Command Palette
Search for a command to run...
FLUX.2-klein-4B : Génère Des Images En Moins D’une Seconde En 4 Étapes Grâce À La Distillation, Permettant Une Interaction En Temps Réel Sur Des GPU Grand Public ; Jeu De Données Vehicles OpenImages : Se Concentre Sur La Détection Et La Localisation Des véhicules.

Actuellement, bien que les modèles de génération d'images les plus courants puissent produire des résultats de haute qualité, ils souffrent de vitesses d'inférence lentes, de besoins élevés en mémoire et d'un mode d'interaction qui reste bloqué à l'ère des « outils hors ligne ». Les utilisateurs ne peuvent qu'attendre passivement après avoir saisi des instructions et ne peuvent pas obtenir de réponse et d'interaction en temps réel.Cela limite l'application de l'IA dans des scénarios tels que la conception en temps réel et le prototypage rapide.
Dans ce contexte,Black Forest Labs a publié le modèle open-source FLUX.2-klein-4B, qui compresse les étapes d'inférence à 4 étapes grâce à la distillation des étapes, réalisant une inférence de bout en bout inférieure à la seconde (≤0,5 s).Son architecture unifiée prend en charge la conversion texte-image, image-image et la génération multi-référence, simplifiant ainsi le passage d'un modèle à l'autre. Elle ne nécessite qu'environ 13 Go de mémoire vidéo pour fonctionner efficacement sur les GPU grand public et prend en charge la quantification FP8/NVFP4, ce qui accroît encore la vitesse jusqu'à 2,7 fois. Elle transforme la génération d'images par IA, autrefois un outil hors ligne complexe, en un collaborateur réactif en temps réel, offrant une solution légère et performante pour des applications telles que la conception en temps réel et l'édition interactive.
Le site web d'HyperAI propose désormais « FLUX.2-klein-4B : un modèle de génération d'images à haute vitesse », alors n'hésitez pas à l'essayer !
Utilisation en ligne :https://go.hyper.ai/N7D6c
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 26 au 30 janvier :
* Jeux de données publics de haute qualité : 7
* Une sélection de tutoriels de haute qualité : 6
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en février : 6
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Données d'images de véhicules OpenImages
Vehicles OpenImages provient du vaste ensemble de données publiques OpenImages de Google et se concentre sur la détection et la localisation des véhicules, dans le but de soutenir l'entraînement rapide et efficace des modèles de détection de véhicules.
Utilisation directe :https://go.hyper.ai/Y8nUj

2. Base de données sur la pneumonie par radiographie thoracique
Le jeu de données « Pneumonie sur radiographie thoracique » est constitué de caractéristiques numériques extraites d'images radiographiques du thorax. Ce jeu de données permet l'analyse statistique et l'apprentissage automatique classique en transformant chaque image en caractéristiques numériques structurées, notamment des statistiques d'intensité globale, des descripteurs de texture (GLCM), des caractéristiques du domaine fréquentiel (FFT), des métriques basées sur les contours et des caractéristiques LBP (Local Binary Pattern).
Utilisation directe :https://go.hyper.ai/RNgZD
3. Diabète Mexique (Ensemble de données sur le diabète au Mexique)
Diabetes Mexico est un ensemble de données sur le diabète publié par l'Institut national de santé publique (INSP) du Mexique. Il repose sur les données de l'Enquête nationale sur la santé et la nutrition (ENSANUT) de 2024 et vise à évaluer les facteurs de risque métaboliques associés au diabète au sein de la population mexicaine.
Utilisation directe :https://go.hyper.ai/2L4uw
4. Indice de qualité de l'air (IQA) de Delhi (Données sur la qualité de l'air de Delhi)
L'indice de qualité de l'air (IQA) de Delhi est un ensemble de données environnementales destiné à l'analyse et à la prévision de la qualité de l'air. Cet ensemble de données fournit des données horaires sur la qualité de l'air et l'environnement pour les principales villes de la région de Delhi-NCR, et convient à l'analyse de la pollution, aux prévisions de séries temporelles et aux applications d'apprentissage automatique.
Utilisation directe :https://go.hyper.ai/cNuok
5. Ensemble de données de transcription de texte LightOnOCR-mix-0126
LightOnOCR-mix-0126 est un ensemble de données de transcription de texte OCR à grande échelle publié par LightOn, conçu pour fournir une supervision pour les modèles OCR de bout en bout et de compréhension de documents, produisant un texte transcrit de page entière naturellement ordonné.
Utilisation directe :https://go.hyper.ai/tZRlI
6. Signal sonar (Ensemble de données de signaux sonar sous-marins)
Sonar Signal est un ensemble de données de signaux sonar utilisés pour la classification d'objets sous-marins. Cet ensemble de données convient aux tâches de classification binaire, visant à déterminer si un signal sonar provient de rochers ou d'un puits de mine.
