Command Palette
Search for a command to run...
Orpheus TTS Dit Adieu À La Sensation Mécanique, La Conversation En Temps Réel Est Aussi Naturelle Que Les Amis ; OpenCodeReasoning Données Massives Open Source, Déverrouillant Un Nouveau Niveau De Raisonnement De Programmation

Les modèles de synthèse vocale ont fait des progrès significatifs ces dernières années, mais les modèles existants présentent encore de nombreuses limites dans leurs applications pratiques. La plupart des modèles ne peuvent générer un discours qu'avec un seul timbre et sont incapables de générer un discours riche en émotions. Pour relever ce défi, Canopy Labs a rendu open source le modèle de synthèse vocale Orpheus-TTS.
Orpheus-TTS peut générer un discours naturel, émotionnel et proche du niveau humain.Il dispose de capacités de clonage de voix sans échantillon et peut imiter des voix spécifiques sans formation préalable.Les utilisateurs peuvent utiliser des balises pour contrôler l’expression émotionnelle de la voix et améliorer le réalisme de la voix. Le modèle a une latence aussi faible qu'environ 200 millisecondes, aidant les utilisateurs à mettre en œuvre des applications en temps réel.
à l'heure actuelle,HyperAI est désormais en ligne「Orpheus TTS : un modèle de synthèse vocale multilingue",Venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/FGexv
Du 26 au 29 mai, le site officiel d'hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 12
* Sélection d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juin : 3
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence de raisonnement multimodal EMMA
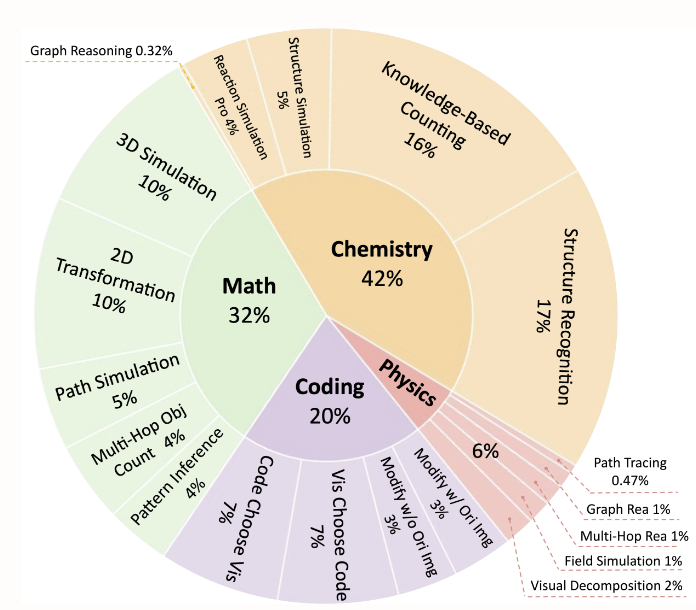
L'ensemble de données se concentre sur les tâches de raisonnement multimodal dans les domaines de la chimie organique (42%), des mathématiques (32%), de la physique (6%) et de la programmation (20%). Il contient 2 788 questions, dont 1 796 sont des échantillons nouvellement construits. Il prend en charge une division fine des tâches et vise à promouvoir la capacité de compréhension conjointe des images et des textes. Les types de tâches de données incluent la simulation de réactions chimiques, le raisonnement graphique mathématique, le traçage de chemins physiques, la visualisation de programmation, etc.
Utilisation directe :https://go.hyper.ai/HtL1N
2. Expressions faciales Ensemble de données de détection de format YOLO d'expressions faciales
Cet ensemble de données est un ensemble de données au format YOLO pour la reconnaissance des émotions, conçu pour la formation et l'évaluation des modèles de détection et de classification des cibles. L'ensemble de données contient environ 70 000 images au total, couvrant 9 catégories d'expressions faciales, prenant en compte les types d'émotions de base et complexes. Il convient aux scénarios d'application tels que la reconnaissance des émotions dans la vision par ordinateur, l'interaction homme-ordinateur, l'analyse de la santé mentale et la surveillance intelligente.
