Command Palette
Search for a command to run...
Rapport Hebdomadaire Sur l'IA | Interprétation Des Technologies OCR De Pointe : DeepSeek, Tencent Et Baidu s'affrontent Sur Un Pied d'égalité, De La Reconnaissance De Caractères À l'analyse De Documents Structurés

Ces dernières années, la reconnaissance optique de caractères (OCR) a rapidement évolué, passant d'un simple outil de reconnaissance de caractères à…Un système général de compréhension de documents basé sur un modèle vision-langageTandis que des entreprises mondiales comme Microsoft et Google continuent d'investir, les principaux fournisseurs chinois tels que Baidu, Tencent et Alibaba Cloud déploient également des solutions intensives, ce qui pousse le marché à passer rapidement de la reconnaissance optique de caractères (OCR) basée sur des règles au traitement intelligent des documents (IDP) qui intègre l'intelligence artificielle et le traitement du langage naturel, et à approfondir continuellement son application dans des scénarios commerciaux réels tels que la finance, les affaires gouvernementales et la santé.
Sous l'impulsion d'une demande soutenue du secteur, l'orientation de la recherche en OCR a également considérablement évolué :Le modèle ne se contente plus de rechercher la « précision de la reconnaissance », mais s'attaque désormais systématiquement à des problèmes plus complexes tels que les mises en page complexes, les symboles multimodaux, la modélisation de contextes longs et la compréhension sémantique de bout en bout.Comment encoder efficacement des informations visuelles bidimensionnelles, analyser plus efficacement des informations textuelles et comment rapprocher l'ordre de lecture du modèle de la logique cognitive humaine sont des questions centrales qui préoccupent à la fois le monde universitaire et l'industrie.
Dans ce contexte d'interaction intense, le suivi et l'analyse continus des articles universitaires les plus récents sur la reconnaissance optique de caractères (OCR) sont particulièrement cruciaux pour saisir l'orientation de pointe de la technologie, comprendre les véritables défis de l'industrie et même trouver la prochaine étape des percées paradigmatiques.
Cette semaine, nous vous recommandons 5 articles populaires sur l'IA et la reconnaissance optique de caractères (OCR).Elle réunit des équipes de DeepSeek, Tencent, l'Université Tsinghua et d'autres institutions. Apprenons ensemble ! ⬇️
En outre, afin de permettre à un plus grand nombre d'utilisateurs de comprendre les derniers développements dans le domaine de l'intelligence artificielle dans le milieu universitaire, le site web HyperAI (hyper.ai) a lancé une section « Derniers articles », mise à jour quotidiennement avec des articles de recherche de pointe en IA.
Derniers articles sur l'IA:https://go.hyper.ai/hzChC
Recommandation de papier de cette semaine
- DeepSeek-OCR 2 : Flux causal visuel
S'appuyant sur DeepSeek-OCR, les chercheurs de DeepSeek-AI ont proposé DeepSeek-OCR 2. Si DeepSeek-OCR explorait la faisabilité de la compression de longs contextes par cartographie optique bidimensionnelle, DeepSeek-OCR 2 vise à explorer la faisabilité d'un nouvel encodeur, DeepEncoderV2, capable de réorganiser dynamiquement les jetons visuels en fonction de la sémantique de l'image. DeepEncoderV2 est conçu pour doter l'encodeur de capacités de raisonnement causal, lui permettant de réorganiser intelligemment les jetons visuels avant la compréhension du contenu basée sur la cartographie optique, remplaçant ainsi le traitement rigide par balayage raster. On obtient ainsi une compréhension d'image plus naturelle et sémantiquement cohérente, améliorant les capacités de reconnaissance optique de caractères (OCR) et d'analyse de documents.
