Command Palette
Search for a command to run...
LightOnOCR-2-1B : OCR De Bout En Bout De Haute Précision Basé Sur L’apprentissage RLVR ; Images Google Street View National Street View : Une Bibliothèque D’images Panoramiques Open Source Basée Sur Une Technologie De Géocartographie De Classe mondiale.

Actuellement, la technologie OCR repose sur un processus complexe et séquentiel : d’abord, les régions de texte sont détectées, puis la reconnaissance est effectuée, et enfin, le post-traitement est réalisé.Ce modèle est lourd et fragile face aux documents aux mises en page complexes et aux formats variés. La moindre erreur, quelle que soit l'étape, peut compromettre les résultats globaux, et son optimisation de bout en bout s'avère difficile, engendrant des coûts de maintenance et d'adaptation élevés.
Dans ce contexte,LightOn a publié le modèle LightOnOCR-2-1B en tant que logiciel libre.Ce modèle vision-langage de bout en bout, doté d'un milliard de paramètres seulement, atteint des performances de pointe sur le benchmark de référence OlmOCR-Bench, surpassant le précédent meilleur modèle à 9 milliards de paramètres, tout en réduisant sa taille d'un facteur 9 et en augmentant considérablement sa vitesse d'inférence. LightOnOCR-2-1B utilise un modèle unifié pour générer directement des cadres de délimitation de texte et d'image structurés et ordonnés à partir des pixels. Grâce à l'intégration de composants pré-entraînés, de données distillées de haute qualité et de stratégies telles que RLVR, il simplifie le processus et améliore significativement l'efficacité du traitement de documents complexes.
Le modèle OCR complet et léger haute performance « LightOnOCR-2-1B » est désormais disponible sur le site web d'HyperAI. Essayez-le !
Utilisation en ligne :https://go.hyper.ai/8zlVw
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 2 au 6 février :
* Jeux de données publics de haute qualité : 6
* Une sélection de tutoriels de haute qualité : 9
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en février : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de tâches génératives multi-domaines RubricHub
RubricHub est un jeu de données de tâches génératives multidomaines à grande échelle, publié conjointement par Li Auto et l'Université du Zhejiang. Ce jeu de données fournit une supervision de haute qualité basée sur des critères de notation pour les tâches génératives ouvertes. Il est construit à l'aide d'un cadre de génération automatisé de critères de notation, allant du grossier au fin, intégrant des stratégies telles que la synthèse guidée par des principes, l'agrégation multi-modèles et l'évolution de la difficulté afin de produire des critères d'évaluation complets et hautement discriminants.
Utilisation directe :https://go.hyper.ai/g3Htm
2. Nemotron-Personas-Brazil Ensemble de données de personnages synthétiques brésiliens
Nemotron-Personas-Brazil est un ensemble de données de personnages synthétiques pour le Brésil, développé par NVIDIA en collaboration avec WideLabs. Il vise à illustrer la diversité et la richesse de la population brésilienne afin de refléter plus fidèlement la répartition multidimensionnelle potentielle de cette population, notamment la diversité régionale, l'origine ethnique, le niveau d'éducation et la répartition professionnelle.
Utilisation directe :https://go.hyper.ai/7xKKH
3. Banc d'évaluation de l'apprentissage contextuel CL-bench
CL-bench est un jeu de données de référence permettant d'évaluer les capacités d'apprentissage contextuel d'un modèle de langage de grande taille. Développé conjointement par l'équipe Tencent Hunyuan et l'université Fudan, il vise à tester la capacité d'un modèle à apprendre de nouvelles règles, de nouveaux concepts ou de nouvelles connaissances du domaine à partir d'un contexte donné, sans recourir à des connaissances pré-entraînées, et à les appliquer à des tâches ultérieures.
Utilisation directe :https://go.hyper.ai/w2MG3
4. Ensemble de données de génération vidéo de robot RoVid-X
RoVid-X est un ensemble de données de génération de vidéos de robots publié par l'Université de Pékin en collaboration avec ByteDance Seed, visant à résoudre les problèmes physiques rencontrés par les modèles de génération vidéo lors de la création de vidéos de robots.
