Command Palette
Search for a command to run...
Technologie d'entrée/sortie Innovante ! Tencent Hunyuan Lance HunyuanWorld-Mirror, Une Reconstruction 3D Révolutionnaire ; Découvrez l'intégralité Du Contenu Netflix ! Le Catalogue De Films Et Séries Netflix Offre Un Éclairage Précieux Sur Les Tendances Du divertissement.

L'apprentissage de la géométrie visuelle est un sujet fondamental en vision par ordinateur, largement appliqué à la réalité augmentée, à la manipulation robotique et à la navigation autonome. Les méthodes traditionnelles, telles que la reconstruction 3D par mouvement (SfM) et les techniques stéréoscopiques multivues, reposent généralement sur une optimisation itérative, ce qui engendre des coûts de calcul élevés.Ces dernières années, le domaine s'est progressivement orienté vers des modèles de reconstruction géométrique de bout en bout basés sur des réseaux neuronaux à propagation directe.
Malgré les progrès significatifs réalisés, les méthodes existantes présentent encore des limitations évidentes, tant au niveau des entrées que des sorties.Du côté des données d'entrée, le modèle actuel ne parvient pas à utiliser les informations préalables facilement disponibles telles que les paramètres intrinsèques de la caméra, la pose initiale et la profondeur du capteur, car il ne traite que l'image brute.Il en résulte de faibles performances face à des problèmes tels que l'ambiguïté d'échelle, les incohérences entre plusieurs points de vue et les régions dépourvues de texture. Côté résultats, les méthodes existantes se limitent généralement à une ou quelques tâches géométriques (comme l'estimation de profondeur ou de pose), ce qui se traduit par une forte spécialisation et un manque d'intégration. Bien que des recherches comme VGGT aient favorisé l'unification des tâches, des fonctions fondamentales telles que l'estimation des normales de surface et la synthèse de nouveaux points de vue n'ont pas encore été intégrées dans un cadre unifié.
Les limitations susmentionnées soulèvent une question essentielle : est-il possible de relever simultanément les défis liés aux entrées et aux sorties dans un cadre général de reconstruction 3D en intégrant efficacement diverses informations préalables ?
Sur cette base,L'équipe Hunyuan de Tencent a lancé HunyuanWorld-Mirror, un modèle à propagation directe entièrement intégré pour des tâches de prédiction de géométrie 3D polyvalentes, conçu pour exploiter toutes les connaissances géométriques préalables disponibles afin d'effectuer des tâches générales de reconstruction 3D.Au cœur du modèle se trouve un mécanisme novateur d'amorçage multimodal qui intègre de manière flexible plusieurs informations géométriques a priori, telles que la pose de la caméra, les paramètres intrinsèques et les cartes de profondeur, tout en générant simultanément de multiples représentations 3D : nuages de points denses, cartes de profondeur multivues, paramètres de la caméra, normales aux surfaces et distributions gaussiennes 3D. Cette architecture unifiée exploite les informations a priori disponibles pour résoudre les ambiguïtés structurelles et fournit une sortie 3D géométriquement cohérente en un seul processus de propagation directe.
HunyuanWorld-Mirror exploite les connaissances a priori disponibles pour permettre une reconstruction robuste dans des scénarios difficiles, et sa conception multitâche assure une cohérence géométrique entre les différentes sorties.Des performances de pointe ont été obtenues sur un large éventail de tests de référence, allant de l'estimation de la caméra, de la carte de points, de la profondeur et de la normale de surface à la synthèse de nouvelles perspectives.
Le site web d'HyperAI propose désormais « HunyuanWorld-Mirror : un modèle de génération de monde 3D », alors venez l'essayer !