Document et interprétation détaillée :https://go.hyper.ai/ChW45
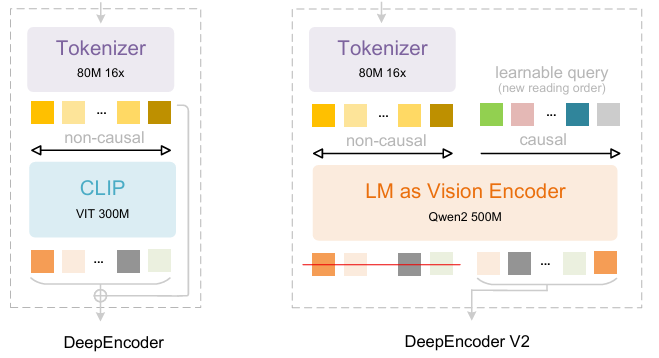
L'ensemble de données d'entraînement comprend des données OCR 1.0, OCR 2.0 et des données de vision générale, les données OCR représentant 80% des données d'entraînement mixtes. Pour l'évaluation, OmniDocBench v1.5 a été utilisé ; il s'agit d'un jeu de données de référence contenant 1 355 pages de documents en chinois et en anglais, incluant des revues, des articles universitaires et des rapports de recherche répartis en neuf catégories.
2. LightOnOCR : un modèle vision-langage multilingue de bout en bout pour la reconnaissance optique de caractères (OCR) de pointe.
Les chercheurs de LightOn ont publié LightOnOCR-2-1B, un modèle visuel-langage multilingue compact d'un milliard de paramètres qui extrait un texte clair et ordonné directement à partir d'images de documents, surpassant ainsi les modèles plus volumineux. Il améliore également la localisation d'images grâce à RLVR et renforce la robustesse par la fusion de points de contrôle. Le modèle et les benchmarks sont disponibles en open source.
Document et interprétation détaillée :https://go.hyper.ai/zXFQs
Lien vers le didacticiel de déploiement en un clic :https://go.hyper.ai/vXC4o
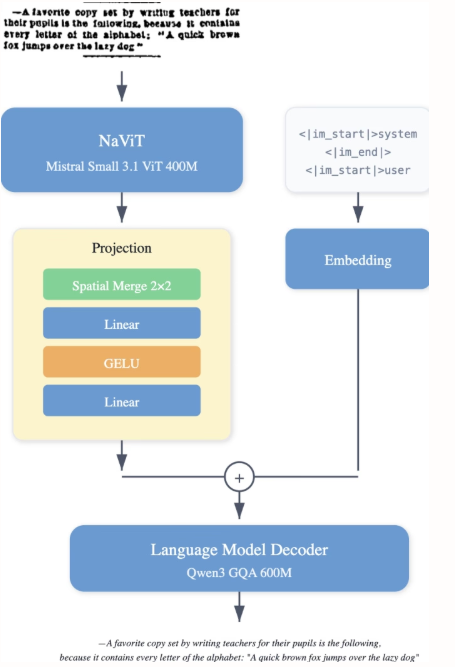
Le jeu de données LightOnOCR-2-1B combine des pages annotées par des enseignants provenant de sources multiples, notamment des documents numérisés pour une meilleure robustesse et des données supplémentaires pour une plus grande diversité de mise en page. Il comprend des zones extraites (paragraphes, titres, résumés) annotées avec GPT-4o, des exemples de pages blanches pour éviter les illusions d'optique, et une supervision TeX obtenue à partir d'arXiv via le pipeline nvpdftex. Des jeux de données OCR publics ont été ajoutés pour accroître la diversité.
3. Rapport technique HunyuanOCR
Cet article présente HunyuanOCR, un modèle vision-langage open source doté d'un milliard de paramètres, développé par Tencent et ses collaborateurs. Grâce à un apprentissage basé sur les données et à une stratégie d'apprentissage par renforcement novatrice, il adopte une architecture légère (adaptateur ViT-LLM MLP) pour unifier les fonctionnalités OCR de bout en bout, incluant la localisation de texte, l'analyse syntaxique de documents, l'extraction d'informations et la traduction. Ses performances surpassent celles des modèles plus volumineux et des API commerciales, permettant un déploiement efficace dans les applications industrielles et de recherche scientifique.