Utilisation directe :https://go.hyper.ai/4P9hI
5. Ensemble de données d'images Google Street View National Street View
Google Street View est un ensemble de données d'images de rues couvrant plusieurs pays. Le nom des fichiers image inclut la date de création et le nom de la carte, et les images de chaque pays sont placées dans leurs dossiers respectifs.
Utilisation directe :https://go.hyper.ai/tZRlI

6. Ensemble de données d'évaluation des capacités de planification à long terme de DeepPlanning
DeepPlanning est un ensemble de données publié par l'équipe Qwen pour évaluer les capacités de planification des agents intelligents, dans le but d'évaluer leurs capacités de raisonnement et de prise de décision dans des tâches de planification complexes et à long terme.
Utilisation directe :https://go.hyper.ai/yywsb
Tutoriels publics sélectionnés
1. Déployer Qwen-Image-Edit à l'aide de vLLM-Omni
Qwen-Image-Edit est un modèle d'édition d'images multifonctionnel développé par l'équipe Tongyi Qianwen d'Alibaba. Ce modèle offre des fonctionnalités d'édition à la fois sémantiques et visuelles, permettant des modifications visuelles de bas niveau (ajout, suppression ou modification d'éléments) ainsi que des modifications sémantiques visuelles de haut niveau (création d'IP, rotation d'objets et transfert de style). Il prend en charge l'édition précise de textes chinois et anglais, permettant la modification directe du contenu textuel des images tout en préservant la police, la taille et le style d'origine.
Exécutez en ligne :https://go.hyper.ai/DowYs
2. Déployer l'image Qwen-Image-2512 à l'aide de vLLM-Omni
Qwen-Image-2512 est le modèle de base de conversion texte-image de la série Qwen-Image. Par rapport aux versions précédentes, Qwen-Image-2512 a bénéficié d'une optimisation systématique sur plusieurs points clés, visant à améliorer le réalisme et l'ergonomie des images générées. Le rendu des portraits est nettement plus naturel : la structure du visage, le grain de peau et l'éclairage se rapprochent davantage des effets photographiques réalistes. Dans les scènes naturelles, le modèle génère des textures de terrain plus détaillées, des détails de végétation et des informations haute fréquence comme le pelage des animaux. Parallèlement, ses capacités de génération de texte et de typographie ont été améliorées, permettant un affichage plus stable des textes lisibles et des mises en page complexes.
Exécutez en ligne :https://go.hyper.ai/Xk93p
3. Étape 3-VL-10B : Compréhension visuelle multimodale et dialogue graphique
STEP3-VL-10B est un modèle de langage visuel open source développé par l'équipe Stepping Star, conçu spécifiquement pour la compréhension multimodale et les tâches de raisonnement complexes. Ce modèle vise à redéfinir l'équilibre entre efficacité, capacité de raisonnement et qualité de la compréhension visuelle au sein d'une échelle de paramètres limitée à 10 milliards (10B). Il démontre des performances supérieures en perception visuelle, en raisonnement complexe et en alignement avec les instructions humaines, surpassant systématiquement les modèles d'échelle similaire dans de nombreux tests de référence et se rapprochant des modèles dont l'échelle de paramètres est 10 à 20 fois plus importante sur certaines tâches.
Exécutez en ligne :https://go.hyper.ai/ZvOV0
4.vLLM+Open WebUI Déploiement de GLM-4.7-Flash
GLM-4.7-Flash est un modèle d'inférence MoE léger, développé par Zhipu AI, conçu pour offrir un équilibre optimal entre hautes performances et débit élevé. Il prend en charge nativement les chaînes de pensée, les appels d'outils et les capacités des agents. Son architecture hybride experte et ses mécanismes d'activation parcimonieux permettent de réduire considérablement la charge de calcul d'une inférence, tout en conservant les performances des modèles de grande taille.
