Command Palette
Search for a command to run...
Avec Une Précision De 971 TP3T ! L'université De Princeton Et d'autres Ont Proposé MOFSeq-LMM, Qui Prédit Efficacement Si Les MOF Peuvent Être synthétisés.
Les réseaux métallo-organiques (MOF) ont démontré un grand potentiel dans des applications telles que le stockage et la séparation des gaz, la catalyse et l'administration de médicaments grâce à leurs structures poreuses hautement modulables et à leurs riches fonctionnalités chimiques. Cependant,Les MOF possèdent un vaste espace de conception englobant des billions de combinaisons possibles d'éléments constitutifs, ce qui rend l'exploration expérimentale extrêmement inefficace.
Pour accélérer la découverte des MOF, des chaînes de traitement informatique ont émergé, visant à générer de nouveaux MOF, à prédire leurs propriétés et, finalement, à réaliser leur synthèse. Dans ce processus,Le principal défi réside dans le faible taux de conversion entre le criblage et la synthèse.Cela s'explique en grande partie par l'incertitude qui entoure la faisabilité de la synthèse de MOF par ordinateur. Par exemple, sur les milliers de criblages informatiques de MOF publiés à ce jour, seule une douzaine environ ont été accompagnés d'une synthèse de MOF.
L'énergie libre est un indicateur important pour évaluer la stabilité thermodynamique et la synthétisabilité des MOF, mais les méthodes de calcul traditionnelles sont coûteuses pour les grands ensembles de données de MOF, ce qui rend le criblage rapide difficile. Pour relever ce défi, une équipe de recherche conjointe de l'Université de Princeton et de la Colorado School of Mines a proposé une méthode de prédiction efficace basée sur l'apprentissage automatique.En utilisant de grands modèles de langage (LLM) pour prédire directement l'énergie libre à partir de la séquence structurelle des MOF, les coûts de calcul peuvent être considérablement réduits, permettant une évaluation thermodynamique à haut débit et évolutive des MOF.Le modèle fait preuve d'une grande polyvalence sans avoir besoin d'être réentraîné : son score F1 atteint 97% lorsqu'il s'agit de déterminer si l'énergie libre des MOF est supérieure ou inférieure au seuil de faisabilité synthétique basé sur l'empirisme.
Les résultats de cette recherche, intitulée « Prédiction très précise et rapide de l'énergie libre des MOF par apprentissage automatique », ont été publiés dans ACS Publications.
Points saillants de la recherche :
* Grâce à ce modèle, les chercheurs peuvent prédire l'énergie libre avec une grande précision et simuler les résultats de simulations moléculaires complètes sans réentraînement, déterminant ainsi la faisabilité de la synthèse des MOF.
* Les travaux qui nécessitaient auparavant beaucoup de temps en laboratoire ou par le biais de simulations moléculaires peuvent désormais être effectués en un temps négligeable.
Cette méthode offre une approche réalisable pour utiliser la prédiction de l'énergie libre par apprentissage automatique comme outil de sélection précoce ou tardive dans le criblage informatique des MOF basé sur la performance.

Adresse du document :
https://pubs.acs.org/doi/10.1021/jacs.5c13960
Suivez notre compte WeChat officiel et répondez « prédiction d'énergie gratuite » en arrière-plan pour obtenir le PDF complet.