Utilisation directe :https://go.hyper.ai/K6iIH

3. Ensemble de données de raisonnement à grande échelle GeneralThought-430K
L'ensemble de données contient 430 000 échantillons, couvrant des problèmes dans les domaines des mathématiques, du code, de la physique, de la chimie, des sciences naturelles, des sciences humaines et sociales, de la technologie de l'ingénierie, etc., y compris des questions provenant de plusieurs modèles de raisonnement, des réponses de référence, des trajectoires de raisonnement, des réponses finales et d'autres métadonnées.
Utilisation directe :https://go.hyper.ai/xdSzd
4. S1k-1.1 Ensemble de données de raisonnement mathématique
Cet ensemble de données est un ensemble de données de raisonnement sur des problèmes mathématiques, contenant 1 000 échantillons. Il se concentre sur les problèmes mathématiques et les trajectoires de raisonnement, couvrant plusieurs domaines mathématiques tels que l'algèbre, la géométrie, les probabilités, etc. Chaque échantillon contient une description du problème, des étapes de résolution de problèmes, des réponses et des trajectoires de raisonnement générées par DeepSeek r1.
Utilisation directe :https://go.hyper.ai/MtvcV
5. Ensemble de données de l'Atlas des protéines humaines HPA
Cet ensemble de données est constitué de données provenant de la base de données Human Protein Atlas (HPA), qui contient un grand nombre d'images de microscopie confocale haute résolution, couvrant la distribution spatiale de milliers de protéines humaines dans différents organites. Il s’agit d’une ressource publique importante pour la recherche sur la localisation subcellulaire des protéines. Évaluation équitable des modèles.
Utilisation directe :https://go.hyper.ai/Dhuwt
6. Ensemble de données de réponses aux questions ZeroSearch
L'ensemble de données contient environ 170 000 échantillons, couvrant de multiples domaines tels que les connaissances scientifiques, les événements historiques, le divertissement cinématographique et télévisuel, la géographie et les sciences humaines. Il couvre également les questions factuelles, les questions de définition, les questions vrai ou faux, etc., et convient à la formation de modèles de questions-réponses de petite et moyenne taille. Grâce à des paires de questions-réponses soigneusement conçues, il vise à évaluer le raisonnement de bon sens, la mémoire factuelle et les capacités d'inférence logique du modèle, en fournissant des ressources de formation et de test standardisées pour le domaine du traitement du langage naturel.
Utilisation directe :https://go.hyper.ai/OkvBx
7. Ensemble de données de référence de raisonnement logique SocialMaze
Cet ensemble de données est un ensemble de données de référence de raisonnement social qui se concentre sur les tâches de raisonnement à rôle caché dans les scénarios d'interaction multi-agents. Il vise à évaluer les capacités de raisonnement logique, de détection de tromperie et de compréhension de dialogues multi-tours des grands modèles de langage (LLM) dans des environnements sociaux complexes, et fournit une plate-forme de test standardisée pour étudier les capacités de raisonnement social des LLM.
Utilisation directe :https://go.hyper.ai/Cch64
8. Ensemble de données de raisonnement de programmation OpenCodeReasoning
Cet ensemble de données vise à fournir des données de formation au raisonnement de programmation de haute qualité pour les grands modèles de langage (LLM) et à promouvoir l'amélioration des capacités de génération de code et de raisonnement logique. L'ensemble de données contient 735 255 échantillons, couvrant 28 319 problèmes de programmation uniques, et constitue l'un des plus grands ensembles de données de programmation de raisonnement actuellement disponibles.
Utilisation directe :https://go.hyper.ai/ofjBJ
9. Ensemble de données de recherche de documents multilingues MLDR
L'ensemble de données couvre 13 langues différentes. Il s'agit d'un ensemble de données de recherche de documents longs multilingues construit sur la base de Wikipédia, Wudao et du corpus multilingue mC4. Il vise à soutenir la recherche et le développement de tâches de recherche de textes longs inter-langues.
Utilisation directe :https://go.hyper.ai/Le0G8
10. Ensemble de données de référence sur les matériaux atomiques MP-20-PXRD
L'ensemble de données se compose de matériaux échantillonnés à partir de la base de données Materials Project, avec un maximum de 20 atomes dans la cellule unitaire. Il contient 45 229 matériaux, qui sont utilisés pour la formation, la validation et les tests dans un rapport de 90%, 7,5% et 2,5%.
