Command Palette
Search for a command to run...
GPT-5 Domine Tous Les Domaines ; OpenAI Lance FrontierScience, Utilisant Une Double Approche « inférence + Recherche » Pour Tester Les Capacités Des Modèles À Grande échelle.
À mesure que les capacités de raisonnement et de connaissance des modèles continuent de s'améliorer, des tests de référence plus exigeants sont essentiels pour mesurer et prédire la capacité d'un modèle à accélérer la recherche scientifique. Le 16 décembre 2025, OpenAI a lancé FrontierScience, un outil de référence conçu pour mesurer les capacités scientifiques de niveau expert.Selon les évaluations préliminaires, GPT-5.2 a obtenu un score de 25% et 77% sur les tâches FrontierScience-Olympiad et Research, respectivement, surpassant d'autres modèles de pointe.
OpenAI a déclaré dans un communiqué officiel : « L'accélération du progrès scientifique est l'une des opportunités les plus prometteuses pour l'intelligence artificielle de bénéficier à l'humanité. C'est pourquoi nous améliorons nos modèles pour les tâches mathématiques et scientifiques complexes et travaillons au développement d'outils qui peuvent aider les scientifiques à tirer le meilleur parti de ces modèles. »
Les précédents référentiels de compétences scientifiques privilégiaient les questions à choix multiples, souvent trop denses ou manquant d'une approche scientifique rigoureuse. À l'inverse, FrontierScience est rédigé et validé par des experts en physique, chimie et biologie, contrairement aux référentiels précédents.Il comprend des questions de type olympique et des questions axées sur la recherche, ce qui lui permet de mesurer à la fois le raisonnement scientifique et les capacités de recherche scientifique.En outre, FrontierScience-Research comprend 60 sous-tâches de recherche originales conçues par des scientifiques titulaires d'un doctorat, avec un niveau de difficulté comparable à celui que ces scientifiques pourraient rencontrer au cours de leurs recherches.
Concernant l'avenir et les limites des tests de performance, OpenAI a déclaré dans son rapport officiel : « FrontierScience présente la limite d'un champ d'application restreint et ne peut couvrir tous les aspects du travail quotidien des scientifiques. Cependant, le domaine a besoin de tests de performance scientifiques plus ambitieux, plus originaux et plus pertinents, et FrontierScience constitue un pas dans cette direction. »
Les résultats de ce projet de recherche ont été publiés sous le titre « FrontierScience : évaluation de la capacité de l'IA à réaliser des tâches scientifiques de niveau expert ».
Adresse du document :
https://hyper.ai/papers/7a783933efcc
Autres articles :
Consultez d'autres points de référence :

L'ensemble de données FrontierScience permet une approche à deux volets : « raisonnement + recherche ».
Dans le cadre de ce projet, l'équipe de recherche a construit l'ensemble de données d'évaluation FrontierScience afin d'évaluer systématiquement les capacités des grands modèles dans le raisonnement scientifique de niveau expert et les sous-tâches de recherche.L'ensemble de données adopte un mécanisme de conception de « création d'experts + structure de tâches à deux niveaux + mécanisme de notation automatique » pour former un référentiel d'évaluation du raisonnement scientifique stimulant, évolutif et reproductible.
Adresse du jeu de données :
https://hyper.ai/datasets/47732
En fonction des différents formats de tâches et des objectifs d'évaluation, l'ensemble de données FrontierScience est divisé en deux sous-ensembles, correspondant à deux types de capacités : le raisonnement exact fermé et le raisonnement scientifique ouvert.
* Jeu de données des Olympiades : Conçu à l’origine par des médaillés et des entraîneurs d’équipes nationales des Olympiades internationales de physique, de chimie et de biologie, avec une difficulté des problèmes comparable à celle des compétitions internationales de haut niveau telles que l’IPhO, l’IChO et l’IBO ; Axé sur des tâches de raisonnement à réponse courte, exigeant des modèles qu’ils produisent une seule valeur numérique, une expression algébrique ou une terminologie biologique pouvant être appariée de manière floue, afin de garantir la vérifiabilité des résultats et la stabilité de l’évaluation automatique.
* Base de données de recherche : Élaborées par des doctorants, des postdoctorants, des professeurs et d’autres chercheurs actifs, les questions simulent des sous-problèmes susceptibles d’être rencontrés dans la recherche scientifique réelle, couvrant les trois grands domaines que sont la physique, la chimie et la biologie. Chaque question est accompagnée d’une note détaillée sur 10 points permettant d’évaluer la performance du modèle sur plusieurs aspects clés, au-delà de la simple exactitude de la réponse : la complétude des hypothèses de modélisation, le raisonnement et les conclusions intermédiaires.