Document et interprétation détaillée :https://go.hyper.ai/F9fni
Lien vers le didacticiel de déploiement en un clic :https://go.hyper.ai/C4srs

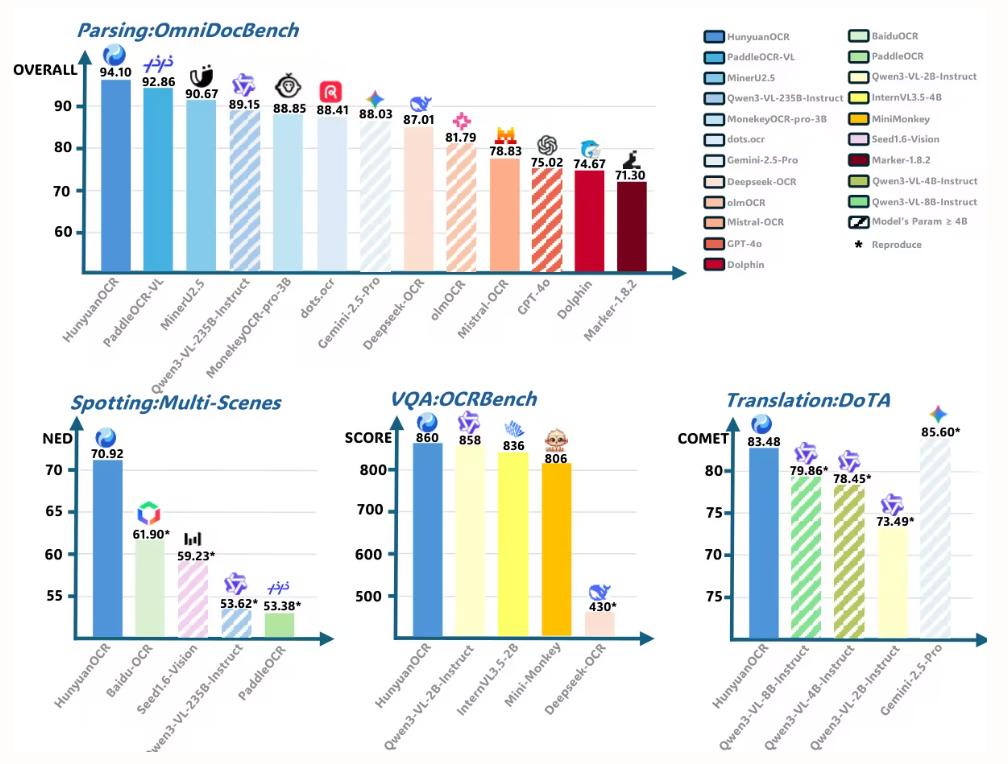
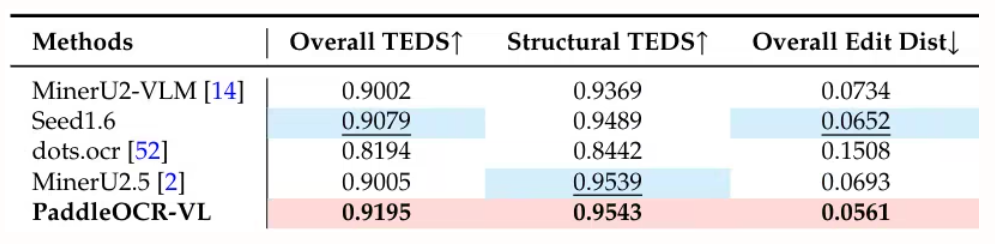
Cet article utilise HunyuanOCR pour évaluer les performances d'analyse syntaxique de documents sur OmniDocBench. Il obtient le score total le plus élevé, soit 94,10, surpassant tous les autres modèles (y compris les plus volumineux).