Autres articles sur les frontières de l'IA :
MOFMinE : Couverture d'un million de prototypes MOF
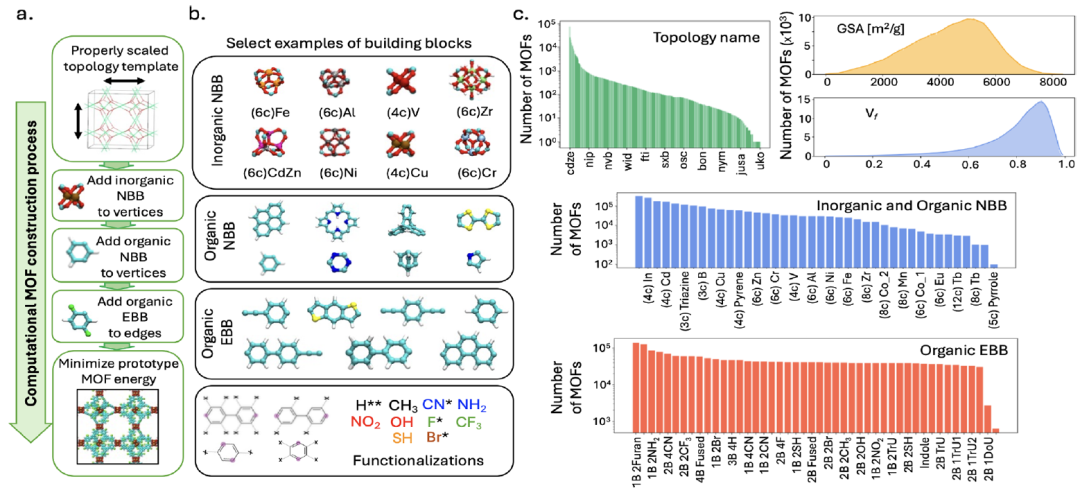
Pour soutenir la formation des modèles,L'équipe de recherche a constitué un vaste ensemble de données MOF, MOFMinE, couvrant environ un million de prototypes MOF.Il comprend des informations sur l'ensemble du processus, depuis la sélection des composants et le mappage du modèle de topologie jusqu'aux modifications fonctionnelles, comme illustré dans la figure suivante :
méthode de construction
L'ensemble de données est généré à partir de la plateforme ToBaCCo-3.0. Chaque MOF est généré en projetant ses unités de construction constitutives sur un gabarit topologique mis à l'échelle (pour correspondre à la taille de l'unité de construction). Ce gabarit détermine l'agencement spatial et la connectivité des unités de construction au sein de la maille élémentaire du MOF. Les unités de construction ToBaCCo sont classées en blocs nodaux (NBB) ou blocs d'arête (EBB) selon leur position : les blocs nodaux sont projetés sur les sommets du gabarit, et les blocs d'arête sur ses arêtes. Les NBB peuvent être inorganiques ou organiques ; les NBB inorganiques correspondent aux unités de construction de second ordre (SBU) du MOF, tandis que les NBB organiques s'associent aux EBB pour former les connecteurs du MOF.
échelle et diversité des données
MOFMinE contient 1 393 modèles topologiques, 27 NBB inorganiques, 14 NBB organiques et 19 EBB de base, et couvre 13 modifications fonctionnelles, assurant la diversité des structures chimiques et topologiques.La base de données présente une fraction de vide allant de 0,01 à 0,99, une surface spécifique (GSA) allant de 26 à 8382 m²/g et une taille de pore maximale (LPD) allant de 2,6 à 127,7 Å, couvrant entièrement l'espace structurel des MOF.
sous-ensemble d'énergie libre
Parmi ces 1 million de prototypes MOF, un sous-ensemble de 65 574 structures a permis de recueillir des données sur l'énergie libre.Ce sous-ensemble comprend 379 modèles topologiques, 6 NBB inorganiques, 11 NBB organiques et 12 EBB de base présentant 13 modifications de fonctionnalisation. Les propriétés de porosité de ce sous-ensemble sont les suivantes : Vf variant de 0,01 à 0,97, GSA variant de 38 à 7 304 m²/g et LPD variant de 2,6 à 87,8 Å. Cet ensemble de données a été utilisé pour l’ajustement précis de la prédiction de l’énergie libre et la validation des LLM.
Modèle MOFSeq-LMM pour une prédiction efficace de l'énergie libre des MOF
Avec le soutien de l'ensemble de données MOFMinE,L'équipe de recherche a construit le cadre de modèle MOFSeq-LMM pour prédire efficacement l'énergie libre des MOF et réaliser une conception basée sur les données, de la structure aux propriétés.L'idée centrale de ce cadre est de transformer les informations structurelles des MOF en une représentation de séquence compréhensible par ordinateur (MOFSeq) et de la combiner avec un grand modèle de langage pour l'apprentissage et la prédiction, réduisant ainsi considérablement les coûts de calcul tout en préservant les informations physico-chimiques.
Caractérisation MOFSeq
Pour surmonter les limitations des stratégies de représentation existantes et exploiter pleinement les grands modèles de langage pour une prédiction étendue des propriétés MOF,Des chercheurs ont mis au point MOFSeq. Cette nouvelle méthode de représentation de séquences basée sur des chaînes de caractères est à la fois compacte et très informative, encodant de manière optimisée les caractéristiques structurelles locales et globales des MOF.Cela permet de traiter les modèles de langage de manière efficace et évolutive.