Afin de garantir l'originalité et la rigueur des questions, l'équipe de recherche les a examinées lors de la phase de test interne du modèle, en éliminant celles qui pouvaient être facilement résolues par des modèles existants afin de limiter le risque de saturation de l'évaluation. Les tâches d'entraînement se déroulent en quatre phases : création, examen, résolution et révision. Des experts indépendants examinent mutuellement leurs tâches pour s'assurer de leur conformité aux normes.Au final, l'équipe a sélectionné 160 questions open source parmi des centaines de questions candidates, tandis que les questions restantes ont été conservées en réserve pour la détection ultérieure de la pollution et une évaluation à long terme.
L'échantillonnage indépendant de sous-ensembles et d'autres modèles comme GPT-5.2 ont obtenu des scores impressionnants.
Afin d'évaluer de manière stable et reproductible la capacité de raisonnement scientifique de grands modèles sans recourir à une récupération externe, l'équipe de recherche a conçu un processus d'évaluation rigoureux et un mécanisme de notation.
Cette étude a sélectionné plusieurs grands modèles de pointe courants comme objets d'évaluation, couvrant différentes institutions et approches techniques, afin de refléter au mieux le niveau de capacité global des grands modèles à usage général actuels dans le domaine du raisonnement scientifique.Tous les modèles ont été déconnectés d'Internet pendant le processus d'évaluation afin de garantir que leurs résultats soient basés uniquement sur leurs connaissances internes et leurs capacités de raisonnement, et ne soient pas influencés par la recherche d'informations en temps réel ou par des outils externes.Cela réduit l'influence des différences de capacités d'acquisition d'informations entre les différents modèles sur les résultats.
Compte tenu du caractère aléatoire inhérent aux grands modèles dans les réponses génératives, l'équipe de recherche a effectué une analyse statistique en prenant plusieurs échantillons indépendants et en faisant la moyenne des résultats des deux sous-ensembles, Olympiade et Recherche, afin d'éviter les fluctuations aléatoires.Concernant la méthode de notation, l'article conçoit des stratégies d'évaluation automatisées pour les deux types de tâches, en tenant compte de leurs différentes caractéristiques :
* Sous-ensemble FrontierScience-Olympiad : met l’accent sur le raisonnement fermé, la notation étant principalement basée sur la détermination de l’équivalence des réponses, autorisant des approximations numériques dans une plage d’erreur raisonnable, des transformations équivalentes d’expressions algébriques et une correspondance floue des termes ou des noms dans les questions biologiques, tout en évitant une sensibilité excessive à la forme d’expression ;
* Sous-ensemble FrontierScience-Research : simulant fidèlement des sous-tâches de recherche réelles, où chaque question décompose le raisonnement scientifique en plusieurs étapes clés indépendantes et vérifiables. Les réponses du modèle sont évaluées élément par élément selon des grilles d’évaluation, et non uniquement sur la base de l’exactitude de la conclusion finale.
Globalement, le test de performance FrontierScience montre une nette tendance à la différenciation des performances entre les deux types de tâches.
Dans la catégorie Olympiades, la plupart des modèles de pointe ont obtenu des scores élevés. Parmi eux,Les trois meilleurs modèles avec les meilleurs scores globaux sont GPT-5.2, Gemini 3 Pro et Claude Opus 4.5, tandis que GPT-4o et OpenAI-o1 ont obtenu des résultats relativement faibles.L'étude indique que, dans ce type de problème avec des conditions claires, des raisonnements relativement fermés et des réponses vérifiables, la plupart des modèles ont été capables de réaliser de manière stable des calculs complexes et des déductions logiques, et que leurs performances globales sont proches de celles des personnes capables de résoudre des problèmes de haut niveau.
