Command Palette
Search for a command to run...
Des Coûts Considérablement Réduits ! Distill-Any-Depth Permet Une Estimation De Profondeur De Haute Précision ; Sélectionné Pour Le CVPR 2025 ! Real-IADD Ouvre De Nouveaux Horizons En Matière De Détection industrielle.

L'estimation de profondeur métrique monoculaire est une technique de vision par ordinateur qui vise à prédire la profondeur absolue à partir d'une seule image RVB. Cette technique trouve de nombreuses applications dans des domaines tels que la conduite autonome, la réalité augmentée, la robotique et la compréhension de scènes 3D.
L'estimation monoculaire de la profondeur (MDE) à zéro coup améliore considérablement les capacités de généralisation en unifiant la distribution de la profondeur et en exploitant des données non étiquetées à grande échelle. Cependant, les méthodes existantes traitent toutes les valeurs de profondeur de manière uniforme, ce qui peut amplifier le bruit dans les pseudo-étiquettes et réduire l'effet de distillation. Sur cette base, l'Université de technologie du Zhejiang et plusieurs autres universités ont publié Distill-Any-Depth.
Distill-Any-Depth intègre les avantages de plusieurs modèles open source grâce à l'algorithme de distillation et permet une estimation de profondeur de haute précision avec seulement une petite quantité de données non étiquetées.Comparé aux méthodes traditionnelles qui nécessitent des millions d’annotations, ce projet ne nécessite que 20 000 images non étiquetées, ce qui réduit considérablement les coûts d’annotation des données.