Dans MOFSeq, les informations locales comprennent principalement la composition atomique des unités de base et leurs informations de connectivité interne ; les informations globales comprennent principalement des descriptions de haut niveau des unités de base MOF et des motifs de connexion entre elles. Les informations locales sont obtenues grâce à l’outil MOFid, tandis que les informations globales reposent sur ToBaCCo-3.0, comme illustré dans la figure ci-dessous :
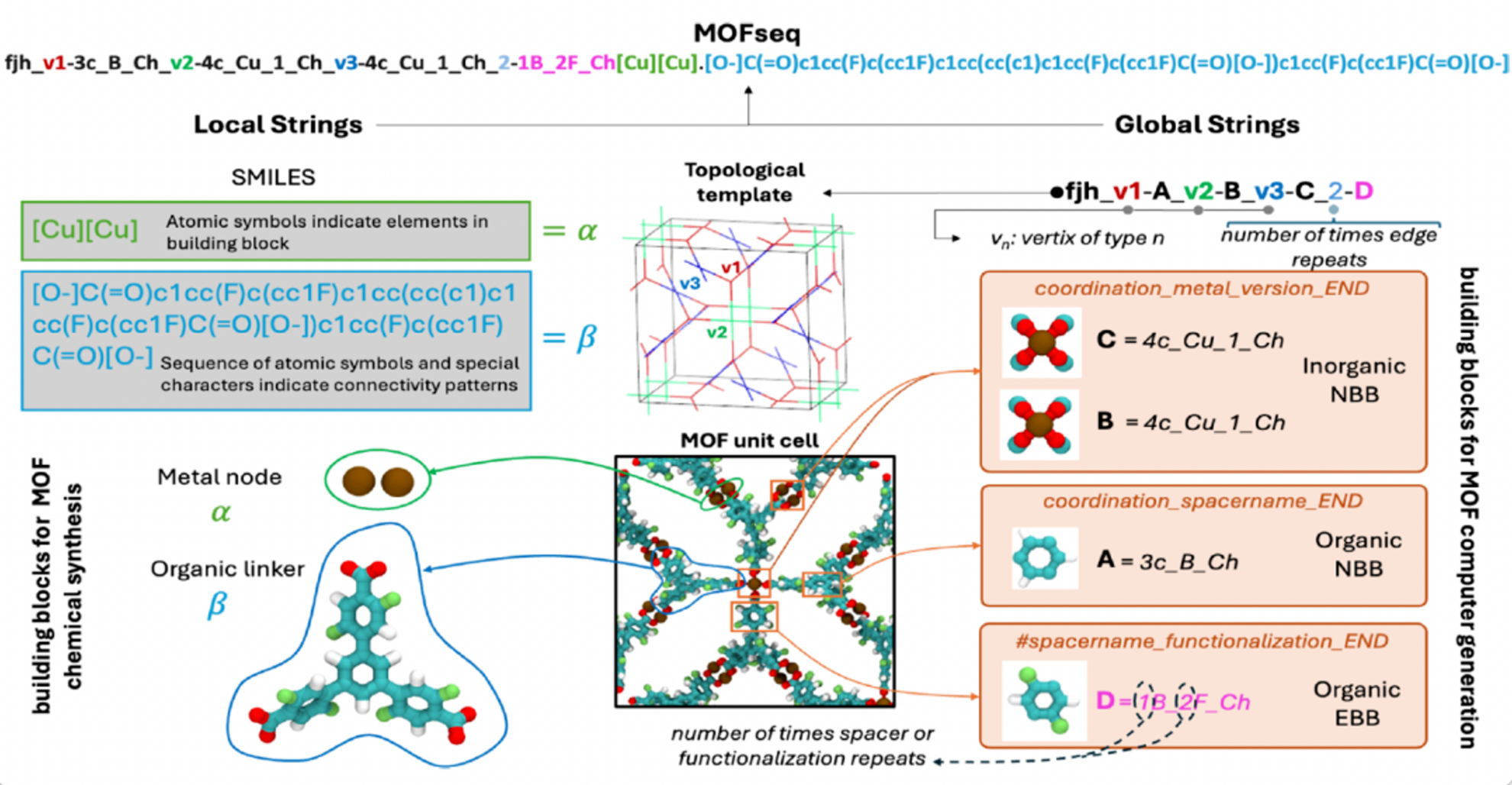
Construction et traitement des données de la base de données MOF
Après avoir construit l'ensemble de données MOFMinE sur la base de la méthode décrite ci-dessus, tous les prototypes MOF générés par ToBaCCo ont été optimisés à l'aide du champ de force UFF4MOF dans LAMMPS (version du 29 octobre 2020) pour obtenir les structures MOF finales.