Utilisation en ligne :https://go.hyper.ai/Ptv69
Aperçu rapide des mises à jour du site web officiel d'hyper.ai du 24 au 28 novembre :
* Jeux de données publics de haute qualité : 7
* Sélection de tutoriels de haute qualité : 6
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en décembre : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
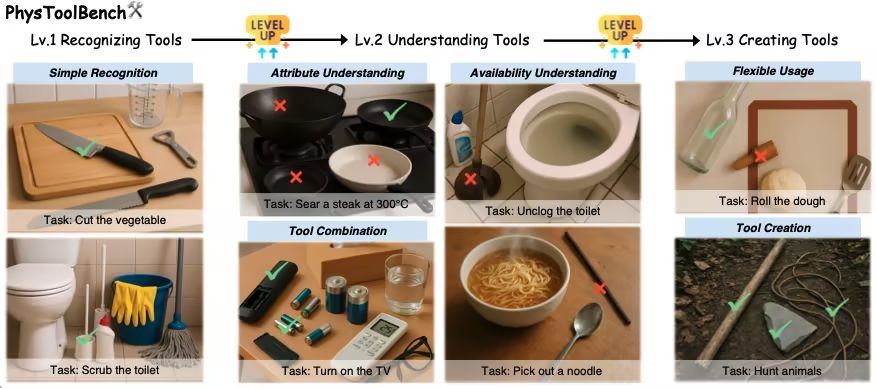
1. Ensemble de données des tâches de l'outil physique PhysToolBench
PhysToolBench est un jeu de données de questions-réponses visuelles et linguistiques (VQA) publié par l'Université des sciences et technologies de Hong Kong (Guangzhou), en collaboration avec l'Université d'aéronautique et d'astronautique de Pékin et d'autres institutions. Il vise à évaluer la capacité des modèles de langage multimodaux (MLLM) à reconnaître, comprendre et créer des outils physiques. Ce jeu de données contient plus de 1 000 paires image-texte, couvrant divers contextes tels que la vie quotidienne, l'industrie, les activités de plein air et les environnements professionnels.
Utilisation directe :https://go.hyper.ai/bP9Ad
2. Jeu de données d'images de cellules sanguines CytoData
Le jeu de données d'images de cellules sanguines CytoData est un jeu de données anonymisé publié dans la revue Nature par une équipe de recherche de l'Université de Cambridge, au Royaume-Uni. Ce jeu de données contient 2 904 frottis sanguins provenant de l'hôpital Addenbrooke de Cambridge, soit un total de 559 808 images de cellules uniques. Parmi celles-ci, 4 996 images sont annotées avec dix types de cellules sanguines, dont les érythroblastes et les éosinophiles.
Utilisation directe :https://go.hyper.ai/uLXKt
3. MeshCoder : Ensemble de données structurées de code objet 3D
MeshCoder est un jeu de données multimodal permettant de générer du code modifiable à partir de nuages de points 3D. Développé par le Laboratoire d'intelligence artificielle de Shanghai en collaboration avec l'Université Tsinghua, l'Institut de technologie de Harbin (Shenzhen) et d'autres institutions, il vise à promouvoir le développement de grands modèles de langage pour l'analyse syntaxique de scènes 3D, la compréhension structurelle et la reconstruction géométrique programmable.
Utilisation directe :https://go.hyper.ai/x3zvv
4. Ensemble de données du catalogue de films et de séries télévisées de Netflix
Le catalogue de films et séries Netflix est un ensemble de données exhaustif couvrant différents types de contenus cinématographiques et télévisuels provenant de nombreux pays à travers le monde. Il vise à illustrer la distribution globale des contenus sur la plateforme Netflix et à fournir des données utiles à la recherche sur les tendances du divertissement, les préférences du public et la stratégie de contenu. Cet ensemble de données inclut les films et séries déjà disponibles sur Netflix. Chaque entrée représente un titre et comprend des informations clés telles que le titre, le type de contenu (film ou série) et le réalisateur.
Utilisation directe :https://go.hyper.ai/8gzcZ
5. Ensemble de données d'interaction homme-objet 3D InteractMove
InteractMove est un jeu de données permettant de générer des interactions homme-objet dans des scènes 3D. Publié conjointement par l'Institut d'informatique et de technologie de l'Université de Pékin et l'Institut des sciences et technologies électroniques de Pékin, il vise à soutenir et à promouvoir la recherche sur la modélisation interactive d'objets mobiles par commande textuelle. Ce jeu de données couvre plusieurs types d'objets mobiles et diverses scènes réelles numérisées, et propose des séquences d'actions d'interaction homme-objet parfaitement alignées sur la scène.
Utilisation directe :https://go.hyper.ai/uFrPd
6. Ensemble de données d'entraînement au fonctionnement de l'interface GroundCUA
GroundCUA est un ensemble de données d'interfaces utilisateur réelles, publié par l'Institut d'intelligence artificielle Mila de Québec en collaboration avec l'Université McGill, l'Université de Montréal et d'autres institutions. Il vise à soutenir la recherche sur les agents intelligents multimodaux capables d'interagir avec les ordinateurs. Cet ensemble de données repose sur des démonstrations humaines réalisées par des experts et comprend plus de 3,56 millions d'annotations au niveau des éléments, vérifiées manuellement.
