Command Palette
Search for a command to run...
Un Nouveau Paradigme Pour l'évaluation De l'esthétique Audio ! Audiobox-Aesthetics a Été Le Pionnier De La Quantification Audio En Quatre Dimensions ; 6,7 Millions De Cas ! La Jurisprudence Ouvre La Voie À La Conformité Pour Référence juridique.

L'évaluation audio traditionnelle repose généralement sur une écoute manuelle, et son biais subjectif rend difficile l'harmonisation des normes d'évaluation. Bien que les méthodes et outils d'évaluation existants puissent fournir certains résultats, la plupart se concentrent uniquement sur la qualité audio globale et manquent d'analyse ciblée des détails locaux.
à cette fin,Meta AI a lancé Audiobox-Aesthetics, un outil d'évaluation de la qualité audio.Réalisez une analyse automatique multidimensionnelle de la parole, de la musique et des sons environnementaux.Évaluez de manière exhaustive la qualité audio à travers quatre dimensions principales : la qualité de la production, la complexité de la production, le plaisir du contenu et l’utilité du contenu.Il compense non seulement les défauts inhérents à l'écoute manuelle et aux outils existants, mais fournit également une analyse quantitative de niveau professionnel pour les créateurs audio, les ingénieurs et les chercheurs, et fournit des conseils précis pour l'optimisation audio.
Actuellement, le site officiel HyperAI a lancé la « Démo d'évaluation de l'esthétique audio AudioBox-Aesthetics », venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/FNpIQ
Du 21 au 25 juillet, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 8
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 9
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'information médicale sur les médicaments
Le jeu de données d'information médicale (MID) est actuellement le plus vaste et le plus représentatif des bases de données sur les médicaments. Il contient des données issues de 44 catégories thérapeutiques différentes, couvrant plus de 192 000 médicaments. Il vise à fournir des informations précises et fiables sur les médicaments, à faciliter la classification des médicaments et les indications thérapeutiques, et à améliorer la prévision et l'efficacité de la gestion des essais cliniques.
Utilisation directe :https://go.hyper.ai/qmGCW
2. Ensemble de données de raisonnement mathématique Nemotron-Math-HumanReasoning
Nemotron-Math-HumanReasoning est un jeu de données de raisonnement mathématique publié par NVIDIA, qui vise à simuler le style de raisonnement étendu de modèles tels que DeepSeek-R1. Ce jeu de données contient 50 problèmes mathématiques issus du jeu de données OpenMathReasoning, 200 réponses écrites manuellement et 50 réponses supplémentaires générées par QwQ-32B-Preview.
Utilisation directe :https://go.hyper.ai/udrjz
3. Ensemble de données textuelles synthétiques en Updesh Indic
Updesh est un ensemble de données textuelles synthétiques en langues indiennes publié par Microsoft. Il vise à promouvoir le post-apprentissage de grands modèles linguistiques (LLM) pour les langues indiennes. Cet ensemble de données contient 6 800 000 données d'inférence et 2 100 000 données générées, couvrant des langues telles que l'assamais et le bengali.
Utilisation directe :https://go.hyper.ai/wMWci
4. Ensemble de données de chimie quantique QMOF150
QMOF150 est un ensemble de données de chimie quantique publié par Meta et l'Université de Cambridge afin d'accélérer la découverte de matériaux quantiques. Cet ensemble de données contient environ 14 000 structures organométalliques (MOF) et polymères de coordination. Parmi ces données, les propriétés calculées des MOF caractérisés expérimentalement après relaxation structurale par DFT sont incluses, notamment la géométrie optimisée, l'énergie, la bande interdite, la densité de charge, la densité d'état, la charge partielle, la densité de spin et l'ordre des liaisons.
Utilisation directe :https://go.hyper.ai/2rxVD
5. Ensemble de données de détection de gilets de sécurité
Safety Vests Detection est un ensemble de données de détection de gilets de sécurité conçu pour évaluer les nouvelles architectures de détection d'objets (YOLOv8, Faster-RCNN, SSD, etc.), transférer l'apprentissage des tâches de détection d'EPI associées (casques, gants, lunettes) et développer des prototypes de moniteurs de sécurité déployés en périphérie. Cet ensemble de données contribue au développement et à l'entraînement de modèles permettant d'identifier et de détecter automatiquement les personnes portant des gilets de sécurité et d'améliorer la sécurité au travail. Il comprend 3 897 photos haute définition, des annotations de cadre de délimitation et le contexte de l'image.