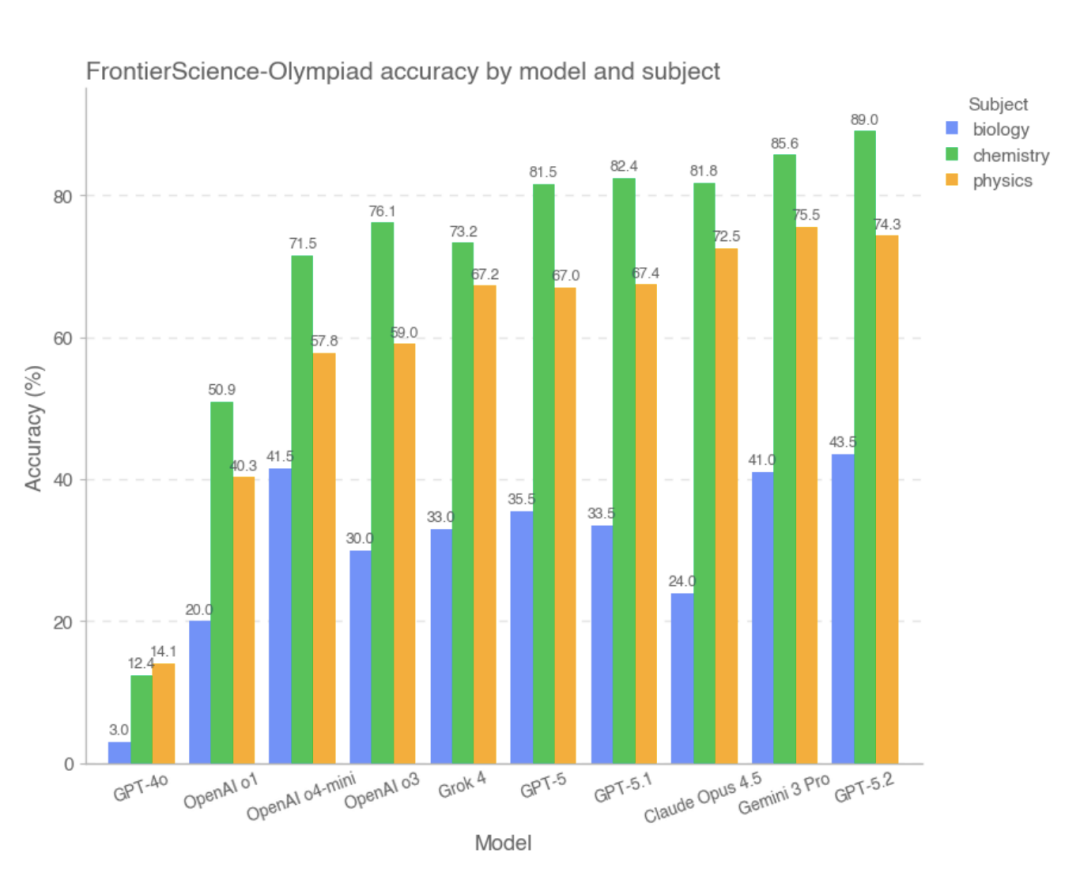
Cependant, sur le sous-ensemble FrontierScience-Research, le score global du modèle était significativement inférieur..Dans le sous-ensemble Recherche, le modèle est plus sujet aux biais lors de la décomposition de problèmes de recherche complexes.Par exemple, il peut y avoir une compréhension incomplète de l'objectif du problème, une mauvaise gestion des variables ou hypothèses clés, ou une accumulation progressive d'erreurs logiques au sein d'un long raisonnement. Comparés aux problèmes de type Olympiades, les modèles à grande échelle présentent encore un écart de capacité important face à des tâches plus ouvertes et plus proches des processus de recherche réels. D'après des données expérimentales,Les modèles qui ont obtenu de bons résultats dans la section Recherche étaient GPT-5, GPT-5.2 et GPT-5.1.
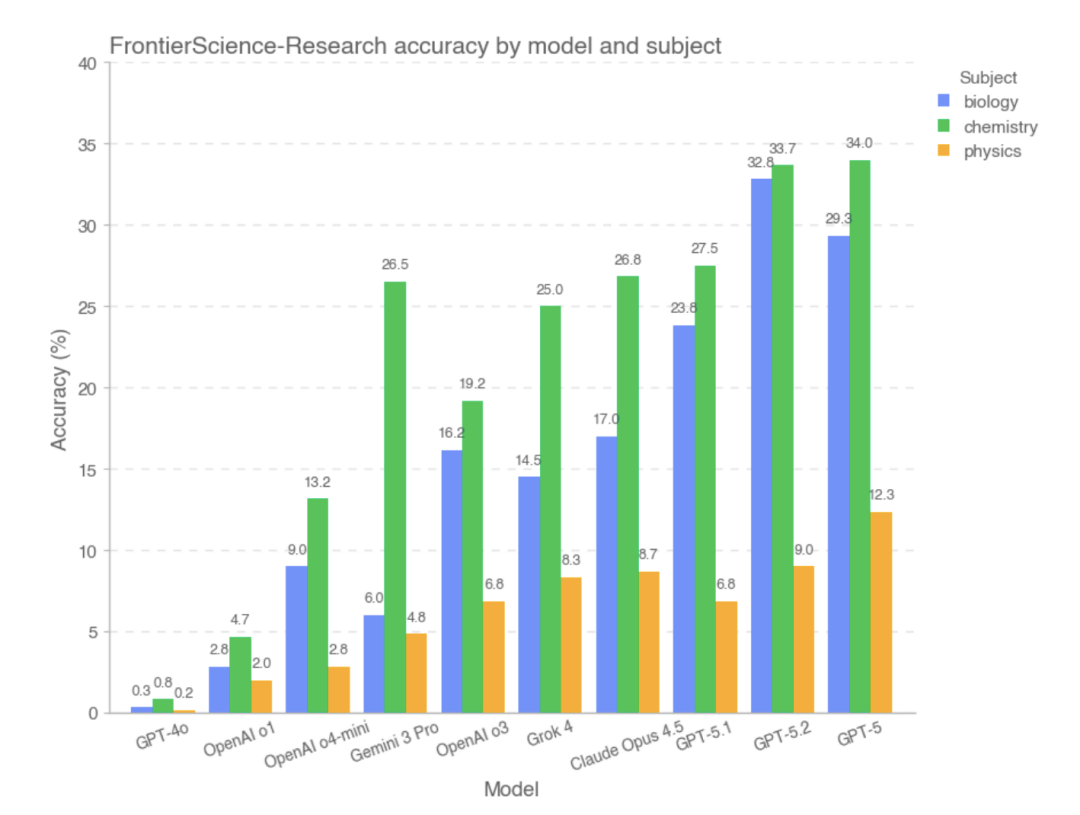
Cette étude a également comparé la précision des modèles GPT-5.2 et OpenAI-o3 sur les jeux de données FrontierScience-Olympiad et FrontierScience-Research, sous différentes intensités d'inférence. Les résultats montrent que…À mesure que le nombre de jetons utilisés dans les tests augmentait, la précision de GPT-5.2 s'améliorait de 67,51 TP3T à 77,11 TP3T sur l'ensemble de données Olympiad, et de 181 TP3T à 251 TP3T sur l'ensemble de données de recherche.Il convient de noter que, sur l'ensemble de données de recherche, le modèle o3 est en fait légèrement moins performant sous une intensité d'inférence élevée que sous une intensité d'inférence moyenne.
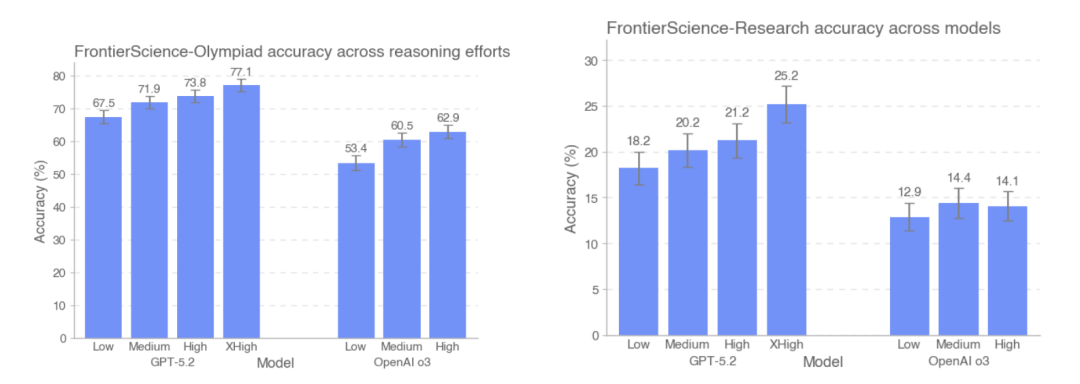
