Command Palette
Search for a command to run...
Tutoriel En Ligne | NVIDIA Open Source LocateAnything, Un Modèle 3B Qui Permet Le Pointage De Cibles d'images Et De Vidéos, La Détection d'objets À Vocabulaire Ouvert, La Localisation De Cibles, La Localisation De Texte OCR Et d'autres fonctions.

À mesure que les modèles de langage visuel (MLV) évoluent vers les agents, l'interaction multimodale et les tâches du monde réel, la « compréhension des images » n'est plus l'objectif final ; il s'agit désormais de « localiser précisément la cible ». Ceci s'applique à la détection d'objets à vocabulaire ouvert, au fonctionnement des interfaces d'agents GUI, à la compréhension de documents et à la perception de l'environnement dans les systèmes de robotique et de conduite autonome.Tous ces facteurs imposent des exigences de plus en plus élevées aux capacités d'ancrage visuel.
Cependant, les modèles de langage visuels dominants actuels adoptent généralement un schéma de « génération de jetons de coordonnées » pour les tâches de localisation. Ce schéma consiste à diviser un cadre de délimitation bidimensionnel en plusieurs jetons de coordonnées unidimensionnels, puis à les générer et à les décoder un par un. Cette approche peine non seulement à maintenir la cohérence de la géométrie interne du cadre de délimitation, mais aussi…De plus, le mécanisme de génération séquentielle strict limite la vitesse de raisonnement.Lorsqu'un modèle doit traiter simultanément un grand nombre de cibles, il est souvent difficile d'équilibrer l'efficacité et la précision de la localisation.
En réponse à ce goulot d'étranglement persistant,NVIDIA a récemment rendu open source un nouveau membre de la série Eagle VLM : LocateAnything-3B.Il s'agit d'un modèle de localisation visuelle du langage comportant 3 milliards de paramètres, prenant en charge diverses tâches telles que la détection d'objets à vocabulaire ouvert, la localisation d'expressions de pointeur, la localisation de texte OCR, la localisation d'éléments d'interface graphique et le pointage de cibles dans les images et les vidéos, dans le but de construire un cadre unifié de localisation et de détection visuelles.
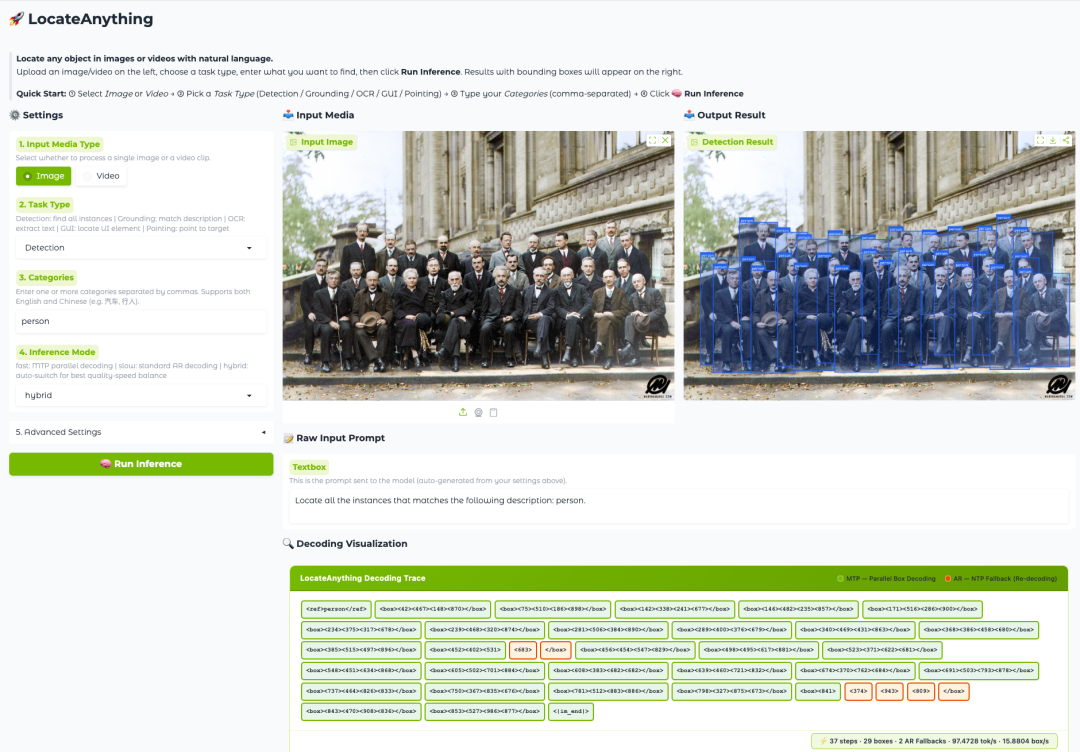
L'innovation majeure de LocateAnything-3B réside dans un nouveau mécanisme appelé décodage par boîtes parallèles (PBD). Contrairement aux méthodes traditionnelles qui génèrent les jetons de coordonnées un par un,PBD peut prédire simultanément et en parallèle des éléments géométriques tels que des boîtes englobantes et des points clés, comme une structure complète.Cette conception préserve non seulement la cohérence géométrique à l'intérieur du cadre de délimitation, mais améliore également considérablement le débit de décodage, permettant au modèle d'atteindre une vitesse d'inférence plus rapide tout en conservant des capacités de localisation de haute précision.