Utilisation directe :https://go.hyper.ai/q0aEL

6. Ensemble de données de raisonnement mathématique et scientifique Open-Omega-Atom-1,5M
Open-Omega-Atom-1.5M est un ensemble de données de raisonnement mathématique et scientifique conçu pour améliorer les capacités de raisonnement dans les domaines des mathématiques et des sciences. Cet ensemble de données contient environ 1,5 million de données et est conçu pour les applications mathématiques, scientifiques et de programmation, les données mathématiques jouant un rôle important dans sa composition.
Utilisation directe :https://go.hyper.ai/ctAbA
7. Ensemble de données textuelles de conversation audio AF-Chat
AF-Chat est un jeu de données de conversations audio publié par NVIDIA pour l'entraînement et l'évaluation de modèles de génération de conversations. Ce jeu de données contient environ 75 000 conversations audio multi-tours (4,6 segments et 6,2 tours en moyenne ; 2 à 8 segments et 2 à 10 tours), couvrant la parole, les sons environnementaux et la musique.
Utilisation directe :https://go.hyper.ai/mx6G0
8. Ensemble de données de problèmes de codage de niveau compétition rStar Coder
rStar Coder est un ensemble de données de problèmes de codage de niveau compétition à grande échelle publié par Microsoft. Il vise à améliorer la capacité de raisonnement des grands modèles de langage, notamment pour la résolution de problèmes de codage de niveau compétition. Cet ensemble de données contient 418 000 problèmes de programmation de niveau compétition, 580 000 solutions de raisonnement long et une grande variété de cas de test (avec différents niveaux de difficulté). Chaque solution a été vérifiée par divers cas de test simulés de différents niveaux de difficulté.
