Command Palette
Search for a command to run...
Logiciel Libre, Excellent Rapport Qualité-prix ! Mistral AI Lance La Série De Modèles Ministral 3, Intégrant Une Compréhension Multimodale Et Des Capacités d'exécution Intelligentes ; De La Danse Dynamique Aux Comportements Quotidiens, Le Jeu De Données X-Dance Permet Des Tests Multidimensionnels Pour La Génération d'animations humaines.

récemment,L'équipe Mistral AI a rendu open source sa série de modèles à haute efficacité, Ministral 3, offrant trois options de paramètres de modèle : 3B, 8B et 14B.Chaque paramètre est disponible en trois versions : Basic, Command et Inference, toutes distribuées sous licence Apache 2.0.
Le Ministral-3-14B, modèle le plus performant de la gamme, offre les performances les plus avancées de sa catégorie, comparables à celles du modèle Mistral Small 3.2-24B, pourtant plus imposant. Optimisé pour un déploiement local, il garantit des performances élevées même sur des appareils compacts aux ressources limitées.
Ministral-3-14B intègre des capacités de compréhension multimodale et d'exécution intelligente :En matière de vision, il peut analyser directement le contenu des images et générer du contenu textuel à partir des informations visuelles ; par ailleurs, sa prise en charge multilingue couvre des dizaines de langues courantes, dont l’anglais, le chinois, le japonais, etc. Le modèle s’appuie sur sa puissante fenêtre de contexte de 256 Ko, qui offre un support solide pour le traitement de tâches complexes et de longues séquences.
Le site web d'HyperAI propose désormais le déploiement en un clic de l'instruction Ministral-3-14B. Essayez-le !
Utilisation en ligne :https://go.hyper.ai/EGIY2
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 1er au 5 décembre :
* Jeux de données publics de haute qualité : 5
* Sélection de tutoriels de haute qualité : 5
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en décembre : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Jeu de données pour la génération de problèmes d'algorithmes évolutionnaires UniCode
UniCode est un ensemble de données automatisé de problèmes algorithmiques et de cas de test, construit à l'aide d'une stratégie de génération évolutionnaire. Il vise à remplacer les ensembles de problèmes statiques traditionnels, générés manuellement, en fournissant des ressources de problèmes de programmation plus diversifiées, stimulantes et robustes. Grâce à un processus systématique de génération et de vérification des problèmes, cet ensemble de données construit des données de problèmes et de tests structurées, exigeantes et exemptes de contamination, adaptées à la recherche algorithmique, à l'évaluation des modèles de génération de code et à l'entraînement aux compétitions.
Utilisation directe :https://go.hyper.ai/YBBcI
2. Ensemble de données VAP-Data sur les performances visuelles et motrices
VAP-Data, développé conjointement par ByteDance et l'Université chinoise de Hong Kong, est actuellement le plus grand ensemble de données de génération vidéo à contrôle sémantique. Il vise à fournir des bancs d'essai de haute qualité pour l'entraînement et l'évaluation de la génération vidéo contrôlée, la synthèse de mouvement contrôlée et les modèles vidéo multimodaux. Cet ensemble de données contient plus de 90 000 paires d'échantillons soigneusement sélectionnés, couvrant 100 conditions sémantiques précises réparties en quatre catégories sémantiques : concept, style, action et plan. Chaque catégorie sémantique comprend plusieurs ensembles d'instances vidéo alignées entre elles.
Utilisation directe :https://go.hyper.ai/wUrHs

3. Ensemble de données d'images microscopiques de champignons multiclasses
Fungi MultiClass Microscopic est un ensemble de données d'images microscopiques de haute qualité destiné à la classification d'images et à la recherche en apprentissage profond, conçu pour fournir des ressources de données d'entraînement et d'évaluation fiables pour des domaines tels que la mycologie médicale et le diagnostic en pathologie agricole.
Utilisation directe :https://go.hyper.ai/ZHUaY
4. Ensemble de données X-Dance sur les mouvements de danse pilotés par l'image
X-Dance est un jeu de données de test publié par l'Université de Nanjing en collaboration avec Tencent et le Laboratoire d'intelligence artificielle de Shanghai. Il est spécifiquement conçu pour la génération d'animations vidéo à partir d'images et vise à évaluer la robustesse et la capacité de généralisation des modèles dans des scénarios réels, notamment face à des défis tels que la préservation de l'identité, la cohérence temporelle et le décalage spatio-temporel.