Au-delà de l'innovation architecturale, NVIDIA a également conçu un système d'entraînement à grande échelle autour de ce modèle. L'équipe de recherche a développé un moteur de données évolutif et lancé le jeu de données LocateAnything-Data, qui contient plus de 138 millions d'exemples d'entraînement. Ce jeu de données couvre de nombreux domaines tels que les scènes naturelles, la robotique, la conduite autonome, l'interaction avec les interfaces graphiques, la compréhension de documents et la reconnaissance optique de caractères (OCR), améliorant ainsi considérablement la capacité de généralisation du modèle dans des scénarios complexes.
Les résultats expérimentaux montrent que LocateAnything offre une meilleure qualité de localisation et une vitesse de décodage accrue dans de nombreux tests de localisation visuelle, dépassant ainsi le compromis traditionnel entre vitesse et précision des modèles de localisation visuelle unifiés. Pour les agents d'interface graphique, les systèmes d'annotation automatique et les agents multimodaux de nouvelle génération, en plein développement, cette capacité de compréhension spatiale efficace et précise devient une infrastructure essentielle.
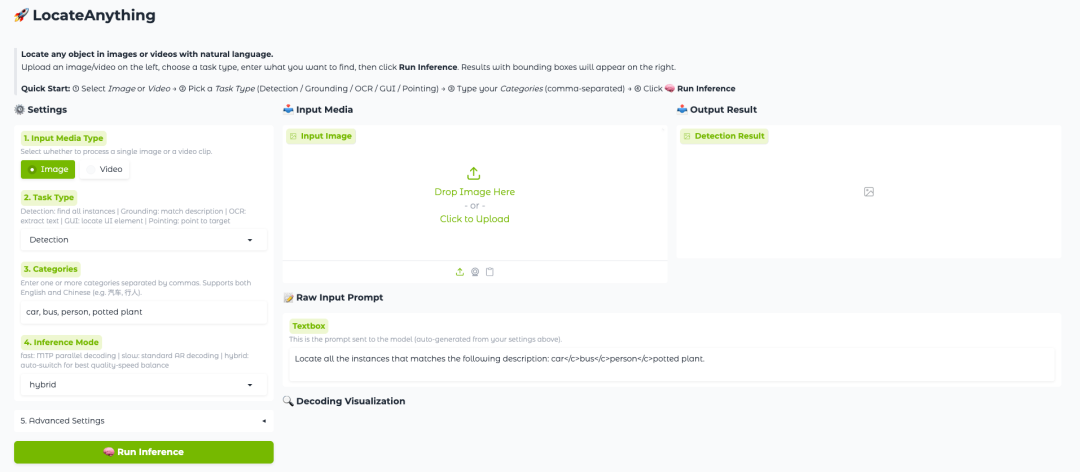
Actuellement, la section tutoriels du site officiel d'HyperAI (hyper.ai) a lancé « LocateAnything-3B : un modèle de localisation visuelle du langage rapide et de haute qualité », qui abaisse le seuil de déploiement sous la forme d'un notebook.
Exécutez en ligne :https://go.hyper.ai/4l9jB
Plus de tutoriels en ligne :
Bienvenue sur notre site web officiel pour plus d'informations :
Essai de démonstration
1. Après avoir accédé à la page d'accueil d'hyper.ai, sélectionnez la page « Tutoriels » ou cliquez sur « Voir plus de tutoriels », sélectionnez « LocateAnything-3B : Modèle de localisation visuelle du langage rapide et de haute qualité », puis cliquez sur « Exécuter ce tutoriel ».
