Command Palette
Search for a command to run...
Détection d'objets En Temps Réel À La Pointe De La Technologie ! YOLOv13 Étend Les Capacités De Perception Globale ; Sélectionné Pour NeurIPS 2025, UltraHR-100K Permet d'obtenir Des Images Texturées À ultra-haute résolution.

La détection d'objets en temps réel est depuis longtemps un domaine de recherche de pointe en vision par ordinateur. De la détection industrielle à la conduite autonome, la quête de rapidité et de précision par les communautés scientifiques et industrielles est restée constante. Dans ce domaine, la série de modèles YOLO s'est imposée grâce à son excellent compromis entre vitesse d'inférence et précision.
Cependant,Des premières versions de YOLO à la récente YOLOv11, et même à YOLOv12 qui utilise un mécanisme d'auto-attention régionale, toutes présentent des limitations dans la gestion de scénarios complexes :Les opérations de convolution ne peuvent agréger les informations qu'au sein d'un champ réceptif local fixe, et leur capacité de modélisation est limitée par la taille du noyau de convolution et la profondeur du réseau. Bien que le mécanisme d'auto-attention élargisse le champ réceptif, il doit néanmoins composer avec le coût de calcul élevé de la modélisation et de la perception globales. Plus important encore, l'auto-attention ne peut modéliser que les corrélations binaires entre pixels.
Pour relever ces défis, la série YOLO a été mise à jour vers sa dernière version, YOLOv13.La nouvelle version introduit HyperACE (Hypergraph-based adaptive relevance enhancement), un mécanisme d'amélioration de la pertinence adaptative basé sur les hypergraphes, qui exploite de manière adaptative les pertinences d'ordre supérieur. Ceci surmonte les limitations des méthodes précédentes, restreintes à la modélisation de la pertinence par paires basée sur le calcul d'hypergraphes, et permet une fusion et une amélioration efficaces des caractéristiques globales, inter-locales et inter-échelles. S'appuyant sur les avantages de la détection en temps réel de la série YOLO, cette nouvelle version introduit également de nouveaux mécanismes tels que la modélisation sémantique d'ordre supérieur et la reconstruction structurelle légère.Cela étend la modélisation traditionnelle des interactions par paires basée sur les régions à la modélisation globale des associations d'ordre supérieur.
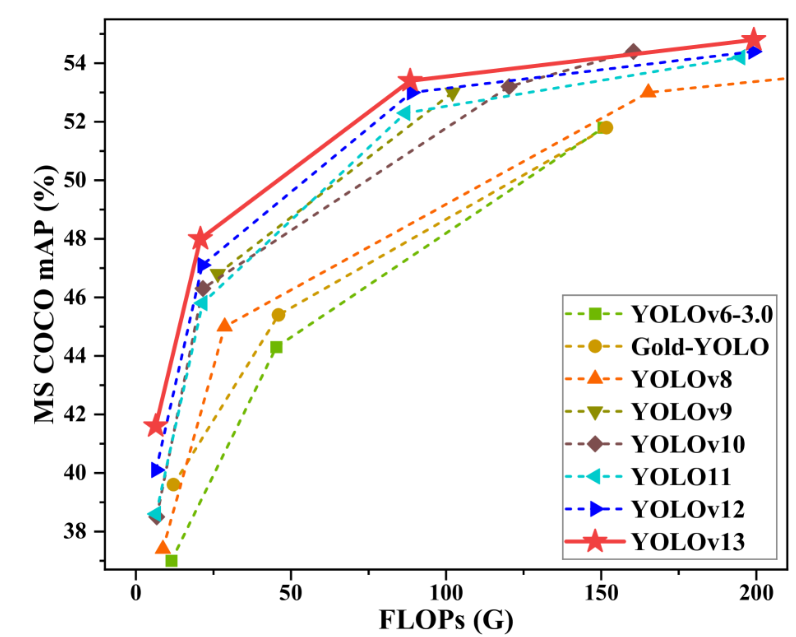
YOLOv13 a acquis une position de leader incontesté sur des ensembles de données majeurs tels que MS COCO et Pascal VOC.Elle démontre des capacités de généralisation et une praticité de déploiement supérieures, offrant des options de performance plus avancées pour les applications dans des scénarios complexes.