L'ensemble de données généré avec ToBaCCo-3.0 ne contient que le nom du MOF et son fichier CIF correspondant pour représenter chaque MOF. Or, MOFSeq requiert à la fois le nom et l'identifiant du MOF (MOFid).Pour obtenir le MOFid, les chercheurs ont utilisé le générateur MOFid développé par Bucior et al.Ce générateur peut générer simultanément MOFid et MOFkey à partir de la structure CIF du MOF.
Au final, les 793 079 échantillons de pré-entraînement MOFSeq ont été répartis en un ensemble d'entraînement de 634 463 échantillons, un ensemble de validation de 79 308 échantillons et un ensemble de test de 79 308 échantillons. Les 54 443 points de données d'ajustement fin MOFSeq ont été répartis en un ensemble d'entraînement de 43 554 échantillons, un ensemble de validation de 5 444 échantillons et un ensemble de test de 5 445 échantillons.
Conception de modèles LLM-Prop
S’appuyant sur la caractérisation MOFSeq, l’équipe de recherche a utilisé LLM-Prop, un grand modèle de langage spécialement conçu pour prédire les propriétés des matériaux. Le modèle LLM-Prop, de taille relativement modérée avec environ 35 millions de paramètres, garantit à la fois une bonne capacité d'apprentissage et une efficacité de calcul élevée. La longueur des données d'entrée est fixée à 2 000 jetons, ce qui permet de prendre en compte les informations de séquence structurale de la plupart des MOF. Grâce à un mécanisme d'attention, le modèle capture de manière adaptative l'influence des différents composants et topologies sur l'énergie libre de la séquence, formant ainsi une représentation interactive des caractéristiques globales et locales.
Pré-entraînement et mise au point
* Phase de pré-entraînement :
Les chercheurs ont entraîné LLM-Prop à prédire les énergies de déformation des MOF à partir de la représentation MOFSeq. L'énergie de déformation a été choisie pour son faible coût de calcul et sa forte corrélation avec l'énergie libre. Des taux d'abandon de 0,2 et 0,5 ont été utilisés lors du pré-entraînement ; les résultats ont montré qu'un taux d'abandon de 0,2 offrait de meilleures performances, tant pour le pré-entraînement que pour les tâches ultérieures. La longueur de l'entrée MOFSeq a été fixée à 2 000 jetons.
Phase de réglage fin :
La configuration est identique à celle du pré-entraînement, mais l'objectif du modèle est modifié pour prédire l'énergie libre, et le nombre d'époques d'entraînement est porté à 200. LLM-Prop est conçu comme un modèle léger, environ 2 000 fois plus petit que Llama 2, privilégiant l'efficacité de calcul. Cette conception implique un compromis : comparé à l'ajustement fin de grands modèles linéaires linéaires (tels que Llama 2 ou GPT-2), LLM-Prop nécessite davantage d'époques d'entraînement pour atteindre des performances élevées, mais sa petite taille rend l'entraînement faisable et efficace.
La précision de la prédiction de la synthèse des MOF a atteint 97%.
Après l'entraînement du modèle MOFSeq-LMM, l'équipe de recherche a évalué systématiquement ses performances en matière de prédiction de l'énergie libre, d'évaluation de la faisabilité de la synthèse et de criblage de MOF polymorphes. Les résultats expérimentaux ont non seulement validé la grande précision du modèle, mais ont également mis en évidence son potentiel d'application pour la conception et le criblage à haut débit de MOF.
