Command Palette
Search for a command to run...
Tutoriel En Ligne | Vitesse De Génération jusqu'à 4 Fois Plus Rapide : DiffusionGemma Peut Générer Simultanément Des Blocs De Texte Entiers, Avec Une Optimisation Continue Basée Sur Un Débruitage Parallèle multi-itérations.

Le 11 juin, Google a officiellement publié en open source DiffusionGemma, un modèle de génération de texte basé sur la technologie de diffusion discrète. Ce modèle tire parti des capacités d'analyse par paramètre de pointe de la série Gemma 4 et des recherches de pointe menées sur la diffusion Gemini, intégrant une nouvelle tête de diffusion pour optimiser la vitesse de génération. Contrairement aux modèles traditionnels de grande taille qui produisent le texte jeton par jeton, il peut générer des blocs de texte entiers simultanément et optimiser en continu les résultats grâce à plusieurs cycles de débruitage parallèles.Cela permet d'augmenter la vitesse de génération jusqu'à quatre fois.
Les données officielles montrent que DiffusionGemma peut atteindre une vitesse de génération de plus de 1100 jetons/s sur un seul GPU NVIDIA H100 et de plus de 700 jetons/s sur une GeForce RTX 5090, dépassant de loin les modèles autorégressifs du même niveau.
Du point de vue de l'architecture,DiffusionGemma utilise une conception hybride experte (MoE) au niveau des paramètres 26B.Le nombre total de paramètres est d'environ 25,2 milliards, mais seuls 3,8 milliards sont activés lors de l'inférence, ce qui réduit considérablement la charge de calcul tout en préservant d'excellentes performances d'inférence. Le modèle repose sur une structure encodeur-décodeur et intègre un mécanisme d'attention