HyperAI a lancé le tutoriel « Distill-Any-Depth : Estimateur de profondeur monoculaire ». Venez l'essayer !
Distill-Any-Depth : estimateur de profondeur monoculaire
Utilisation en ligne :https://go.hyper.ai/DNSf5
Du 16 au 20 juin, le site officiel hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 14
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juillet : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
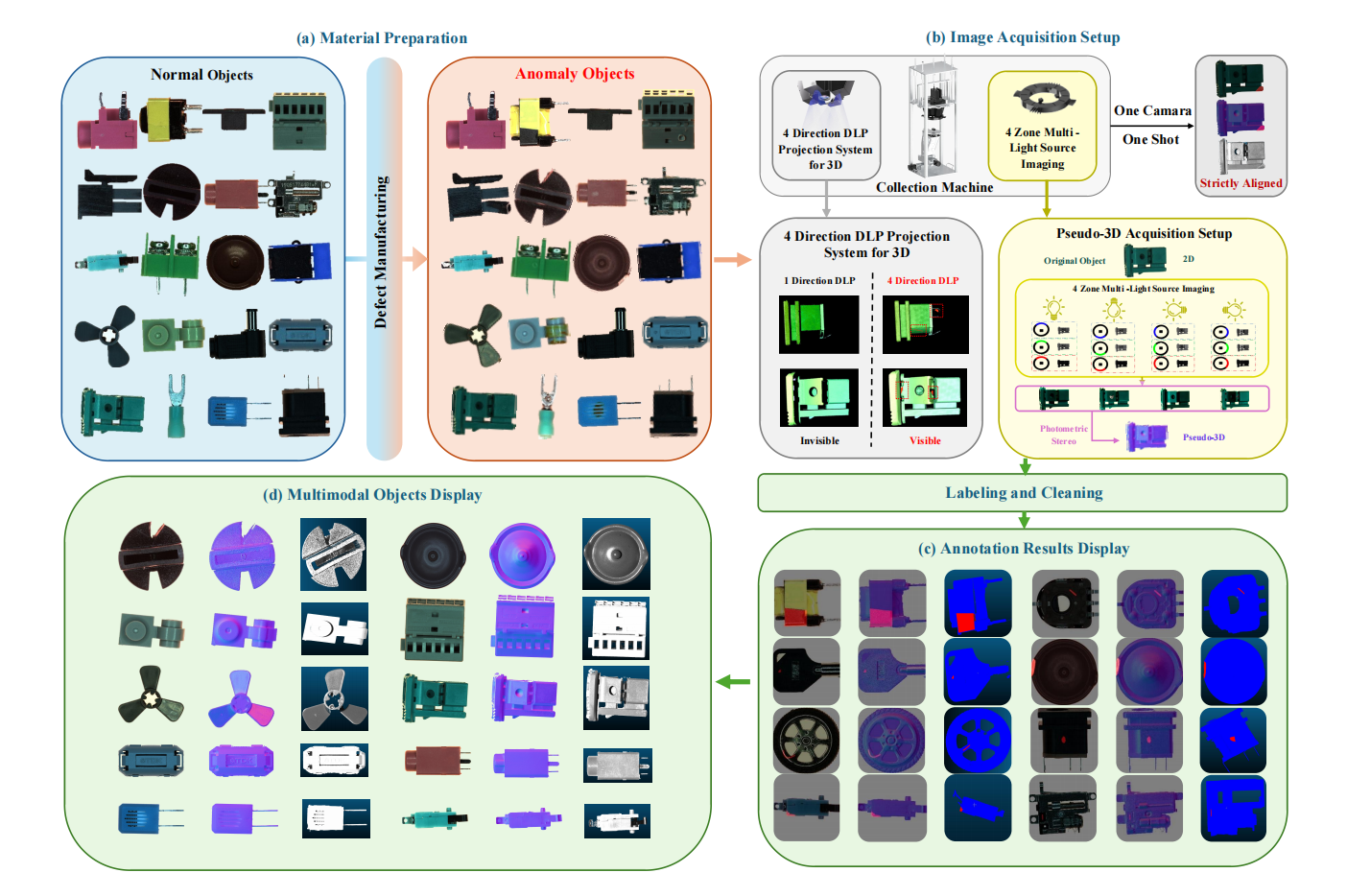
1. Ensemble de données de détection d'anomalies industrielles Real-IAD D³
Real-IAD D³ est un ensemble de données multimodales de haute précision, et des articles connexes ont été inclus dans la principale conférence sur la vision par ordinateur CVPR 2025. L'ensemble de données contient 20 catégories de produits industriels, 69 types de défauts et un total de 8 450 échantillons, dont 5 000 échantillons normaux et 3 450 échantillons anormaux.
Utilisation directe :https://go.hyper.ai/i4T8m
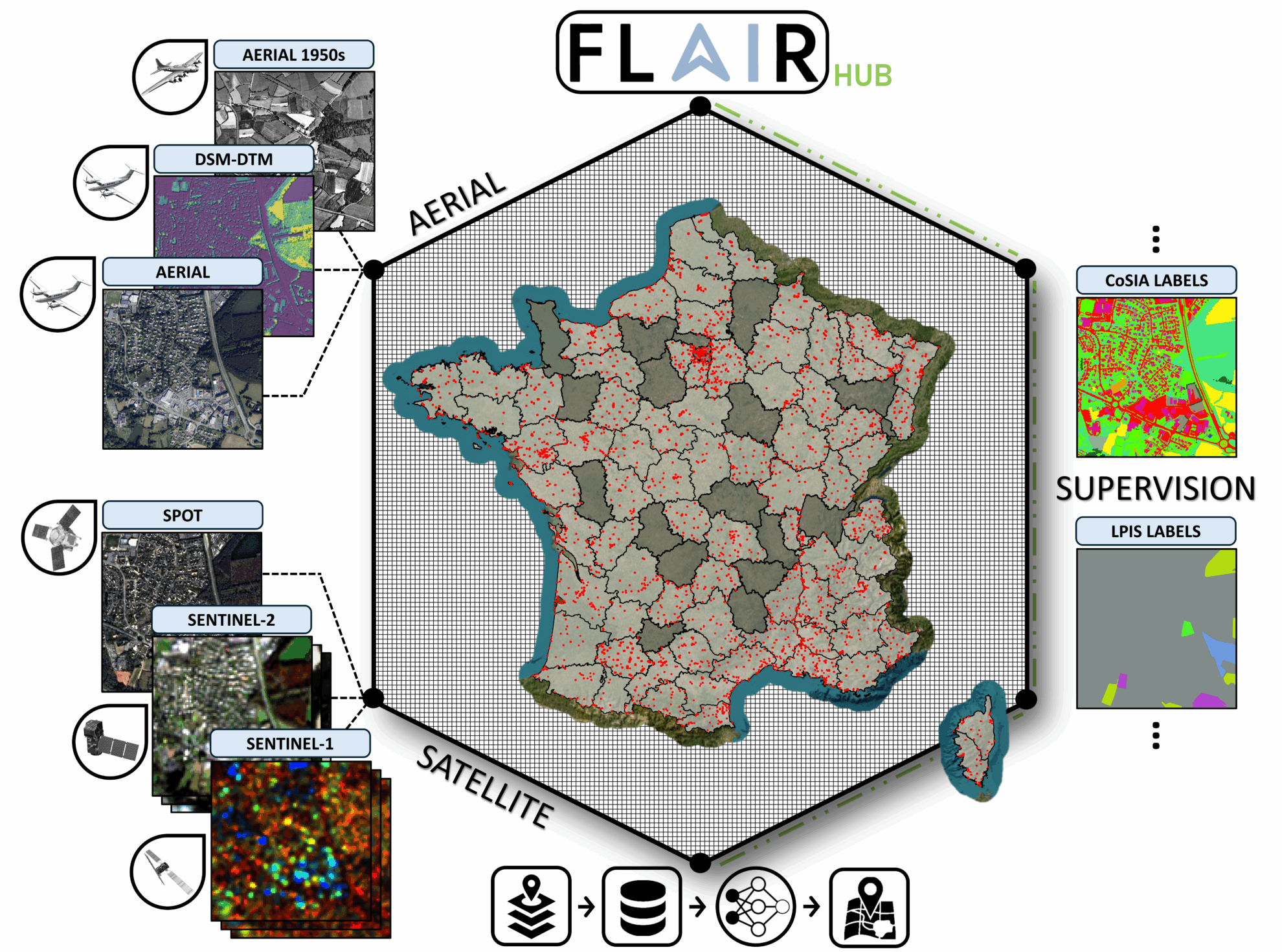
2. Ensemble de données foncières françaises multi-capteurs FLAIR HUB
FLAIR-HUB couvre plus de 2 500 km2 des divers écoclimats et paysages de France, englobant 19 classes d'occupation du sol et 23 catégories de cultures, et contient 63 milliards de pixels annotés manuellement, tout en intégrant des sources de données complémentaires.
Utilisation directe :https://go.hyper.ai/4VvCI
3. Ensemble de données de raisonnement mathématique MathFusionQA
