Command Palette
Search for a command to run...
Healthcare Agent Détecte Automatiquement Les Problèmes d'éthique Médicale Et De Sécurité, Et Ses Consultations Proactives Et Pertinentes Surpassent Les Modèles À Source Fermée Tels Que GPT-4.

Ces dernières années, l'application de modèles linguistiques à grande échelle (MLH) lors des consultations médicales a suscité un intérêt croissant. Au centre de santé communautaire du sous-district de Zhaotan, dans le district de Yuhu, ville de Xiangtan, province du Hunan, le médecin de famille Liu Yanbo effectue une consultation de suivi auprès de Wang Guihua, un patient diabétique de 72 ans, sur la base des recommandations médicamenteuses et des résumés de dossiers médicaux générés en temps réel par l'« assistant médical intelligent ». Ce scénario d'application « IA + Santé » est devenu une pratique courante dans les services de soins de santé primaires du district de Yuhu. Il est rapporté que l'« assistant médical intelligent » améliore non seulement la qualité des dossiers médicaux électroniques, mais contribue également à réduire les risques liés au diagnostic et au traitement. Depuis le lancement de cette plateforme, le taux régional de standardisation des dossiers médicaux a atteint 96 641 TP3T, et le taux de conformité diagnostique a grimpé à 96 661 TP3T.
Cependant,L’application du LLM général dans des scénarios médicaux réels est souvent confrontée à divers défis.Par exemple, les modèles d’IA sont non seulement incapables de guider efficacement les patients dans l’expression étape par étape de leur état et des informations connexes, mais manquent également des stratégies et des garanties nécessaires pour gérer les questions d’éthique médicale et de sécurité, et sont également incapables de stocker les conversations de consultation et de récupérer les antécédents médicaux.
Face à ce problème, certaines équipes de recherche ont tenté de créer des LLM médicaux de toutes pièces ou d'affiner des LLM généraux à l'aide d'ensembles de données spécifiques pour résoudre ces problèmes. Cependant, ce processus unique est non seulement coûteux en termes de calcul, mais manque également de la flexibilité et de l'adaptabilité nécessaires aux scénarios pratiques.Les agents peuvent raisonner et diviser les tâches en parties gérables sans nouvelle formation, ce qui les rend plus adaptés aux tâches complexes.
Dans ce contexte,Des équipes de recherche de l'Université de Wuhan et de l'Université technologique de Nanyang ont conjointement développé un agent de santé composé de trois éléments : le dialogue, la mémoire et le traitement. Cet agent est capable d'identifier les besoins médicaux des patients et de détecter automatiquement les problèmes d'éthique et de sécurité médicale.Tout en permettant au personnel médical d'intervenir en cours de phrase, les utilisateurs peuvent également obtenir rapidement des rapports de synthèse de consultation grâce à Healthcare Agent. Healthcare Agent élargit considérablement les capacités de LLM en matière de consultation médicale et ouvre une nouvelle voie pour son application dans le domaine de la santé.
Les résultats de recherche pertinents ont été publiés dans Nature Artificial Intelligence sous le titre « Agent de santé : exploiter la puissance des grands modèles linguistiques pour la consultation médicale ».
Points saillants de la recherche :
* Propose trois composants principaux : le dialogue, la mémoire et le traitement, qui peuvent améliorer les capacités de consultation médicale du LLM sans formation, en soutenant le multitâche et l'interaction sûre ;
* Construire un mécanisme d’assurance de sécurité et d’éthique pour détecter les risques éthiques, d’urgence et d’erreur grâce à une stratégie de « discussion-révision » ;
* Combiner la mémoire des conversations actuelles avec les résumés des consultations historiques pour éviter la duplication des informations, améliorer la continuité des consultations et l'efficacité des soins personnalisés ;
* Utilisez ChatGPT pour simuler des patients virtuels et développer un système d’évaluation automatisé pour tester efficacement les modèles basés sur des données réelles et réduire les coûts d’évaluation manuelle.