bidirectionnel, lui permettant de traiter 256 jetons simultanément en parallèle. Il prend également en charge les tâches qui dépendent fortement du contexte global, telles que l'édition de texte en temps réel, la complétion de code et la génération de structures mathématiques.
De plus, DiffusionGemma prend en charge des contextes longs allant jusqu'à 256 000 jetons, une entrée de graphes et de texte multimodale et des modes d'inférence activés par <|think|>, offrant aux développeurs de nouvelles options technologiques pour explorer des applications d'IA de nouvelle génération à haute efficacité.
Bien que Google souligne toujours que la version standard de Gemma 4 est plus adaptée aux environnements de production en termes de qualité de génération, les capacités de génération de texte basées sur la diffusion démontrées par DiffusionGemma pourraient ouvrir une nouvelle voie remarquable pour le développement de grands modèles de langage.
Pour permettre aux développeurs de découvrir DiffusionGemma avec un minimum d'efforts, HyperAI a rapidement réagi après la mise à disposition du modèle en open source et a maintenant lancé un notebook facile à déployer, qui peut vérifier les puissantes capacités du modèle en utilisant uniquement une carte graphique NVIDIA RTX Pro 6000.
Exécutez en ligne :https://go.hyper.ai/879dB
Plus de tutoriels en ligne :
Essai de démonstration
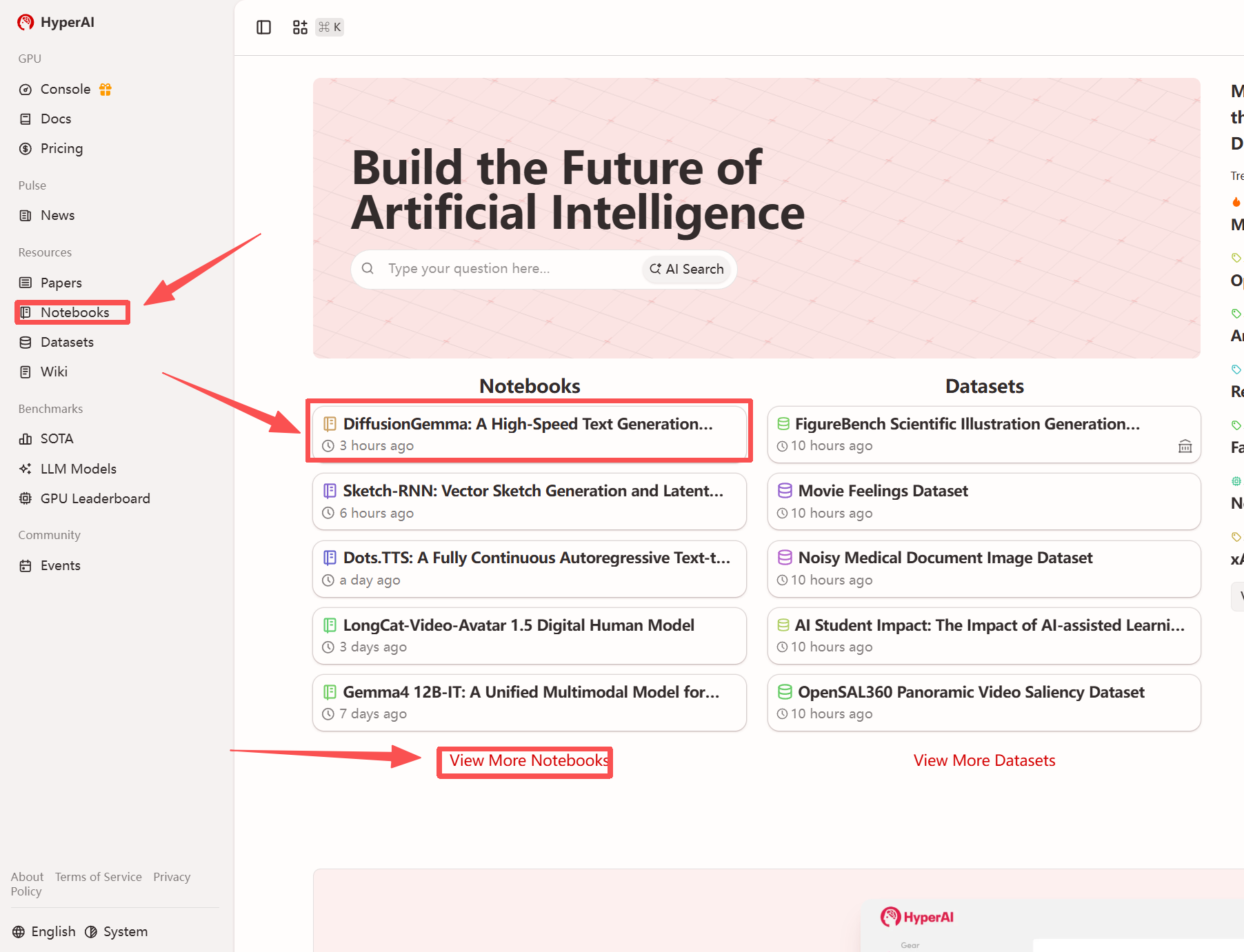
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels » ou cliquez sur « Voir plus de tutoriels », sélectionnez « DiffusionGemma : Modèle de génération de texte à haute vitesse basé sur la diffusion discrète », puis cliquez sur « Exécuter ce tutoriel ».
