et son.La déclaration officielle indique que cette conception réduit considérablement la latence d'inférence multimodale tout en réduisant la complexité du système et l'empreinte mémoire.
Outre son architecture multimodale unifiée, la Gemma 4 12B prend également en charge une fenêtre de contexte ultra-longue de 256 Ko, un mode d'inférence profonde Thinking commutable, l'appel de fonctions natif et les fonctionnalités de flux de travail d'agents. Dans les benchmarks standard,Ses performances globales sont proches de celles du modèle Gemma 4 26B MoE, qui est plus de deux fois plus grand.Le coût d'exploitation est inférieur à la moitié de celui de cette dernière solution. Pour les développeurs souhaitant déployer localement des fonctionnalités d'IA avancées, cela signifie qu'ils peuvent bénéficier d'une expérience d'inférence et d'agent comparable à celle des modèles multimodaux haut de gamme actuels, sans avoir recours à des GPU onéreux.
Actuellement, la section tutoriels du site officiel d'HyperAI (hyper.ai) a lancé « Déploiement en un clic de Gemma 4 12B-it », qui abaisse le seuil de déploiement sous la forme d'un notebook et permet aux développeurs de vérifier plus facilement et rapidement les modèles.
Exécutez en ligne :https://go.hyper.ai/1Jrdl
Plus de tutoriels en ligne :
Essai de démonstration
