Command Palette
Search for a command to run...
Surmontez Les Difficultés De La Reconnaissance De l'écriture Manuscrite Par OCR ! Lancement Du Didacticiel InkSight, Permettant Une Transcription De Haute Précision ; L'ensemble De Données iNatSounds Est Publié, Contenant 230 000 Enregistrements Audio d'espèces Naturelles

Les notes manuscrites sont le moyen par lequel de nombreuses personnes enregistrent leurs inspirations dans leur vie quotidienne, mais la manière de convertir efficacement le contenu manuscrit en texte électronique a toujours été un défi majeur. La technologie OCR (reconnaissance optique de caractères) traditionnelle a souvent une précision limitée lorsqu'il s'agit de traiter des arrière-plans complexes ou une écriture manuscrite irrégulière.
Pour résoudre ce problème, Google Research a récemment lancé la technologie InkSight, qui simule le processus de lecture humaine grâce à l'apprentissage en profondeur, reconnaît avec précision le texte manuscrit et restitue parfaitement son style. Contrairement à l'OCR traditionnel, InkSight peut toujours maintenir une grande précision dans des conditions de faible luminosité ou d'arrière-plans complexes, prenant en charge la transcription au niveau du mot et de la page entière, et l'effet est presque le même que l'écriture manuscrite d'origine. Cette technologie a montré un grand potentiel dans des domaines tels que la numérisation de documents et la protection du patrimoine culturel.
Afin d'aider de nombreux passionnés d'écriture manuscrite à numériser facilement leur inspiration et faciliter la transcription de haute précision de documents précieux,Le tutoriel InkSight est désormais disponible sur le site officiel hyper.ai. Vous pouvez en faire l'expérience en le clonant en un clic~
Exécutez en ligne :https://go.hyper.ai/gVh8a

Du 11 au 15 novembre, le site officiel de hyper.ai a été mis à jour rapidement :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 6
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en novembre : 2
Visitez le site officiel : hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de conduite autonome DrivingDojo
L'ensemble de données de conduite autonome DrivingDojo contient environ 18 000 clips vidéo, spécialement conçus pour simuler des interactions visuelles dans le monde réel et couvre des actions de conduite riches, des interactions multi-agents et des connaissances de conduite en monde ouvert. Cet ensemble de données vise à faire progresser le développement de modèles interactifs et informatifs du monde de la conduite.
Utilisation directe :https://go.hyper.ai/Y86yY

2. Ensemble de données d'images routières des autoroutes américaines TuSimple
L'ensemble de données TuSimple contient 6 408 images d'autoroutes américaines, dont 3 626 pour la formation, 358 pour la validation et 2 782 pour les tests. La résolution de l'image est de 1280×720 et toutes les images sont prises dans des conditions météorologiques différentes.
Utilisation directe :https://go.hyper.ai/Mo6bt

3. Ensemble de données d'images de 100 sports de classification sportive
Cet ensemble de données couvre un ensemble d'images animées de 100 sports différents, et toutes les images sont au format jpg 224x224x3. Les données sont divisées en images d’entraînement, images de test et images de validation. De plus, l'ensemble de données est livré avec un fichier CSV pour faciliter le chargement et le traitement de ces données d'image par les chercheurs.
Utilisation directe :https://go.hyper.ai/715At

4. Ensemble de données sur les espèces de plantes d'intérieur : 47 espèces de plantes d'intérieur
L'ensemble de données a été collecté à partir de Bing Images et contient 14 790 images classées en 47 catégories d'espèces végétales différentes.
Utilisation directe :https://go.hyper.ai/v7wTX

5.Ensemble de données multimodales sur la biodiversité des insectes BIOSCAN-5M
BIOSCAN-5M est un ensemble de données complet et multimodal sur la biodiversité des insectes conçu pour comprendre et surveiller la biodiversité mondiale des insectes. L'ensemble de données contient des informations détaillées sur plus de 5 millions de spécimens d'insectes, élargissant considérablement les ensembles de données biologiques basés sur des images existants.
Utilisation directe :https://go.hyper.ai/YDeuN