MathFusionQA se concentre sur le raisonnement et la résolution de problèmes mathématiques en plusieurs étapes. L'ensemble de données contient 59 000 exemples de questions-réponses mathématiques de haute qualité, couvrant divers types de questions, tels que les opérations arithmétiques, les équations algébriques, les applications géométriques, le raisonnement logique, etc. Les scénarios de questions sont riches et couvrent des applications quotidiennes, des formations académiques, etc., visant à améliorer la capacité de résolution de problèmes mathématiques du modèle de langage étendu (LLM).
Utilisation directe :https://go.hyper.ai/uGR9C
4. Ensemble de données de livres Institutional Books 1.0
Institutional Books comprend 983 004 livres du domaine public en 254 langues, principalement publiés aux XIXe et XXe siècles. Cet ensemble de données comprend 242 milliards de jetons et 386 millions de pages de texte, et est disponible aux formats d'exportation OCR bruts et post-traités.
Utilisation directe :https://go.hyper.ai/ZsSI7
5. Ensemble de données de raisonnement médical ReasonMed
ReasonMed est le plus grand ensemble de données open source de raisonnement médical, conçu pour entraîner et évaluer des modèles pour des tâches telles que la réponse à des questions médicales et la génération de texte. Cet ensemble de données contient 370 000 exemples de questions-réponses de haute qualité, couvrant de nombreux domaines tels que les connaissances cliniques, l'anatomie et la génétique.