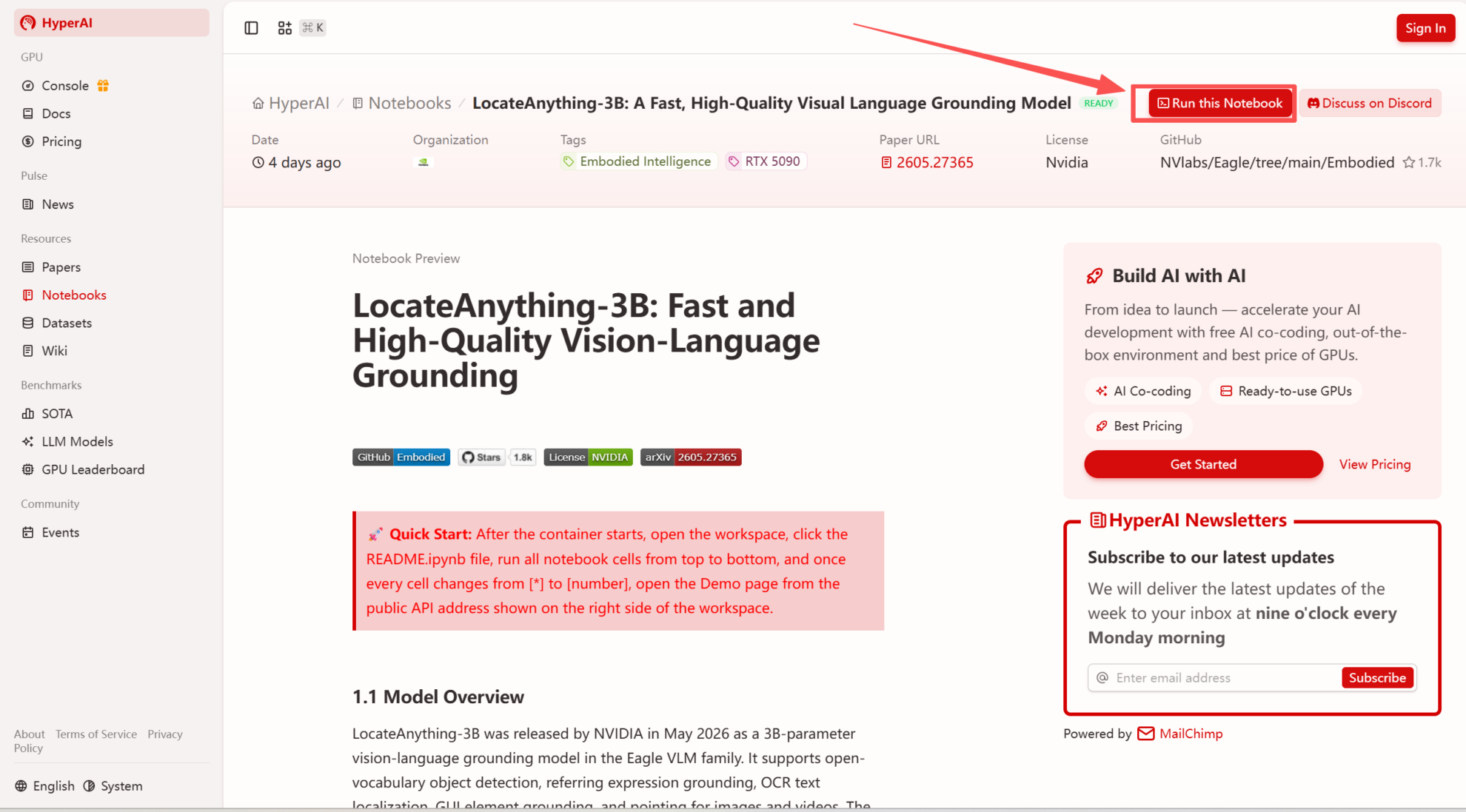
2. Une fois la page redirigée, cliquez sur « Cloner » en haut à droite pour cloner le tutoriel dans votre propre conteneur.
Remarque : Vous pouvez changer de langue en haut à droite de la page. Actuellement, le chinois et l’anglais sont disponibles. Ce tutoriel présente les étapes en anglais.