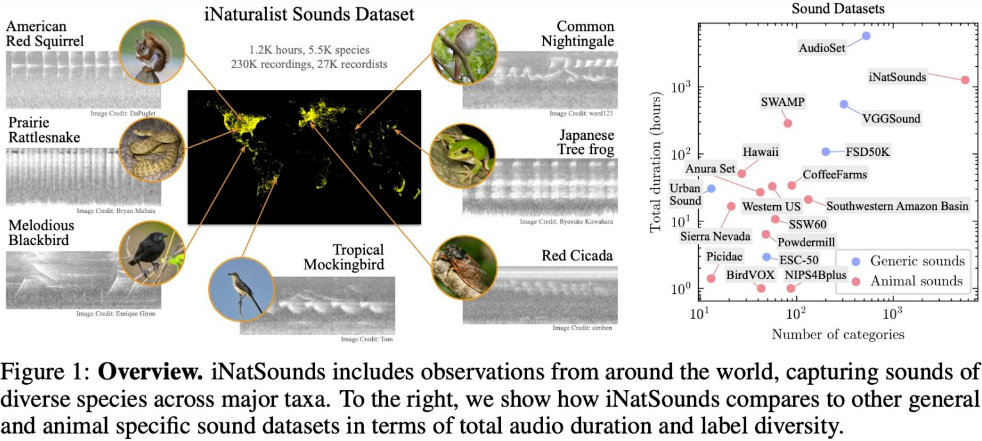
6. Ensemble de données sonores iNaturalist Ensemble de données sonores sur les espèces naturelles
L'ensemble de données est une collection de fichiers audio d'espèces naturelles, qui collecte 230 000 fichiers audio, capturant des sons de plus de 5 500 espèces, fournis par plus de 27 000 enregistreurs dans le monde entier.
Utilisation directe :https://go.hyper.ai/S0lg6
7. Ensemble de données satellite haute résolution OpenSatMap
OpenSatMap est un ensemble de données satellite haute résolution conçu pour la création de cartes à grande échelle. Il comprend des images non seulement de nombreuses villes de Chine, mais également de plus de 50 villes et de 18 pays à travers le monde. Ces images ont une résolution de 20 niveaux, la plus élevée parmi les ensembles de données satellitaires existants.
Utilisation directe :https://go.hyper.ai/PtbCB
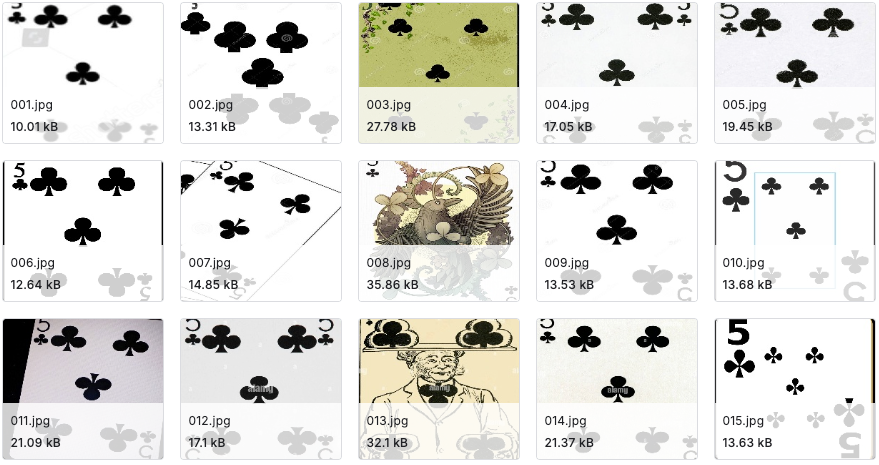
8. Ensemble de données d'images de cartes
Cards Image est un ensemble de données d'images de cartes à jouer. L'ensemble de données contient 7 624 images d'entraînement, 265 images de test et 265 images de validation. Toutes les images sont au format jpg 224x224x3. Chaque image a été soigneusement recadrée pour ne montrer qu'une seule carte à jouer, occupant plus de 50% pixels de l'image.
Utilisation directe :https://go.hyper.ai/DuOJb
9. Ensemble de données de paires image-texte à grande échelle PD12M
PD12M est le plus grand ensemble de données de paires image-texte du domaine public, contenant 12,4 millions d'images de haute qualité sous licence du domaine public et CCO avec des légendes synthétiques, principalement utilisées pour la formation de modèles texte-image.
Utilisation directe :https://go.hyper.ai/xyjrD