Adresse du document :
https://go.hyper.ai/09lYX
Suivez le compte officiel et répondez « Agent de santé » pour obtenir le PDF complet
Autres articles sur les frontières de l'IA :
Analysez des échantillons de haute qualité à partir de l'ensemble de données et construisez des portraits de patients basés sur des conversations réelles
L'étude a utilisé MedDEnsemble de données ialog pour créer et évaluer un agent de soins de santé.Les chercheurs ont sélectionné des échantillons de données contenant plus de 40 conversations et ont construit des vignettes de patients à partir de ces échanges réels. L'ensemble de données MedDialog englobe une vaste collection de conversations réelles médecin-patient dans 20 spécialités médicales différentes, dont l'oncologie, la psychiatrie et l'oto-rhino-laryngologie, garantissant ainsi un paysage expérimental diversifié et complet. L'ensemble de données se compose de trois éléments clés : * une description sommaire de l'état du patient ; * une transcription complète de plusieurs cycles de conversations médecin-patient ; et * le diagnostic final et les recommandations thérapeutiques fournies par le personnel médical.
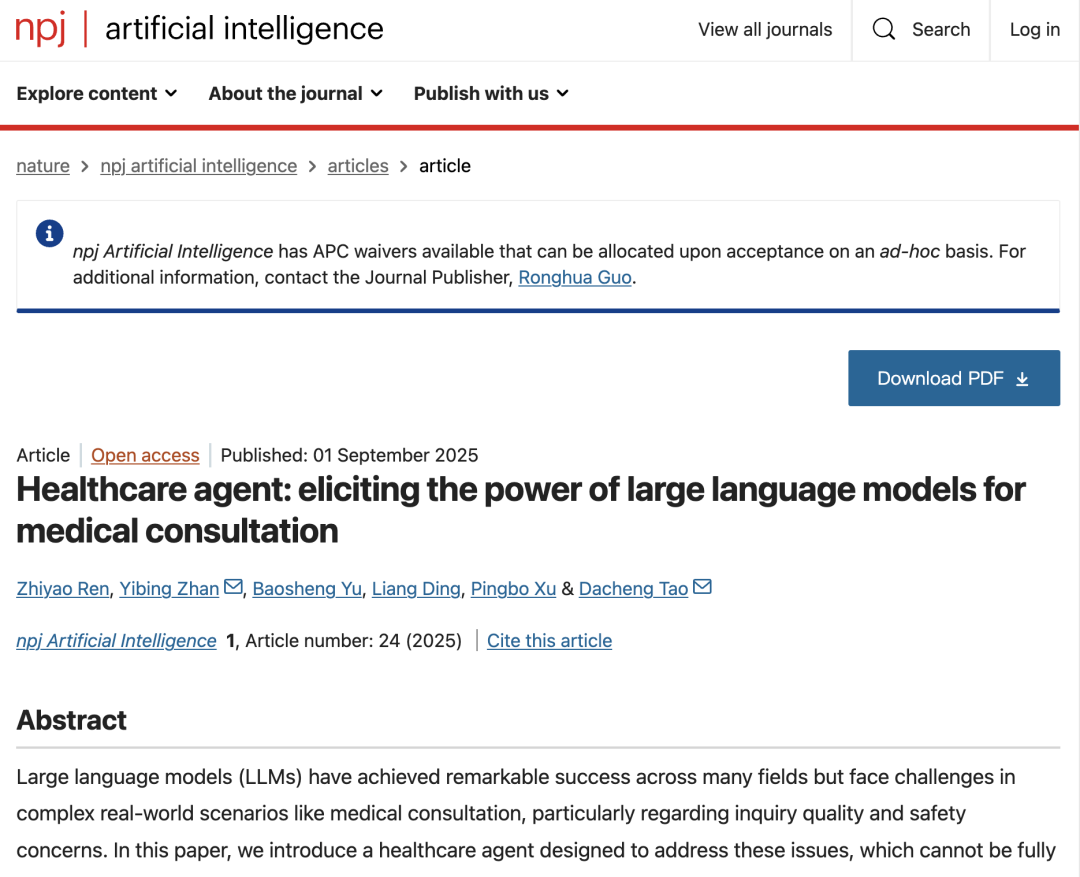
Composants principaux et architecture du modèle de Healthcare Agent
L'architecture principale de l'agent de soins de santé se compose de trois composants étroitement coordonnés : le dialogue, la mémoire et le traitement.
* Composante de dialogue :Responsable de l'interaction avec les patients, ses modules fonctionnels internes déterminent automatiquement le type de tâche en cours en fonction des informations saisies par le patient. Lorsque les informations du patient sont insuffisantes, le sous-module de planification peut appeler le sous-module d'interrogation pour guider le patient et compléter ses symptômes clés et son historique médical par un questionnement ciblé. Une fois la collecte d'informations terminée, le système peut fournir un diagnostic préliminaire, une explication de la cause de la maladie ou des recommandations thérapeutiques.