Sur la base de la conception globale et des résultats expérimentaux de FrontierScience,Ce modèle de grande taille a pu fonctionner de manière stable dans des problèmes scientifiques aux structures claires et aux conditions fermées, et ses performances sur certaines tâches ont approché le niveau des experts humains.Cependant, ses capacités restent considérablement limitées lorsqu'il s'agit de sous-tâches de recherche nécessitant une modélisation continue, une décomposition du problème et le maintien de la cohérence dans un raisonnement à longue chaîne.
Au-delà de l'exactitude des réponses, les modèles à grande échelle inaugurent une nouvelle norme de capacité.
Dans son explication officielle, OpenAI souligne explicitement que FrontierScience ne couvre pas toutes les dimensions du travail quotidien des scientifiques ; ses tâches consistent encore principalement en un raisonnement textuel et n’intègrent pas encore d’opérations expérimentales, d’informations multimodales ni de processus de collaboration de recherche concrets. Cependant, compte tenu de la saturation générale des méthodes d’évaluation scientifique existantes, FrontierScience propose une voie d’évaluation plus exigeante et plus pertinente sur le plan diagnostique : elle ne se contente pas d’évaluer l’exactitude des réponses du modèle, mais commence également à mesurer systématiquement sa capacité à accomplir des sous-tâches de recherche. De ce point de vue, la valeur de FrontierScience réside non seulement dans le classement lui-même, mais aussi dans la mise en place d’un nouveau référentiel pour l’amélioration ultérieure des modèles et la recherche en intelligence scientifique. À mesure que les capacités de raisonnement des modèles évoluent, ce type de référentiel, mettant l’accent sur l’originalité, la participation d’experts et l’évaluation du processus, pourrait devenir un indicateur précieux permettant de déterminer si l’intelligence artificielle s’oriente véritablement vers la collaboration en recherche.
Liens de référence :
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience