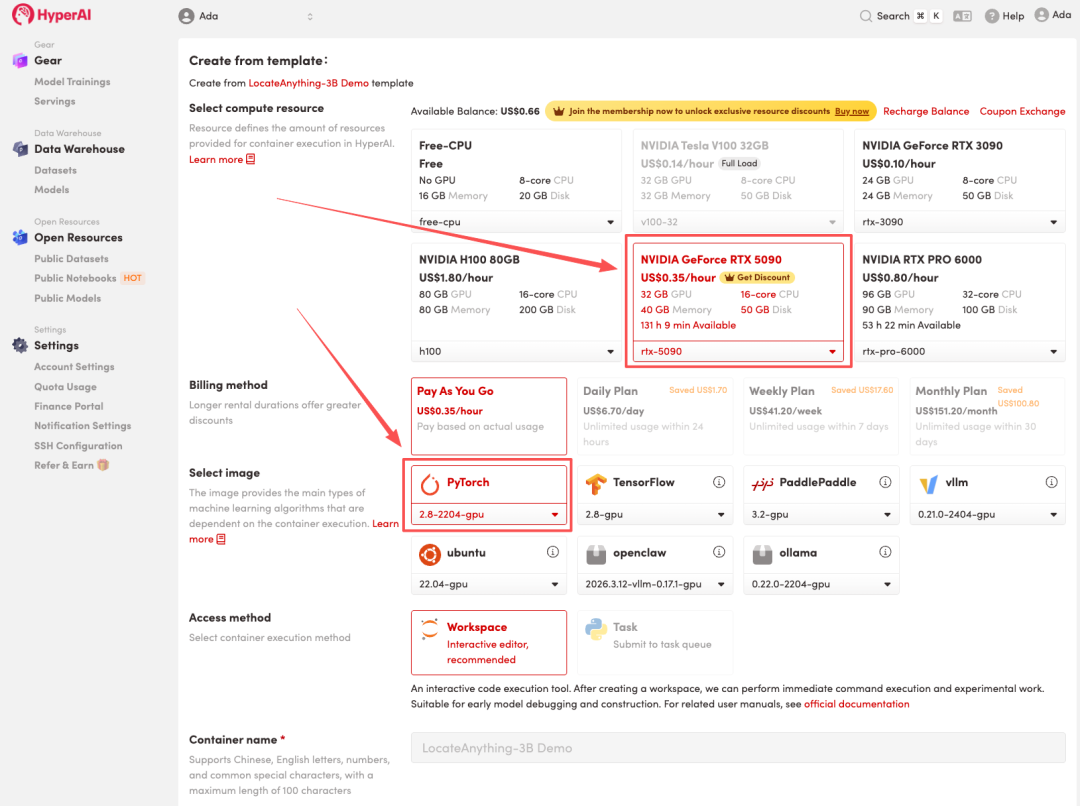
3. Sélectionnez les images « NVIDIA RTX 5090 » et « PyTorch », puis cliquez sur « Continuer l'exécution de la tâche ».
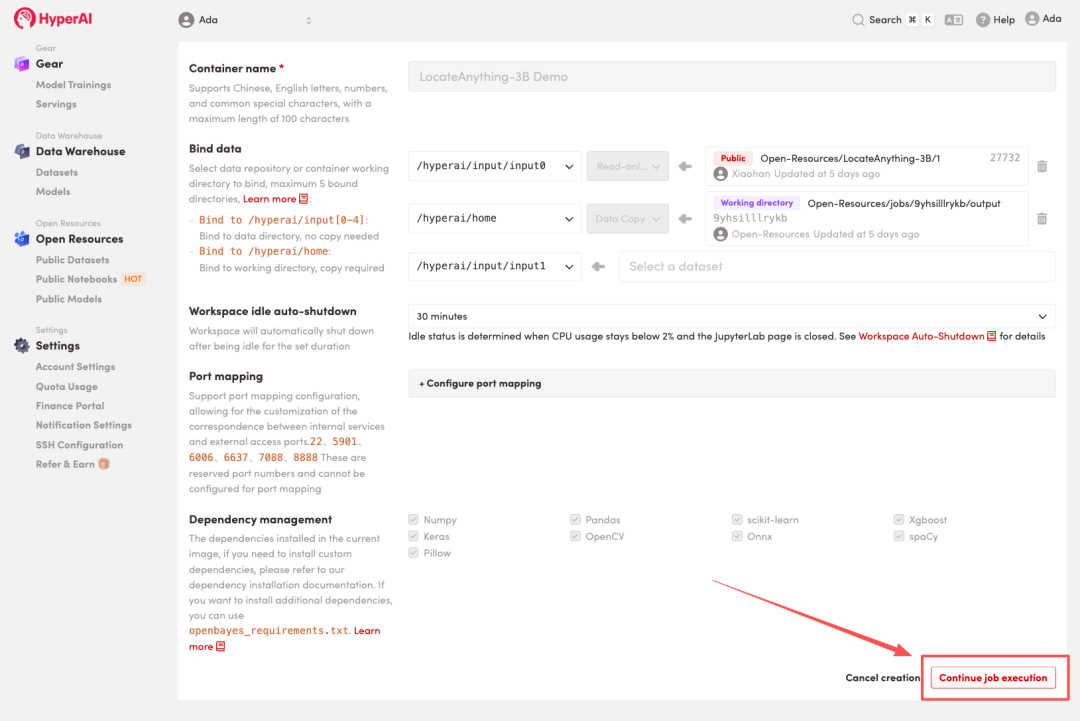
4. Attendez que les ressources soient allouées. Une fois que le statut passe à « En cours d'exécution », cliquez sur « Ouvrir l'espace de travail » pour accéder à l'espace de travail Jupyter.