Utilisation directe :https://go.hyper.ai/bUKbv
Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 4 catégories de tutoriels publics de haute qualité :
* Tutoriels de synthèse audio : 5
* Tutoriels de génération d'images : 3
* Tutoriels de synthèse vidéo : 2
* Tutoriels de raisonnement mathématique : 2
Tutoriel de synthèse audio
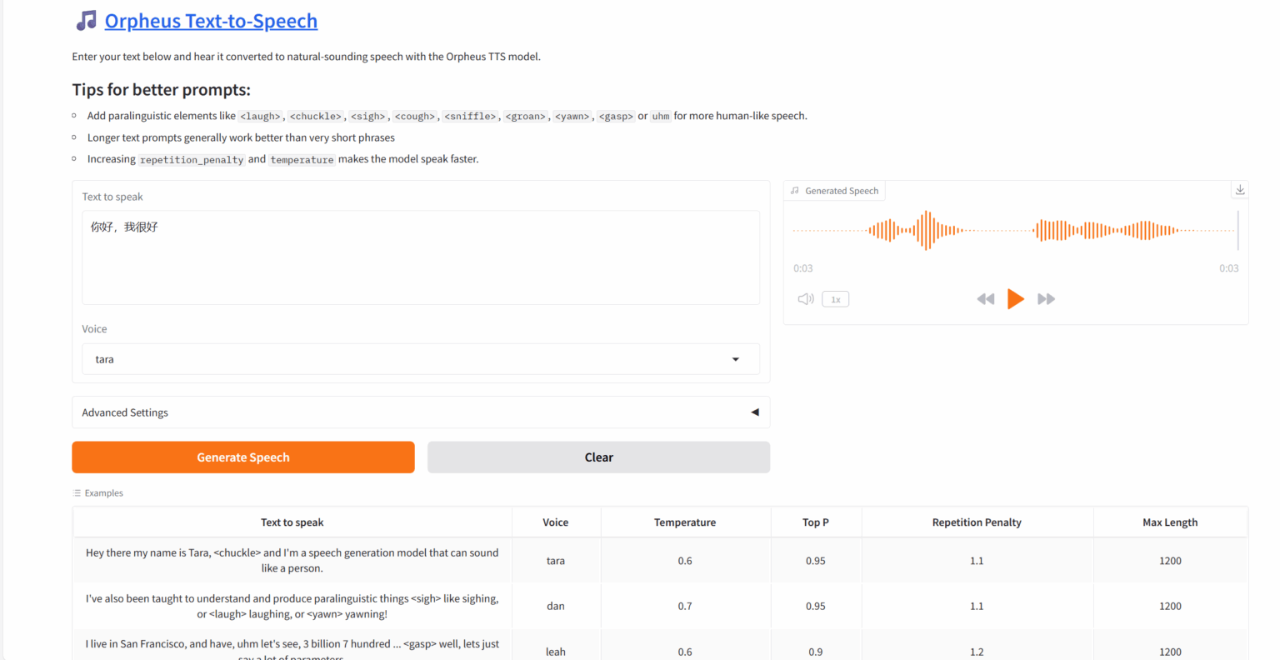
1. Orpheus TTS : un modèle de synthèse vocale multilingue
Orpheus-TTS peut générer une parole naturelle, émotionnelle et proche du niveau humain, et dispose de capacités de clonage de voix sans échantillon et peut imiter des voix spécifiques sans formation préalable. Les utilisateurs peuvent utiliser des balises pour contrôler l’expression émotionnelle de la voix et améliorer le réalisme de la voix. Orpheus TTS a une faible latence d'environ 200 millisecondes, ce qui le rend adapté aux applications en temps réel.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/FGexv
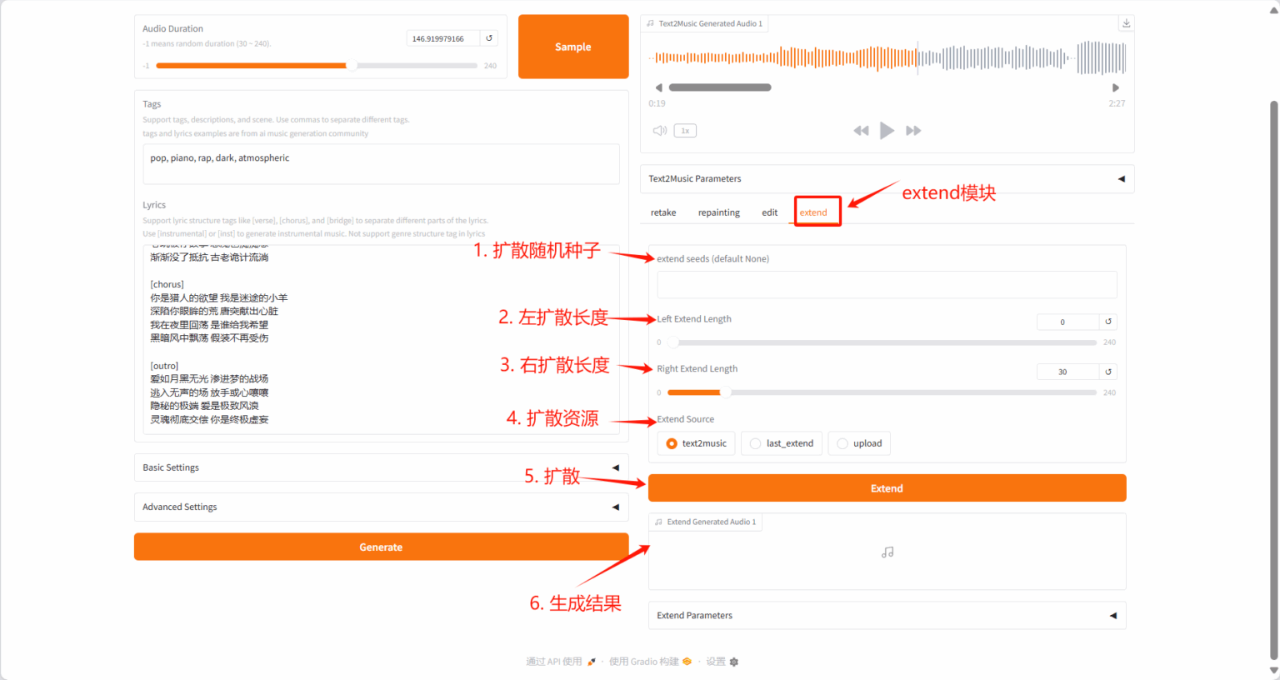
2. ACE-Step : Modèle de base pour la génération musicale
ACE-Step-v1-3.5B synthétise jusqu'à 4 minutes de musique en seulement 20 secondes sur un GPU A100, 15 fois plus rapidement qu'une base de référence basée sur LLM, tout en obtenant une cohérence musicale et un alignement lyrique supérieurs en termes de métriques mélodiques, harmoniques et rythmiques. De plus, le modèle préserve les détails acoustiques fins, permettant des mécanismes de contrôle avancés tels que le clonage de voix, l'édition de paroles, le remixage et la génération de pistes.