Le site web d'HyperAI propose désormais une fonctionnalité de déploiement Yolov13 en un clic. Essayez-la !
Utilisation en ligne :https://go.hyper.ai/PAcy1
Aperçu rapide des mises à jour du site web hyper.ai du 3 au 7 novembre :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
Principales conférences avec des dates limites en novembre : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données sur les indicateurs de santé liés au diabète
L'ensemble de données Diabetes Health Indicators est une base de données analytiques complète en santé et médecine, conçue pour faciliter la prédiction du risque de diabète, la recherche en santé publique et la modélisation par apprentissage automatique. Cet ensemble de données comprend 31 champs de caractéristiques du diabète, répartis en quatre grandes catégories de variables : caractéristiques démographiques, mode de vie, antécédents médicaux et indicateurs cliniques.
Utilisation directe :https://go.hyper.ai/nVnPo
2. Nemotron Personas USA : Un ensemble de données de personas américains.
Nemotron-Personas-USA est un ensemble de données de profils d'utilisateurs synthétiques à grande échelle publié par NVIDIA, conçu pour prendre en charge l'entraînement et l'évaluation de grands modèles de langage (LLM) et de systèmes d'agents intelligents dans des tâches telles que la génération de dialogues, la simulation de rôles, la modélisation d'utilisateurs et l'analyse de comportements divers.
Utilisation directe :https://go.hyper.ai/lMA6r
3. Ensemble de données d'images à ultra-haute résolution UltraHR-100K
UltraHR-100K est un jeu de données à grande échelle et de haute qualité destiné à la conversion de texte en image (T2I) en ultra-haute résolution (UHR). Il vise à améliorer les performances des modèles de diffusion en matière de synthèse de détails fins, de représentation de la diversité du contenu et de fidélité visuelle. Ce jeu de données contient environ 100 000 images en ultra-haute résolution, couvrant un large éventail de sujets, notamment des personnes et des bâtiments. Chaque image possède une résolution supérieure à 3K et est accompagnée d'une description textuelle riche et détaillée.
Utilisation directe :https://go.hyper.ai/I3Fwl

4. Données sur le mode de vie
Lifestyle Data est un ensemble de données complet sur les comportements de santé et de forme physique, conçu pour fournir une base de données de haute qualité aux systèmes de recommandations de santé personnalisées, à l'analyse de l'activité physique et à la modélisation prédictive des modes de vie. Cet ensemble de données intègre des informations sur les individus selon de multiples dimensions, notamment leur alimentation quotidienne, leur activité physique, leurs indicateurs physiologiques et leur composition corporelle. Il est présenté dans un tableau structuré (CSV) avec des champs complets couvrant des variables à plusieurs niveaux telles que les caractéristiques individuelles, les performances sportives, la structure alimentaire et les comportements liés à la forme physique.
Utilisation directe :https://go.hyper.ai/SGK9K
5. Ensemble de données mondial sur les risques de séismes et de tsunamis
L'évaluation mondiale des risques de séismes et de tsunamis est un ensemble de données mondial destiné à l'évaluation des risques de séismes et de tsunamis, conçu pour fournir une base de données standardisée et calculable pour la prévision des risques de tsunamis, l'analyse des événements sismiques et l'évaluation des aléas sismiques.
Utilisation directe :https://go.hyper.ai/a9Nrz
6. Ensemble de données d'évaluation de la distribution vocale ShiftySpeech
ShiftySpeech est un banc d'essai à grande échelle pour la détection de la parole synthétique, développé par l'Université Johns Hopkins. Il vise à étudier la capacité de généralisation des modèles de détection de la synthèse vocale dans le monde réel face à la « dérive de distribution » (incluant les changements de langue, de locuteur, de modèle de génération et de conditions d'enregistrement).