Exécutez en ligne :https://go.hyper.ai/bIopo

5. LightOnOCR-2-1B : Modèle OCR complet, léger et haute performance
LightOnOCR-2-1B est la dernière génération de modèle de reconnaissance optique de caractères (OCR) de bout en bout développé par LightOn AI. Version phare de la série LightOnOCR, il unifie la compréhension de documents et la génération de texte au sein d'une architecture compacte, prend en charge un milliard de paramètres et fonctionne sur des GPU grand public (nécessitant environ 6 Go de VRAM). Ce modèle utilise une architecture de type Transformer pour la reconnaissance visuelle et intègre la technologie d'apprentissage par renforcement (RLVR), ce qui lui permet d'atteindre une précision de reconnaissance et une vitesse d'inférence extrêmement élevées. Il est spécialement conçu pour les applications nécessitant le traitement de documents complexes, de textes manuscrits et de formules LaTeX.
Exécutez en ligne :https://go.hyper.ai/8zlVw
6. vLLM+Déploiement de l'interface utilisateur Web ouverte de LFM2.5-1.2B-Thinking
LFM2.5-1.2B-Thinking est le dernier modèle d'architecture hybride optimisé pour le traitement en périphérie (edge computing) de Liquid AI. Version de la série LFM2.5 spécifiquement optimisée pour l'inférence logique, il combine le traitement de longues séquences et des capacités d'inférence performantes dans une architecture compacte. Ce modèle, doté de 1,2 milliard de paramètres, fonctionne de manière fluide sur les GPU grand public et même sur les appareils périphériques. Son architecture hybride innovante offre une efficacité mémoire et un débit exceptionnels, et il est conçu pour les scénarios nécessitant une inférence en temps réel sur les appareils, sans compromis sur l'intelligence.
Exécutez en ligne :https://go.hyper.ai/PACIr
7. TurboDiffusion : Système de génération vidéo piloté par image et texte
TurboDiffusion est un système de génération de diffusion vidéo haute performance développé par une équipe de l'Université Tsinghua. Basé sur une architecture 2.1, ce projet utilise la distillation d'ordre élevé pour pallier les problèmes de lenteur d'inférence et de forte consommation de ressources de calcul dans les modèles vidéo à grande échelle, permettant ainsi une génération vidéo de haute qualité en un minimum d'étapes.