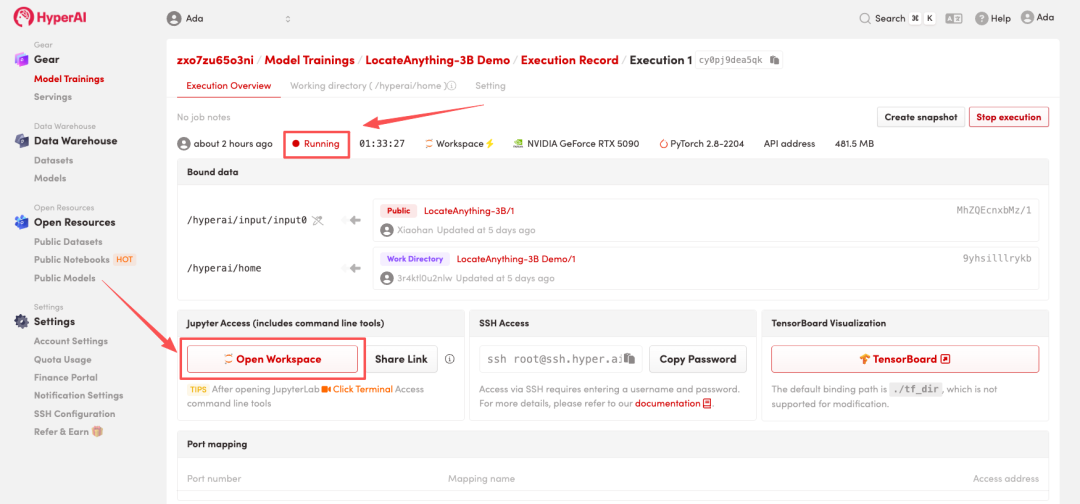
Affichage des effets
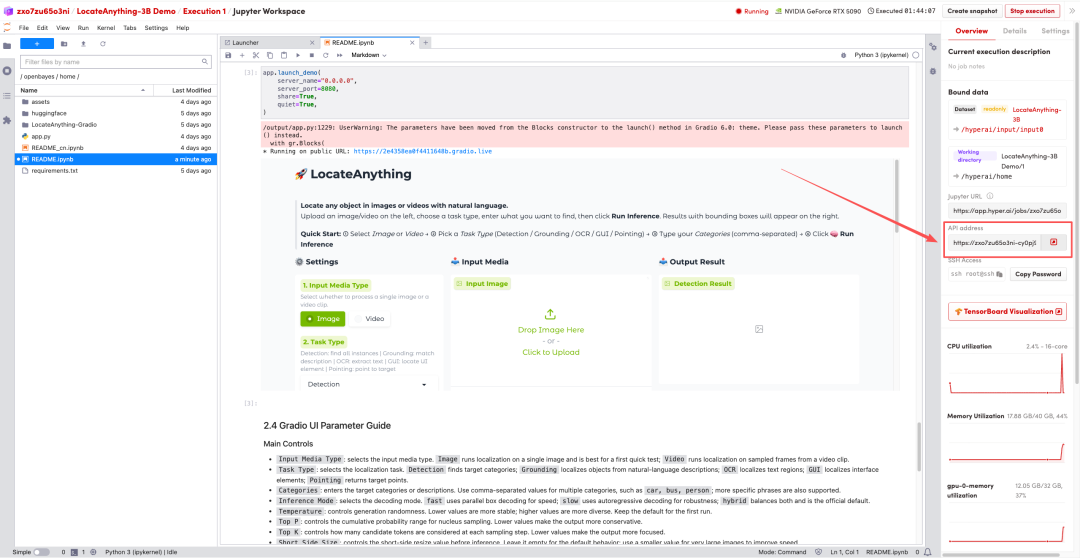
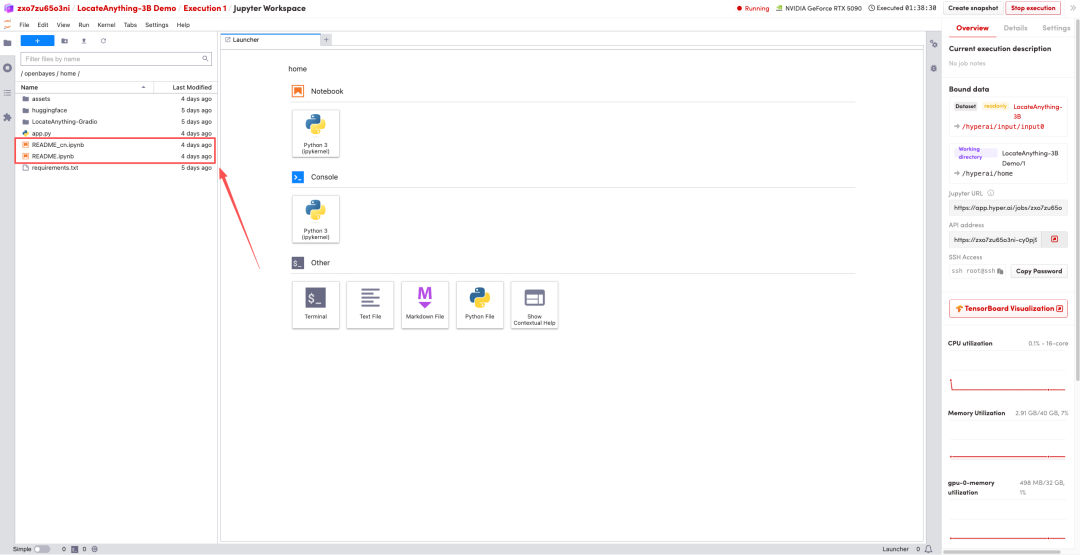
1. Une fois la page redirigée, cliquez sur le fichier