Utilisation directe :https://go.hyper.ai/YMKSP
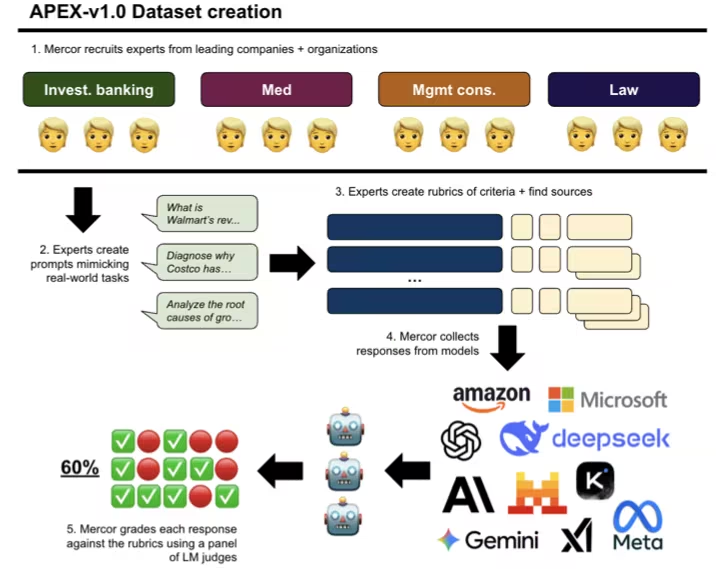
7. Ensemble de données de référence APEX AI pour la productivité
APEX est un ensemble de données de référence complet, initialement publié par l'équipe de recherche de Mercor en collaboration avec la faculté de droit de Harvard et le Scripps Research Institute. Il sert à évaluer les performances des modèles d'intelligence artificielle de pointe dans les tâches intellectuelles à forte valeur économique. Son objectif est de mesurer les performances de ces modèles face à des problématiques économiques concrètes, et non de se limiter au raisonnement abstrait.
Utilisation directe :https://go.hyper.ai/3E2on
8. Ensemble de données de référence pour les tâches de base multilingues Multi-LMentry
Multi-LMentry est un jeu de données de référence multilingue conçu pour évaluer systématiquement la capacité de généralisation interlingue des grands modèles de langage (LLM) pour la compréhension du langage de bas niveau et les tâches de raisonnement élémentaire dans des environnements multilingues. Ce jeu de données couvre neuf langues, dont l'anglais et l'allemand. Les tâches sont reformulées manuellement par des locuteurs natifs, dans une forme similaire à celle du cadre LMentry original, mais sans traduction directe, afin de garantir leur naturel et leur adéquation culturelle.
Utilisation directe :https://go.hyper.ai/o2uJC
9. Ensemble de données de montage vidéo piloté par les instructions Ditto-1M
Ditto-1M est un ensemble de données de montage vidéo piloté par instructions, développé par l'Université des sciences et technologies de Hong Kong en collaboration avec Ant Group, l'Université du Zhejiang et d'autres institutions. Il vise à promouvoir le développement de modèles de montage vidéo basés sur des instructions en langage naturel et à améliorer la compréhension des instructions complexes par ces modèles ainsi que la précision de la génération vidéo grâce à des échantillons synthétiques de grande envergure et de haute qualité.
Utilisation directe :https://go.hyper.ai/o2uJC

10. Données de performance du réacteur chimique Reac-Discoveryensemble
Reac-Discovery, développé par l'Université Jaume I, est un jeu de données destiné à la conception de réacteurs à flux continu pilotée par l'IA et à l'optimisation des performances réactionnelles. Ce jeu de données est généré automatiquement lors d'expériences réalisées sur la plateforme Reac-Discovery, développée en interne par l'équipe, sans recours à des sources de données externes publiques. Il couvre trois catégories de données : géométrie, imprimabilité et performances réactionnelles, correspondant aux modules fonctionnels Reac-Gen, Reac-Fab et Reac-Eval de la plateforme.