4 .PaddleOCR-VL : Amélioration de l’analyse syntaxique de documents multilingues grâce à un modèle vision-langage ultra-compact de 0,9 octet
L'équipe de Baidu a proposé PaddleOCR-VL, un modèle vision-langage économe en ressources qui intègre un encodeur à résolution dynamique de type NaViT au modèle ERNIE-4.5-0.3B. Ce modèle offre des performances de pointe en analyse syntaxique de documents multilingues, reconnaissant avec précision des éléments complexes tels que les tableaux et les formules. Tout en conservant une grande rapidité de raisonnement, il surpasse les solutions existantes et convient parfaitement aux applications concrètes.
Document et interprétation détaillée :https://go.hyper.ai/Rw3ur
Lien vers le didacticiel de déploiement en un clic :https://go.hyper.ai/5D8oo
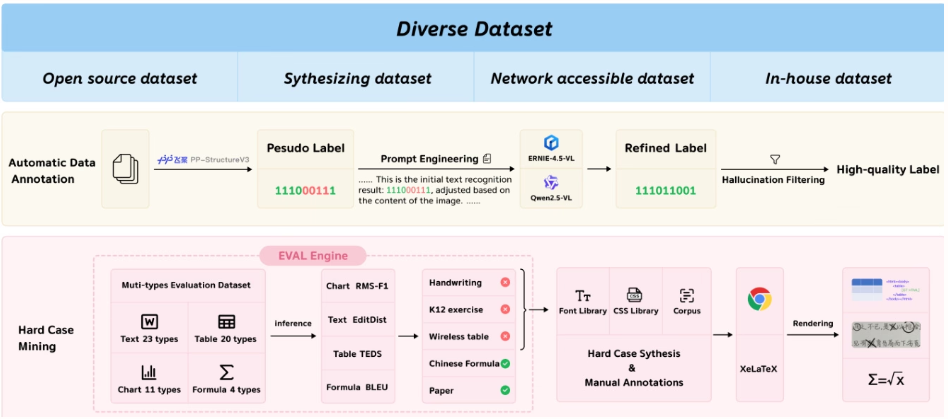
Cette étude a évalué l'analyse syntaxique de documents au niveau de la page sur OmniDocBench v1.5, olmOCR-Bench et OmniDocBench v1.0. Elle a obtenu un score global de pointe de 92,86 sur OmniDocBench v1.5, supérieur à celui de MinerU2.5-1.2B (90,67). Elle s'est également distinguée par ses performances en matière de texte (distance d'édition de 0,035), de formules (CDM : 91,22), de tableaux (TEDS : 90,89 et TEDS-S : 94,76) et d'ordre de lecture (0,043).
5. Théorie générale de la reconnaissance optique de caractères (OCR) : vers l’OCR-2.0 via un modèle de bout en bout unifié
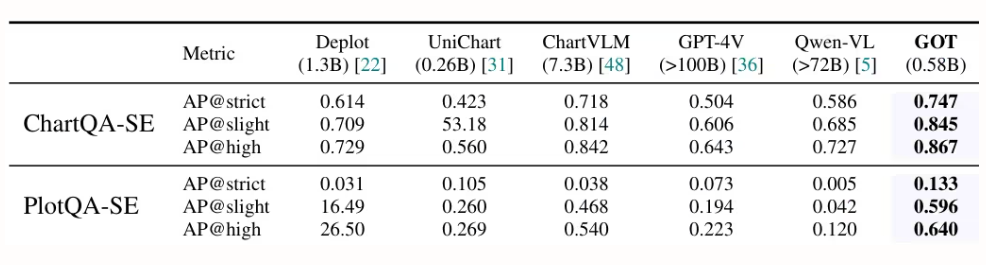
Des chercheurs de StepFun, Megvii Technology, de l'Université de l'Académie chinoise des sciences et de l'Université Tsinghua ont proposé GOT, un modèle OCR-2.0 unifié de bout en bout doté de 580 millions de paramètres. Grâce à un encodeur à haute compression et un décodeur à contexte étendu, il étend ses capacités de reconnaissance du texte à une variété de signaux optiques artificiels, tels que les formules mathématiques, les tableaux, les graphiques et les figures géométriques. Il prend en charge la saisie de pages entières ou partielles, la sortie formatée (Markdown/TikZ/SMILES), la reconnaissance interactive au niveau des régions, la résolution dynamique et le traitement multipage, contribuant ainsi de manière significative au développement de la compréhension intelligente des documents.