Utilisation directe :https://go.hyper.ai/5bDrX
7. Ensemble de données multivues de clones de caméra
Camera Clone, développé par l'Université de Hong Kong en collaboration avec l'Université du Zhejiang, Kuaishou Technology et d'autres institutions, est un vaste ensemble de données vidéo synthétiques basé sur le rendu Unreal Engine 5. Il vise à faciliter l'apprentissage par clonage de caméra, qui consiste à reproduire les mouvements de caméra d'une vidéo de référence tout en conservant le contenu de la scène, réalisant ainsi une « reproduction du contenu associée à une correspondance des mouvements de caméra ».
Utilisation directe :https://go.hyper.ai/US4nY
Tutoriels publics sélectionnés
1. Tutoriel officiel PyTorch : Implémentation de l’apprentissage profond avec PyTorch
L'objectif de ce tutoriel est de comprendre comment utiliser les tenseurs et construire des réseaux neuronaux dans PyTorch, et d'entraîner un petit réseau neuronal à classifier des images.
Exécutez en ligne :https://go.hyper.ai/Fb2c6
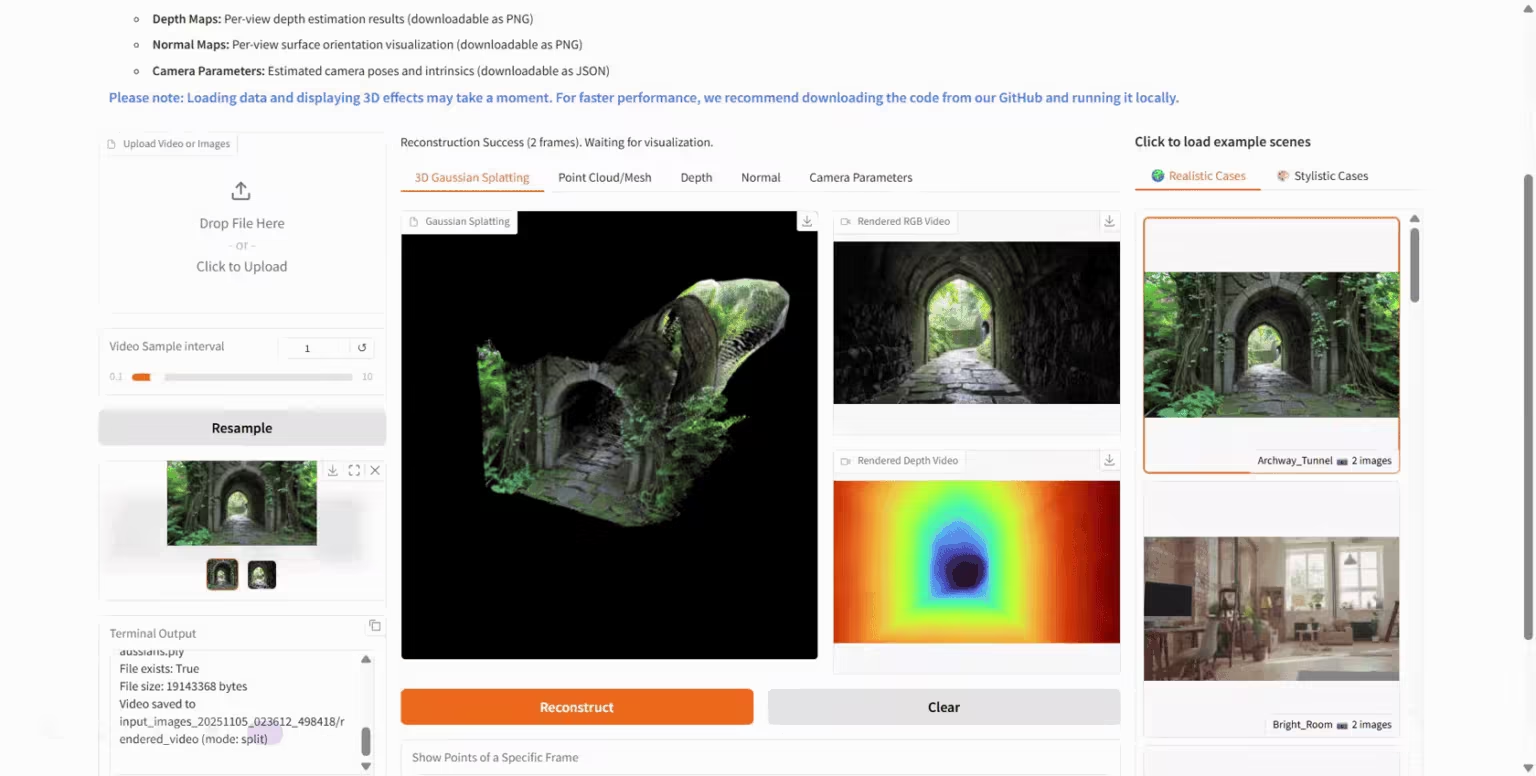
2. HunyuanWorld-Mirror : un modèle de génération de monde 3D
HunyuanWorld-Mirror est un modèle de génération de monde 3D open source développé par l'équipe Hunyuan de Tencent. Il prend en charge plusieurs méthodes d'entrée, notamment les images et vidéos multivues, et peut produire divers résultats de prédiction géométrique 3D tels que des nuages de points, des cartes de profondeur et des paramètres de caméra. Ce modèle, basé sur une architecture feedforward pure, peut être déployé sur une seule carte graphique et traite localement 8 à 32 entrées de vue en seulement une seconde, réalisant ainsi une inférence de second niveau.