Utilisation directe :https://go.hyper.ai/DwGmH
6. Ensemble de données de réponses aux questions médicales Miriad-5,8M
L'ensemble de données contient 5,82 millions de paires questions-réponses médicales, couvrant tous les aspects, de la science fondamentale à la pratique clinique. MIRIAD fournit des paires questions-réponses structurées et de haute qualité pour soutenir diverses tâches en aval, telles que le RAG, la récupération médicale, la détection des hallucinations et l'adaptation des instructions.
Utilisation directe :https://go.hyper.ai/Xw8Ph
7. Ensemble de données textuelles ouvertes à grande échelle Common Corpus
Cet ensemble de données est actuellement le plus grand ensemble de données textuelles sous licence ouverte, contenant 2 000 milliards de jetons, couvrant du contenu dans de multiples domaines tels que les livres, la littérature scientifique, les codes, les documents juridiques, etc. ; les principales langues sont l'anglais et le français, et il comprend également 8 langues avec plus de 10 milliards de jetons (allemand/espagnol/italien, etc.) et 33 langues avec plus d'un milliard de jetons.
Utilisation directe :https://go.hyper.ai/PnbfK
8. Ensemble de données de référence HLE sur le raisonnement humain par questions
HLE vise à créer le système d'évaluation fermé ultime, repoussant les limites de la connaissance humaine. L'ensemble de données contient 2 500 questions couvrant des dizaines de disciplines telles que les mathématiques, les sciences humaines et les sciences naturelles, y compris des questions à choix multiples et des questions à réponse courte adaptées à la notation automatique.
Utilisation directe :https://go.hyper.ai/Lq7mE
9. Ensemble de données de raisonnement sur les cas médicaux MedCaseReasoning
MedCaseReasoning contient 13 000 cas, couvrant de multiples disciplines telles que la médecine interne, la neurologie, les maladies infectieuses et la cardiologie. Cet ensemble de données intègre l'intégralité du processus de diagnostic et de traitement de cas cliniques multispécialités, couvrant des tâches essentielles telles que le diagnostic des maladies, l'analyse différentielle et la prise de décision thérapeutique. Il vise à fournir des ressources standardisées pour l'évaluation de la capacité de raisonnement des grands modèles de langage médicaux.
Utilisation directe :https://go.hyper.ai/4vqwo
10. Ensemble de données d'alignement image-texte FineHARD
FineHARD est un jeu de données open source d'alignement image-texte de haute qualité. Ce jeu de données, caractérisé par son échelle et son raffinement, contient 12 millions d'images et leurs descriptions longues et courtes correspondantes, couvrant 40 millions de cadres de délimitation.
Utilisation directe :https://go.hyper.ai/L2TOZ
Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 4 catégories de tutoriels publics de haute qualité :
*Tutoriels de déploiement de grands modèles : 5
*Tutoriels de traitement multimodal : 4
*Tutoriels de reconstruction 3D : 3
*Tutoriel de reconnaissance OCR : 2
Déploiement de grands modèlesTutoriel
1. Déploiement vLLM+Open WebUI KernelLLM-8B
KernelLLM vise à traduire automatiquement les modules PyTorch en code noyau Triton performant, simplifiant et accélérant ainsi le processus de programmation GPU hautes performances. Le modèle, basé sur l'architecture Llama 3.1 Instruct, comporte 8 milliards de paramètres et vise à générer des implémentations noyau Triton performantes.
Exécutez en ligne :https://go.hyper.ai/DfoWo
2. Déploiement vLLM+Open WebUI MiniCPM4-8B
MiniCPM 4.0 permet un raisonnement haute performance à faible coût de calcul grâce à des technologies telles que l'architecture parcimonieuse, la compression de quantification et un cadre de raisonnement efficace. Il est particulièrement adapté au traitement de textes longs, aux scénarios sensibles à la confidentialité et au déploiement d'appareils informatiques de pointe. Lors du traitement de séquences longues, le modèle affiche une vitesse de traitement nettement supérieure à celle de Qwen3-8B.
Exécutez en ligne :https://go.hyper.ai/kcANp
3. Déploiement vLLM+Open WebUI FairyR1-14B-Preview
FairyR1-14B-Preview se concentre sur les tâches mathématiques et de programmation. Le modèle est basé sur la base DeepSeek-R1-Distill-Qwen-32B et est construit en combinant des techniques de réglage fin et de fusion de modèles.