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/Qjxmu
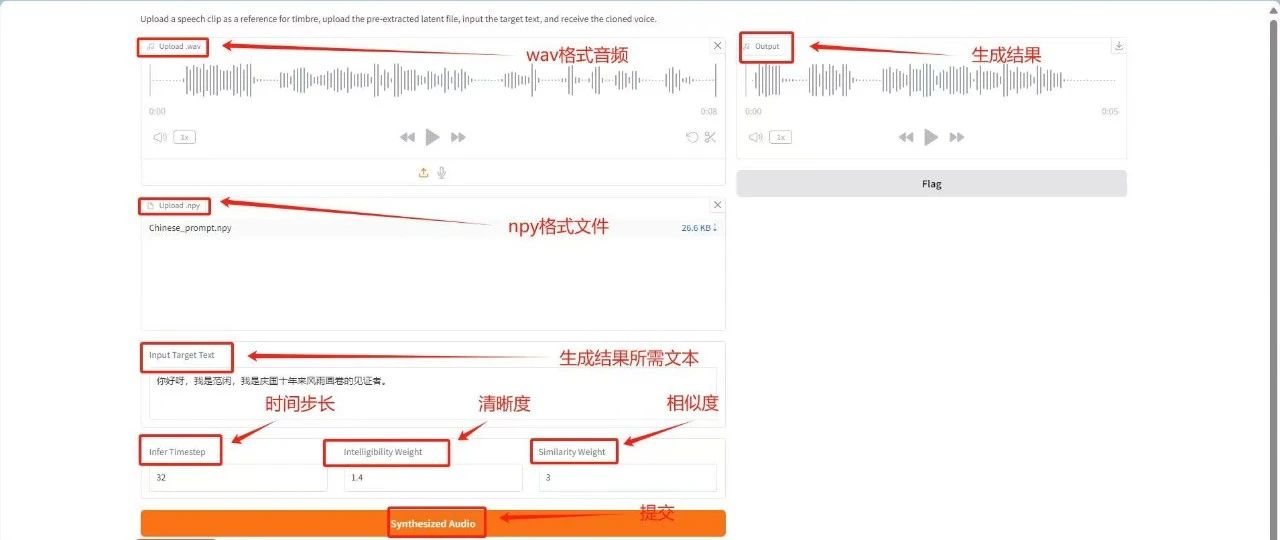
3. Déploiement en un clic de MegaTTS3
MegaTTS 3 est un système TTS doté d'un algorithme innovant de transducteur diffus latent guidé (DiT) à alignement clairsemé qui permet d'obtenir une qualité de parole TTS zéro coup de pointe et prend en charge un contrôle très flexible de la force de l'accent. Il est principalement utilisé pour convertir le texte d'entrée en une sortie vocale de haute qualité, naturelle et fluide.
Ce tutoriel utilise une seule carte RTX 4090. Vous pouvez le déployer en un clic en utilisant le lien ci-dessous.
Exécutez en ligne :https://go.hyper.ai/rujKs
4. Reconnaissance vocale Parakeet-tdt-0.6b-v2
Parakeet-tdt-0.6b-v2 est basé sur l'architecture d'encodeur FastConformer et le décodeur TDT, et peut transcrire efficacement jusqu'à 24 minutes de clips audio en anglais à la fois. Ce modèle se concentre sur les tâches de transcription vocale en anglais de haute précision et à faible latence et convient aux scénarios de conversion de la parole en texte en anglais en temps réel (tels que les conversations de service client, les comptes rendus de réunion, les assistants vocaux, etc.).
Ce didacticiel utilise une seule ressource de calcul RTX 4090 et le modèle prend uniquement en charge la reconnaissance vocale en anglais.
Exécutez en ligne :https://go.hyper.ai/pWmfu
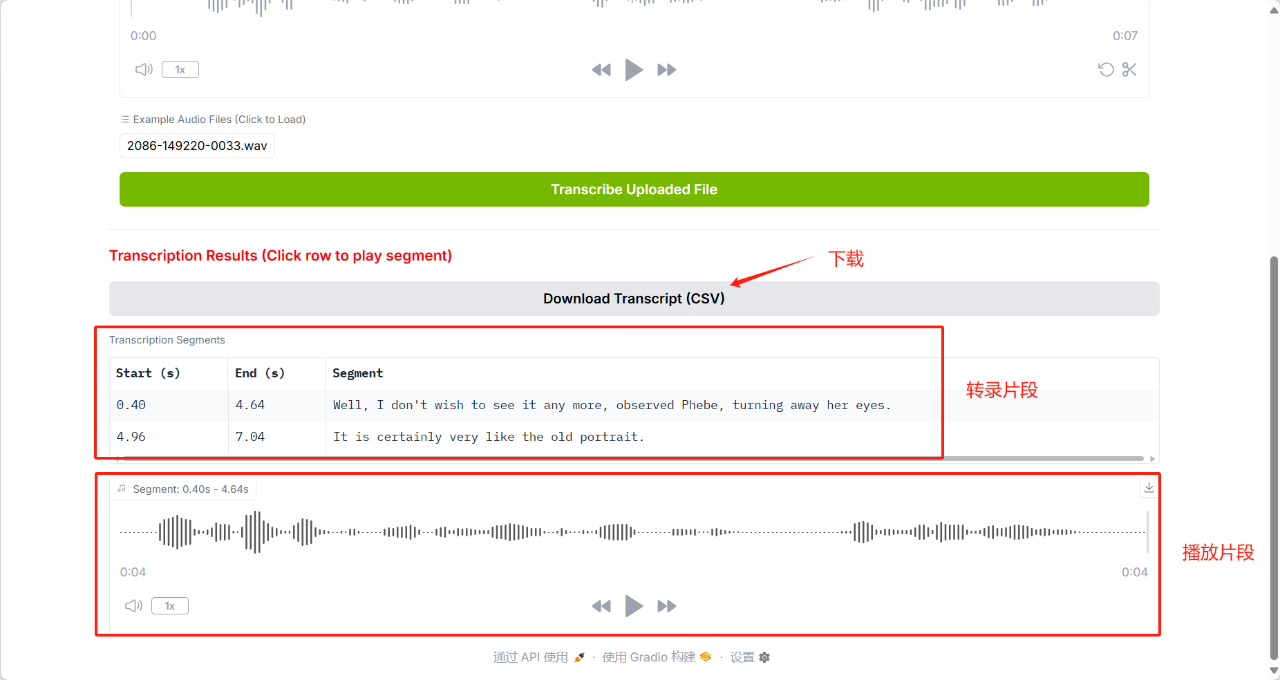
5. Dia-1.6B : Démonstration de synthèse vocale émotionnelle