Utilisation directe :https://go.hyper.ai/QXsNo

5. Ensemble de données 3EED pour la compréhension 3D basée sur le langage
3EED est un jeu de données d'ancrage visuel 3D multiplateforme et multimodal, développé par l'Université des sciences et technologies de Hong Kong (Guangzhou) en collaboration avec l'Université technologique de Nanyang, l'Université des sciences et technologies de Hong Kong et d'autres institutions. Accepté pour NeurIPS 2025, il vise à aider les modèles à réaliser des tâches de localisation de cibles 3D guidées par le langage dans des scènes extérieures réelles, et à évaluer de manière exhaustive la robustesse multiplateforme et les capacités de compréhension spatiale des modèles.
Utilisez-le directement : https://go.hyper.ai/gC8Fq
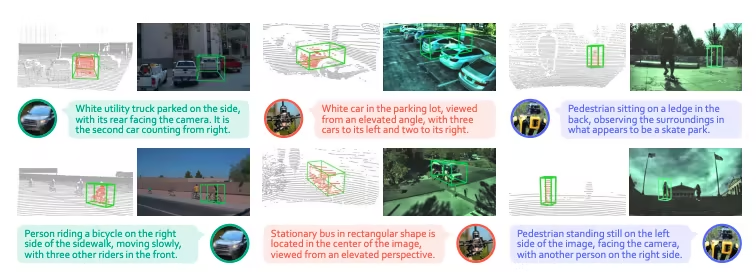
Tutoriels publics sélectionnés
1. Un sapin de Noël 3D basé sur la reconnaissance gestuelle
3D Christmas Tree est un projet innovant créé par moleculemmeng020425. Il offre une expérience visuelle immersive et cinématographique. Développé avec React et Three.js (R3F), ce projet utilise une technologie avancée de reconnaissance gestuelle par IA, permettant aux utilisateurs de contrôler facilement la forme du sapin (en le rassemblant et en le dispersant) et de faire pivoter librement le point de vue grâce à des gestes.
Exécutez en ligne :https://go.hyper.ai/LpApP
2. Déploiement en un clic de l'instruction Ministry-3-14B
Ministral-3-14B-Instruct-2512 est un modèle multimodal développé par Mistral AI. Il prend en charge le traitement multimodal (texte et image) et multilingue, offrant des performances élevées et un excellent rapport coût-efficacité. Grâce aux technologies d'optimisation de partenaires comme NVIDIA, ce modèle fonctionne efficacement sur différents matériels et convient à l'informatique de périphérie, aux déploiements en entreprise et à d'autres scénarios, fournissant ainsi aux développeurs des outils puissants pour la création et le déploiement d'applications d'IA.
Exécutez en ligne :https://go.hyper.ai/EGIY2
3. SAM3 : Modèle de segmentation visuelle
SAM3 est un modèle de vision par ordinateur avancé développé par Meta AI. Ce modèle détecte, segmente et suit les objets dans les images et les vidéos à partir de texte, d'exemples et d'indices visuels. Il prend en charge la saisie de phrases à vocabulaire ouvert, offre de puissantes capacités d'interaction intermodale et corrige les résultats de segmentation en temps réel. SAM3 surpasse les systèmes existants en matière de segmentation d'images et de vidéos, avec des performances deux fois supérieures, et prend en charge l'apprentissage zéro-shot.