Exécutez en ligne :https://go.hyper.ai/Ptv69
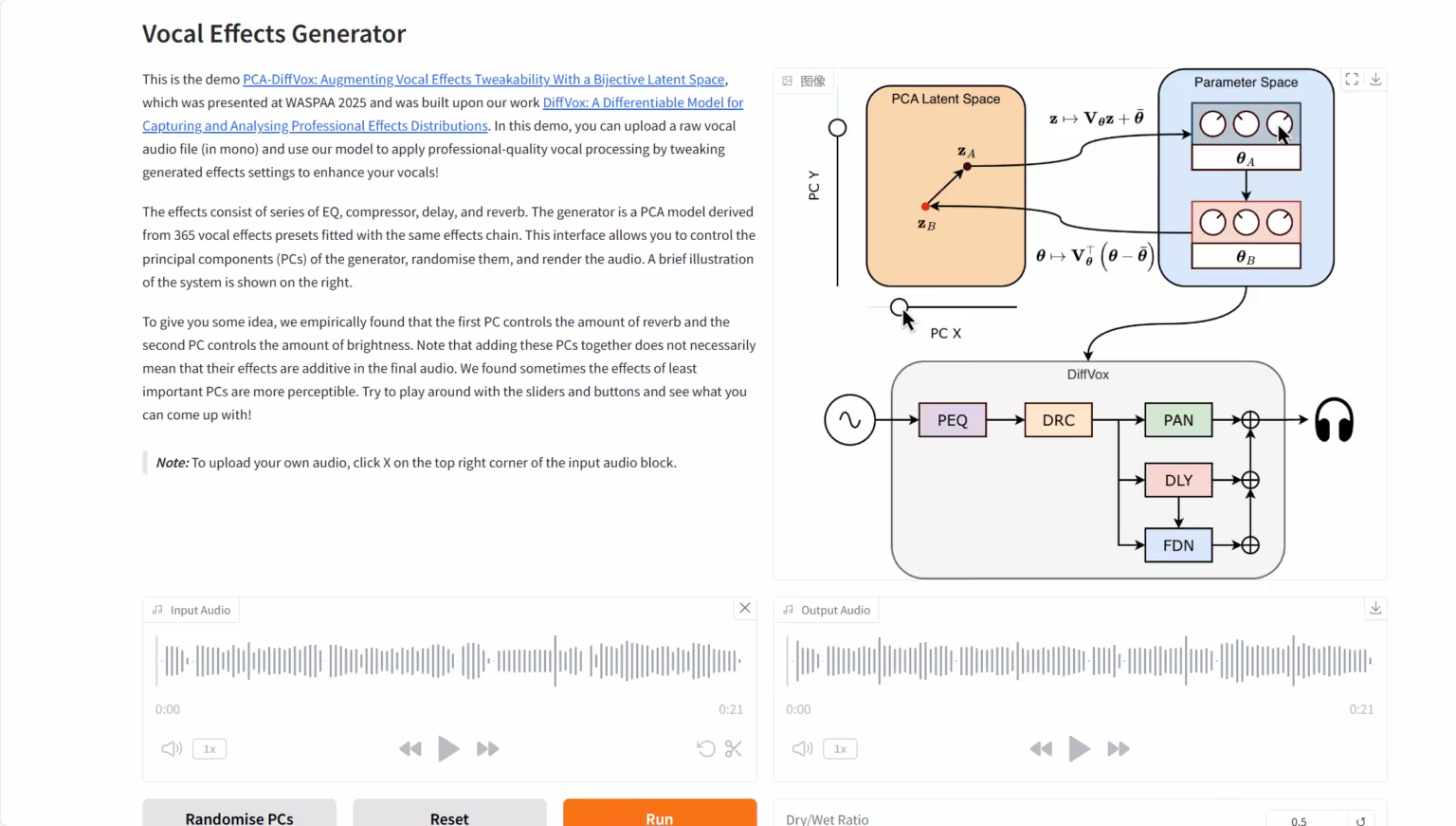
3. DiffVox : Modèle de différenciation sonore
Le projet DiffVox a été lancé conjointement par Sony AI, le groupe Sony et une équipe de recherche de l'université Queen Mary de Londres. La force de ce modèle réside dans l'utilisation de méthodes d'optimisation avancées au moment de l'inférence et dans l'introduction novatrice de contraintes a priori gaussiennes. Grâce à ces caractéristiques, il transforme intelligemment un enregistrement vocal brut en un signal audio de haute qualité, audiblement proche de la référence cible et conforme aux normes de mixage professionnelles en termes de paramètres.