Utilisation directe :https://go.hyper.ai/uXIom
7. Ensemble de données étiquetées des gestes de la main pour un jeu de voiture
Hand Gestures Labbled est un ensemble de données d'images pour jeux de voiture basés sur les gestes, conçu pour entraîner des modèles d'apprentissage automatique pour les commandes gestuelles dans ce type de jeux. L'ensemble contient 330 images réparties en quatre catégories de gestes : gauche, avancer, droite et s'arrêter.
Utilisation directe :https://go.hyper.ai/sZmIc
Tutoriels publics sélectionnés
1. WeDLM : un cadre de décodage de modèles de langage de grande taille et à haute efficacité
WeDLM (Window-based Efficient Decoding for Large Models) est un framework de décodage de modèles de langage de grande taille et à haute efficacité, développé par Tencent. Il est conçu pour doter les systèmes de dialogue IA de nouvelle génération de capacités de génération de langage ultra-rapides, intelligentes et hautement adaptatives. Ce framework utilise une architecture de décodage parallèle innovante basée sur des fenêtres, ce qui permet d'améliorer considérablement la vitesse de décodage tout en préservant une génération de texte de haute qualité. Son avancée technologique majeure réside dans l'intégration de la prise de décision par seuil d'entropie et de mécanismes de pénalité positionnelle, résolvant ainsi le problème de la limitation de vitesse du décodage autorégressif traditionnel lors de la génération de longues séquences.
Exécutez en ligne :https://go.hyper.ai/Cfahp
2. FLUX.2-klein-4B : Modèle de génération d’images ultra-rapide
FLUX.2-klein-4B est le tout dernier modèle de génération d'images ultrarapide de Black Forest Labs. Basé sur l'architecture Rectified Flow, il utilise une conception Transformer distillée à 4 milliards de paramètres, unifiant les capacités d'édition d'images textuelles et multi-références au sein d'un modèle compact. Il ne nécessite qu'environ 13 Go de mémoire GPU et peut atteindre des vitesses d'inférence de bout en bout inférieures à 1 seconde sur les GPU grand public.
Exécutez en ligne :https://go.hyper.ai/N7D6c
3. Agent de diagnostic DiagGym
DiagAgent, un agent de diagnostic (7B, 8B, 14B) développé par l'équipe AI4Med de l'Université Jiao Tong de Shanghai et du Laboratoire d'intelligence artificielle de Shanghai, gère proactivement le parcours diagnostique. Il sélectionne les examens les plus pertinents, décide du moment opportun pour les interrompre et fournit un diagnostic final précis. Contrairement aux modèles médicaux traditionnels de grande taille qui ne donnent qu'une réponse unique, DiagAgent peut recommander des examens pertinents et adapter le diagnostic au cours d'échanges successifs, ne fournissant un diagnostic final que lorsque suffisamment d'informations sont recueillies. DiagAgent est optimisé dans l'environnement DiagGym grâce à un apprentissage par renforcement multi-tours de bout en bout (GRPO). À chaque interaction, l'agent commence par une consultation initiale, interagit avec DiagGym en recommandant des examens et en recevant les résultats de simulation, puis décide du moment opportun pour établir un diagnostic final.
Exécutez en ligne :https://go.hyper.ai/FzOau
4. Pocket-TTS : Un système de synthèse vocale en streaming de haute qualité et léger
Pocket-TTS est un modèle de synthèse vocale ultra-léger développé par Kyutai Labs. Ce modèle privilégie une faible latence et une sortie en flux continu, afin de fournir des capacités de génération vocale de haute qualité pour les environnements aux ressources limitées ou les scénarios nécessitant une interaction en temps réel (comme les assistants vocaux IA).
Exécutez en ligne :https://go.hyper.ai/CwgHo
5. Tutoriel sur le compilateur Triton
Triton est un langage et un compilateur pour la programmation parallèle, conçu pour fournir un environnement de programmation basé sur Python permettant d'écrire efficacement des noyaux de calcul DNN personnalisés capables de fonctionner à débit maximal sur du matériel GPU.
Exécutez en ligne :https://go.hyper.ai/Xqd8j
6. Tutoriel TVM 0.22.0
Apache TVM est un framework de compilation open source pour l'apprentissage automatique destiné aux CPU, aux GPU et aux accélérateurs d'apprentissage automatique, conçu pour permettre aux ingénieurs en apprentissage automatique d'optimiser et d'exécuter efficacement des calculs sur n'importe quel matériel.