Utilisation directe :https://go.hyper.ai/bMxVY
Tutoriels publics sélectionnés
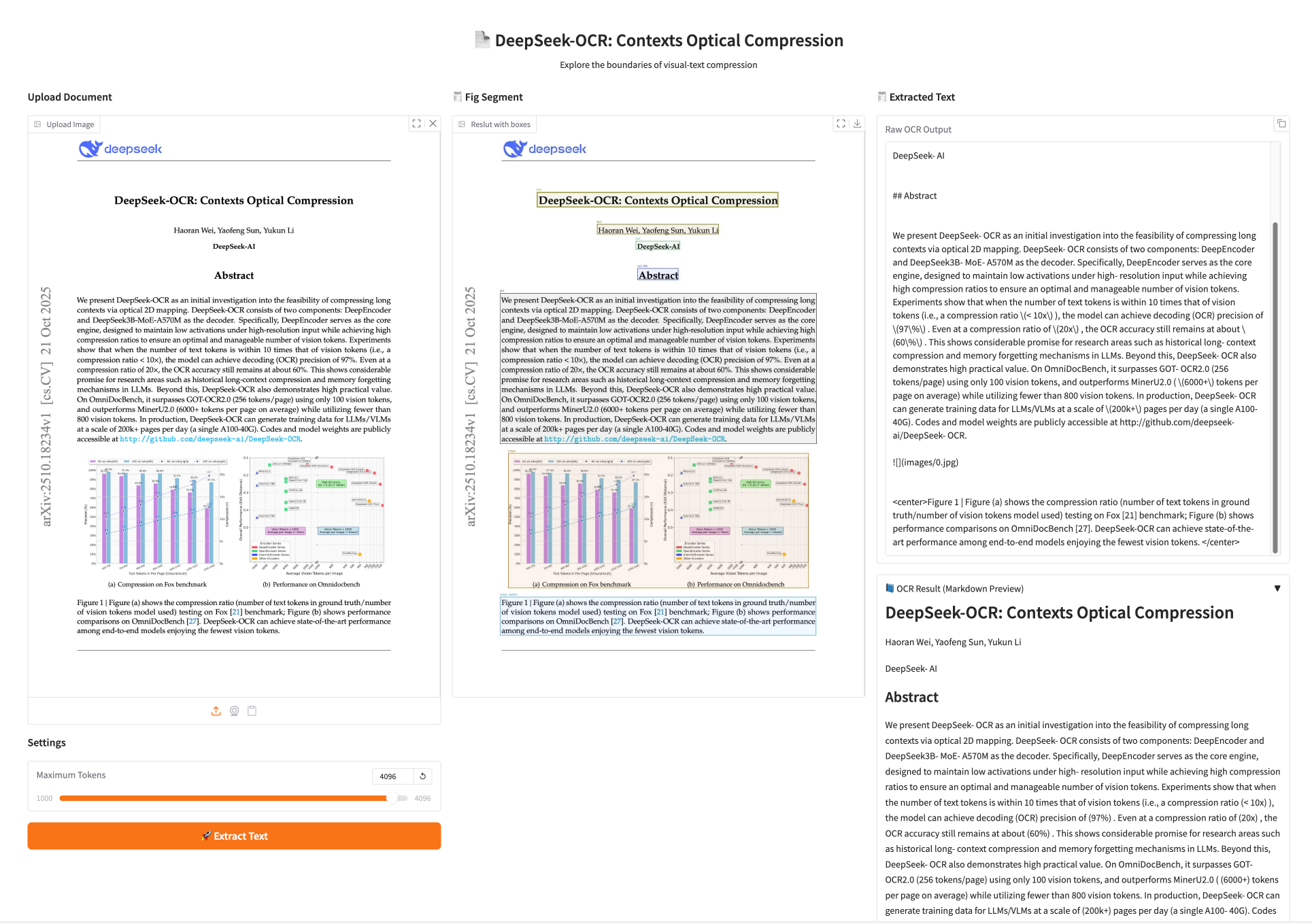
1. DeepSeek-OCR : La « compression visuelle » remplace la reconnaissance de caractères traditionnelle
DeepSeek-OCR, développé par DeepSeek Inc., est une étude préliminaire sur la faisabilité de la compression de longs contextes à partir d'images. Les expériences montrent que lorsque le nombre de jetons textuels ne dépasse pas 10 fois celui des jetons visuels (soit un taux de compression inférieur à 10×), le modèle atteint une précision de décodage (OCR) de 971 TP3T. Même avec un taux de compression de 20×, la précision de l'OCR reste d'environ 601 TP3T.