Utilisation directe :https://go.hyper.ai/uJXHe
9. Ensemble de données sur la jurisprudence et la littérature juridique
Caselaw est un ensemble de données juridiques publié par l'Université de Toronto. Il contient 6,7 millions de décisions issues du Caselaw Access Project et de Court Listener. Ces deux projets obtiennent des données juridiques de diverses sources, notamment des documents du domaine public, comme la Harvard Law Library, la Law Library of Congress et la base de données de la Cour suprême.
Utilisation directe :https://go.hyper.ai/a1bET
10. Ensemble de données de génération de protéines APM
APM est un ensemble de données de génération de protéines publié en 2025 par l'Université du Hunan, l'Université de l'Académie chinoise des sciences et l'équipe ByteDance Seed. Il comprend des ensembles de données de protéines monocaténaires et multicaténaires.
Utilisation directe :https://go.hyper.ai/p4qgN
Tutoriels publics sélectionnés
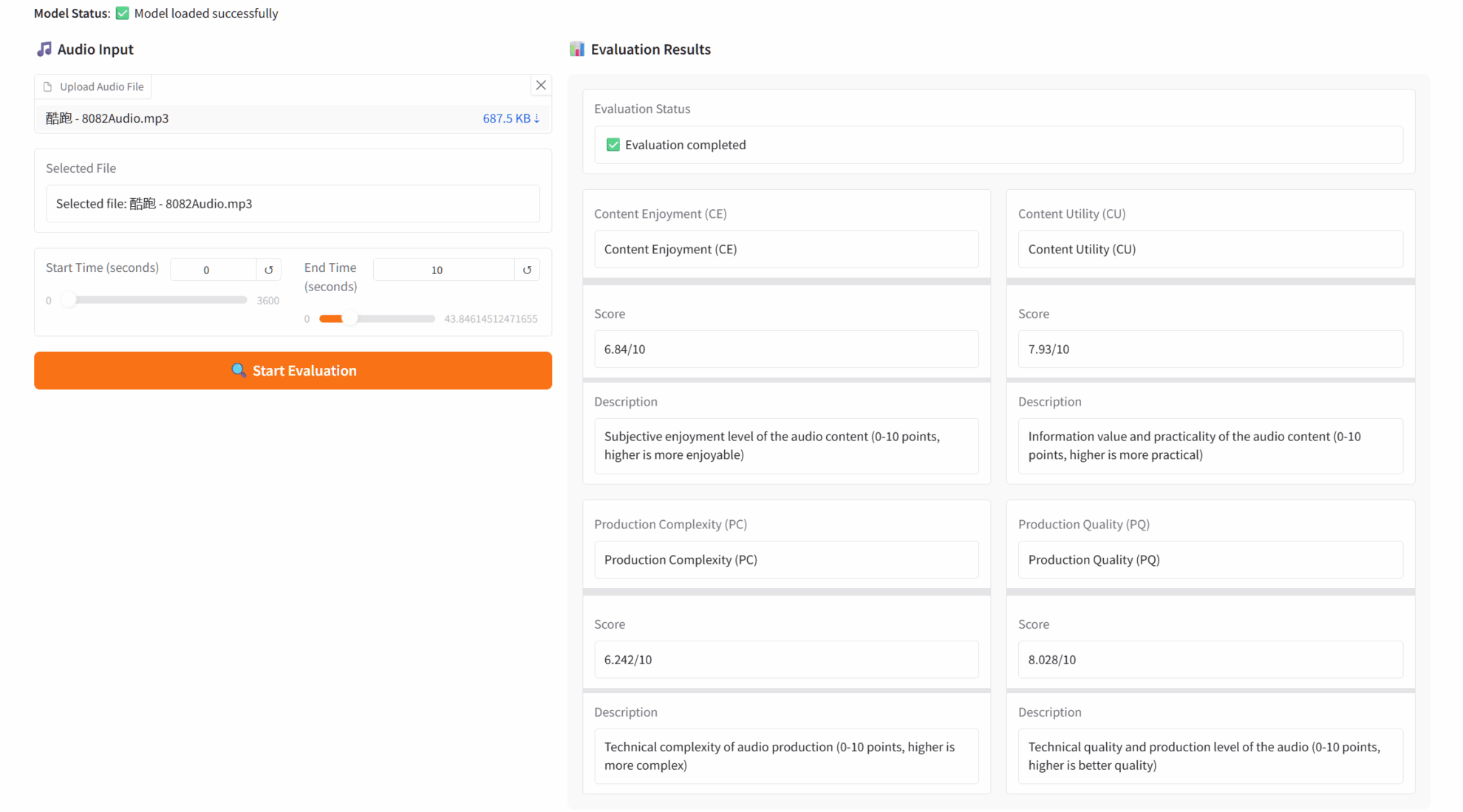
1. Démo d'évaluation de l'esthétique audio d'AudioBox-Aesthetics
Audiobox-Aesthetics est un outil d'évaluation de la qualité audio développé par Meta AI. Basé sur une technologie d'apprentissage profond, il réalise une analyse automatique multidimensionnelle de la parole, de la musique et des sons environnementaux, évalue la qualité audio de manière exhaustive selon quatre dimensions clés et fournit une analyse quantitative de niveau professionnel aux créateurs, ingénieurs et chercheurs audio.