performance de prédiction de l'énergie libre
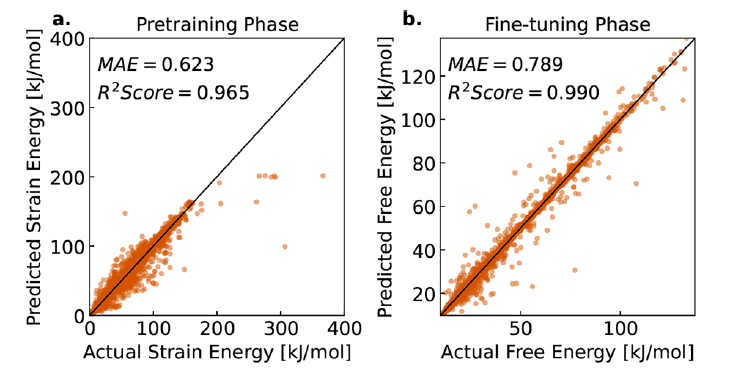
d'abord,L'équipe a évalué les performances de prédiction de l'énergie libre de LLM-Prop sur des échantillons MOF inconnus.Les résultats montrent que le modèle peut prédire avec précision l'énergie libre avec une erreur absolue moyenne (MAE) de 0,789 kJ/mol MOFatom, tout en atteignant une corrélation élevée de R² = 0,990, comme le montre la figure b ci-dessous.Cela signifie que le modèle peut fournir des prédictions proches des valeurs réelles dans la grande majorité des échantillons de MOF.
Lors de la phase de pré-entraînement, le modèle a été entraîné à l'aide de données d'énergie de déformation, atteignant une erreur absolue moyenne (MAE) de 0,623 kJ/mol MOFatom et un coefficient de détermination (R²) de 0,965, comme illustré sur la figure a. Cette forte corrélation indique que les données d'énergie de déformation peuvent fournir des informations préliminaires efficaces pour la prédiction de l'énergie libre, validant ainsi la pertinence de la stratégie de pré-entraînement de l'équipe de recherche. Une analyse plus approfondie révèle une forte corrélation entre l'énergie de déformation pré-entraînée et l'énergie libre affinée, démontrant l'intérêt de l'énergie de déformation comme indicateur indirect et économique pour l'entraînement du modèle.
Résultats de l'expérience d'ablation
Afin de mieux comprendre les facteurs influençant les performances du modèle, l'équipe a mené des expériences d'ablation systématiques. Ces expériences ont examiné l'impact des caractéristiques locales, des caractéristiques globales et du pré-entraînement sur la prédiction de l'énergie libre. Les résultats sont présentés dans le tableau ci-dessous :
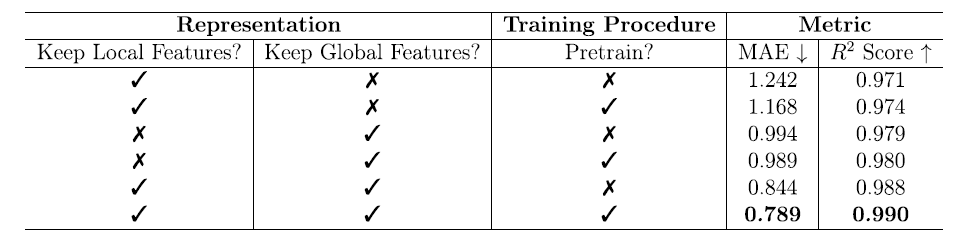
Caractéristiques locales uniquement : grâce au pré-entraînement, l’erreur absolue moyenne (MAE) a diminué de 1,242 à 1,168 kJ/mol MOFatom et le coefficient de détermination (R²) a augmenté de 0,971 à 0,974, ce qui indique que le pré-entraînement peut améliorer la capacité de généralisation du modèle lorsque les caractéristiques locales sont limitées.
* Fonctionnalités globales uniquement :
Les performances sont nettement supérieures à celles obtenues avec les seules caractéristiques locales : l’erreur absolue moyenne (MAE) diminue en dessous de 1,0 kJ/mol MOFatom et le coefficient de détermination (R²) augmente jusqu’à environ 0,980. Le pré-entraînement a un impact relativement faible dans ce cas (la MAE diminue de 0,994 à 0,989 kJ/mol MOFatom et le R² augmente de 0,979 à 0,980), ce qui indique que les caractéristiques globales contiennent davantage d’informations sur la tâche et nécessitent moins de pré-entraînement pour un apprentissage efficace.