Document et interprétation détaillée :https://go.hyper.ai/9E6Ra
Lien vers le didacticiel de déploiement en un clic :https://go.hyper.ai/HInRr
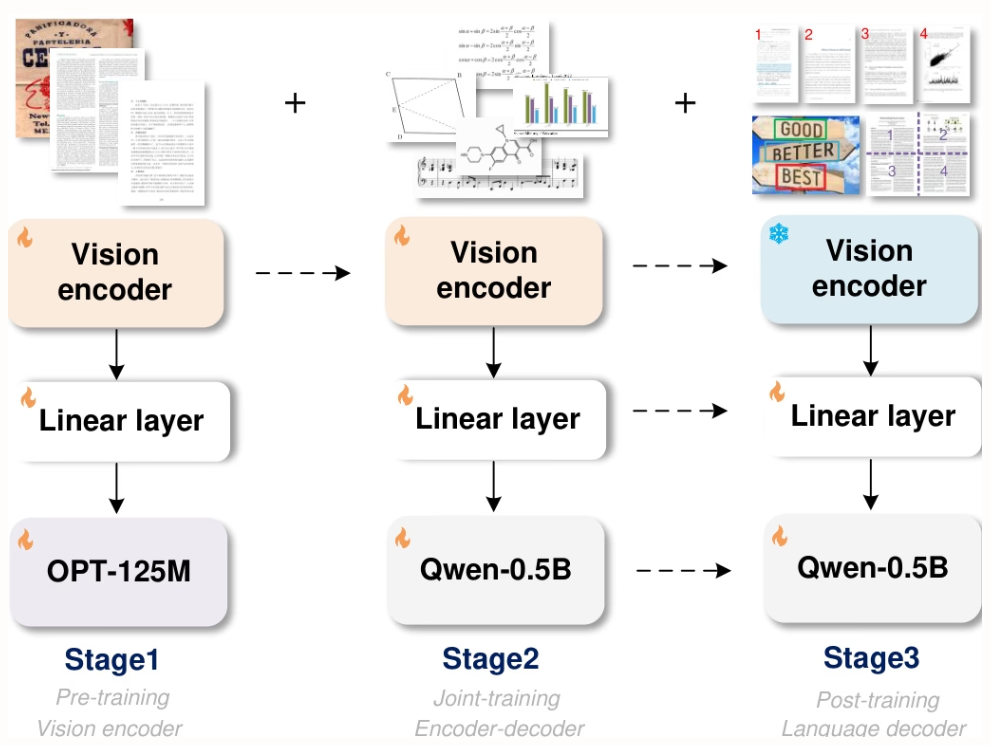
Les expériences décrites dans cet article ont été menées sur un GPU L40s 8×8 et trois phases d'entraînement ont été réalisées : pré-entraînement (3 itérations, taille de lot de 128, taux d'apprentissage de 1e-4), entraînement conjoint (1 itération, longueur maximale des jetons : 6 000) et post-entraînement (1 itération, longueur maximale des jetons : 8 192, taux d'apprentissage de 2e-5). La première phase a conservé 801 TP3T de données afin de maintenir les performances.
Voici l'intégralité du contenu de la recommandation d'article de cette semaine. Pour découvrir d'autres articles de recherche de pointe en IA, veuillez consulter la section « Derniers articles » du site officiel d'hyper.ai.
Nous invitons également les équipes de recherche à nous soumettre des résultats et des articles de haute qualité. Les personnes intéressées peuvent ajouter leur compte WeChat NeuroStar (identifiant WeChat : Hyperai01).
À la semaine prochaine !