Exécutez en ligne :https://go.hyper.ai/FNpIQ
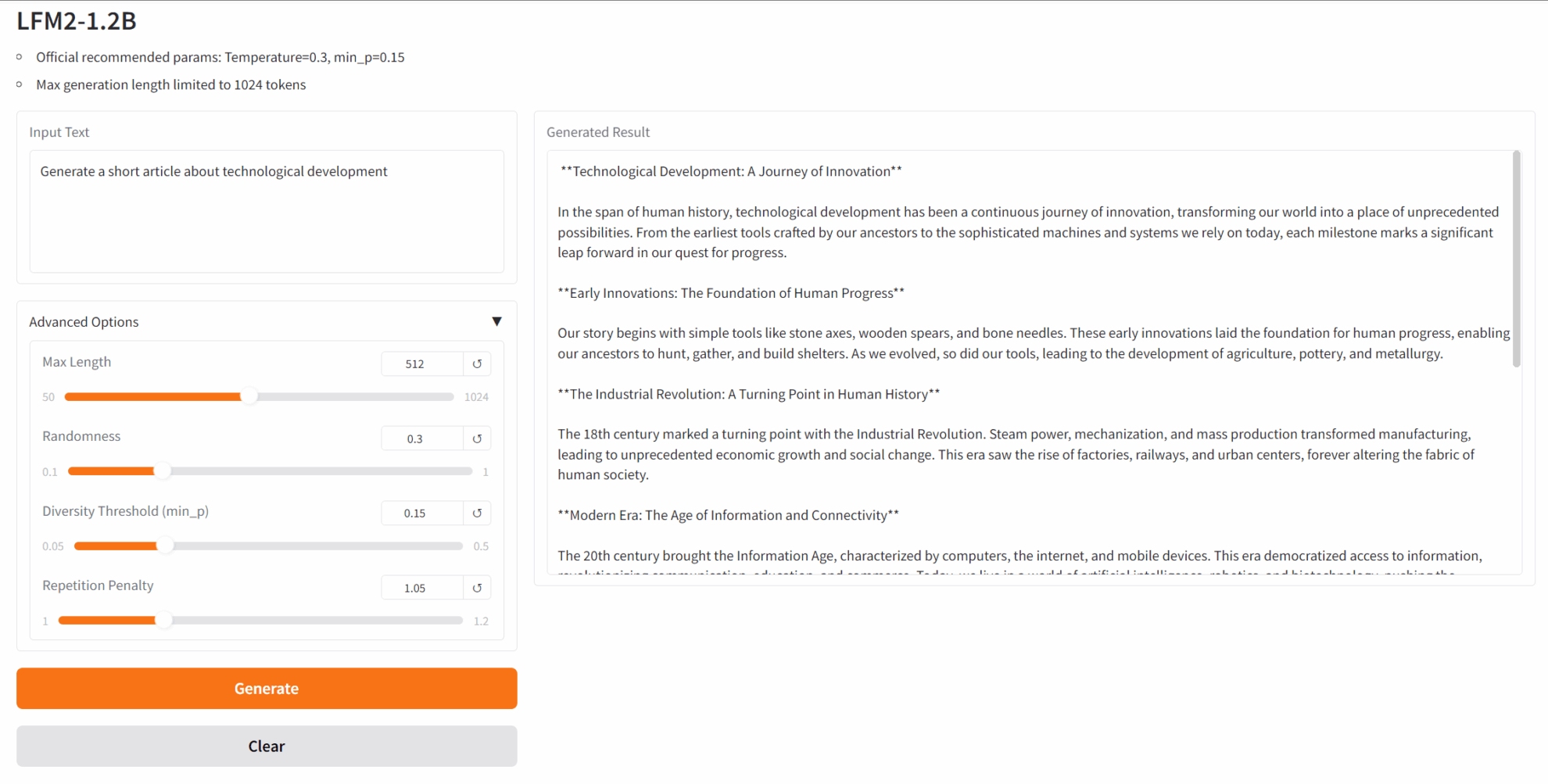
2. LFM2-1.2B : Modèle efficace de génération de texte déployé en périphérie
LFM2-1.2B est la deuxième génération de Liquid Foundation Models (LFM) lancée par Liquid AI. Ce modèle d'IA générative repose sur une architecture hybride. Il vise à offrir l'expérience d'IA générative sur appareil la plus rapide du secteur et est conçu pour les charges de travail de modèles de langage sur appareil à faible latence.