Exécutez en ligne :https://go.hyper.ai/YjCht
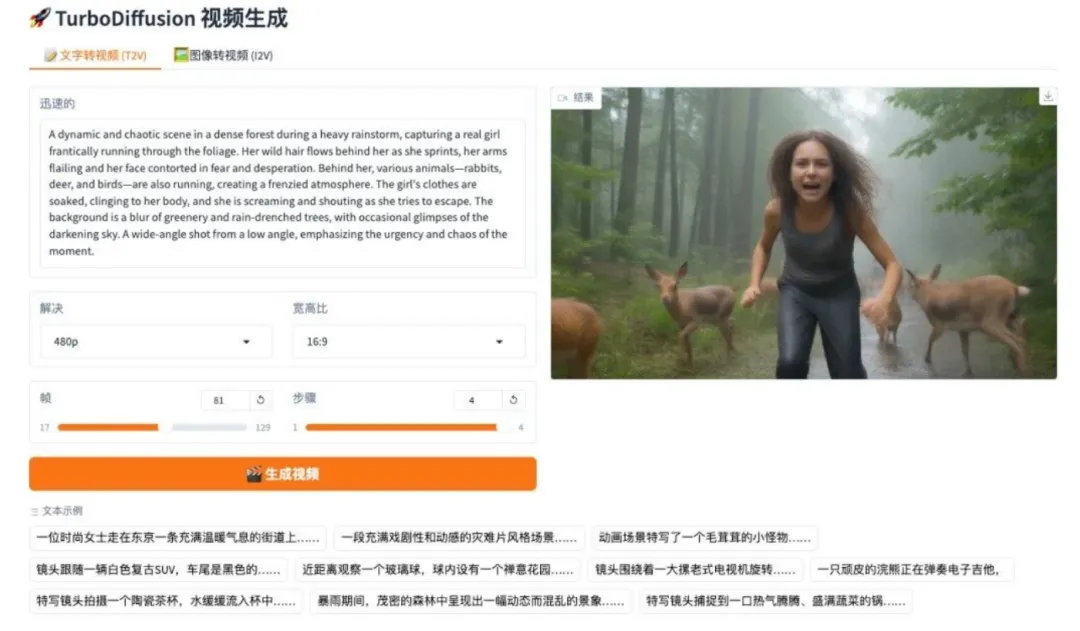
8. Flux causal visuel DeepSeek-OCR 2
DeepSeek-OCR 2 est le modèle OCR de deuxième génération développé par l'équipe DeepSeek. Grâce à l'architecture DeepEncoder V2, il opère un changement de paradigme, passant d'une lecture fixe à un raisonnement sémantique. Le modèle utilise l'interrogation de flux causaux et un mécanisme d'attention à double flux pour réorganiser dynamiquement les jetons visuels, reconstruisant ainsi plus précisément la logique de lecture naturelle des documents complexes. Lors de l'évaluation OmniDocBench v1.5, le modèle a obtenu un score global de 91,09%, une amélioration significative par rapport à son prédécesseur, tout en réduisant considérablement le taux de répétition des résultats OCR. Il ouvre ainsi la voie à la conception future d'un encodeur multimodal.
Exécutez en ligne :https://go.hyper.ai/ITInm
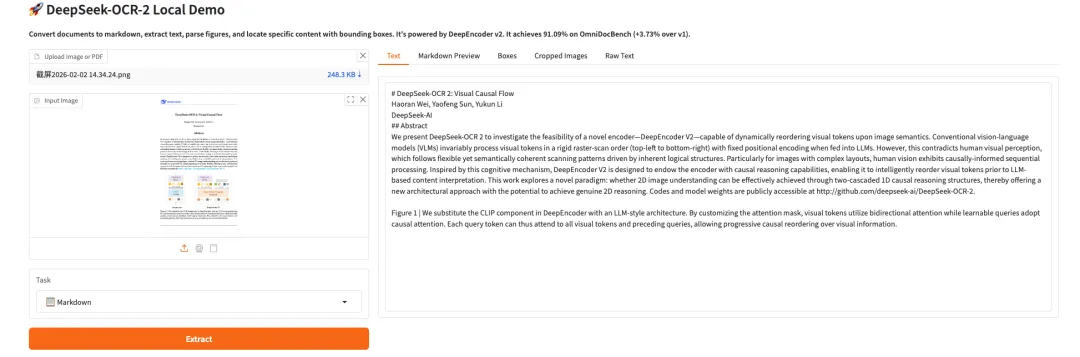
9. Personaplex-7B-v1 : Interface vocale de dialogue en temps réel et personnalisée pour chaque personnage
PersonaPlex-7B-v1 est un modèle de dialogue personnalisé multimodal à 7 milliards de paramètres, développé par NVIDIA. Conçu pour l'interaction voix/texte en temps réel, la simulation de la cohérence des personnages sur le long terme et les tâches de perception multimodale, il vise à fournir un système de démonstration immersif de jeu de rôle et d'interaction multimodale avec une vitesse de réponse de l'ordre de la milliseconde.
Exécutez en ligne :https://go.hyper.ai/ndoj0
Recommandation de papier de cette semaine
1. Apprentissage par renforcement collaboratif multi-agents en temps de test pour le raisonnement
Cet article propose MATTRL, un cadre d'apprentissage par renforcement en phase de test qui améliore le raisonnement multi-agents en intégrant une expérience textuelle structurée au processus de raisonnement. Il permet d'atteindre un consensus grâce à la collaboration d'une équipe multi-experts et à une répartition des crédits tour par tour, et obtient des améliorations significatives des performances sur des benchmarks médicaux, mathématiques et éducatifs sans nécessiter de réentraînement.
