Command Palette
Search for a command to run...
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
MM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Abstract
Self-evolving has emerged as a key paradigm for improving foundational models such as Large Language Models (LLMs) and Vision Language Models (VLMs) with minimal human intervention. While recent approaches have demonstrated that LLM agents can self-evolve from scratch with little to no data, VLMs introduce an additional visual modality that typically requires at least some seed data, such as images, to bootstrap the self-evolution process. In this work, we present Multi-model Multimodal Zero (MM-Zero), the first RL-based framework to achieve zero-data self-evolution for VLM reasoning. Moving beyond prior dual-role (Proposer and Solver) setups, MM-Zero introduces a multi-role self-evolving training framework comprising three specialized roles: a Proposer that generates abstract visual concepts and formulates questions; a Coder that translates these concepts into executable code (e.g., Python, SVG) to render visual images; and a Solver that performs multimodal reasoning over the generated visual content. All three roles are initialized from the same base model and trained using Group Relative Policy Optimization (GRPO), with carefully designed reward mechanisms that integrate execution feedback, visual verification, and difficulty balancing. Our experiments show that MM-Zero improves VLM reasoning performance across a wide range of multimodal benchmarks. MM-Zero establishes a scalable path toward self-evolving multi-model systems for multimodal models, extending the frontier of self-improvement beyond the conventional two-model paradigm.
One-sentence Summary
Researchers from the University of Maryland, Brown University, and NVIDIA introduce MM-Zero, the first reinforcement learning framework enabling vision-language models to self-evolve without external data by employing a novel tri-role system of Proposer, Coder, and Solver to generate and reason over synthetic visual content.
Key Contributions
- MM-Zero addresses the bottleneck of requiring seed image data for Vision Language Model self-evolution by introducing the first framework to achieve zero-data training through autonomous visual content generation.
- The method replaces traditional dual-role setups with a novel tri-role pipeline where a Proposer creates abstract concepts, a Coder renders them into executable code, and a Solver performs reasoning, all optimized via Group Relative Policy Optimization.
- Experiments on Qwen3-VL and Mimo-VL models demonstrate that this approach yields consistent performance improvements across diverse multimodal benchmarks without relying on any external human-annotated datasets.
Introduction
Self-evolving paradigms offer a scalable path to improve Vision Language Models (VLMs) by reducing reliance on costly human-annotated data, yet existing methods remain bottlenecked by their dependence on static seed image datasets. Prior approaches typically adapt dual-role proposer-solver frameworks that can only iterate within the fixed distribution of pre-collected images, limiting the diversity and complexity of generated training scenarios. The authors leverage a novel tri-role reinforcement learning framework called MM-Zero that achieves true zero-data self-evolution by introducing a specialized Coder role to programmatically render visual content from abstract concepts. This system enables a Proposer, Coder, and Solver to interact in a closed loop where the model generates its own visual training data and reasoning tasks without any external inputs, significantly expanding the frontier of autonomous multimodal learning.
Method
The authors present MM-Zero, a self-evolving framework for Multimodal Large Language Models (MLLMs) that utilizes Reinforcement Learning with Verifiable Rewards (RLVR). The system is composed of three distinct model agents evolved from the same base model: a Proposer (πP), a Coder (πD), and a Solver (πS). These agents operate in a closed training loop where each role is optimized sequentially via Group Relative Policy Optimization (GRPO) while the others remain frozen.
Refer to the framework diagram to understand the interaction between these components. The Proposer generates a quadruple consisting of a fine-grained textual description, an easy question with a known answer, and a hard question requiring multi-step reasoning. The Coder converts the textual description into executable code (specifically SVG) to render a figure. The Solver then processes the rendered image. It first answers the easy question to verify semantic correctness, providing a reward signal to update the Coder. Subsequently, it answers the hard question using majority voting to generate pseudo-labels for its own training while providing a difficulty reward to optimize the Proposer.