Exécutez en ligne :https://go.hyper.ai/s3yot
Recommandation de papier de cette semaine
1. Récompenser l'exceptionnel : apprentissage par renforcement tenant compte de l'unicité pour la résolution créative de problèmes dans les masters en droit
Cet article propose une méthode d'apprentissage par renforcement prenant en compte l'unicité des solutions. La méthode conçoit une fonction objectif au niveau du déploiement et récompense les stratégies de raisonnement de haut niveau rares en pondérant la taille du clustering et du clustering inverse à l'aide d'un modèle de langage étendu (LLM). Ceci améliore significativement la diversité des solutions et les performances pass@k sur des benchmarks de raisonnement mathématique, physique et médical, sans compromettre pass@1.
Lien vers l'article :https://go.hyper.ai/k5A3R
2. DeepResearchEval : un cadre automatisé pour la construction de tâches de recherche approfondie et l’évaluation par agents
Cet article propose DeepResearchEval, un cadre automatisé qui génère des tâches de recherche approfondie réalistes et complexes grâce à des approches basées sur les rôles et utilise des mécanismes d'évaluation de la qualité adaptatifs et spécifiques à la tâche, ainsi que des mécanismes de vérification proactive des faits, pour évaluer les agents à partir de modèles de langage de grande taille. Ceci permet la vérification d'affirmations sans citations, autorisant ainsi une évaluation fiable des systèmes de recherche en réseau à plusieurs étapes.
Lien vers l'article :https://go.hyper.ai/b92V4
3. Auto-évolution contrôlée pour l'optimisation algorithmique du code
Cet article propose une méthode d'auto-évolution contrôlée (CSE) qui améliore l'efficacité de la génération de code en permettant la réutilisation de l'expérience grâce à une initialisation diversifiée, des opérations génétiques guidées par le retour d'information et une mémoire hiérarchique. Elle permet une exploration efficace et une optimisation continue de divers réseaux LLM sur le benchmark EffiBench-X.
Lien vers l'article :https://go.hyper.ai/RJHUC
4. MMFormalizer : Autoformalisation multimodale en conditions réelles
Cet article propose MMFORMALIZER, un nouveau cadre de formalisation automatique multimodal qui combine la localisation adaptative avec des primitives perceptives pour construire récursivement des propositions avec des fondements formels dans des axiomes mathématiques et physiques, permettant un raisonnement machine dans des domaines tels que la mécanique classique, la relativité, la mécanique quantique et la thermodynamique, et démontrant une évolutivité sur le benchmark PHYX-AF.
Lien vers l'article :https://go.hyper.ai/mC7NC
5. MAXS : Exploration méta-adaptative avec des agents LLM
Cet article propose MAXS, un cadre de raisonnement méta-adaptatif pour les agents de modèles de langage de grande taille (LLM). En introduisant des mécanismes de planification anticipée et de convergence de trajectoire, il atténue les problèmes de vision à court terme locale et d'instabilité du raisonnement. Combiné à l'estimation des avantages et à la sélection de la taille du pas basée sur la cohérence, il permet un raisonnement multi-outils efficace, stable et performant.
Lien vers l'article :https://go.hyper.ai/Wrhke
Interprétation des articles communautaires
1. De Moltrbot aux dividendes politiques, une « entreprise d'IA à une seule personne » à l'avant-garde de la tendance peut-elle devenir une grande et forte entreprise ?
Avec la diffusion croissante d'outils technologiques tels que ChatGPT, les outils de conception d'IA et les systèmes d'analyse de données intelligents, l'univers des startups connaît une révolution de l'efficacité sans précédent. Clawdbot (rebaptisé Moltrbot), devenu viral récemment, est perçu comme un assistant personnel open source en passe de révolutionner la productivité d'ici 2026. Cet agent IA, présenté comme un « assistant personnel de haut niveau », a fait sensation dans la Silicon Valley, son nombre d'étoiles sur GitHub atteignant 57 500 en seulement trois jours après son lancement. Plus important encore, cette nouvelle forme de startup bénéficie d'un soutien politique favorable. Dès 2016, les « Avis du Conseil d'État sur la promotion du développement durable et sain du capital-risque » encourageaient explicitement les personnes disposant de capitaux et d'une expérience en gestion à s'engager dans des activités de capital-risque en créant légalement des entreprises unipersonnelles.
Voir le rapport complet :https://go.hyper.ai/2hKRe
2. Skild AI, une startup de robotique, lève 1,4 milliard de dollars avec la participation de SoftBank, Nvidia, Sequoia Capital et Bezos, entre autres, pour développer des modèles de base à usage général.
À la mi-janvier 2026, la startup de robotique Skild AI annonçait la finalisation d'une levée de fonds de série C d'environ 1,4 milliard de dollars, valorisant l'entreprise à plus de 14 milliards de dollars. Ce tour de table était mené par le groupe japonais SoftBank, avec la participation d'investisseurs stratégiques tels que NVentures (filiale de Nvidia), Macquarie Capital et Bezos Expeditions (fondée par Jeff Bezos, fondateur d'Amazon). Samsung, LG, Schneider Electric et Salesforce Ventures y ont également participé. Alors que le matériel robotique est encore en pleine évolution et que les applications restent très fragmentées, les capitaux se sont massivement et quasi simultanément concentrés sur quelques entreprises qui ne se contentent pas de fabriquer des robots. Ceci reflète, dans une certaine mesure, la nature lucrative des investissements et confirme que cette startup, créée il y a moins de trois ans, a fait le choix d'une voie prometteuse.