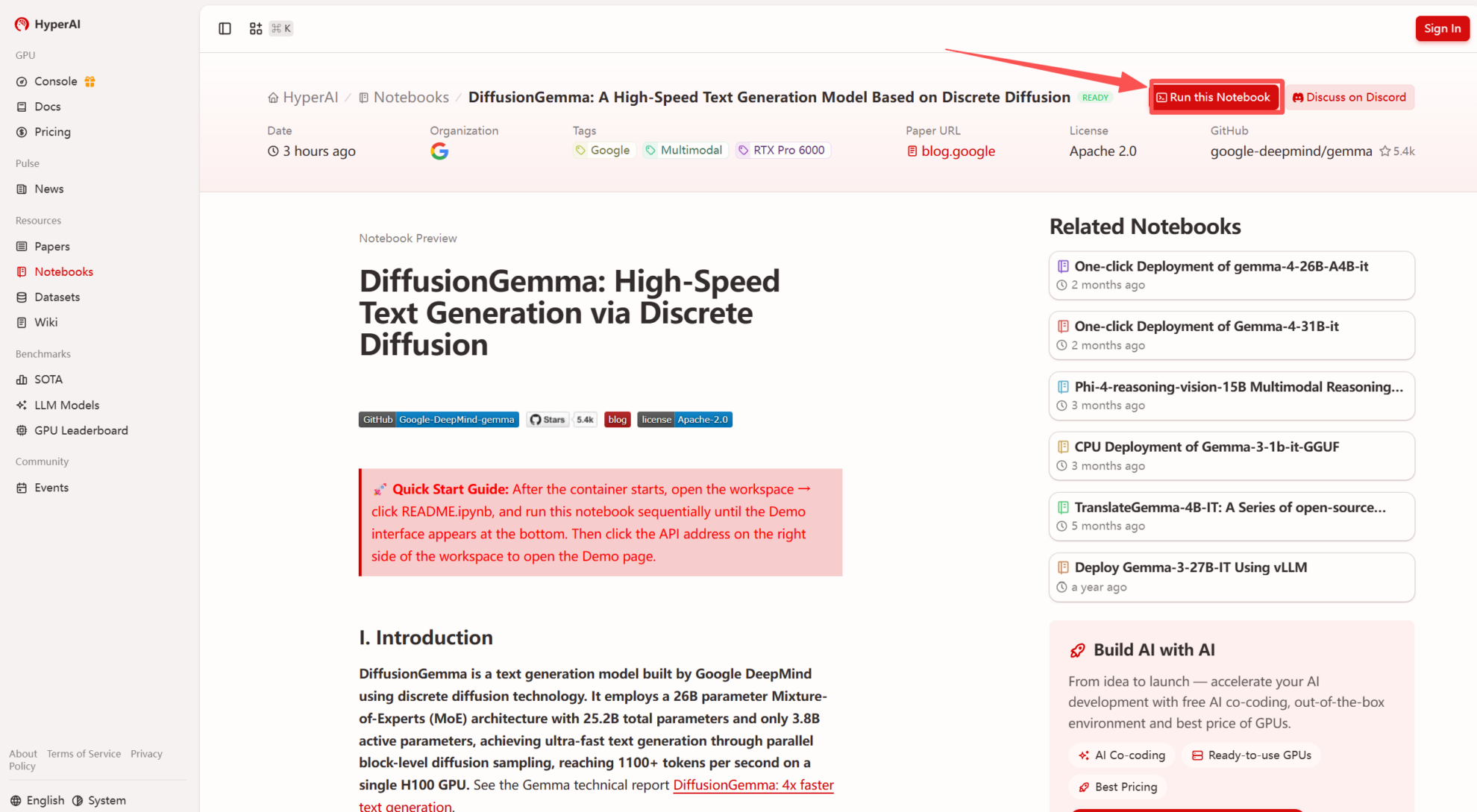
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
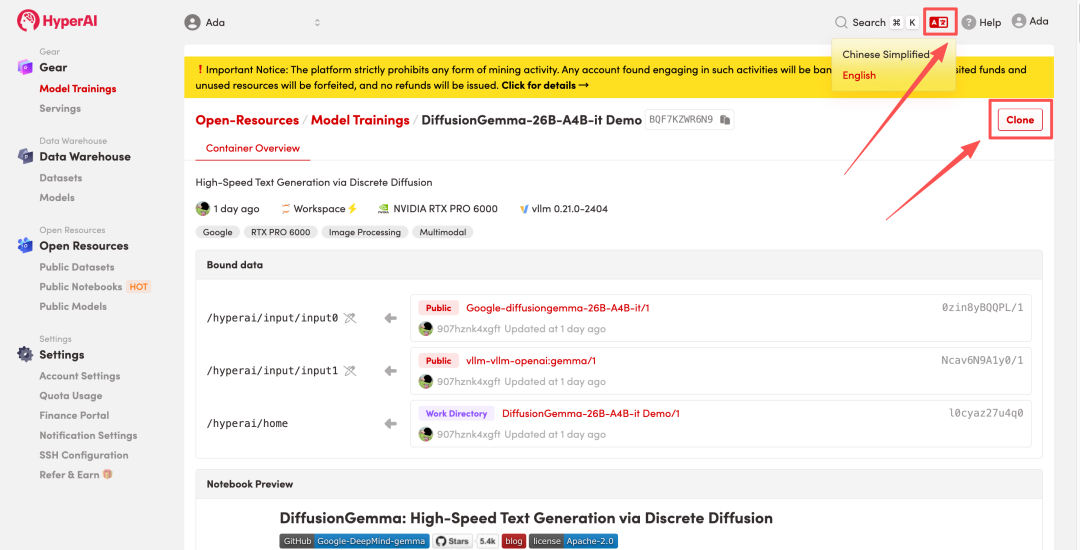
3. Sélectionnez les images « NVIDIA RTX Pro 