* Combinaison de fonctionnalités locales et globales :
Avec le soutien du pré-entraînement, le modèle a atteint des performances optimales avec un MAE de 0,789 kJ/mol MOFatom et un R² de 0,990, démontrant que l'effet synergique des deux types de caractéristiques est crucial pour améliorer la précision de la prédiction.
Cette expérience d'ablation démontre clairement que la conception des caractéristiques globales et locales et la stratégie de pré-entraînement de MOFSeq sont les éléments essentiels pour améliorer la capacité prédictive du modèle.
Évaluation de la faisabilité de la synthèse
Dans les applications industrielles, il est plus important de déterminer la faisabilité de la synthèse des MOF que de se concentrer uniquement sur la valeur absolue de leur énergie libre. L'équipe de recherche a fixé le seuil de ΔL_MFFL (un indice basé sur la correction d'énergie libre) à 4,4 kJ/mol MOFatom et a effectué une prédiction par classification binaire de la faisabilité de la synthèse des MOF. Les résultats expérimentaux sont présentés dans la figure ci-dessous :
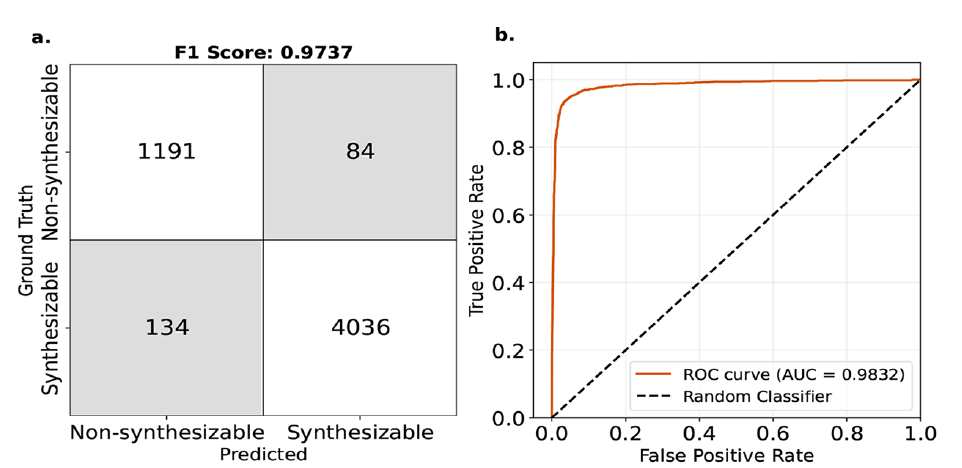
* Le score F1 a atteint 97%, démontrant la bonne capacité de généralisation du modèle.
* L'aire sous la courbe ROC (AUC) atteint 0,98 – ce qui peut finalement être compris comme la probabilité d'une évaluation incorrecte si le modèle détermine qu'un certain MOF peut être synthétisé étant seulement d'environ 2%.
Criblage des MOF polymorphes
Pour les systèmes MOF polymorphes,L'expérience a par ailleurs confirmé la capacité du modèle à identifier le polymorphe le plus stable.Parmi 7 490 familles de polymorphes, chacune contenant 2 à 50 polymorphes, le modèle peut sélectionner correctement le polymorphe le plus stable avec une différence d'énergie libre de seulement 0,16 kJ/mol MOFatom, avec un taux de réussite d'environ 63% ; lorsque la différence d'énergie libre augmente à 0,49 kJ/mol MOFatom, le taux de réussite passe à 89%.
Globalement, le modèle atteint un taux de réussite moyen d'environ 781 TP3T sur la tâche de reconnaissance du polymorphisme.Comme le montre la figure ci-dessous, elle présente une valeur significative dans la prédiction à haut débit avant le criblage expérimental.

D'un point de vue pratique, si LLM détermine qu'une certaine structure de MOF peut être synthétisée après évaluation de sa stabilité thermodynamique et de la compétition polymorphique, sa probabilité de justesse se situe approximativement entre 76% et 98%. La probabilité la plus élevée correspond au cas où le MOF ne présente pas de polymorphes concurrents.
L'IA est en train de redéfinir le paradigme de la recherche en MOF et en science des matériaux.