Exécutez en ligne :https://go.hyper.ai/PEaVo

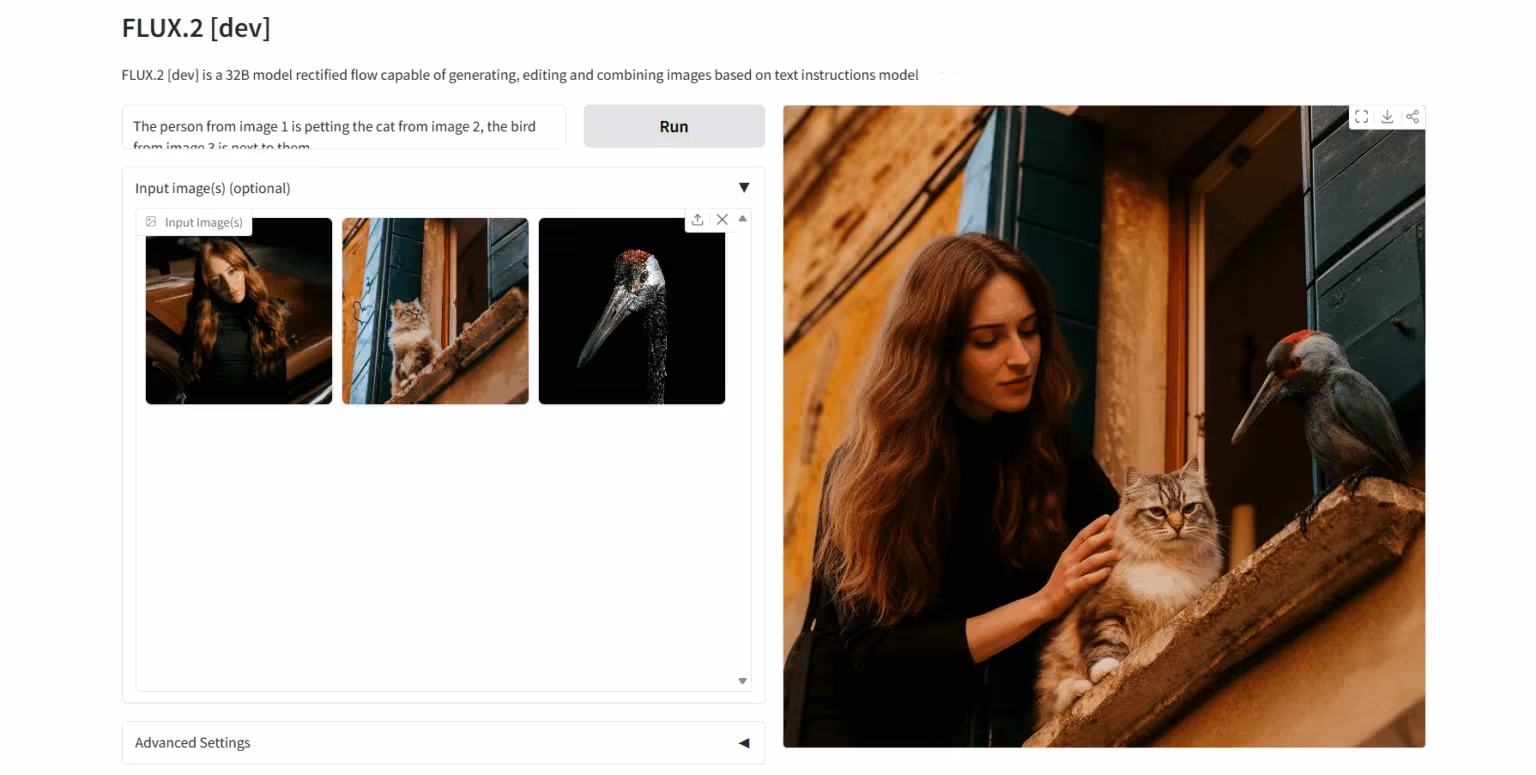
4. FLUX.2-dev : Modèle de génération et d’édition d’images
FLUX.2 est un modèle d'imagerie basé sur l'IA, développé par Black Forest Labs. Conçu spécifiquement pour les flux de travail créatifs réels, il prend en charge jusqu'à 10 images de référence et génère des images de haute qualité jusqu'à une résolution de 4 mégapixels, offrant un rendu exceptionnel des détails et du texte. Combinant un modèle de langage visuel à une architecture de transformateur de flux, FLUX.2 améliore considérablement la compréhension des connaissances du monde réel et la qualité de la génération d'images, favorisant ainsi l'innovation ouverte et la généralisation des technologies d'intelligence visuelle.