6000 » et « vLLM », puis cliquez sur « Continuer l'exécution de la tâche ».
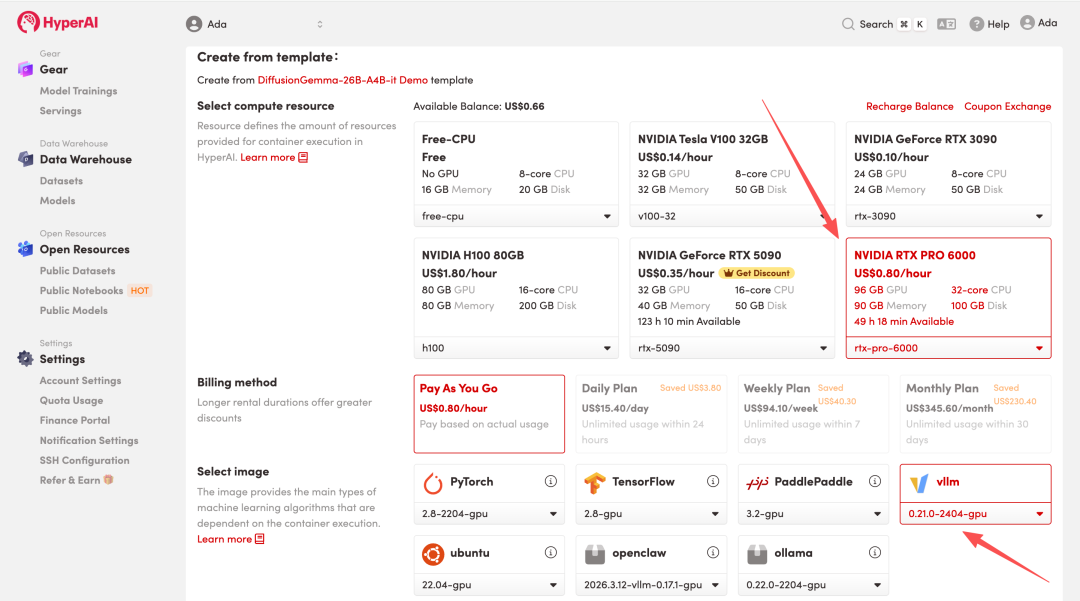
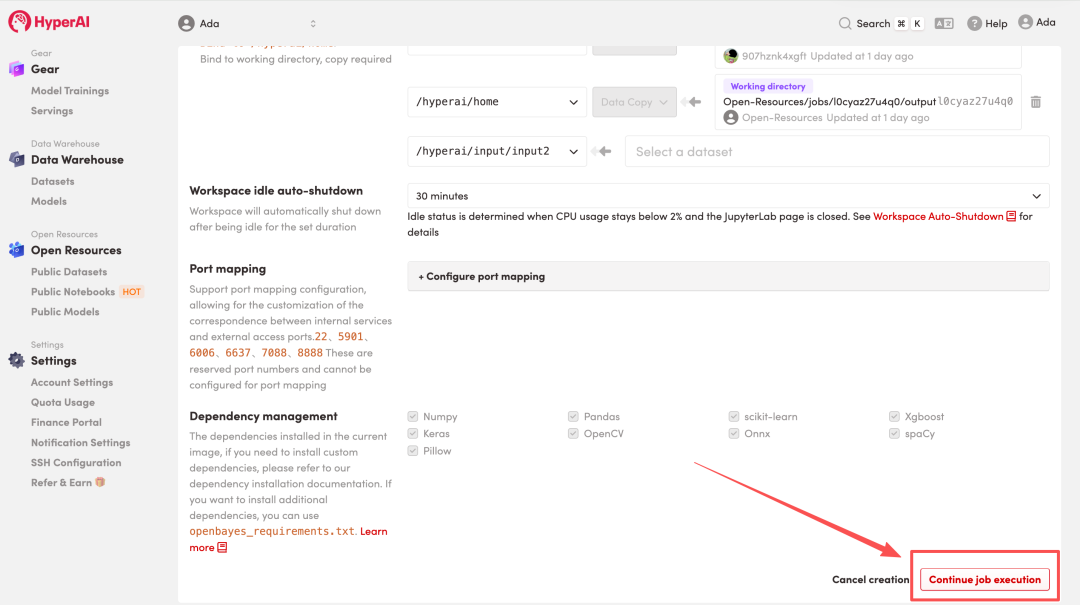