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels », ou cliquez sur « Voir plus de tutoriels », sélectionnez « Déploiement en un clic de Gemma 4 12B-it », puis cliquez sur « Exécuter ce tutoriel ».
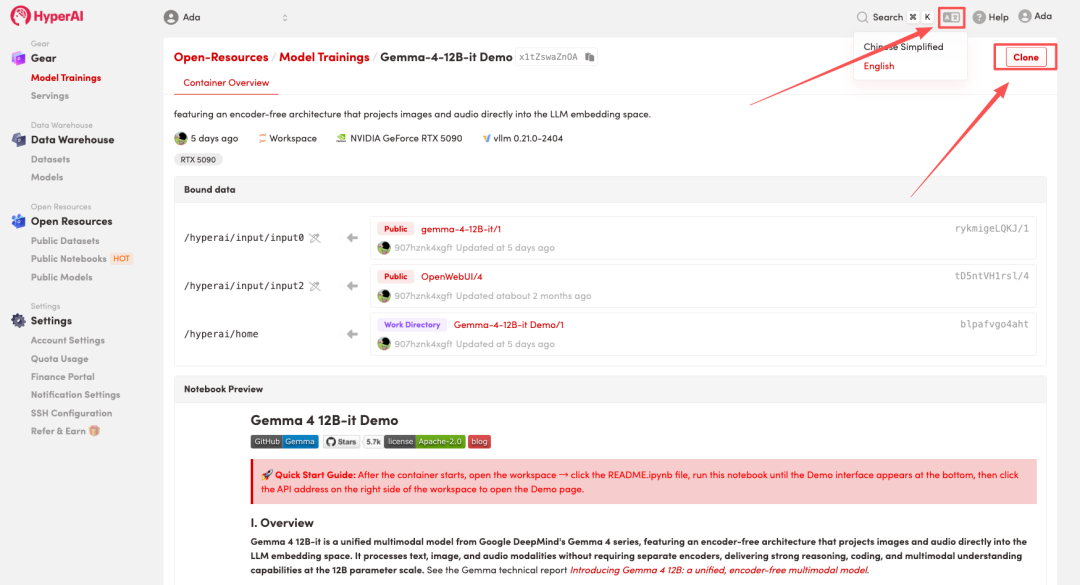
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
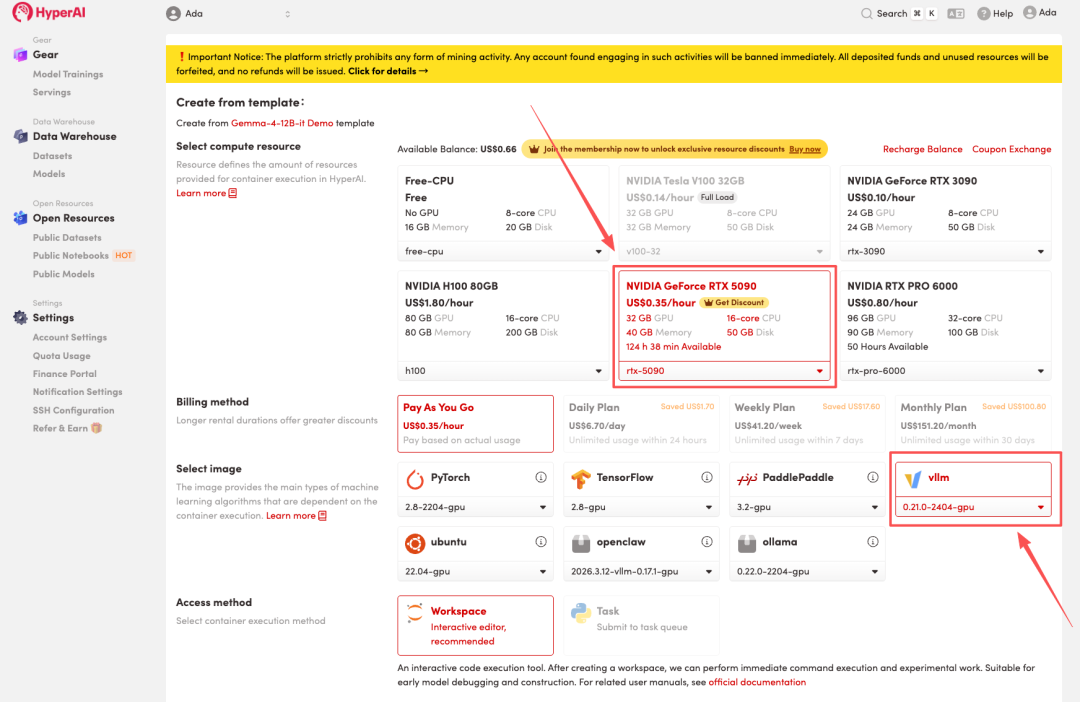
3. Sélectionnez les images « NVIDIA RTX 5090 » et « vLLM », puis cliquez sur « Continuer l'exécution de la tâche ».