Exécutez en ligne :https://go.hyper.ai/4abhg
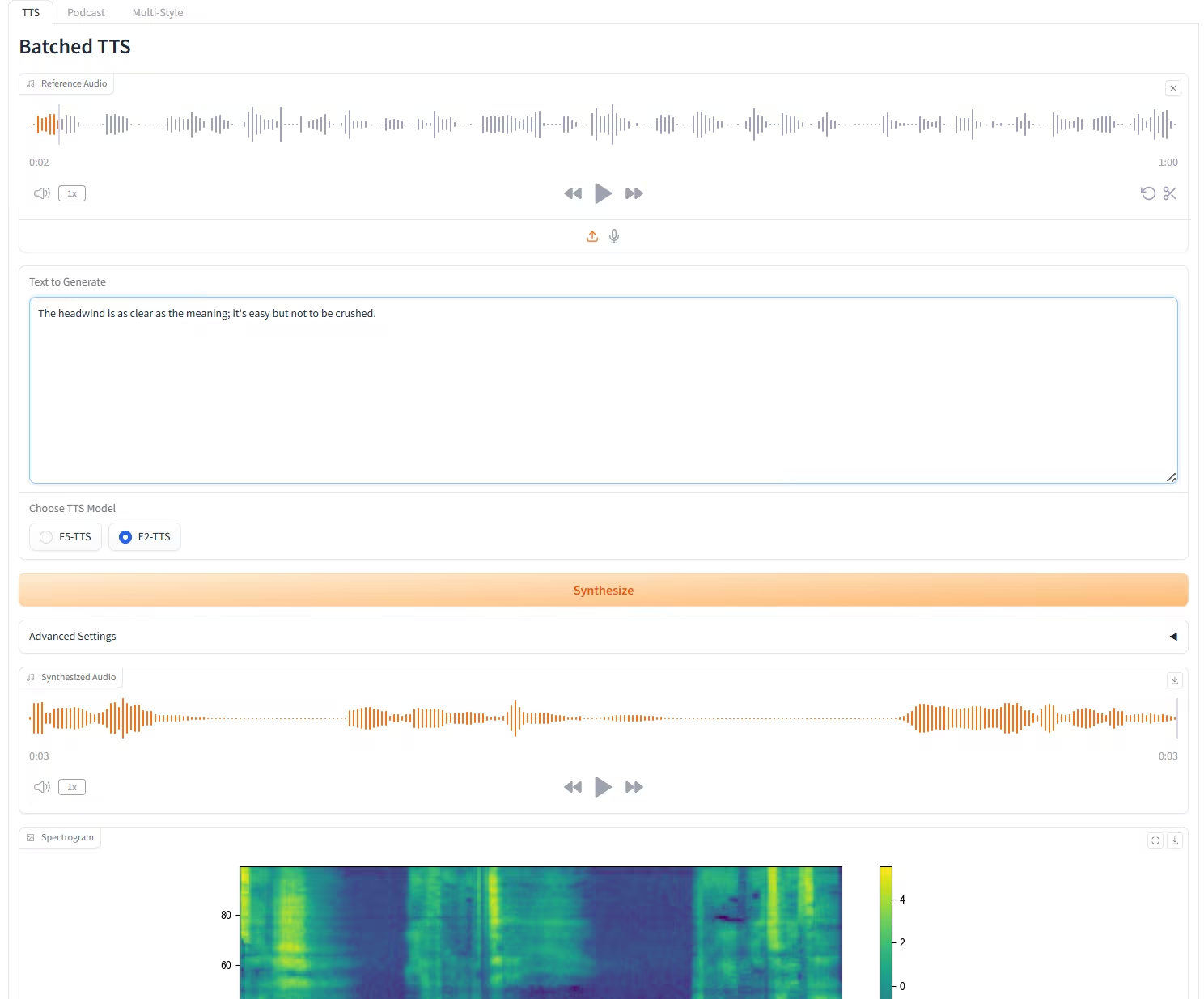
5. Le F5-E2 TTS peut cloner n'importe quel son en seulement 3 secondes.
F5-TTS est un système de synthèse vocale (TTS) haute performance, développé conjointement en open source par l'Université Jiao Tong de Shanghai, l'Université de Cambridge et l'Institut de recherche automobile Geely (Ningbo). Il repose sur une méthode de génération non autorégressive utilisant la correspondance de flux, combinée à la technologie Diffusion Transformer (DiT). Ce système génère rapidement une parole naturelle, fluide et fidèle à partir du texte original grâce à un apprentissage zéro-shot, sans supervision supplémentaire. Il prend en charge la synthèse multilingue, notamment le chinois et l'anglais, et peut synthétiser efficacement la parole à partir de textes longs.