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
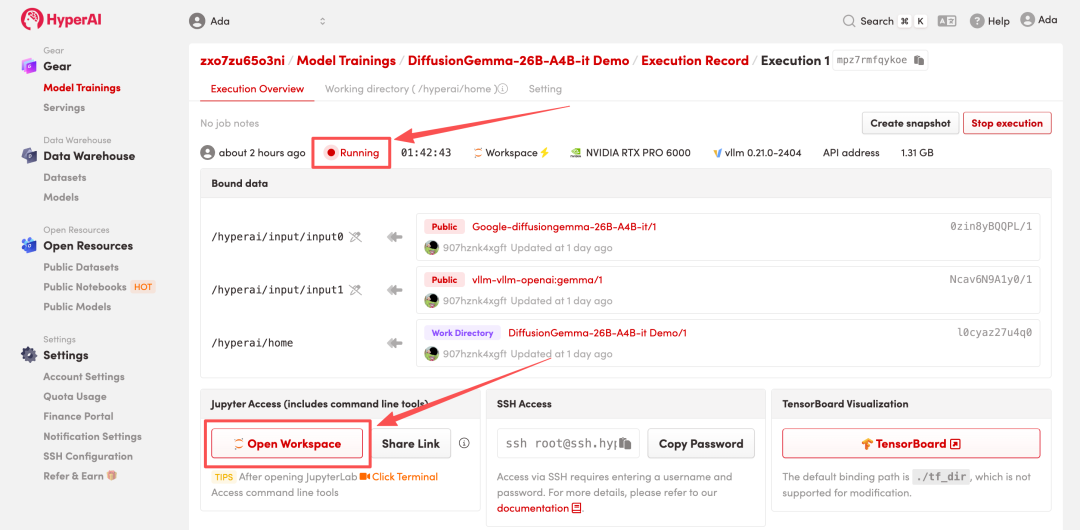
Affichage des effets
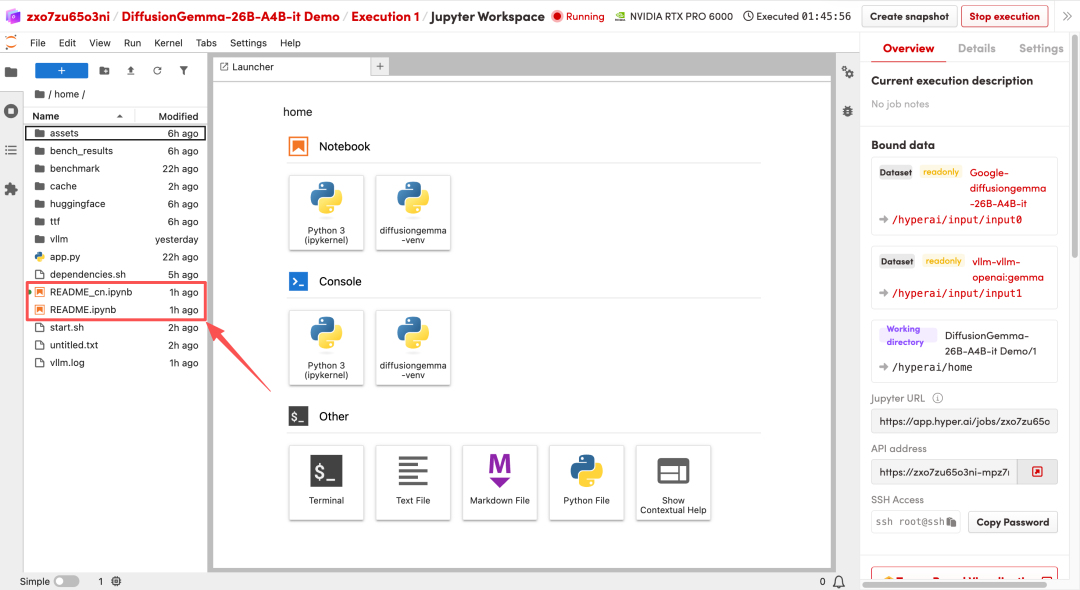
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