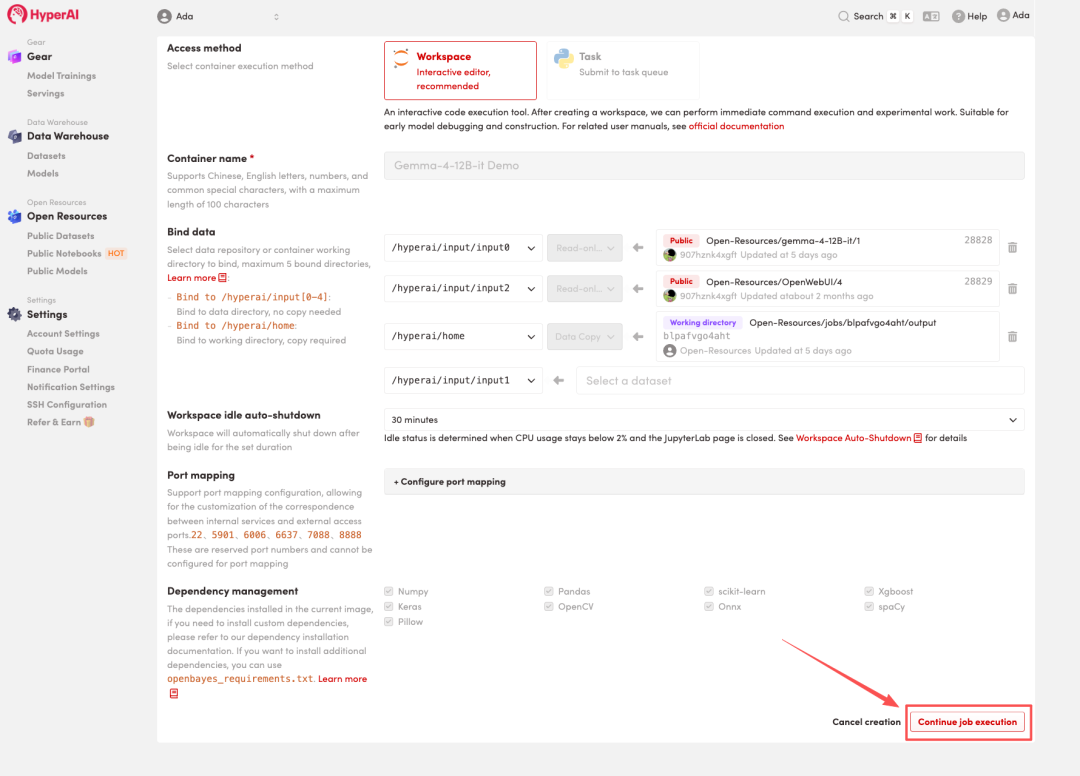
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
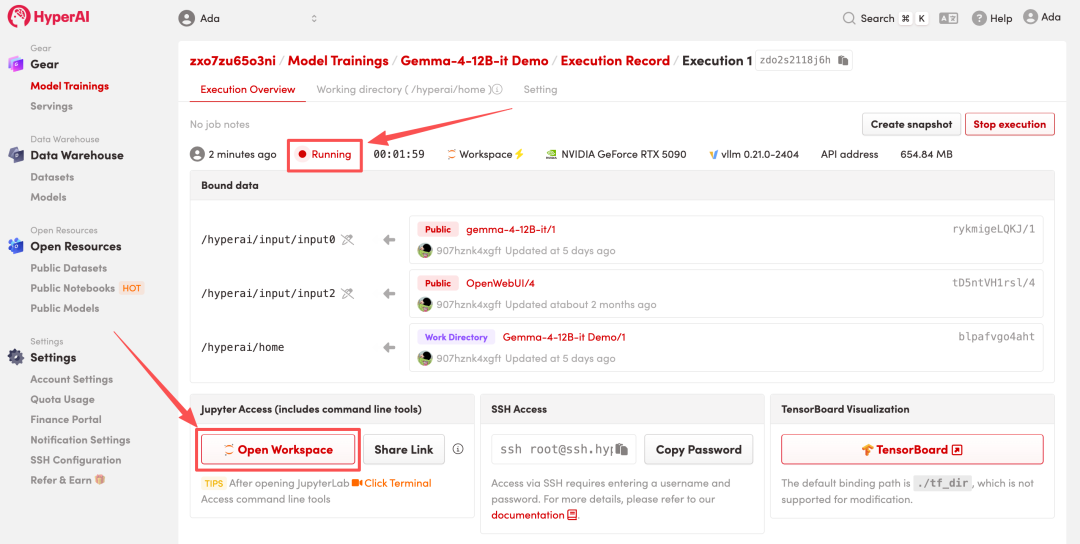
Affichage des effets
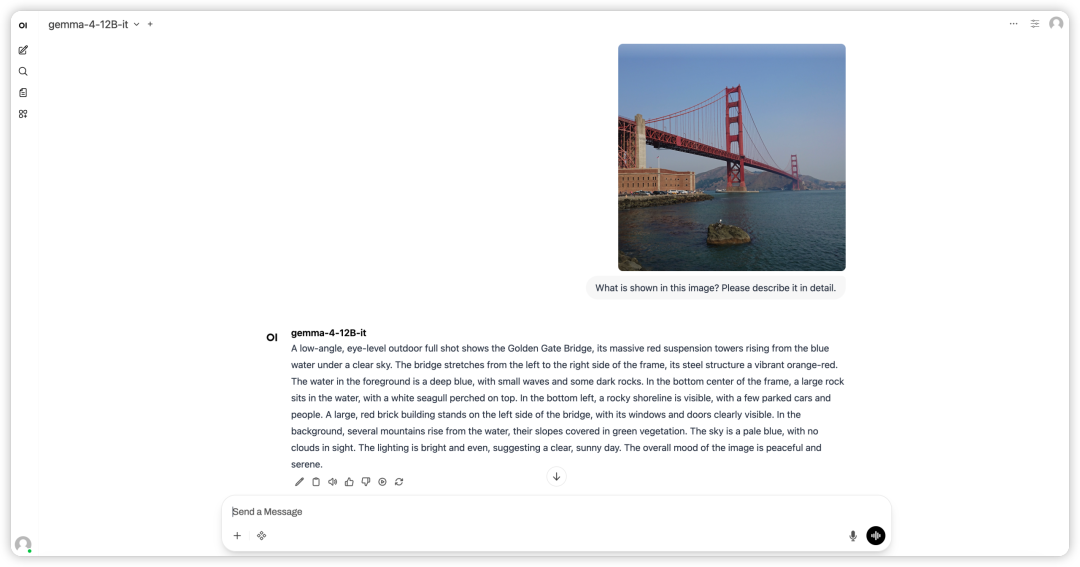
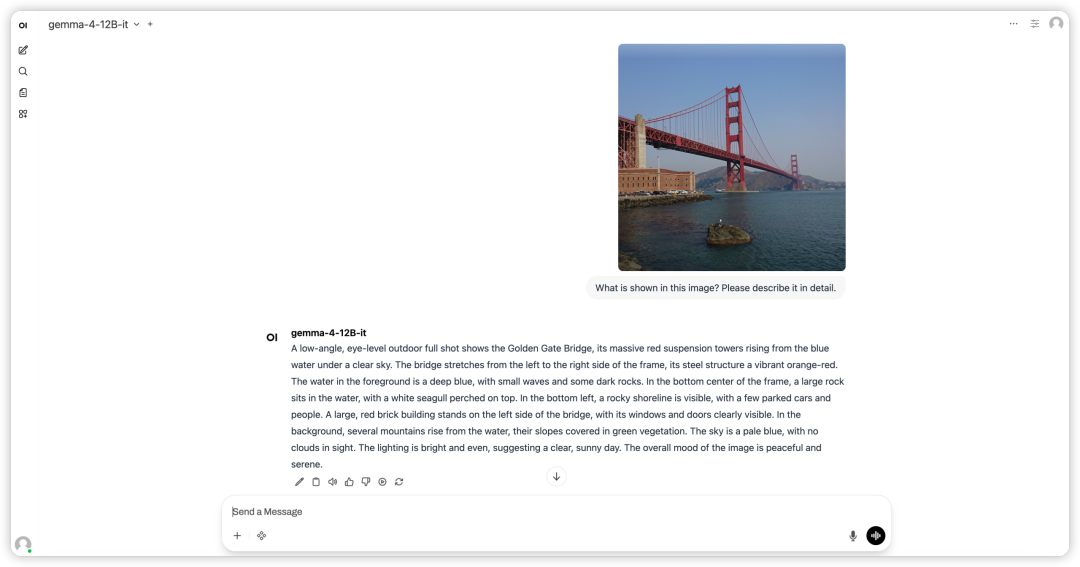
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
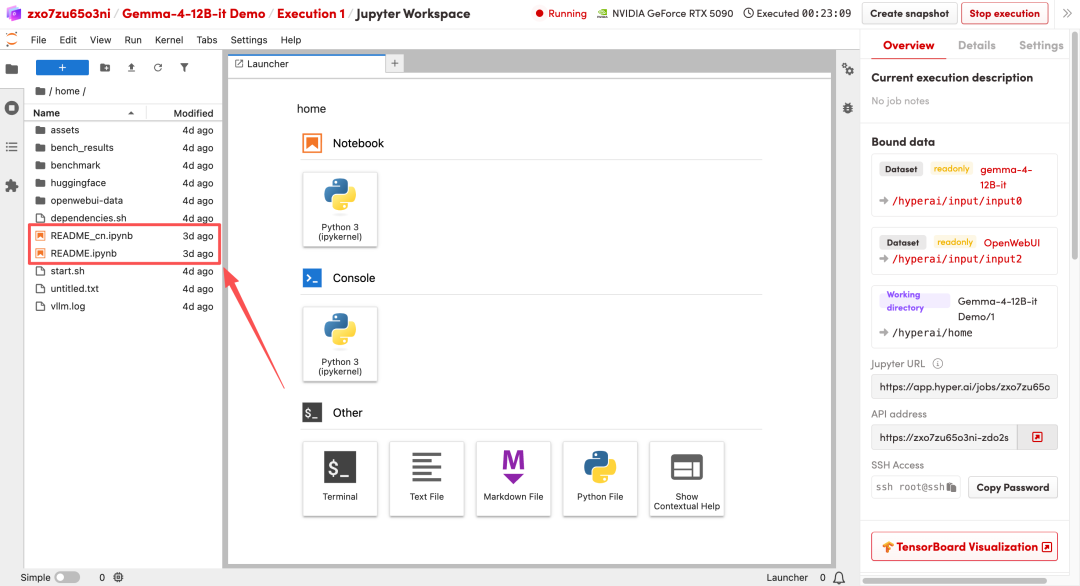
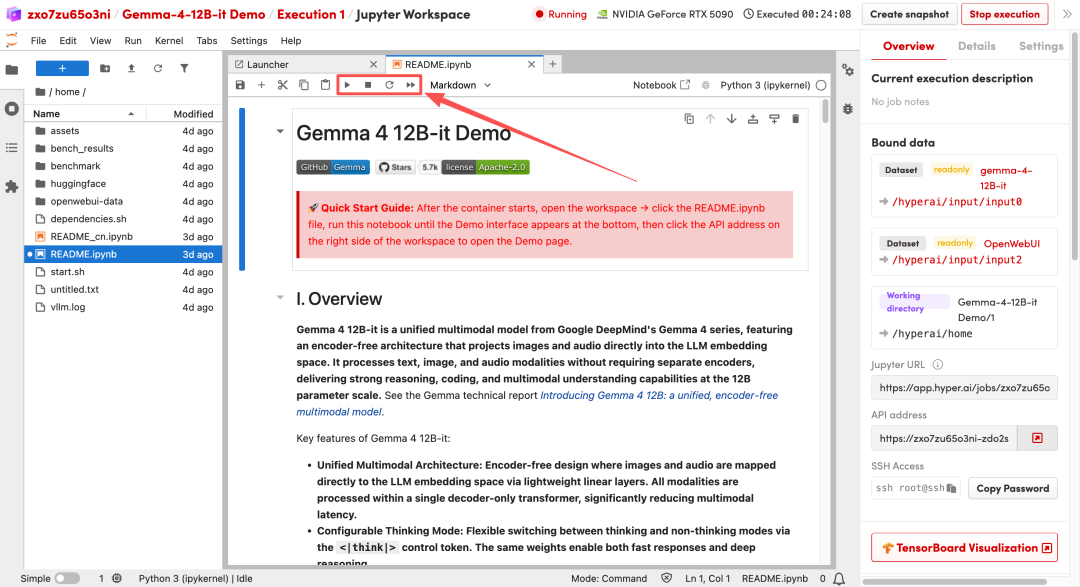
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour ouvrir l'interface de démonstration.