Exécutez en ligne :https://go.hyper.ai/8YCMD
Recommandation de papier de cette semaine
1. Des modèles de code de base aux agents et applications : un panorama complet et un guide pratique de l’intelligence du code
Cette étude intègre systématiquement et fournit un ensemble complet d'analyses intégrées et de lignes directrices pratiques (y compris une série d'expériences analytiques et exploratoires) pour explorer le cycle de vie complet des LLM basés sur le code, couvrant la construction des données, le pré-entraînement, les paradigmes d'incitation, le pré-entraînement du code, le réglage fin supervisé, l'apprentissage par renforcement et la construction d'agents de programmation autonomes.
Lien vers l'article :https://go.hyper.ai/xvPZN
2. DeepSeek-V3.2 : Repousser les frontières des grands modèles de langage ouverts
Cet article présente DeepSeek-V3.2, un modèle qui offre des capacités d'inférence et des performances d'agent supérieures tout en conservant une efficacité de calcul élevée. Les principales avancées technologiques de DeepSeek-V3.2 reposent sur trois aspects : le mécanisme d'attention parcimonieuse DeepSeek Sparse Attention (DSA), un cadre d'apprentissage par renforcement évolutif et un pipeline de synthèse de tâches d'agent à grande échelle.
Lien vers l'article :https://go.hyper.ai/pVyE9
3. LongVT : Inciter à « réfléchir avec des vidéos longues » grâce à l’appel d’outils natifs
Cet article propose LongVT, un cadre de traitement intelligent du corps entier qui permet une analyse approfondie des vidéos longues grâce à une chaîne multimodale entrelacée d'outils et de pensées. Il exploite les capacités de positionnement temporel inhérentes aux LMM comme outil natif de découpage vidéo, se concentrant précisément sur des segments vidéo spécifiques et effectuant un rééchantillonnage plus fin des images.
Lien vers l'article :https://go.hyper.ai/ho70t
4. Z-Image : un modèle de base efficace pour la génération d’images avec transformateur de diffusion à flux unique
Cet article propose Z-Image, un modèle génératif hautement performant doté de 6 milliards de paramètres et basé sur l'architecture Scalable Single-Stream Diffusion Transformer (S3-DiT), remettant en question le paradigme du « scaling-only ». S'appuyant sur ce modèle, les chercheurs ont développé Z-Image-Turbo, un modèle utilisant une méthode de distillation en quelques étapes combinée à un système de récompenses post-entraînement. Ce modèle atteint une latence d'inférence inférieure à la seconde sur les GPU H800 professionnels tout en restant compatible avec le matériel grand public (moins de 16 Go de VRAM), abaissant ainsi considérablement le seuil de déploiement.
Lien vers l'article :https://go.hyper.ai/qqSwp
5. Rapport technique Qwen3-VL
Cet article présente Qwen3-VL, le modèle de langage visuel le plus performant de la série Qwen à ce jour, qui affiche des résultats exceptionnels sur un large éventail de benchmarks multimodaux. Ce modèle prend en charge nativement des contextes entrelacés jusqu'à 256 000 jetons, intégrant de manière transparente les informations textuelles, visuelles et vidéo. La famille de modèles comprend des architectures denses (2B/4B/8B/32B) et des architectures hybrides expertes (30B-A3B/235B-A22B) afin d'optimiser les compromis entre latence et qualité selon les scénarios.
Lien vers l'article :https://go.hyper.ai/8HkMJ
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. Remodeler le pouvoir prédictif des assemblages de protéines désordonnés : NVIDIA, le MIT, l’Université d’Oxford, l’Université de Copenhague, Peptone et d’autres publient des modèles génératifs et de nouveaux points de référence.
Une équipe conjointe composée de Peptone, société britannique spécialisée dans le développement de technologies d'analyse des protéines, de NVIDIA et du MIT, a réalisé deux avancées majeures. La première est PeptoneBench, un cadre d'évaluation systématique qui intègre des données expérimentales multi-sources issues de la SAXS, de la RMN, de la RDC et de la PRE, et combine des méthodes statistiques telles que la pondération par entropie maximale afin d'obtenir une comparaison quantitative rigoureuse entre les observations expérimentales et les prédictions théoriques. La seconde est PepTron, un modèle génératif entraîné sur un ensemble de données IDR synthétiques étendu, qui améliore spécifiquement la modélisation des régions désordonnées et permet ainsi de mieux appréhender la diversité conformationnelle des protéines désordonnées.