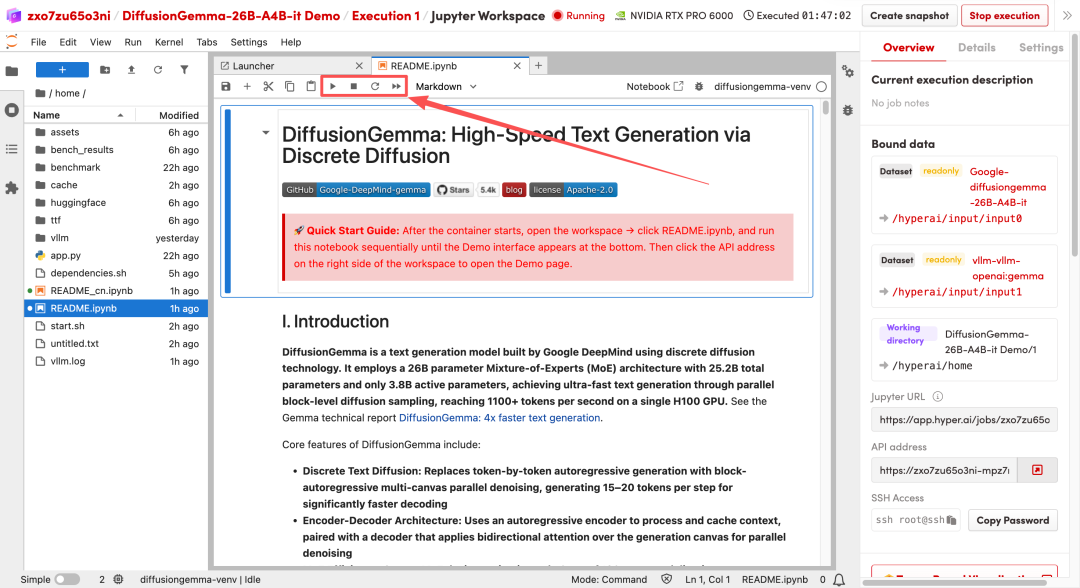
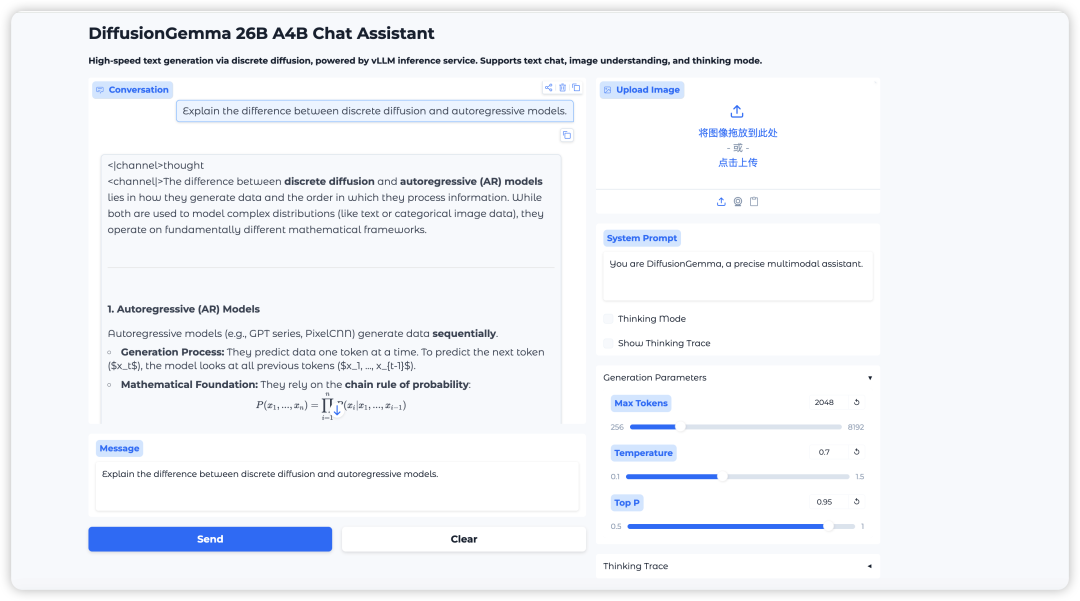
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour ouvrir l'interface de démonstration.