Lien vers l'article :https://go.hyper.ai/ENmkT
2. A^3-Bench : Évaluation comparative du raisonnement scientifique basé sur la mémoire via l’activation d’ancres et d’attracteurs
Cet article propose A³-Bench, un banc d'essai de raisonnement scientifique à double échelle basé sur la mémoire. Il évalue l'activation des ancres et des attracteurs à l'aide du cadre d'annotation SAPM et de la métrique AAUI, révélant comment l'utilisation de la mémoire peut améliorer la cohérence du raisonnement au-delà de la cohérence standard ou de la précision des réponses.
Lien vers l'article :https://go.hyper.ai/Ao5t9
3. PaCoRe : Apprendre à faire évoluer le calcul en temps réel grâce au raisonnement coordonné parallèle
Cet article propose PaCoRe, un cadre d'inférence collaborative parallèle qui permet une mise à l'échelle massive du calcul en temps réel (TTC) grâce à l'échange de messages entre plusieurs itérations de trajectoires d'inférence parallèles. Il surpasse GPT-5 (93,2%) avec une précision de 94,5% sur HMMT 2025. Il intègre efficacement le processus d'inférence de millions de jetons dans un contexte donné, tout en rendant le modèle et les données accessibles en open source afin de favoriser le développement de systèmes d'inférence évolutifs.
Lien vers l'article :https://go.hyper.ai/fQrnt
4. Attribution de mouvement pour la génération vidéo
Cet article propose Motive, un cadre d'attribution de données centré sur le mouvement et basé sur le gradient, qui dissocie la dynamique temporelle de l'apparence statique grâce à un masque de perte pondéré par le mouvement. Ceci permet une reconnaissance évolutive des segments influençant le réglage fin, améliorant ainsi la fluidité du mouvement et la plausibilité physique dans la génération de vidéos à partir de texte. Il atteint un taux de préférence humaine de 74,11 % (TP3T) sur VPench.
Lien vers l'article :https://go.hyper.ai/2pU21
5. VIBE : Éditeur basé sur des instructions visuelles
Cet article propose VIBE, un flux de travail compact d'édition d'images basé sur des instructions. VIBE utilise un modèle Qwen3-VL à 2 milliards de paramètres pour le guidage et un modèle de diffusion Sana1.5 à 1,6 milliard de paramètres pour la génération. Il permet une édition de haute qualité préservant rigoureusement la cohérence de l'image source, pour un coût de calcul extrêmement faible. Fonctionnant efficacement sur 24 Go de mémoire GPU, il génère une image 2K sur un H100 en seulement 4 secondes environ, atteignant des performances égales, voire supérieures, à celles de modèles de référence plus volumineux.
Lien vers l'article :https://go.hyper.ai/8YMEO
Interprétation des articles communautaires
1. Après avoir analysé 100 millions de points de données du télescope spatial Hubble en 3 jours, l'Agence spatiale européenne a proposé AnomalyMatch, découvrant plus d'un millier d'objets célestes anormaux.
Actuellement, les relevés du ciel à grande échelle, multibandes, à large champ de vision et à haute profondeur, propulsent l'astronomie dans une ère de traitement des données sans précédent. L'un de ses principaux atouts scientifiques réside dans la découverte et l'identification systématiques d'objets célestes rares présentant un intérêt astrophysique particulier. Cependant, leur découverte a longtemps reposé en grande partie sur l'identification visuelle fortuite par les chercheurs ou sur un tri manuel effectué par des projets de sciences participatives. Ces méthodes sont non seulement très subjectives et inefficaces, mais aussi mal adaptées à l'échelle massive des données à venir. Pour pallier cette lacune, une équipe de recherche du Centre européen d'astronomie spatiale (ESAC), une branche de l'Agence spatiale européenne (ESA), a proposé et appliqué une nouvelle méthode appelée AnomalyMatch.