Dia-1.6B est capable de générer des conversations très réalistes directement à partir de scripts texte et prend en charge le contrôle des émotions et du ton basé sur l'audio. Il peut également générer des sons de communication non verbale tels que des rires, de la toux, des éclaircissements de gorge, etc., rendant la conversation plus naturelle et plus vivante. Ce projet prend également en charge le téléchargement de vos propres échantillons audio. Le modèle générera des voix similaires en fonction des échantillons pour obtenir un clonage d'empreinte vocale à échantillon zéro.
Ce tutoriel utilise des ressources pour une seule carte RTX 4090 et ne prend actuellement en charge que la génération en anglais.
Exécutez en ligne :https://go.hyper.ai/5J3lp
Tutoriel de génération d'images
1. Édition d'image de cohérence d'arrière-plan KV-Edit
KV-Edit est une méthode d'édition d'images sans formation qui maintient strictement la cohérence d'arrière-plan entre les images originales et éditées, et atteint des performances impressionnantes sur diverses tâches d'édition, notamment l'ajout, la suppression et le remplacement d'objets.
Ce tutoriel utilise une seule carte RTX A6000. Cliquez sur le lien ci-dessous pour cloner rapidement le modèle.
Exécutez en ligne :https://go.hyper.ai/wo2xJ

2. Synthèse d'images haute résolution Sana
Sana est un framework texte-image capable de générer efficacement des images jusqu'à une résolution de 4096 × 4096. Sana peut synthétiser des images haute résolution et de haute qualité à une vitesse très rapide, avec de fortes capacités d'alignement texte-image.