Exécutez en ligne :https://go.hyper.ai/Y19Wv
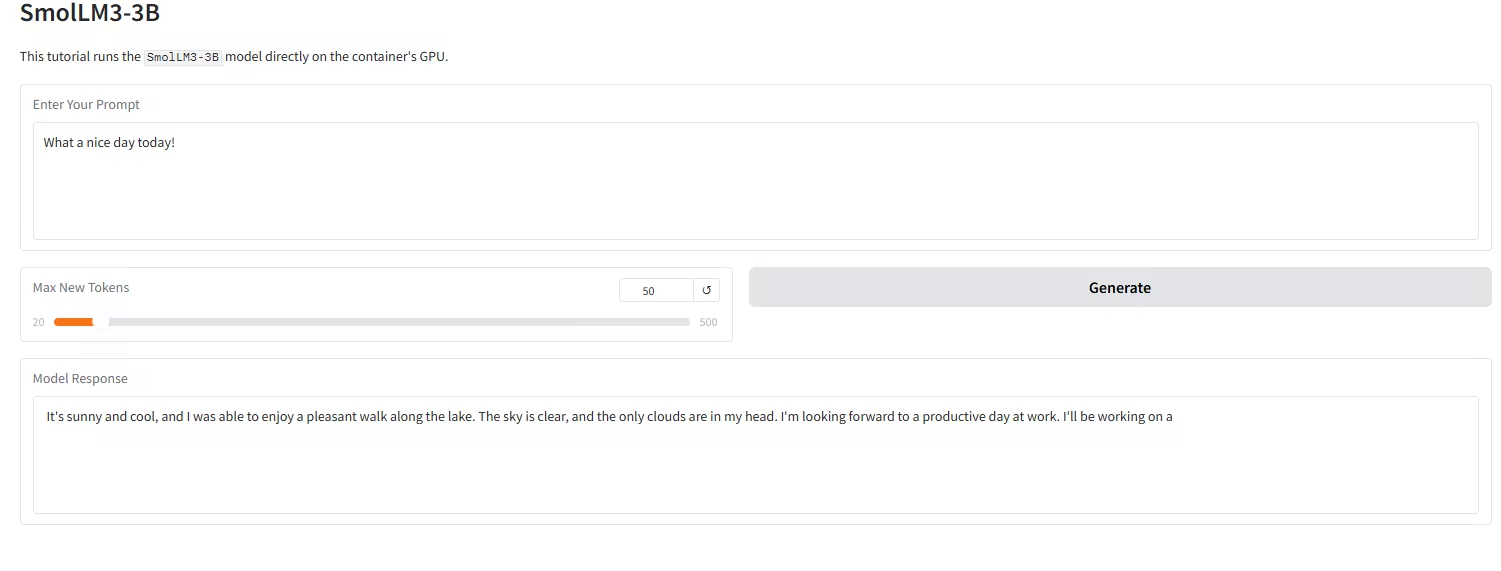
4. Déploiement en un clic du modèle SmolLM3-3B
SmolLM3-3B, développé par l'équipe Hugging Face TB (Transformer Big), est présenté comme le « plafond des performances de pointe ». Il s'agit d'un modèle de langage open-source révolutionnaire doté de 3 milliards de paramètres, visant à dépasser les limites de performance des petits modèles dans une taille compacte de 3 milliards.