Exécutez en ligne :https://go.hyper.ai/wmghV
2. Nanonets-OCR2-3B : Interprétation plus précise des éléments visuels dans les documents complexes
Nanonets-OCR2-3B est un modèle de conversion d'images en Markdown développé par Nanonets. Ce modèle permet non seulement de convertir des documents en Markdown structuré, mais aussi d'exploiter la reconnaissance intelligente de contenu, le balisage sémantique et la réponse visuelle contextuelle aux questions pour une compréhension plus approfondie et une interprétation plus précise des documents complexes.
Exécuter en ligne : https://go.hyper.ai/3DWbb
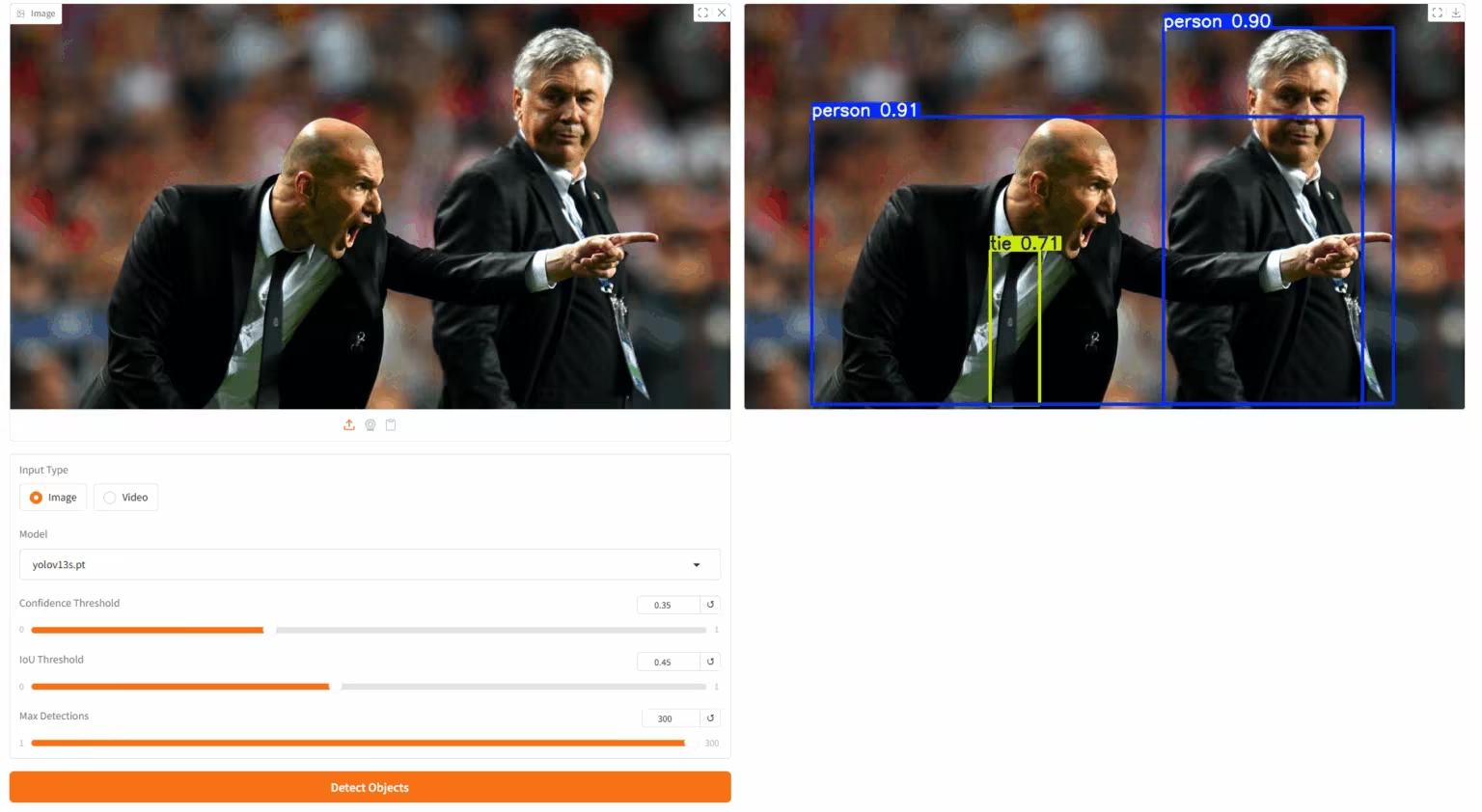
3. Déploiement de Yolov13 en un clic
YOLOv13 est un modèle de détection d'objets proposé par une équipe de recherche conjointe de l'Université Tsinghua, de l'Université de Technologie de Taiyuan, de l'Université Jiaotong de Xi'an et d'autres universités. S'appuyant sur les avantages de la détection en temps réel de la série YOLO, ce modèle introduit de nouveaux mécanismes tels que l'amélioration des hypergraphes, la modélisation sémantique d'ordre supérieur et la reconstruction structurelle légère. Il se distingue nettement sur des jeux de données de référence comme MS COCO et Pascal VOC, démontrant ainsi une capacité de généralisation accrue et une grande facilité d'utilisation.