10. Ensemble de données multimodales texte-image MINT-1T
L'ensemble de données MINT-1T est un ensemble de données multimodal contenant mille milliards de balises de texte et 3,4 milliards d'images, soit 10 fois la taille du plus grand ensemble de données open source précédent. L'ensemble de données comprend non seulement des documents HTML, mais également des documents PDF et des articles ArXiv, améliorant considérablement la couverture des documents scientifiques.
Utilisation directe :https://go.hyper.ai/Vf3mq
Tutoriels publics sélectionnés
1. Démo InkSight pour numériser du texte manuscrit
InkSight est une technologie de reconnaissance et de numérisation de textes manuscrits. La technologie imite le processus de lecture et d’apprentissage humain en réécrivant et en apprenant continuellement à partir d’un texte manuscrit, accumulant ainsi une compréhension de l’apparence et du sens du texte. Par rapport à la technologie traditionnelle de reconnaissance optique de caractères (OCR), InkSight démontre une précision de reconnaissance supérieure lors du traitement de texte manuscrit dans des arrière-plans complexes, du texte flou ou des conditions de faible luminosité.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés. Vous pouvez expérimenter la conversion de l'écriture manuscrite avec un démarrage en un clic.
Exécutez en ligne :https://go.hyper.ai/gVh8a

2. CharacterGen génère des personnages 3D de haute qualité à partir d'une seule image
CharacterGen prend une seule image d'entrée et génère un maillage de personnage unifié posé en 3D avec une qualité élevée et une apparence cohérente, prêt à être utilisé dans les flux de travail de gréement et d'animation en aval.
Ce tutoriel est une démonstration d'exécution en un clic de CharacterGen. L'environnement et les dépendances pertinents ont été installés. Vous pouvez cloner et commencer à expérimenter la génération de personnages 3D de haute qualité.
Exécutez en ligne :https://go.hyper.ai/jtVAF