Exécutez en ligne :https://go.hyper.ai/wZ48d
5. PixelReasoner-RL : Modèle d’inférence visuelle au niveau du pixel
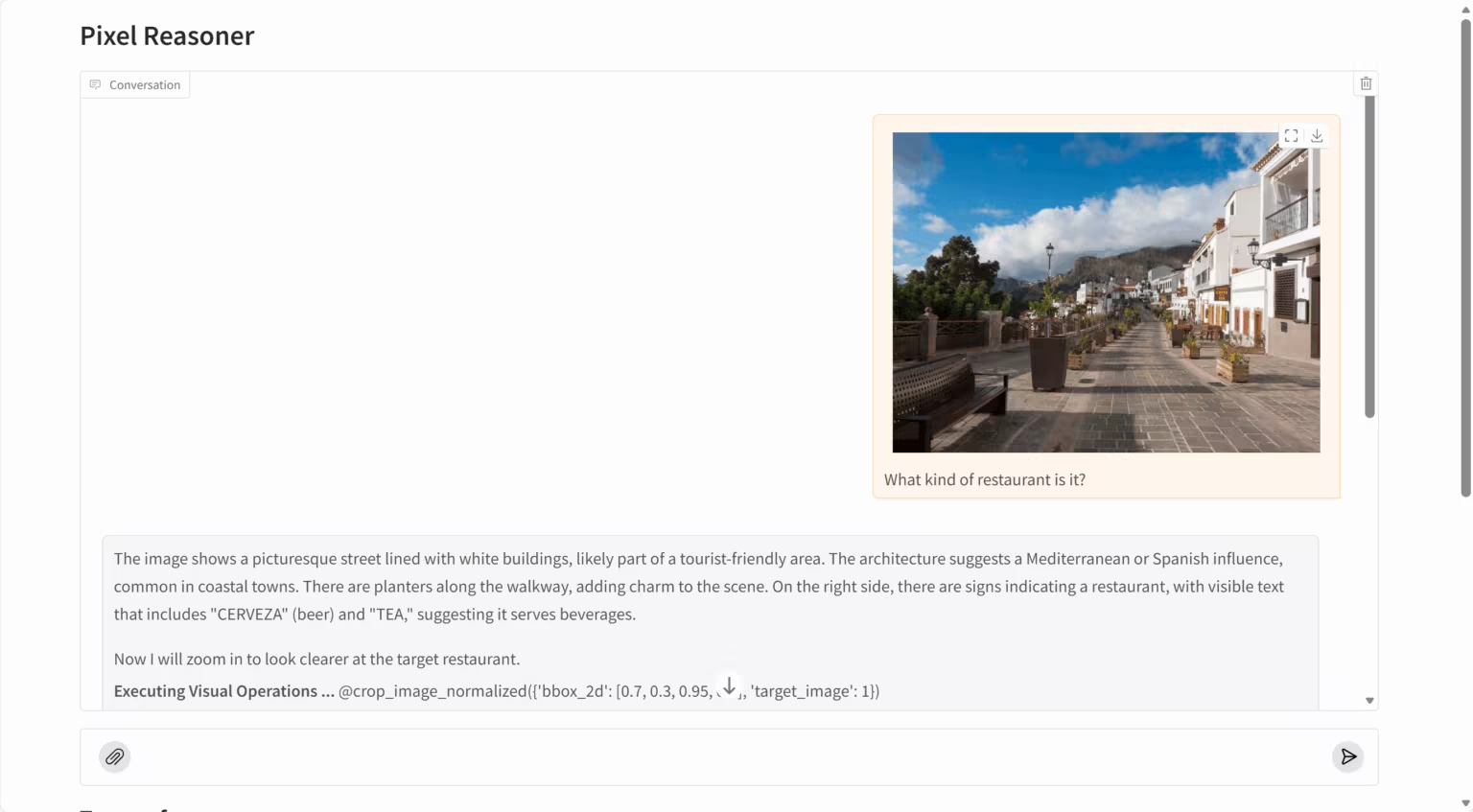
PixelReasoner-RL-v1 est un modèle de langage visuel révolutionnaire développé par TIGER AI Lab. Basé sur l'architecture Qwen2.5-VL, ce projet utilise une méthode d'apprentissage par renforcement innovante, guidée par la curiosité, pour surmonter les limitations des modèles de langage visuel traditionnels qui s'appuient uniquement sur le raisonnement textuel. Le modèle peut raisonner directement dans l'espace pixel, prenant en charge des opérations visuelles telles que la mise à l'échelle et la sélection d'images, ce qui améliore considérablement sa capacité à comprendre les détails des images, les relations spatiales et le contenu vidéo.