Exécutez en ligne :https://go.hyper.ai/PAcy1
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Chaque activation optimisée : passage à l’échelle du raisonneur général pour une base de langage ouvert de 1 000 milliards d’utilisateurs
Cet article présente Ling 2.0, un modèle de base de langage pour les tâches de raisonnement sérialisées, construit sur le principe fondamental d'« amélioration de la capacité de raisonnement à chaque activation ». Sous une architecture unifiée de type Mixture-of-Experts (MoE), ce modèle peut évoluer de milliards à mille milliards de paramètres, en mettant l'accent sur une forte parcimonie, une cohérence inter-échelle et une efficacité guidée par des lois d'échelle empiriques.
Lien vers l'article :https://go.hyper.ai/O4pRV
2. ThinkMorph : Propriétés émergentes dans le raisonnement multimodal à chaîne de pensée entrelacée
Cet article présente ThinkMorph, un modèle unifié affiné sur 24 000 trajectoires de raisonnement entrelacées de haute qualité, couvrant une variété de tâches avec différents niveaux d’implication visuelle, capable de générer des étapes de raisonnement graphique-texte progressives et de maintenir une logique sémantique cohérente tout en manipulant le contenu visuel.
Lien vers l'article :https://go.hyper.ai/AGtSS
3. Ne laissez pas votre VLA aveugler : aligner les représentations visuelles pour la généralisation OOD
Cette étude a examiné de manière systématique la préservation des représentations lors du réglage fin des modèles Vision-Langage-Action (VLA), et a constaté que le réglage fin de l'action directe entraîne une dégradation des performances de la représentation visuelle. Afin de caractériser et de mesurer cet impact, les chercheurs ont exploré les représentations sous-jacentes des modèles VLA et analysé leurs cartes attentionnelles. De plus, une série de tâches et de méthodes ciblées ont été conçues pour comparer les modèles VLA à leurs modèles VLM correspondants, isolant ainsi les modifications des capacités visuo-langagières induites par le réglage fin de l'action.
Lien vers l'article :https://go.hyper.ai/xNU6P
4. OS-Sentinel : Vers des agents d’interface graphique mobile plus sûrs grâce à une validation hybride dans des flux de travail réalistes
Cet article propose un nouveau cadre de détection de sécurité hybride, OS-Sentinel, qui détecte de manière collaborative les violations explicites au niveau du système grâce à un vérificateur formel, tout en évaluant simultanément les risques contextuels et les comportements de proxy à l'aide d'un juge contextuel basé sur VLM.
Lien vers l'article :https://go.hyper.ai/bG6b5
5. VCode : un banc d’essai de codage multimodal utilisant le SVG comme représentation visuelle symbolique
Cet article propose VCode, un cadre de référence qui transforme la compréhension multimodale en une tâche de génération de code : à partir d’une image, le modèle doit générer du code SVG préservant la sémantique symbolique pour permettre l’inférence ultérieure. Ce cadre couvre trois domaines : la compréhension générale (MM-Vet), les connaissances spécifiques à un sujet (MMMU) et les tâches centrées sur la perception visuelle (CV-Bench).