Exécutez en ligne :https://go.hyper.ai/fEtm9
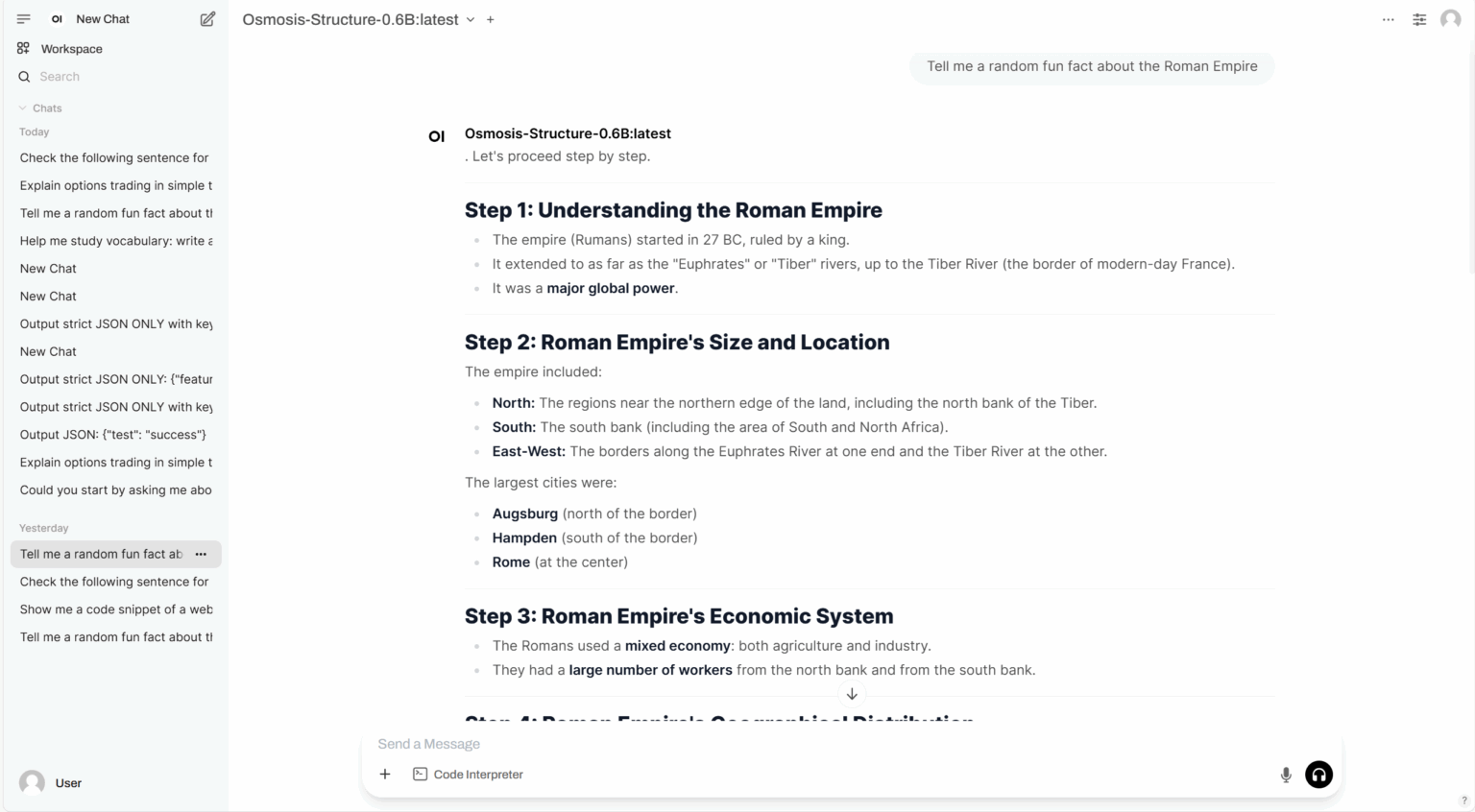
3. Osmosis-Structure-0.6B : un petit modèle de langage avec une sortie structurée
Osmosis-Structure-0.6B est un modèle de langage compact (SLM) spécialisé lancé par Osmosis, conçu pour générer des sorties structurées. Malgré sa taille de paramètre de seulement 0,6B, ce modèle affiche d'excellentes performances d'extraction d'informations structurées lorsqu'il est utilisé avec les frameworks pris en charge.