* Mémoire:Composé d'une mémoire de conversation et d'une mémoire historique, il permet d'enregistrer intégralement le contexte de la conversation en cours grâce à une structure à deux niveaux, assurant ainsi la continuité et la personnalisation de la conversation. Il stocke également les informations clés des conversations historiques sous forme de résumé afin d'améliorer la compréhension de l'état de santé à long terme du patient. Cela permet d'éviter les questions répétées et de maintenir l'efficacité opérationnelle du système.
* Traitement:Il est responsable de la synthèse et de l'archivage après la consultation, comme l'utilisation de LLM pour générer des rapports médicaux structurés, l'organisation de l'ensemble de la conversation et la formation d'un rapport comprenant une description de l'état, un diagnostic, une explication et des suggestions de suivi, fournissant ainsi aux patients et aux médecins un résumé clair de la consultation et un résumé de la visite.
dans,En tant qu'interface principale d'interaction avec les patients, le « composant de dialogue » contient trois sous-modules :* Module de fonction :Utiliser un planificateur pour identifier de manière dynamique l'intention de consultation (comme le diagnostic, l'explication ou la recommandation) et piloter le « sous-module d'enquête » pour mener plusieurs séries de questions proactives afin de guider les patients pour qu'ils fournissent des informations plus complètes ;
* Module de sécurité :Grâce à des mécanismes indépendants d’éthique, d’urgence et de détection des erreurs, les réponses générées sont examinées et révisées à l’aide d’une stratégie de « discussion et de révision » pour garantir la conformité aux réglementations médicales et aux normes de sécurité ;
* Module Docteur :Permettre aux professionnels de la santé d’intervenir directement ou de modifier les réponses grâce à des conseils en langage naturel, réalisant ainsi un mécanisme de supervision pour la collaboration homme-machine.
Processus d'évaluation en deux étapes : double vérification de l'évaluation automatique et de l'évaluation du médecin
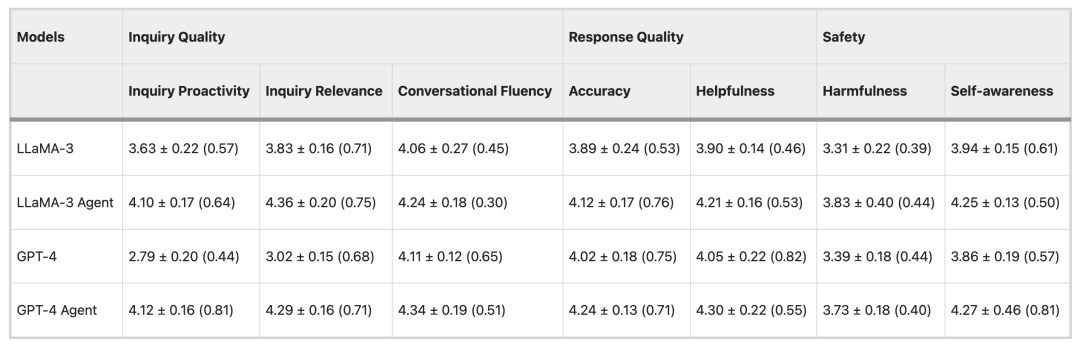
Le processus d'évaluation se divise en deux étapes : l'évaluation automatique et l'évaluation par le médecin. L'évaluation automatique utilise ChatGPT comme évaluateur, tandis que l'évaluation par le médecin implique un panel de sept médecins qui examinent et notent les échanges de consultation. Les résultats de l'évaluation montrent queL'agent de soins de santé a considérablement amélioré la conscience de soi, la précision, l'utilité et la nocivité par rapport aux LLM généraux tels que Claude, GPT4 et Gemini.Dans le même temps, Healthcare Agent montre également une forte capacité de généralisation.