README à gauche, puis sur « Exécuter » en haut.
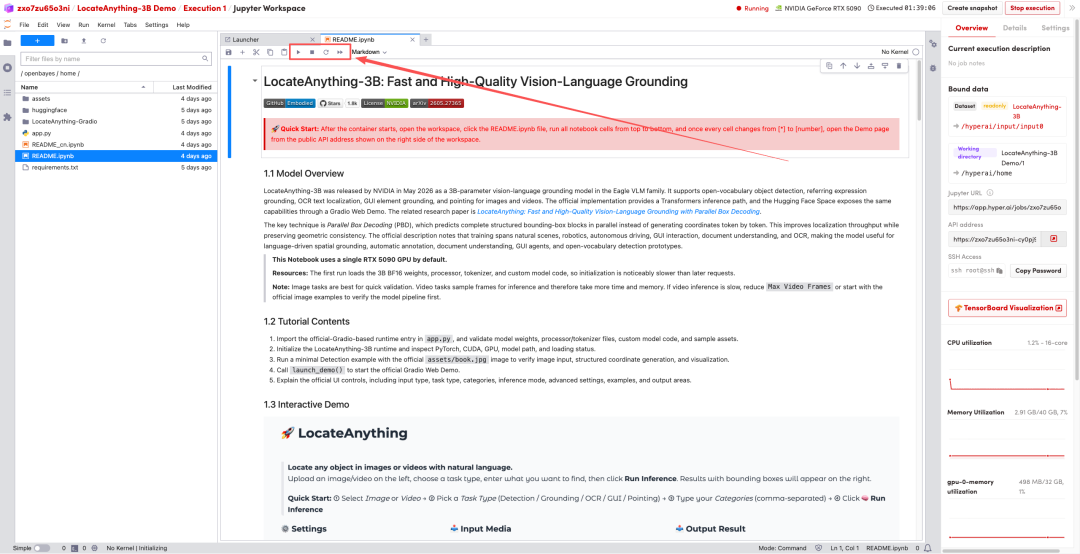
2. Une fois le processus terminé, cliquez sur l'adresse API à droite pour accéder à la page de démonstration.