3. Déploiement en un clic de Ministral-8B-Instruct-2410
Ministral-8B est un modèle de langage développé par l'équipe Mistral AI spécifiquement pour les appareils de pointe et les scénarios d'informatique de pointe. Il peut effectuer plusieurs tâches, notamment répondre à des questions, traduire des textes dans différentes langues, créer des résumés de documents et aider à rédiger des articles et des rapports. Il adopte un mode d'attention de fenêtre coulissante entrelacée, qui non seulement améliore la vitesse d'inférence du modèle, mais réduit également considérablement l'utilisation de la mémoire, ce qui le rend très adapté à l'exécution sur des périphériques de périphérie à ressources limitées.
Accédez au site Web officiel pour cloner et démarrer le conteneur, copiez directement l'adresse API et vous pourrez communiquer avec le modèle.
Exécutez en ligne :https://go.hyper.ai/wMQWN
4. Tutoriel VASP : 1-1. Calcul DFT des atomes d'oxygène isolés
VASP est un progiciel permettant d'effectuer des calculs de structure électronique et des simulations de mécanique quantique-dynamique moléculaire. Il s’agit de l’un des logiciels commerciaux les plus populaires pour la simulation des matériaux et la recherche en science des matériaux computationnelle. Sa grande précision et ses fonctions puissantes en font un outil important pour les chercheurs pour prédire et concevoir les propriétés des matériaux. Il est largement utilisé en physique des solides, en science des matériaux, en chimie, en dynamique moléculaire et dans d’autres domaines.
Ce tutoriel est la première partie du tutoriel officiel VASP : calculs DFT d'atomes d'oxygène isolés. Cliquez sur le lien ci-dessous et suivez le didacticiel pour démarrer des calculs DFT hautes performances à partir de zéro.
Exécutez en ligne :https://go.hyper.ai/pa2NX
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Étant donné que le développement de médicaments ne dispose pas d’un paradigme standard unifié, le processus de développement est complexe et nécessite un étiquetage précis des données, ce qui limite l’application de grands modèles linguistiques dans le domaine du développement de médicaments. En réponse à cela, des équipes de recherche de quatre grandes universités ont proposé conjointement un grand modèle de langage Y-Mol guidé par des connaissances biomédicales multi-échelles. Il peut être affiné sur différents corpus de textes et instructions, améliorant ainsi les performances et le potentiel du modèle dans le développement de médicaments. Cet article est une interprétation détaillée et un partage du document de recherche.
Voir le rapport complet :https://go.hyper.ai/14X5I
En tant que maître de classe mondiale dans le domaine de la conception de protéines, David Baker a ouvert le code source de nombreux outils d'apprentissage en profondeur. Il est également le « roi académique », ayant publié plus de 700 articles de recherche dans le domaine des protéines, avec un total de 177 000 citations. David Baker a été directement impliqué en tant que fondateur dans le développement de 21 entreprises dans des domaines tels que le traitement des maladies, la production alimentaire et la science des matériaux. Cliquez pour lire et en savoir plus sur l'expérience légendaire de David Baker.
Voir le rapport complet :https://go.hyper.ai/ItxvG
Lors du forum COSCon'24 AI for Science coproduit par HyperAI, Jingtao Ding, chercheur postdoctoral du Centre de science urbaine et de recherche informatique, Département de génie électronique, Université Tsinghua, a prononcé un discours intitulé « Modélisation et découverte de modèles de systèmes urbains complexes pilotés par l'IA ». Il a donné une explication approfondie de la méthode de modélisation générative spatio-temporelle des systèmes urbains complexes et des derniers progrès de recherche de l'équipe. Plein d'informations utiles, cliquez pour lire.
Voir le rapport complet :https://go.hyper.ai/qaDYE
Le 13 novembre, Huang Renxun et Son Masayoshi ont eu une conversation hors ligne au Japon, passant en revue l'investissement passé de ce dernier dans Nvidia et discutant du développement de l'IA au Japon. Huang Renxun a déclaré sans détour que Masayoshi Son est « le seul entrepreneur et innovateur au monde qui a choisi des gagnants et travaillé avec des gagnants à chaque génération de changement technologique ». Cet article fait le point sur les conflits passés entre les deux et sur l’orientation actuelle du développement. Cliquez pour lire les détails.
Voir le rapport complet :https://go.hyper.ai/hLKbG
Articles populaires de l'encyclopédie
1. Cadre d'alignement de l'UNA
2. Cousin numérique
3. Effondrement du modèle
4. Augmentation du gradient
5. Principe de fréquence
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
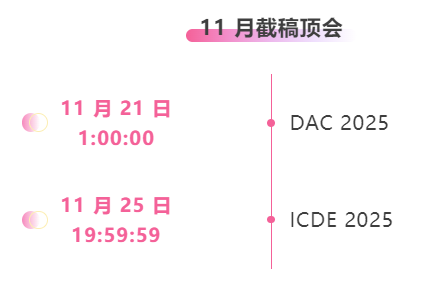
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :
Enfin, je recommande un « Programme d’incitation aux créateurs ». Les amis intéressés peuvent scanner le code QR pour participer !