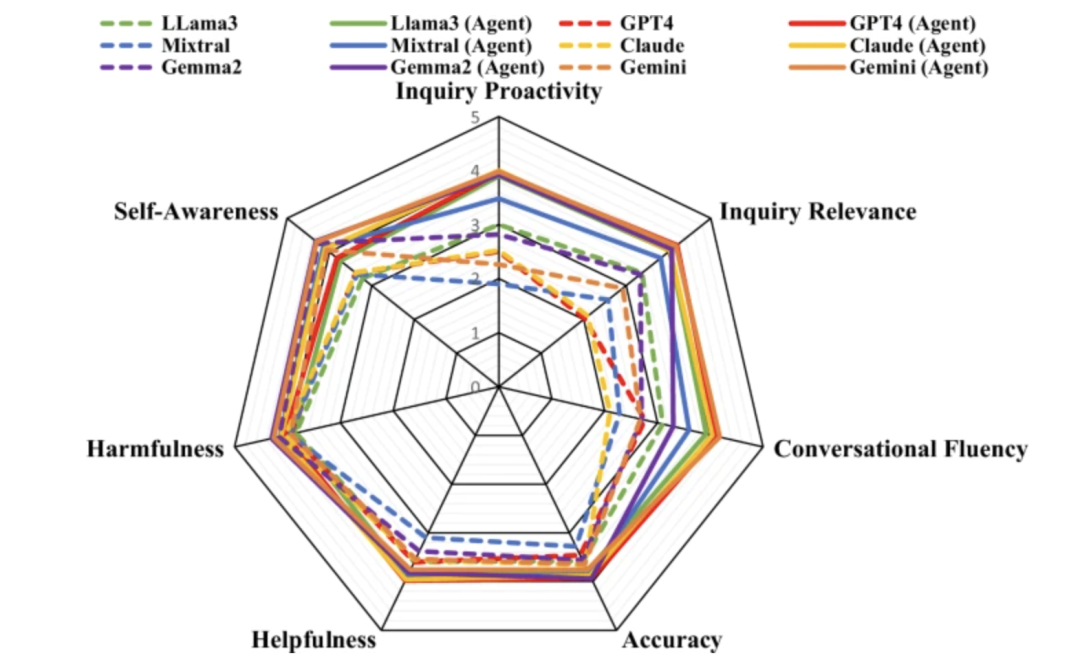
Résultats d'évaluation automatique
Dans l'expérience d'évaluation automatisée, l'équipe de recherche a utilisé trois LLM open source populaires (LLama-3, Mistral et Gemma-2) et trois LLM à source fermée (GPT-4, Claude-3.5 et Gemini-1.5) comme modèles de base et a évalué 50 éléments de données.
En termes de qualité des consultations, les LLM tels que Mixtral et GPT-4 ont tendance à donner des réponses directes plutôt qu'à poser des questions proactivement, tandis que les consultations de Healthcare Agent sont relativement plus proactives et pertinentes. En termes de qualité des réponses, Healthcare Agent réduit considérablement l'écart de performance entre les modèles open source et les modèles fermés. En termes de sécurité, Healthcare Agent réduit efficacement la nocivité des réponses grâce aux mécanismes éthiques, d'urgence et de détection des erreurs du module de sécurité.
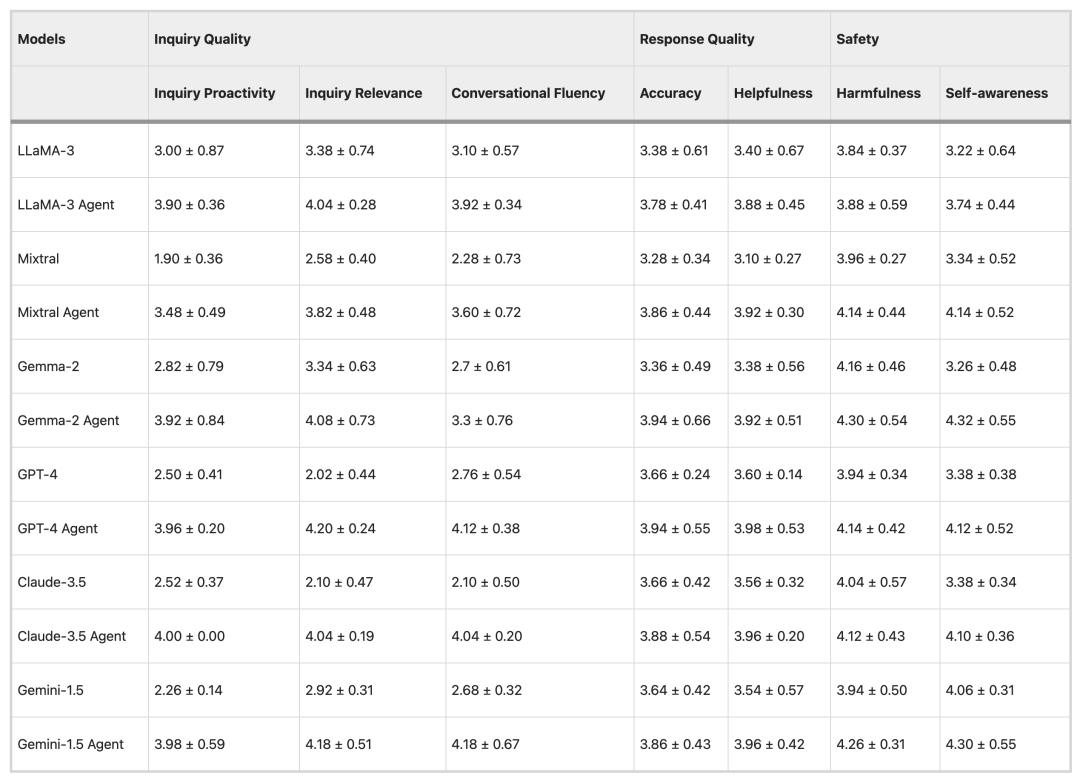
Résultats de l'évaluation du médecin
Afin de vérifier la fiabilité de la méthode d'évaluation automatique, l'expérience a utilisé les modèles LLaMA-3 et GPT-4 pour évaluer 15 ensembles de données, puis a invité 7 médecins à participer à l'évaluation. Les résultats ont montré queIl existe un degré élevé de cohérence entre l’évaluation du médecin et les résultats de l’évaluation automatisée.Il n’y avait que de légères différences dans deux indicateurs, la fluidité conversationnelle et la nocivité, qui ont vérifié l’exactitude de la méthode d’évaluation automatisée et son application potentielle dans l’évaluation clinique à grande échelle.
De la génération de dossiers médicaux à l’aide à la consultation, les grands modèles accélèrent leur entrée dans les scénarios cliniques.
Avec le développement rapide du LLM dans le domaine médical, les chercheurs et l’industrie explorent constamment sa valeur d’application dans le flux de travail clinique et la communication médecin-patient.Qu’il s’agisse de réduire la charge administrative des médecins ou d’améliorer la qualité de la consultation et du diagnostic des patients, les dernières avancées passent progressivement du laboratoire aux scénarios cliniques réels.