Ce tutoriel utilise le modèle Sana-1600M-1024px pour la démonstration, et la ressource de puissance de calcul utilise une seule carte RTX 4090.
Exécutez en ligne :https://go.hyper.ai/tiP36

3. Édition contextuelle : génération et édition d'images pilotées par commandes
In-Context Edit est un framework efficace pour l'édition d'images basée sur des commandes. Comparé aux méthodes précédentes, ICEdit ne dispose que de 1% de paramètres entraînables (200M) et de 0,1% de données d'entraînement (50k), montrant une forte capacité de généralisation et peut gérer diverses tâches d'édition. Comparé aux modèles commerciaux tels que Gemini et GPT4o, il est plus open source, moins coûteux, plus rapide et offre de meilleures performances.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource. Si vous souhaitez atteindre les 9 secondes officielles mentionnées pour générer des images, vous aurez besoin d'une carte graphique avec une configuration plus élevée. Actuellement, seules les descriptions de texte en anglais sont prises en charge.
Exécutez en ligne :https://go.hyper.ai/Ytv6C

Tutoriel de génération de vidéos
1. TransPixeler : Génération de vidéo RGBA à partir de texte
TransPixeler conserve les avantages du modèle RVB d'origine et réalise un alignement fort entre les canaux RVB et alpha avec des données de formation limitées, ce qui peut générer efficacement des vidéos RGBA diverses et cohérentes, favorisant ainsi la possibilité d'effets visuels et de création de contenu interactif.
Ce didacticiel utilise une seule carte RTX A6000 comme ressource et la description textuelle ne prend actuellement en charge que l'anglais.