8 octobre 2025L'Académie royale des sciences de Suède a décidé d'attribuer le prix Nobel de chimie 2025 au professeur Susumu Kitagawa de l'université de Kyoto, au professeur Richard Robson de l'université de Melbourne et au professeur Omar Yaghi de l'université de Californie à Berkeley, en reconnaissance de leurs contributions à la recherche dans le domaine des MOF.Rétrospectivement, ce moment historique marque le début d'une recherche de plus de 30 ans sur les MOF, qui a progressivement évolué de la construction structurale initiale et de l'exploration de la synthèse vers la maîtrise des performances, l'expansion des applications et l'industrialisation. Forte de cette étape marquante, la science des matériaux s'ouvre à une nouvelle variable : l'intégration profonde de l'intelligence artificielle redéfinit le paradigme de recherche et le rythme d'innovation des MOF, voire de l'ensemble du domaine de la science des matériaux.
En réponse au défi que représente le vaste et complexe monde des MOF dépourvu de conventions de dénomination standardisées, en octobre 2025,Une équipe de recherche de l'Université de Toronto et du Centre de recherche sur l'innovation en matière d'énergie propre du Conseil national de recherches du Canada a proposé MOF-ChemUnity : un graphe de connaissances structuré, évolutif et extensible.Cette méthode utilise LLM pour établir une correspondance biunivoque fiable entre les noms de MOF et leurs synonymes dans la littérature et les structures cristallines enregistrées dans la CSD, permettant ainsi de lever l'ambiguïté entre les noms de MOF, leurs synonymes et les structures cristallines. Dans sa version actuelle, MOF-ChemUnity intègre environ 10 000 articles scientifiques et plus de 15 000 structures cristallines de la CSD, ainsi que leurs propriétés chimiques calculées, présentées dans un format exploitable par machine.
Titre de l'article : MOF-ChemUnity : Modèles de langage étendus basés sur la littérature pour la recherche sur les réseaux métallo-organiques
Adresse du document :https://pubs.acs.org/doi/10.1021/jacs.5c11789
Dans la conception rationnelle des matériaux MOF, la prédiction structurale avant synthèse a toujours constitué un défi majeur pour parvenir à une synthèse efficace et ciblée de ces matériaux. Pour y remédier,Une équipe dirigée par les professeurs Cui Yong et Gong Wei de l'université Jiao Tong de Shanghai a développé un flux de travail d'apprentissage automatique basé sur les données qui permet une prédiction rapide et précise du type de nœud métallique des MOF.Cette méthode utilise les informations structurales des ligands organiques et établit une correspondance entre les caractéristiques des ligands et les types de nœuds métalliques grâce à un modèle d'apprentissage automatique, permettant ainsi de prédire efficacement les types de nœuds métalliques susceptibles de se former avant la synthèse. Le modèle de prédiction, entraîné et optimisé, a atteint une précision de 91%, une justesse de 89% et un rappel de 85% sur l'ensemble de test.
Titre de l'article : Prédiction, par apprentissage automatique basé sur les données, des types de nœuds métalliques dans les réseaux métallo-organiques pour guider la conception des connecteurs et cibler la séparation inverse C3H8/C3H6
Adresse du document :http://engine.scichina.com/doi/10.1007/s11426-025-2917-4
La recherche traditionnelle sur les MOF débute souvent par l'étude de leur structure ou de leurs propriétés, en approchant progressivement le matériau cible grâce au contrôle de variables locales et à des expériences ou calculs approfondis. Cependant, dans ces nouveaux travaux, le point de départ est différent : les chercheurs construisent d'abord des systèmes de représentation des matériaux, réalisables par calcul et pertinents, puis laissent les modèles apprendre quelles combinaisons structurales sont physiquement plausibles, thermodynamiquement possibles et synthétiquement intéressantes. Lorsque les modèles pourront rapidement fournir des évaluations thermodynamiques et structurales fiables dans un espace structural à l'échelle du million, la recherche sur les matériaux se concentrera davantage sur la définition du problème, la construction des représentations et la définition des limites de décision que sur le calcul et la mesure. Il s'agit peut-être du prochain grand pas méthodologique que la recherche sur les MOF est sur le point d'accomplir après plus de trente ans d'accumulation de connaissances structurales et chimiques.
Références :
1.https://pubs.acs.org/doi/10.1021/jacs.5c13960
2.https://phys.org/news/2026-01-tool-narrows-ideal-metal-frameworks.html