Voir le rapport complet :https://go.hyper.ai/Jm3aq
2. Résumé des ensembles de données | 16 ensembles de données d'intelligence incarnée couvrant la préhension, la réponse aux questions, le raisonnement logique, le raisonnement sur les trajectoires et d'autres domaines.
Si, ces dix dernières années, le principal enjeu de l'intelligence artificielle a été la « compréhension du monde » et la « génération de contenu », la question centrale de la prochaine étape se déplace vers un défi plus complexe : comment l'IA peut-elle véritablement s'intégrer au monde physique et y agir, apprendre et évoluer ? Dans les recherches et les discussions connexes, le terme « intelligence incarnée » apparaît fréquemment. Comme son nom l'indique, l'intelligence incarnée ne se limite pas à un robot traditionnel, mais met plutôt l'accent sur l'intelligence issue de l'interaction entre l'agent et son environnement, au sein d'une boucle fermée de perception, de prise de décision et d'action. Cet article recense et recommande de manière systématique tous les jeux de données de haute qualité actuellement disponibles concernant l'intelligence incarnée, offrant ainsi une référence pour les recherches et les apprentissages futurs.
Voir le rapport complet :https://go.hyper.ai/lsCyF
3. Tutoriel en ligne | Améliorations de l'analyse des formules/tableaux de DeepSeek-OCR 2 : gain de performance de près de 41 TP3T avec un faible coût de jetons visuels
Dans le développement des modèles de langage visuel (MLV), la reconnaissance optique de caractères (OCR) de documents s'est toujours heurtée à des défis majeurs tels que l'analyse syntaxique de mises en page complexes et l'alignement de la logique sémantique. Permettre aux modèles de « comprendre » la logique visuelle comme les humains représente une avancée cruciale pour l'amélioration de la compréhension des documents. Récemment, DeepSeek-OCR 2 de DeepSeek-AI a apporté une nouvelle réponse. Son principal atout réside dans l'adoption de la nouvelle architecture DeepEncoder V2 : le modèle abandonne l'encodeur visuel CLIP traditionnel et introduit un paradigme d'encodage visuel de type LLM. Grâce à la fusion de l'attention bidirectionnelle et de l'attention causale, il réalise un réarrangement sémantique des jetons visuels, ouvrant la voie à un nouveau raisonnement causal unidimensionnel en deux étapes pour la compréhension d'images bidimensionnelles.
Voir le rapport complet :https://go.hyper.ai/nMH13
4. Couvrant 19 scénarios, dont l'astrophysique, les sciences de la Terre, la rhéologie et l'acoustique, Polymathic AI construit 1,3 milliard de modèles pour obtenir une simulation précise des milieux continus.
Dans les domaines du calcul scientifique et de la simulation d'ingénierie, la prédiction efficace et précise de l'évolution des systèmes physiques complexes a toujours constitué un défi majeur pour la recherche académique et industrielle. Parallèlement, les avancées en apprentissage profond dans le traitement automatique du langage naturel et la vision par ordinateur ont incité les chercheurs à explorer les applications potentielles des « modèles fondamentaux » dans les simulations physiques. Cependant, les systèmes physiques évoluent souvent sur de multiples échelles de temps et d'espace, tandis que la plupart des modèles d'apprentissage sont généralement entraînés uniquement sur la dynamique à court terme. Utilisés pour des prédictions à long terme, ces modèles présentent une accumulation d'erreurs dans les systèmes complexes, entraînant une instabilité. Partant de ce constat, une équipe de recherche de la collaboration Polymathic AI a proposé Walrus, un modèle fondamental comportant 1,3 milliard de paramètres, une architecture basée sur les Transformers et principalement conçu pour la dynamique des milieux continus de type fluide.
Voir le rapport complet :https://go.hyper.ai/MJrny
Articles populaires de l'encyclopédie
1. Tri inverse combiné au RRF
2. Théorème de représentation de Kolmogorov-Arnold
3. Compréhension du langage multitâche à grande échelle (MMLU)
4. Optimiseurs de boîte noire
5. Probabilité conditionnelle de classe
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