Lien vers l'article :https://go.hyper.ai/UNmqK
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
En octobre 2025, Demis Hassabis, PDG de Google DeepMind, figurait en couverture du classement TIME 100 du magazine Time. D'AlphaGo à AlphaFold, Hassabis a toujours défendu l'orientation scientifique de l'IA au service de la science, mais suite à l'intégration de DeepMind à Google, de nombreux médias ont critiqué les ambitions commerciales et les controverses éthiques de l'entreprise.
Voir le rapport complet :https://go.hyper.ai/vSqZI
NeuTTS-Air, le dernier modèle de synthèse vocale open source de bout en bout de Neuphonic, atteint des performances de pointe parmi les modèles open source, notamment en synthèse hyperréaliste et en inférence en temps réel. Il peut également s'adapter à de nouveaux scénarios tels que les agents intégrés et le transfert de style, prend en charge le clonage audio de 3 secondes et génère des dialogues naturels.
Voir le rapport complet :https://go.hyper.ai/5kAIi
Une équipe conjointe de l'ETH Zurich, de Caltech et de l'Université de l'Alberta a proposé un cadre d'apprentissage profond appelé NOBLE. Il s'agit du premier cadre d'apprentissage profond à grande échelle à valider ses performances à l'aide de données expérimentales provenant du cortex cérébral humain. De plus, et c'est la première fois, il apprend directement la dynamique non linéaire des neurones à partir de données expérimentales, atteignant des vitesses de simulation 4 200 fois supérieures à celles des solveurs numériques traditionnels.
Voir le rapport complet :https://go.hyper.ai/oQ74B
Fondée par trois jeunes de 22 ans ayant abandonné leurs études, Mercor a levé 350 millions de dollars lors d'un tour de table de série C en moins de trois ans, sa valorisation atteignant 10 milliards de dollars. L'entreprise réduit l'efficacité du recrutement traditionnel à quelques secondes grâce à son modèle de recrutement basé sur l'IA et a lancé le benchmark APEX, établissant une nouvelle norme pour évaluer la valeur économique de l'IA.
Voir le rapport complet :https://go.hyper.ai/kBj1w
Une équipe de recherche dirigée par le professeur David Baker de l'Université de Washington a développé un réseau neuronal graphique appelé PLACER, capable de générer avec précision les structures de diverses petites molécules organiques à partir de leur composition atomique et des informations de liaison de ces petites molécules ; et, étant donné la structure macroscopique des protéines, il peut construire les structures détaillées des petites molécules et des chaînes latérales des protéines pour les tâches d'amarrage protéine-petite molécule.
Voir le rapport complet :https://go.hyper.ai/sisqO
Articles populaires de l'encyclopédie
1. DALL-E
2. Hyperréseaux
3. Front de Pareto
4. Mémoire à long terme bidirectionnelle (Bi-LSTM)
5. Fusion de rangs réciproques
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de novembre pour le sommet
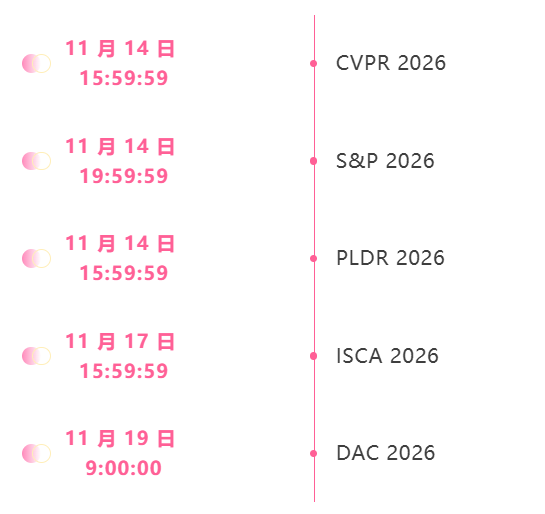
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