Exécutez en ligne :https://go.hyper.ai/t1rdr
6. Krea-realtime-video : Modèle de génération vidéo en temps réel
Krea Realtime 14B est un modèle de génération vidéo en temps réel à 14 milliards de paramètres, développé par l'équipe Krea. Il permet la génération de vidéos longues en temps réel et figure parmi les plus grands modèles de ce type disponibles publiquement. Basé sur le modèle de conversion texte-vidéo Wan 2.1 14B, ce modèle utilise un apprentissage par distillation auto-forcée pour transformer le modèle de diffusion vidéo traditionnel en une structure autorégressive, offrant ainsi une expérience de génération vidéo véritablement en temps réel.
Exécutez en ligne :https://go.hyper.ai/GS7oW

Recommandation de papier de cette semaine
1. Mémoire agentique générale via la recherche approfondie
Cet article propose un nouveau cadre de travail appelé General Agentic Memory (GAM). Ce cadre suit le principe du « juste-à-temps » (JIT) : il ne conserve hors ligne que des mémoires simples mais pratiques, tout en se concentrant sur la construction de contextes optimisés pour ses clients lors de l’exécution. Des études expérimentales démontrent que GAM améliore significativement les performances dans divers scénarios d’exécution de tâches en mémoire, par rapport aux systèmes de mémoire existants.
Lien vers l'article :https://go.hyper.ai/sA1RN
2. ROOT : Optimiseur orthogonalisé robuste pour l’apprentissage des réseaux de neurones
Cet article propose ROOT, un optimiseur orthogonalisé robuste, qui améliore considérablement la stabilité de l'apprentissage grâce à un mécanisme de robustesse double. De nombreux résultats expérimentaux démontrent que ROOT présente une robustesse nettement supérieure dans les environnements bruités et les scénarios d'optimisation non convexes. Comparé aux optimiseurs basés sur Muon et Adam, il converge non seulement plus rapidement, mais atteint également des performances finales supérieures.
Lien vers l'article :https://go.hyper.ai/gv0x2
3. GigaEvo : un framework d’optimisation open source basé sur les LLM et les algorithmes d’évolution
Cet article propose GigaEvo, un framework open source évolutif conçu pour accompagner les chercheurs dans leurs travaux sur les méthodes de calcul hybrides LLM-évolutionnaires inspirées d'AlphaEvolve. Le système GigaEvo fournit des implémentations modulaires de plusieurs composants essentiels : l'algorithme qualité-diversité MAP-Elites, un pipeline d'évaluation asynchrone basé sur des graphes acycliques orientés (DAG), un opérateur de mutation piloté par LLM doté de capacités génératives performantes, et un mécanisme de traçage de lignées bidirectionnel, tout en prenant en charge des stratégies évolutionnaires multi-îles flexibles.
Lien vers l'article :https://go.hyper.ai/jN3Q1
4. SAM 3 : Segmenter tout avec des concepts
Cet article propose Segment Anything Model (SAM) 3, un modèle unifié capable de détecter, segmenter et suivre des objets dans des images et des vidéos à partir d'instructions conceptuelles. SAM 3 atteint une précision deux fois supérieure à celle des systèmes existants pour les tâches de segmentation d'images et de vidéos, et améliore les performances des générations précédentes de SAM pour les tâches de segmentation visuelle. SAM 3 est désormais open source, et un nouveau benchmark pour la segmentation conceptuelle guidée par des instructions, Segment Anything with Concepts (SA-Co), a également été publié.
Lien vers l'article :https://go.hyper.ai/KN3g7
5. OpenMMReasoner : Repousser les frontières du raisonnement multimodal grâce à une recette ouverte et générale
Cet article présente OpenMMReasoner, un schéma d'entraînement à l'inférence multimodale en deux étapes, entièrement transparent, combinant l'ajustement supervisé (SFT) et l'apprentissage par renforcement (RL). Lors de l'étape SFT, les chercheurs ont constitué un jeu de données initialisé à froid de 874 000 échantillons et mis en œuvre un mécanisme de validation rigoureux et progressif afin d'établir des bases solides pour les capacités d'inférence. L'étape RL suivante utilise un jeu de données de 74 000 échantillons couvrant plusieurs domaines pour renforcer et stabiliser ces capacités, permettant ainsi un processus d'apprentissage plus robuste et efficace.