Exécutez en ligne :https://go.hyper.ai/8jwGm
4. Tutoriel d'évaluation comparative des modèles de séries d'intégration Qwen3
La famille Qwen3 Embedding représente une avancée significative dans une variété de tâches d'intégration et de classement de texte, notamment la récupération de texte, la récupération de code, la classification de texte, le regroupement de texte et l'exploration de bi-texte.
Grâce à ce didacticiel, vous comprendrez systématiquement les concepts de base des modèles intégrés et des modèles de réorganisation, et apprendrez à les sélectionner et à les appliquer dans des scénarios pratiques.
Exécutez en ligne :https://go.hyper.ai/YtMdH
5. Déploiement vLLM+Open WebUI Devstral-Small-2505
Devstral excelle dans l'utilisation d'outils permettant d'explorer des bases de code, de modifier plusieurs fichiers et de piloter des agents d'ingénierie logicielle. Le modèle a obtenu de bons résultats sur SWE-bench, devenant le modèle open source numéro un du benchmark.
Exécutez en ligne :https://go.hyper.ai/mnGzy
Tutoriel sur le traitement multimodal
1. Déploiement en un clic de VideoLLaMA3-7B
VideoLLaMA3 est un modèle de base multimodal open source dédié à la compréhension d'images et de vidéos. Il améliore considérablement la précision et l'efficacité de la compréhension vidéo grâce à une architecture centrée sur la vision et à une ingénierie des données de haute qualité.
Ce didacticiel utilise une seule ressource informatique RTX 4090 et déploie le modèle VideoLLaMA3-7B-Image, qui fournit deux exemples : la compréhension vidéo et la compréhension d'image.
Exécutez en ligne :https://go.hyper.ai/t2z4d
2. Step1X-Edit : Outil d'édition d'images
Step1X-Edit offre trois fonctionnalités clés : une analyse sémantique précise, le maintien de la cohérence des identités et un contrôle de zone de haute précision. Il prend en charge 11 types de tâches d'édition d'images à haute fréquence, telles que le remplacement de texte, le transfert de style, la transformation de matériaux et la retouche de caractères.
Exécutez en ligne :https://go.hyper.ai/MdDTI

3. Chain-of-Zoom : démonstration d'agrandissement des détails d'une image en super-résolution
Chain-of-Zoom est un framework de zoom chaîné (COZ) qui résout le problème des modèles modernes de super-résolution d'image unique (SISR) lorsqu'ils sont sollicités pour zoomer bien au-delà de cette plage. Le modèle SR de diffusion 4x standard encapsulé dans le framework COZ peut atteindre un zoom supérieur à 256x tout en conservant une qualité et une fidélité perceptuelles élevées.
Exécutez en ligne :https://go.hyper.ai/7Lixx

4. Sa2VA : Vers une compréhension perceptive dense des images et des vidéos
Sa2VA est le premier modèle unifié pour la compréhension perceptive dense des images et des vidéos. Contrairement aux modèles de langage multimodaux existants, souvent limités à des modalités et tâches spécifiques, Sa2VA prend en charge un large éventail de tâches d'images et de vidéos, notamment la segmentation de référence et la conversation, avec un réglage fin minimal en une seule étape.
Exécutez en ligne :https://go.hyper.ai/tj2bX
Tutoriel de reconstruction 3D
1. Distill-Any-Depth : estimateur de profondeur monoculaire
Le projet intègre les avantages de plusieurs modèles open source grâce à l'algorithme de distillation, permettant une estimation de profondeur de haute précision avec seulement une petite quantité de données non étiquetées, actualisant ainsi les performances actuelles de SOTA (State-of-the-Art).
Exécutez en ligne :https://go.hyper.ai/DNSf5

2. VGGT : un modèle de vision 3D général
VGGT est un réseau neuronal à rétroaction directe qui déduit directement toutes les propriétés 3D clés d'une scène, y compris les paramètres extrinsèques et intrinsèques de la caméra, les cartes de points, les cartes de profondeur et les trajectoires des points 3D, à partir d'une, de quelques ou de centaines de vues en quelques secondes. Simple et efficace, il permet une reconstruction en moins d'une seconde, surpassant même les méthodes alternatives nécessitant un post-traitement par des techniques d'optimisation de la géométrie visuelle.