Exécutez en ligne :https://go.hyper.ai/1OFP9

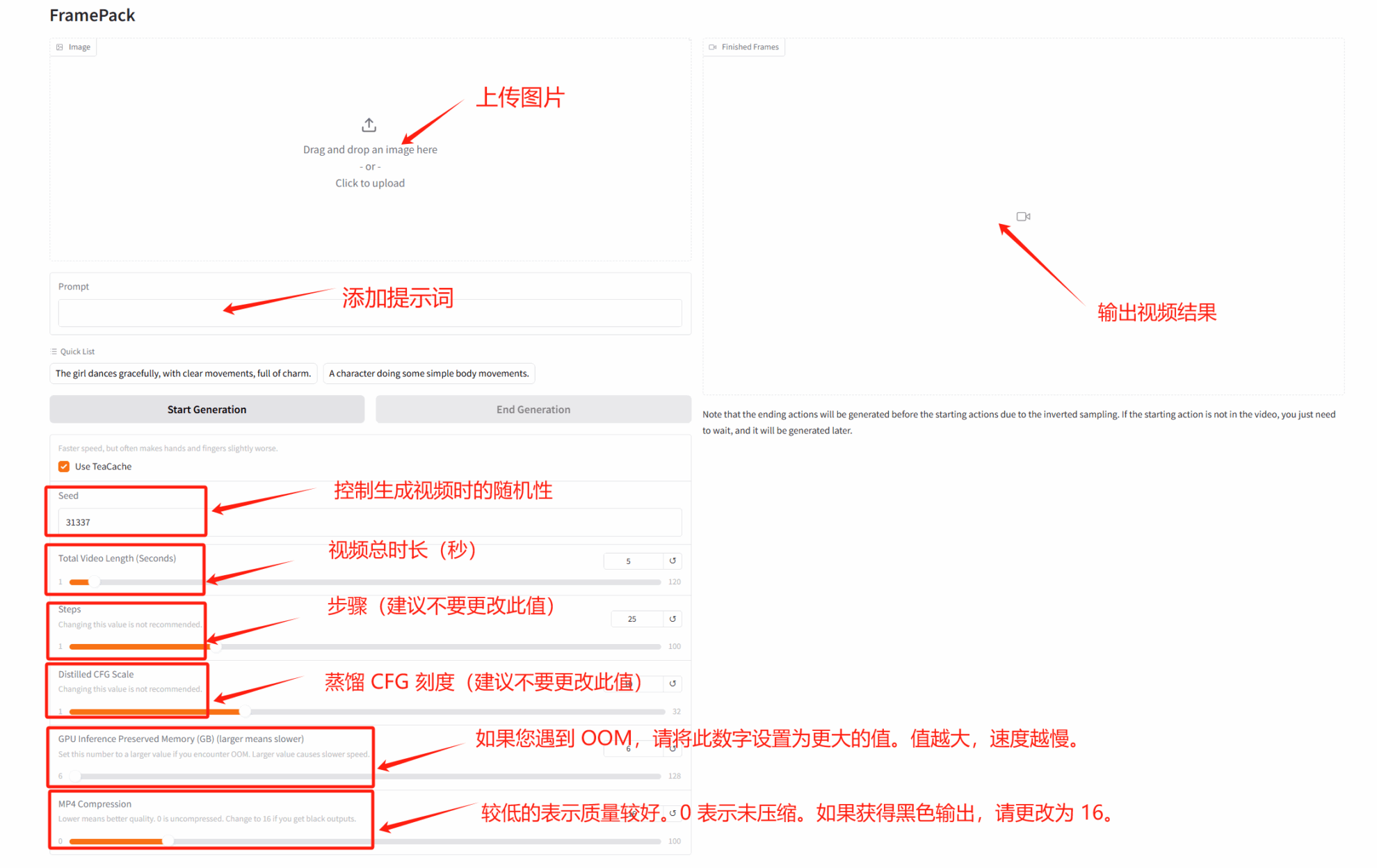
2. Démonstration de génération vidéo à faible mémoire vidéo FramePack
FramePack utilise une architecture de réseau neuronal innovante pour résoudre efficacement les problèmes tels que l'utilisation élevée de la mémoire vidéo, la dérive et l'oubli dans la génération vidéo traditionnelle, et réduit considérablement les exigences matérielles.