Lien vers l'article :https://go.hyper.ai/OfXKY
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
1. Le premier modèle astronomique multimodal, AION-1, a été développé avec succès ! L'UC Berkeley et d'autres chercheurs ont réussi à construire un cadre d'IA astronomique multimodal généralisé basé sur un pré-entraînement sur 200 millions de cibles astronomiques.
Des équipes issues de plus de dix institutions de recherche du monde entier, dont l'Université de Californie à Berkeley, l'Université de Cambridge et l'Université d'Oxford, ont collaboré au lancement d'AION-1, la première famille de modèles multimodaux fondamentaux à grande échelle pour l'astronomie. Grâce à un réseau dorsal de fusion précoce unifié, ce modèle intègre et modélise des informations observationnelles hétérogènes telles que des images, des spectres et des données de catalogues d'étoiles. Il offre non seulement d'excellentes performances dans des scénarios sans données d'observation préalables, mais sa précision de détection linéaire peut également rivaliser, voire surpasser, celle de modèles spécifiquement entraînés pour des tâches particulières.
Voir le rapport complet :https://go.hyper.ai/2zA0f
2. Le modèle de génération vidéo open-source de Meituan, LongCat-Video, possède trois capacités majeures : la génération vidéo basée sur du texte, la génération vidéo basée sur des images et la continuation vidéo, comparables aux modèles open-source et propriétaires de premier plan.
Meituan a publié en open source son dernier modèle de génération vidéo, LongCat-Video. Ce modèle vise à gérer diverses tâches de génération vidéo grâce à une architecture unifiée, notamment la conversion de texte en vidéo, d'image en vidéo et la continuation vidéo. Fort de ses performances exceptionnelles dans les tâches générales de génération vidéo, l'équipe de recherche considère LongCat-Video comme une avancée majeure vers la construction d'un véritable « modèle du monde ».
Voir le rapport complet :https://go.hyper.ai/b6pzF
3. Utilisation gratuite du processeur / 30 heures de crédit d'utilisation du GPU / 70 Go de stockage super large, HyperAI Pro est officiellement lancé !
HyperAI a sélectionné des centaines de tutoriels d'apprentissage automatique et les a compilés dans des notebooks Jupyter, permettant ainsi aux débutants comme aux ingénieurs expérimentés d'accéder facilement à des projets open source de haute qualité ou de créer et déployer des modèles entièrement nouveaux. HyperAI fournit une puissance de calcul stable pour accompagner les projets d'IA, de l'idée initiale au déploiement rapide. Afin de mieux répondre aux besoins de ses utilisateurs et de proposer des options de facturation plus flexibles et abordables, HyperAI a officiellement lancé son système d'abonnement HyperAI Pro.
Voir le rapport complet :https://go.hyper.ai/Oi7d3
4. L'université de Cambridge développe un classificateur d'images de cellules sanguines ; un modèle de diffusion aide à la détection de la leucémie, surpassant les capacités des experts cliniques.
Une équipe de recherche de l'Université de Cambridge, au Royaume-Uni, a proposé CytoDiffusion, une méthode de classification d'images de cellules sanguines basée sur un modèle de diffusion. Ce modèle reproduit fidèlement la distribution morphologique des cellules sanguines pour une classification précise, tout en offrant de solides capacités de détection d'anomalies, une grande robustesse face aux variations de distribution, une interprétabilité aisée, une efficacité de traitement des données élevée et des capacités de quantification de l'incertitude supérieures à celles des experts cliniques.
Voir le rapport complet :https://go.hyper.ai/QSCmq
5. Le PDG de Broadcom, âgé de 72 ans et qui a bâti son entreprise sur des acquisitions, a prolongé son contrat jusqu'en 2030, dans le but d'augmenter les revenus de l'entreprise liés à l'IA à 120 milliards de dollars.
En consultant le CV de Hock Tan, les fusions-acquisitions sont un sujet incontournable. Cependant, le considérer uniquement sous l'angle de l'investissement serait réducteur. Au-delà des simples calculs de profit et de chiffre d'affaires, chacune de ses décisions contribue à hisser progressivement son entreprise au rang de pilier stratégique ; les prévisions de tendances sous-jacentes sont d'autant plus cruciales.
Voir le rapport complet :https://go.hyper.ai/6lPG5
Articles populaires de l'encyclopédie
1. DALL-E
2. Hyperréseaux
3. Front de Pareto
4. Mémoire bidirectionnelle à long terme (Bi-LSTM)
5. Fusion de rang réciproque
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Conférence de haut niveau avec une date limite en décembre

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 800 ensembles de données publics
* Comprend plus de 600 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