Exécutez en ligne :https://go.hyper.ai/e8xzG
3. UniDepthV2 : estimation de la profondeur métrique monoculaire universelle
UniDepthV2 est capable de reconstruire des scènes 3D métriques à partir d'une seule image, sur plusieurs domaines. Contrairement au paradigme MMDE existant, UniDepthV2 prédit directement les points 3D métriques à partir de l'image d'entrée au moment de l'inférence, sans aucune information supplémentaire, s'efforçant ainsi d'obtenir une solution MMDE générale et flexible.
Exécutez en ligne :https://go.hyper.ai/JdgZC
Tutoriel de reconnaissance OCR
1. MonkeyOCR : analyse de documents basée sur le triple paradigme structure-reconnaissance-relation
MonkeyOCR permet la conversion efficace de documents non structurés en informations structurées. Ce modèle prend en charge divers types de documents, notamment les articles universitaires, les manuels scolaires et les journaux, et est applicable à plusieurs langues, offrant ainsi un support performant pour la numérisation et le traitement automatisé des documents.
Exécutez en ligne :https://go.hyper.ai/s9GE2
2. Nanonets-OCR-s : Outil d'extraction et d'analyse comparative des informations documentaires
Nanonets-OCR-s reconnaît divers éléments dans les documents, tels que les formules mathématiques, les images, les signatures, les filigranes, les cases à cocher et les tableaux, et les organise au format Markdown structuré. Cette capacité en fait un outil idéal pour le traitement de documents complexes, tels que les travaux universitaires, les documents juridiques ou les rapports commerciaux.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource. Il propose deux fonctions : l'extraction d'informations et d'images de documents et la conversion de PDF en Markdown.
Exécutez en ligne :https://go.hyper.ai/1uPym
Nous avons également créé un groupe d'échange de tutoriels sur la diffusion stable. N'hésitez pas à ajouter Neural Star (identifiant WeChat : Hyperai01) et à ajouter [Tutoriel SD] pour rejoindre le groupe afin de discuter de divers problèmes techniques et de partager les résultats de vos applications.
Recommandation de papier de cette semaine
1.FocalAD : planification locale des mouvements pour une conduite autonome de bout en bout
Cet article propose FocalAD, un nouveau framework de conduite autonome de bout en bout qui se concentre sur les voisins locaux critiques et optimise la planification en améliorant la représentation locale des mouvements. Plus précisément, FocalAD comprend deux modules principaux : Interacteur d'agent local autonome (ELAI) et Perte d'agent local focal (FLA).
Lien vers l'article :https://go.hyper.ai/vjBZy
2. Biomni : un agent IA biomédical à usage général
Nous présentons Biomni : un assistant d'IA biomédicale polyvalent conçu pour réaliser de manière autonome un large éventail de tâches de recherche dans de multiples domaines biomédicaux. Pour cartographier systématiquement l'espace d'action biomédical, Biomni exploite des agents de découverte d'actions afin d'exploiter des outils, des bases de données et des protocoles clés issus de dizaines de milliers d'articles couvrant 25 domaines biomédicaux, créant ainsi le premier environnement d'agent unifié.
Lien vers l'article :https://go.hyper.ai/zTFzy
3.SeerAttention-R : Adaptation de l'attention clairsemée pour un raisonnement long
Cet article présente SeerAttention-R, un framework d'attention parcimonieuse conçu pour le décodage long des modèles d'inférence. Ce framework étend SeerAttention et conserve la conception de l'apprentissage de l'attention parcimonieuse grâce à un mécanisme de filtrage par auto-distillation, tout en supprimant le regroupement de requêtes pour s'adapter au décodage autorégressif. Grâce à son mécanisme de filtrage par insertion léger, SeerAttention-R est flexible et s'intègre facilement aux modèles pré-entraînés existants sans modifier les paramètres d'origine.