Ce tutoriel utilise RTX 4090 comme ressource de calcul. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/rYELB
Tutoriel de raisonnement mathématique
1. Déployer OpenMath-Nemotron-1.5B avec vLLM+Open WebUI
Le modèle a été créé en affinant Qwen/Qwen2.5-Math-1.5B sur l'ensemble de données OpenMathReasoning. Le modèle atteint des résultats de pointe sur des critères mathématiques populaires et est désormais autorisé à être utilisé à des fins commerciales.
Les ressources informatiques de ce tutoriel utilisent une seule carte RTX 4090, ne prennent en charge que le calcul de problèmes mathématiques et les réponses sont en anglais.
Exécutez en ligne :https://go.hyper.ai/rasEm
2. Déployer DeepSeek-Prover-V2-7B à l'aide de vLLM+Open WebUI
La caractéristique la plus importante de DeepSeek-Prover-V2-7B est sa capacité à combiner de manière transparente le raisonnement mathématique informel (c'est-à-dire la méthode de raisonnement couramment utilisée par les humains) avec des preuves formelles rigoureuses, permettant au modèle de penser de manière aussi flexible que les humains et de démontrer aussi rigoureusement que les ordinateurs, réalisant ainsi une fusion intégrée du raisonnement mathématique.
Ce tutoriel utilise une seule carte RTX A6000 comme ressource. Ce modèle ne prend en charge que les problèmes de raisonnement mathématique.
Exécutez en ligne :https://go.hyper.ai/JYCI2
Articles de la communauté
1. Publié dans la sous-revue de Nature ! L'Université des sciences et technologies de Huazhong a proposé un modèle d'IA de stratégie de fusion pour obtenir une prédiction précise du risque de mortalité par choc septique dans plusieurs centres et dans toutes les spécialités
Une équipe de recherche de l'hôpital Tongji et de l'école de gestion médicale et de santé affiliée au Tongji Medical College de l'université des sciences et technologies de Huazhong a proposé de manière innovante un modèle de fusion de classification basé sur TOPSIS (TCF) pour prédire le risque de décès dans les 28 jours chez les patients souffrant de choc septique en unité de soins intensifs. Le modèle intègre 7 modèles d’apprentissage automatique et présente une stabilité et une précision élevées dans la validation interprofessionnelle et multicentrique.
Voir le rapport complet :https://go.hyper.ai/K42Fp
2. L'Université d'Oxford et d'autres ont fouillé en profondeur les données de santé de 7,46 millions d'adultes pour développer des algorithmes de dépistage précoce et ont réussi à prédire précocement 15 types de cancer sur la base d'indicateurs sanguins.
Les équipes de recherche de l'Université Queen Mary de Londres et de l'Université d'Oxford ont collaboré pour développer deux nouveaux algorithmes de prédiction du cancer basés sur les dossiers médicaux électroniques anonymes de 7,46 millions d'adultes en Angleterre : l'algorithme de base intègre les facteurs cliniques traditionnels et les variables de symptômes, et l'algorithme avancé intègre en outre des indicateurs sanguins tels que la numération globulaire complète et les tests de la fonction hépatique. Cet article est une interprétation détaillée et un partage du document de recherche.
Voir le rapport complet :https://go.hyper.ai/12a8Z
3. Sélectionné pour l'ICML 2025, l'Université Tsinghua/Renmin/Byte a proposé le premier cadre de génération unifiée intermolécule UniMoMo pour réaliser la conception de molécules médicamenteuses multitypes
L'équipe du professeur Liu Yang de l'Université Tsinghua, en collaboration avec les équipes de l'Université Renmin et de ByteDance, a proposé conjointement un cadre de génération unifié pour toutes les espèces moléculaires, UniMoMo. Ce cadre représente uniformément différents types de molécules en fonction de fragments moléculaires, permettant la conception de différents types de molécules de liaison pour la même cible. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/e96ci
Articles populaires de l'encyclopédie
1. Unité récurrente fermée
2. Fusion de tri inverse
3. Diffusion gaussienne tridimensionnelle
4. Raisonnement basé sur des cas
5. Mémoire à long terme bidirectionnelle
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :https://go.hyper.ai/wiki
Date limite de juin pour le sommet
VLDB 2026 2 juin 7:59:59
S&P 2026 6 juin 7:59:59
ICDE 2026 19 juin 7:59:59
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