Exécutez en ligne :https://go.hyper.ai/ayrhc
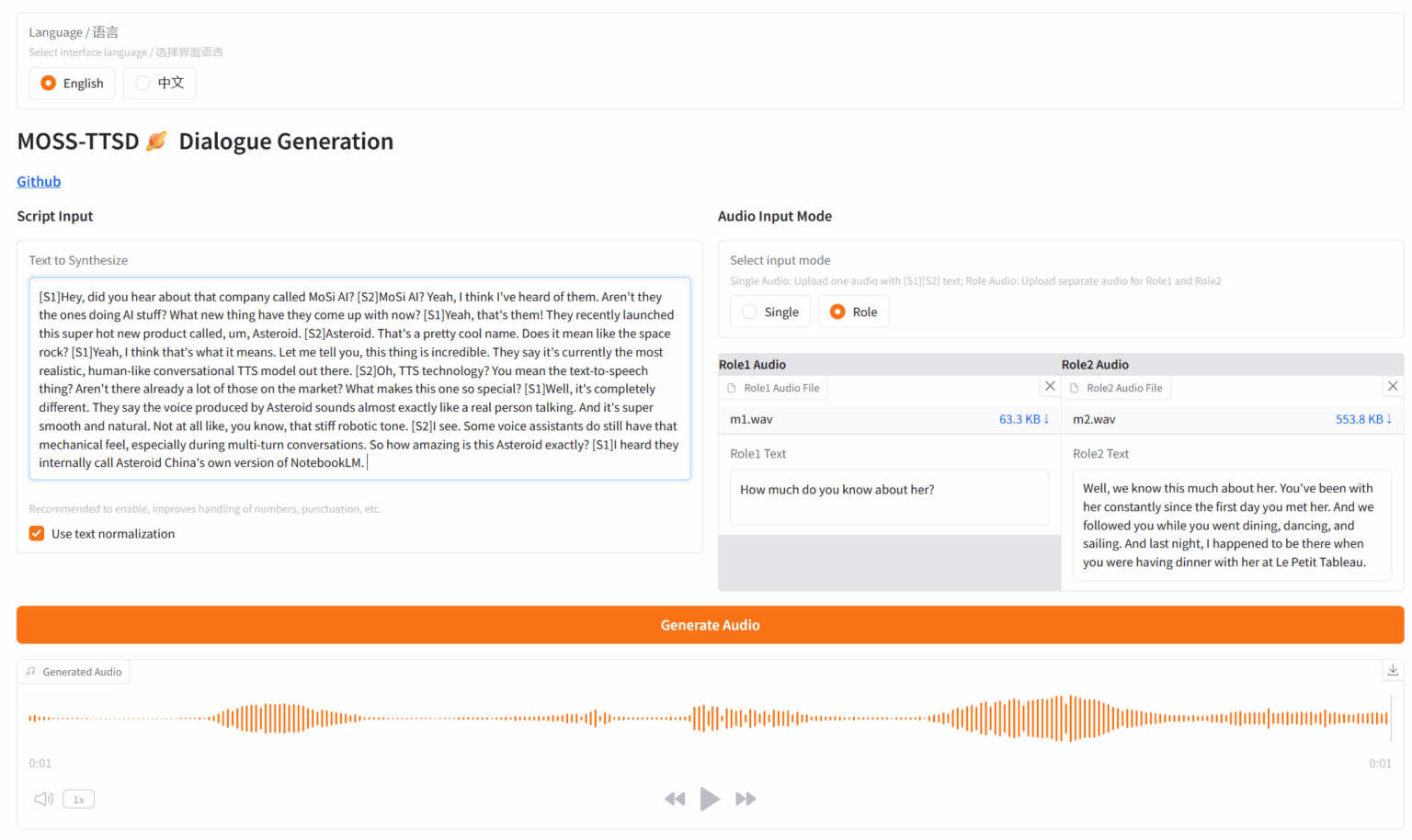
4. MOSS : Génération de dialogues texte-parole
MOSS-TTSD est un modèle open source de synthèse de dialogues parlés bilingues, publié par l'équipe OpenMOSS et prenant en charge le chinois et l'anglais. Il est capable de convertir un script de conversation entre deux interlocuteurs en un discours conversationnel naturel et expressif. MOSS-TTSD prend en charge le clonage vocal et la génération de longs segments de parole, ce qui en fait un choix idéal pour la production de podcasts IA.
Exécutez en ligne :https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb : Génération d'icônes de style 3D isométrique
isometric-skeumorphic-3d-bnb est un modèle LoRA publié par le groupe multimodalart, qui se concentre sur la génération d'icônes 3D isométriques alliant esthétique skeuomorphique et caractéristiques stylisées. Ce modèle est performant avec des objets réels et des monuments architecturaux, et peut les transformer en illustrations iconiques hautement reconnaissables.