Lien vers l'article :https://go.hyper.ai/8XHpf
4.Restauration d'images textuelles avec modèles de diffusion
Dans cet article, nous proposons un framework de diffusion multitâche, TeReDiff, qui intègre les caractéristiques internes du modèle de diffusion dans un module de détection de texte, permettant aux deux composants de bénéficier d'un apprentissage conjoint. Cela lui permet d'extraire des représentations textuelles riches, utilisables comme indices lors de l'étape de débruitage ultérieure.
Lien vers l'article :https://go.hyper.ai/3YDSf
5.Apprentissage différenciable unifié de la réponse électrique
Cet article met en œuvre un cadre d'apprentissage automatique équivariant dans lequel les caractéristiques de réponse sont dérivées de la relation différentielle exacte entre la fonction de potentiel généralisée et le champ externe appliqué. La méthode se concentre sur la réponse au champ électrique, prédisant l'enthalpie électrique, la force, la polarisation, la charge de Born et la polarisabilité dans un modèle unifié appliquant un ensemble complet de contraintes physiques, de symétries et de lois de conservation précises.
Lien vers l'article :https://go.hyper.ai/AO8dM
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe de recherche conjointe de l'Université Harvard et de Bosch a proposé une solution innovante et développé un cadre d'apprentissage différentiable unifié pour la réponse électrique. Ce cadre permet d'apprendre simultanément l'énergie potentielle généralisée et sa fonction de réponse aux stimuli externes dans un modèle d'apprentissage automatique unique, surmontant ainsi les défauts inhérents aux modèles indépendants traditionnels et ouvrant une nouvelle voie à la recherche de haute précision sur les propriétés diélectriques et ferroélectriques des cristaux, des matériaux désordonnés et liquides.
Voir le rapport complet :https://go.hyper.ai/d3cAc
HyperAI organisera le 7e salon Meet AI Compiler Technology Salon à Zhongguancun, Pékin, le 5 juillet. Cet événement a invité quatre experts seniors d'AMD, Muxi Integrated Circuit, ByteDance et de l'Université de Pékin à explorer les pratiques de pointe des compilateurs d'IA sous de multiples perspectives, de la compilation de bas niveau aux applications de haut niveau.
Voir le rapport complet :https://go.hyper.ai/elNCA
L'Université de technologie du Shandong, en collaboration avec des équipes de recherche de l'Université forestière de Pékin, de l'Académie des sciences agricoles du Guangdong, de l'Université de São Paulo au Brésil, de l'Université des sciences médicales Rosalind Franklin au Royaume-Uni et de l'Université d'Umeå en Suède, ont construit conjointement le modèle PlantLncBoost, fournissant une solution systématique au problème de généralisation de l'identification des lncRNA des plantes.
Voir le rapport complet :https://go.hyper.ai/M88RZ
Le département des sciences et de l'ingénierie des matériaux du MIT, en collaboration avec une équipe multidépartementale, a développé une nouvelle approche basée sur les données basée sur un grand modèle de langage (LLM) et une architecture de réseau neuronal multi-têtes pour réaliser une prédiction et un criblage à grande échelle de la réactivité des matériaux de substitution du ciment.
Voir le rapport complet :https://go.hyper.ai/rtvf4
Afin de permettre à davantage d'utilisateurs de connaître les derniers développements dans le domaine de l'intelligence artificielle dans le milieu universitaire, le site Web officiel d'HyperAI (hyper.ai) a désormais lancé une section « Derniers articles », qui met à jour quotidiennement les articles de recherche de pointe en IA, couvrant plusieurs domaines verticaux tels que l'apprentissage automatique, le langage informatique, la vision par ordinateur et la reconnaissance de formes, ainsi que l'interaction homme-machine.
Voir le rapport complet : https://go.hyper.ai/ttAl7
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de juillet pour le sommet
2 juillet 7:59:59 VLDB 2026
11 juillet 7:59:59 POPL 2026
15 juillet 7:59:59 SODA 2026
18 juillet 7:59:59 SIGMOD 2026
19 juillet 7:59:59 ICSE 2026
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