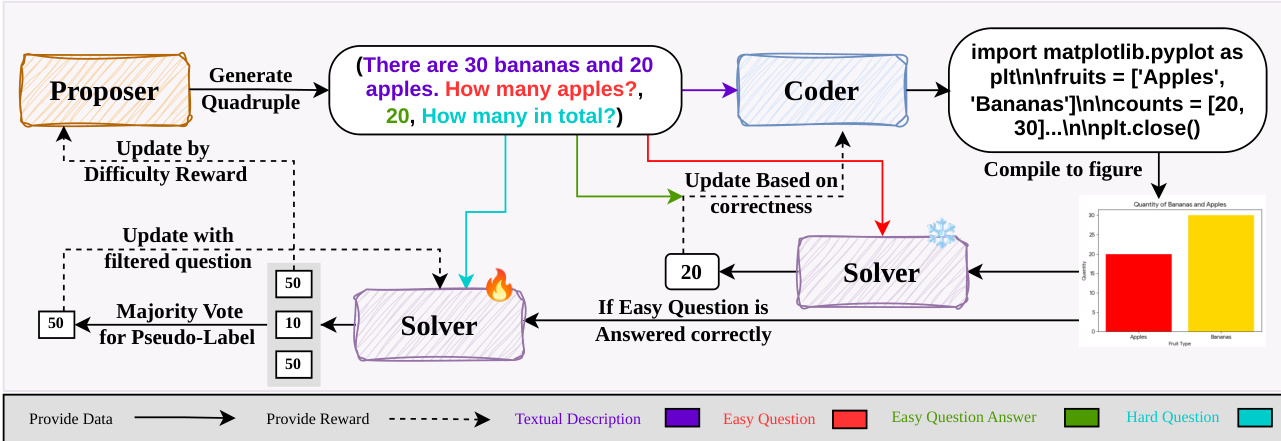
The training pipeline involves an iterative evolution of the models. As shown in the figure below, the Coder and Proposer improve over iterations (Iter 1 to Iter 3), generating increasingly complex visual content and questions. For instance, the Coder evolves from rendering simple stacked bar charts to complex geometric constructions with multiple overlapping circles. The Proposer evolves to generate more detailed captions and harder questions that push the Solver's reasoning capabilities. To ensure training quality, the authors apply stage-specific data filters. For the Coder, they retain examples where the rendering success rate falls within a specific range, excluding trivially simple or impossible tasks. For the Solver, they keep examples where easy-question accuracy is high but hard-question accuracy remains in a challenging range, ensuring the model is trained on data of appropriate difficulty.

The reward formulation is central to the self-evolving process. The Proposer receives a hierarchical reward Rp(x) that validates formatting, solvability, and difficulty. This includes a code execution indicator, a solvability score based on the Solver's accuracy on the easy question, and a difficulty score based on the Solver's self-consistency on the hard question. The difficulty score follows the Goldilocks principle, peaking when the Solver is maximally uncertain. Additionally, penalties are applied for easy-hard mismatches and lack of content diversity.
The Coder is rewarded based on execution status, semantic correctness (solvability of the easy question), and task feasibility (difficulty of the hard question). The Solver, trained on hard questions without ground truth labels, utilizes Test-Time Reinforcement Learning (TTRL). It generates multiple reasoning paths and identifies a silver answer via majority vote. The reward for the Solver is a weighted sum of answer accuracy against this consensus and structural validity, ensuring the model adheres to a Chain-of-Thought format followed by a boxed final answer.
The authors adopt Group Relative Policy Optimization (GRPO) to update the policies. Given a prompt p, the current policy generates a group of N responses with corresponding rewards. These rewards are normalized within the group to yield response-level advantages A^i, which are used to maximize a clipped surrogate objective regularized with a KL divergence term. This approach allows the system to improve reasoning and generation quality without requiring a learned value function.
Experiment
- Solver evaluation across general visual reasoning, mathematical visual reasoning, and hallucination detection benchmarks validates that the proposed framework improves model performance without external data, with the most significant gains observed in complex visual math tasks.
- Experiments on multiple model sizes demonstrate that the method generalizes effectively, though models with stronger base capabilities and higher image rendering success rates achieve greater improvements.
- Qualitative analysis of training iterations reveals a clear evolution where generated images transition from cluttered and unreadable to polished and faithful, while questions progress from trivial value extraction to requiring genuine multi-step compositional reasoning.
- Ablation studies confirm that capping solvability rewards prevents the model from exploiting shortcuts by embedding answers directly in images, while enforcing content diversity avoids overfitting to narrow visual types like histograms.
- Continued training beyond initial iterations shows that performance does not saturate, indicating a promising path for self-evolving multimodal models to improve reasoning capabilities autonomously.