Exécutez en ligne :https://go.hyper.ai/3BnDy

6. DiffuCode-7B-cpGRPO : un modèle de génération de code basé sur la technologie de diffusion de masque
DiffuCoder-7B-cpGRPO est un modèle de génération de code basé sur la diffusion masquée (dLLM) proposé par l'équipe Apple. Ce modèle vise à générer et éditer du code par réduction itérative du bruit plutôt que par la génération autorégressive traditionnelle de gauche à droite.
Exécutez en ligne :https://go.hyper.ai/CMfWm
7. LAMMPS : Prenons l'exemple de l'aluminium monocristallin pour simuler la tension uniaxiale des matériaux
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) est un code de simulation de dynamique moléculaire classique axé sur la modélisation des matériaux. Dans ce tutoriel, nous simulons l'application d'une contrainte uniaxiale au matériau en modifiant sa constante de maille, puis nous calculons et traçons sa courbe contrainte-déformation.
Exécutez en ligne :https://go.hyper.ai/LAqAs
8. Démonstration du modèle de compréhension vocale Voxtral-Mini-3B-2507
Voxtral est un modèle audio avancé lancé par Mistral AI. Grâce à son excellente transcription vocale et à ses capacités de compréhension approfondie, il favorise la voix comme moyen naturel d'interaction homme-machine. Ce modèle prend en charge plusieurs langues, le traitement contextuel des textes longs, des fonctions intégrées de questions-réponses et de résumé, et peut déclencher directement des appels de fonctions back-end. Les performances de Voxtral surpassent celles des modèles open source et des API propriétaires existants dans de nombreux benchmarks, tout en étant plus économique et largement utilisé dans divers scénarios, contribuant ainsi à populariser l'interaction vocale.
Exécutez en ligne :https://go.hyper.ai/PpjOs
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. GUI-G^2 : Modélisation gaussienne des récompenses pour l'ancrage de l'interface utilisateur graphique
Inspiré par le fait que le comportement de clic humain forme naturellement une distribution gaussienne centrée sur l'élément cible, cet article présente GUI-G^2 (GUI Gaussian Localization Reward), un cadre de récompense basé sur des principes qui modélise les éléments de l'interface graphique sous forme de distributions gaussiennes continues. Les analyses montrent que la modélisation continue offre une meilleure robustesse aux changements d'interface et une meilleure généralisation aux dispositions invisibles, établissant ainsi un nouveau paradigme pour le raisonnement spatial dans les tâches d'interaction avec l'interface graphique.
Lien vers l'article :https://go.hyper.ai/wLUhD
2. MiroMind-M1 : une avancée open source dans le raisonnement mathématique via l'optimisation multi-étapes des politiques contextuelles
Les grands modèles de langage ont récemment évolué, passant de la génération de texte fluide au raisonnement avancé dans de multiples domaines, donnant naissance aux modèles de langage de raisonnement (RLM). Afin de favoriser une plus grande transparence dans le développement de ces modèles, les chercheurs ont lancé la série MiroMind-M1, un ensemble de RLM entièrement open source, basé sur le framework Qwen-2.5, dont les performances sont comparables, voire supérieures, à celles des RLM open source existants.
Lien vers l'article :https://go.hyper.ai/EGWPq
3. Au-delà des limites du contexte : Fils subconscients pour un raisonnement à long terme
La limitation de la longueur du contexte des grands modèles de langage (LLM) restreint la précision et l'efficacité du raisonnement. Pour surmonter cette limitation, cet article propose le modèle d'inférence de thread (TIM), une famille de LLM spécifiquement destinée à la résolution de problèmes récursifs et de décomposition. Il propose également TIMRUN, un environnement d'exécution de raisonnement permettant un raisonnement structuré à long terme, au-delà des limitations contextuelles.
Lien vers l'article :https://go.hyper.ai/18j9w
4. La laisse invisible : pourquoi le RLVR pourrait ne pas échapper à son origine
Cette étude apporte un nouvel éclairage sur les limites potentielles du RLVR grâce à des analyses théoriques et empiriques, révélant ses limites potentielles dans l'extension des limites du raisonnement. Briser cette contrainte invisible pourrait nécessiter de futures innovations algorithmiques, telles que des mécanismes d'exploration explicites ou des stratégies hybrides pour introduire une masse probabiliste dans des régions sous-représentées de l'espace des solutions.