Voir le rapport complet :https://go.hyper.ai/YBd9t
2. Tutoriel en ligne | FLUX.2, la nouvelle technologie de pointe en matière de génération d'images, peut référencer jusqu'à 10 images simultanément, atteignant une cohérence extrêmement élevée en termes de caractère et de style.
Après une longue période de silence, Black Forest Labs fait son grand retour en publiant en open source FLUX.2, son modèle de génération et d'édition d'images nouvelle génération. Sorti en 2024, FLUX.1 offrait des résultats quasi-réalistes pour la génération d'images de personnes, notamment de personnes réelles. Désormais, la mise à jour FLUX.2 repousse les limites de la qualité d'image et de la flexibilité créative, atteignant des performances de pointe en matière de compréhension des instructions, de qualité visuelle, de rendu des détails et de diversité des rendus.
Voir le rapport complet :https://go.hyper.ai/wLDRW
3. Aperçu de l'événement | Shanghai Innovation Lab, TileAI, Huawei et Advanced Compiler Lab se réunissent à Shanghai ; TVM, TileRT, PyPTO et Triton présentent leurs atouts uniques.
Le 8e salon technique Meet AI Compiler se tiendra le 27 décembre à la Shanghai Innovation Academy. Cette session réunira des experts de la Shanghai Innovation Academy, de la communauté TileAI, de Huawei HiSilicon et de l'Advanced Compiler Lab. Ils partageront leurs connaissances sur l'ensemble de la chaîne technologique, de la conception de la pile logicielle et du développement des opérateurs à l'optimisation des performances. Les sujets abordés incluront l'interopérabilité inter-écosystèmes de TVM, l'optimisation des opérateurs de fusion de PyPTO, les systèmes à faible latence avec TileRT et l'accélération multi-architecture avec Triton, présentant ainsi un parcours technique complet, de la théorie à la mise en œuvre.
Voir le rapport complet :https://go.hyper.ai/x6po9
4. Stanford, l'Université de Pékin, l'UCL et l'UC Berkeley ont collaboré pour utiliser CNN afin d'identifier avec précision sept échantillons lenticulaires rares parmi 810 000 quasars.
Une équipe composée de nombreuses institutions de recherche, dont l'université de Stanford, le SLAC National Accelerator Laboratory, l'université de Pékin, l'observatoire de Brera de l'Institut national italien d'astrophysique, l'University College London et l'université de Californie à Berkeley, a développé un flux de travail basé sur les données pour identifier les quasars qui agissent comme de fortes lentilles gravitationnelles dans les données spectrales de DESI DR1, élargissant considérablement la taille auparavant réduite de l'échantillon de quasars.
Voir le rapport complet :https://go.hyper.ai/6s2FB
5. Avec seulement 2% atteints, le pari de Sam Altman sur l'infrastructure de vérification d'identité humaine est confronté à un dilemme réglementaire mondial.
À une époque où l'authenticité de l'IA est difficile à discerner, Sam Altman et Alex Blania développent un système mondial de « vérification humaine » par reconnaissance de l'iris. Cependant, l'expansion de Tools for Humanity se heurte à d'immenses difficultés. Les Philippines ont suspendu ses services de données, invoquant des problèmes de confidentialité et d'influence indue, et plusieurs autres pays ont lancé des enquêtes. L'écart entre leur objectif d'un milliard d'utilisateurs et leurs 17,5 millions d'utilisateurs actuels ne cesse de se creuser. Malgré un financement conséquent et une équipe de haut niveau, les questions de confidentialité et de réglementation demeureront un enjeu majeur pour l'avenir de Tools for Humanity.
Consultez le rapport complet : https://go.hyper.ai/KL1Dq
Articles populaires de l'encyclopédie
1. DALL-E
2. Hyperréseaux
3. Front de Pareto
4. Mémoire bidirectionnelle à long terme (Bi-LSTM)
5. Fusion de rang réciproque
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Conférence de haut niveau avec une date limite en décembre

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