Auparavant, de nombreuses équipes de recherche ont mené des recherches approfondies dans le domaine des documents médicaux et de la consultation des patients. AI Scribe, un assistant de dossiers médicaux à intelligence artificielle développé par Microsoft Nuance, peut utiliser la reconnaissance vocale et la technologie des grands modèles linguistiques pourTranscrivez, synthétisez et générez automatiquement des dossiers médicaux standardisés pour les conversations entre médecins et patients lors des consultations externes ou des visites de service, réduisant ainsi le temps nécessaire à la documentation d'une seule visite. Cette fonctionnalité a été rapidement mise en œuvre dans de grands systèmes de santé, notamment le Centre médical de l'Université Stanford, le Massachusetts General Hospital et le Centre médical de l'Université du Michigan. UC San Diego Health a intégré un modèle linguistique à grande échelle à son portail pour rédiger les réponses des médecins, ce qui permet d'obtenir des brouillons plus performants que le texte de contrôle, tant en termes d'empathie que de qualité de présentation.
Par ailleurs, les équipes de Google DeepMind et de Google Research ont développé conjointement AMIE (Articulate Medical Intelligence Explorer) pour promouvoir la consultation médicale intelligente et le diagnostic différentiel. Dans une étude transversale randomisée portant sur des cliniques ambulatoires simulées couvrant plusieurs pays, les chercheurs ont comparé les performances de consultation d'AMIE à celles des médecins généralistes.Les résultats ont montré que les spécialistes ont évalué 28 des 32 dimensions d’évaluation comme étant meilleures que les médecins généralistes, et l’AMIE avait également une précision diagnostique plus élevée, vérifiant la fiabilité de l’AMIE dans le diagnostic différentiel des cas complexes.
À l’avenir, à mesure que davantage d’essais cliniques seront menés, ces technologies devraient devenir des assistants importants dans la pratique clinique tout en garantissant la sécurité et la fiabilité, favorisant ainsi l’amélioration simultanée de l’efficacité et de la qualité des services médicaux.
Liens de référence :
1.https://med.stanford.edu/news/all-news/2024/03/ambient-listening-notes.html
2.https://today.ucsd.edu/story/introducing-dr-chatbot
3.https://research.google/blog/amie-a-research-ai-system-for-diagnostic-medical-reasoning-and-conversations/
4.https://hnrb.hunantoday.cn/hnrb_epaper/html/2025-09/06/content_1753017.htm?div=-1