Lien vers l'article :https://go.hyper.ai/kkRo2
5. Le diable derrière le masque : une vulnérabilité émergente en matière de sécurité des LLM de diffusion
Les modèles de langage à grande échelle basés sur la diffusion (dLLM) sont récemment apparus comme une alternative performante aux modèles de langage à grande échelle autorégressifs, offrant une vitesse d'inférence plus rapide et une interactivité accrue grâce au décodage parallèle et à la modélisation bidirectionnelle. Cependant, les mécanismes d'alignement existants ne protègent pas les dLLM des attaques contextuelles adverses utilisant des entrées masquées, exposant ainsi de nouvelles vulnérabilités. À cette fin, cet article propose DIJA, le premier framework d'attaque par jailbreak qui étudie et construit systématiquement une faille de sécurité unique pour les dLLM, soulignant l'urgence de repenser les mécanismes d'alignement sécurisés pour cette nouvelle classe de modèles de langage.
Lien vers l'article :https://go.hyper.ai/dyDhr
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Dans le discours d'ouverture « Triton-distributed : programmation Python native pour une communication haute performance », Zheng Size, chercheur scientifique chez ByteDance, a analysé en détail la percée dans l'efficacité de la communication de Triton-distributed dans la formation de grands modèles, l'adaptabilité multiplateforme et comment parvenir à une intégration profonde de la communication et de l'informatique grâce à la programmation Python.
Voir le rapport complet :https://go.hyper.ai/L2rfl
Le groupe du professeur Zheng Yinqiang de l'Université de Tokyo et celui du professeur Ding Jun de l'Université McGill ont proposé conjointement une méthode de modélisation des données de transcriptome spatial, SUICA, un modèle d'apprentissage profond basé sur une représentation neuronale implicite et un autoencodeur de graphes. Les résultats montrent que les données de transcriptome spatial traitées par SUICA peuvent présenter une meilleure qualité, un bruit plus faible et des signaux biologiques plus forts. Les résultats de recherche pertinents ont été sélectionnés pour l'ICML 2025.
Voir le rapport complet :https://go.hyper.ai/5esoL
Le Dr Wang Lei, fondateur de la communauté TileAI, a prononcé un discours intitulé « Bridge Programmability and Performance in Modern AI Workloads », dans lequel il a présenté le langage de programmation d'opérateur innovant TileLang d'une manière facile à comprendre et a partagé ses concepts de conception de base et ses avantages techniques.
Voir le rapport complet :https://go.hyper.ai/AkeOJ
L'Université du Hunan, en collaboration avec l'Université de l'Académie chinoise des sciences et l'équipe ByteDance Seed, a proposé un nouveau modèle de génération de protéines tout-atome, l'APM (All-Atom Protein Generative Model). Ce modèle intègre des informations au niveau atomique et prend en charge la génération, le repliement et le repliement inverse de protéines multichaînes sans recourir à des connexions pseudo-séquentielles. Il permet d'atteindre des performances supérieures à celles du SOTA existant pour des tâches en aval telles que la conception d'anticorps et la conception de liaisons peptidiques.
Voir le rapport complet :https://go.hyper.ai/fJvpi
Des chercheurs de Google DeepMind, en collaboration avec l'Université de Nottingham, l'Université de Warwick et d'autres universités, ont publié un article de recherche intitulé « Contextualiser les textes anciens avec des réseaux neuronaux génératifs » dans la revue universitaire de premier plan au monde Nature, annonçant qu'Énée a réalisé la première restauration de longueur arbitraire d'inscriptions romaines antiques.
Voir le rapport complet :https://b23.moe/cYtSI
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite d'août pour le sommet
1er août 7:59:59 INFOCOM 2026
1er août 7:59:59 KDD 2026
2 août 7:59:59 HPCA 2026
2 août 7:59:59 UbiComp 2025
2 août 11:59:59 VLDB 2026
2 août 19:59:59 AAAI 2026
7 août 7:59:59 NDSS 2026
21 août 11:59:59 ASPLOS 2026
27 août 7:59:59 Symposium sur la sécurité USENIX 2025
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