Voir le rapport complet :https://go.hyper.ai/iYHbK
3. AlphaGenome fait la une de Nature ! Prédit les effets de la variation sur toutes les modalités et tous les types cellulaires en moins d'une seconde.
En juin 2025, Google DeepMind a lancé AlphaGenome. Ce modèle prend en entrée des séquences d'ADN pouvant atteindre un million de paires de bases et prédit des milliers de propriétés moléculaires liées à leurs activités de régulation. Il peut également évaluer l'impact des variations ou mutations génétiques en comparant les prédictions de séquences mutées et non mutées. L'une des avancées majeures d'AlphaGenome réside dans sa capacité à « prédire directement les jonctions d'épissage à partir des séquences et à les utiliser pour prédire l'effet des variations ». Le Dr Caleb Lareau, du Memorial Sloan Kettering Cancer Center, a déclaré : « Il s'agit d'une étape importante dans ce domaine. Pour la première fois, nous disposons d'un modèle qui allie contexte étendu, précision à la base près et performances de pointe, couvrant un large éventail de tâches génomiques. »
Voir le rapport complet :https://go.hyper.ai/jgO8K
4. Sur la base de milliards de gènes provenant d'un million d'espèces, NVIDIA et d'autres ont construit la série de modèles EDEN, atteignant des capacités de prédiction de génome et de protéines de pointe (SOTA).
L'objectif fondamental de la biologie programmable est de concevoir rationnellement et de réguler précisément les systèmes vivants, afin de développer des thérapies révolutionnaires pour les maladies complexes. Cependant, ce processus est depuis longtemps limité par la complexité inhérente des systèmes biologiques. Sa capacité de généralisation est fortement insuffisante face à la conception de thérapies innovantes multimodales et multi-échelles. Pour surmonter cette limitation fondamentale, Basecamp Research, NVIDIA et plusieurs institutions académiques de premier plan ont développé conjointement la série EDEN de modèles métagénomiques de base.
Voir le rapport complet :https://go.hyper.ai/jPS42
5. L'Université de Californie a construit un spectromètre sur puce basé sur un réseau neuronal entièrement connecté, atteignant une résolution spectrale de 8 nanomètres à l'échelle d'une puce.
Aujourd'hui, les appareils photo des smartphones atteignent des résolutions de plusieurs mégapixels, mais ils ne peuvent toujours pas analyser la composition chimique des substances comme le font les spectromètres professionnels. Cette lacune s'explique par l'absence d'un composant essentiel dans les smartphones et autres appareils : un spectromètre capable de lire avec précision la « signature spectrale » unique d'une substance. Les spectromètres traditionnels, outils importants pour l'analyse des substances, fonctionnent en séparant la lumière composite en spectres de différentes longueurs d'onde, puis en identifiant la composition de la substance grâce à ses raies spectrales caractéristiques. Cependant, ils se heurtent à un obstacle majeur : la miniaturisation exige l'abandon des structures dispersives traditionnelles ; or, sans ces structures, comment obtenir des informations spectrales ? Pour relever ce défi, une équipe de recherche de l'Université de Californie a proposé une solution innovante : concevoir une structure de piégeage de photons (PTST) spéciale à la surface d'une photodiode en silicium standard et y intégrer un réseau neuronal entièrement connecté, hautement résistant au bruit.
Voir le rapport complet :https://go.hyper.ai/bYwq8
Articles populaires de l'encyclopédie
1. Images par seconde (IPS)
2. Fusion par tri inversé RRF
3. Modèle de langage visuel (VLM)
4. Hyperréseaux
5. Attention contrôlée
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
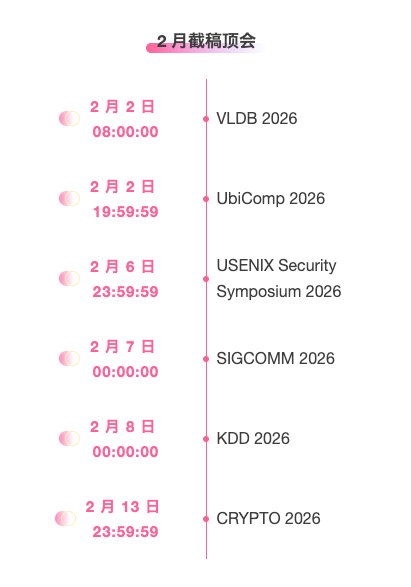
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








