Command Palette
Search for a command to run...
Bias In, Bias Out? Finding Unbiased Subnetworks in Vanilla Models
Bias In, Bias Out? Finding Unbiased Subnetworks in Vanilla Models
Ivan Luiz De Moura Matos Abdel Djalil Sad Saoud Ekaterina Iakovleva Vito Paolo Pastore Enzo Tartaglione
Abstract
The issue of algorithmic biases in deep learning has led to the development of various debiasing techniques, many of which perform complex training procedures or dataset manipulation. However, an intriguing question arises: is it possible to extract fair and bias-agnostic subnetworks from standard vanilla-trained models without relying on additional data, such as unbiased training set? In this work, we introduce Bias-Invariant Subnetwork Extraction (BISE), a learning strategy that identifies and isolates "bias-free" subnetworks that already exist within conventionally trained models, without retraining or finetuning the original parameters. Our approach demonstrates that such subnetworks can be extracted via pruning and can operate without modification, effectively relying less on biased features and maintaining robust performance. Our findings contribute towards efficient bias mitigation through structural adaptation of pre-trained neural networks via parameter removal, as opposed to costly strategies that are either data-centric or involve (re)training all model parameters. Extensive experiments on common benchmarks show the advantages of our approach in terms of the performance and computational efficiency of the resulting debiased model.
One-sentence Summary
Researchers from Télécom Paris and the University of Genoa introduce Bias-Invariant Subnetwork Extraction, a method that prunes pre-trained models to isolate fair subnetworks without retraining or extra data, offering a computationally efficient alternative to complex debiasing techniques that rely on dataset manipulation or full parameter updates.
Key Contributions
- Current debiasing techniques often require complex retraining or additional unbiased data, whereas this work addresses the challenge of extracting fair subnetworks from standard vanilla-trained models without any parameter updates or external datasets.
- The proposed Bias-Invariant Subnetwork Extraction (BISE) method identifies and isolates bias-agnostic subnetworks through structured pruning by optimizing an objective function that balances empirical loss while minimizing bias-related information.
- Extensive experiments on common benchmarks demonstrate that these extracted subnetworks operate effectively without modification and achieve state-of-the-art accuracy when further finetuned, offering a computationally efficient alternative to costly data-centric strategies.
Introduction
Algorithmic bias in deep learning often stems from models learning spurious correlations in training data, leading to unfair outcomes that violate emerging regulations like the EU AI Act. Current mitigation strategies typically require complex retraining procedures, adversarial objectives, or access to balanced datasets that are often unavailable or costly to curate. The authors introduce Bias-Invariant Subnetwork Extraction (BISE), a method that identifies and isolates bias-robust subnetworks within standard vanilla-trained models using structured pruning. This approach eliminates the need for retraining or additional unbiased data by learning auxiliary variables to remove bias-related parameters while preserving task performance.
Dataset
Dataset Overview
The authors evaluate their method using five popular datasets designed to test debiasing capabilities across image and text domains. Each dataset introduces a specific spurious correlation between a target label and a bias attribute.
- BiasedMNIST: A synthetic dataset built on MNIST where the background color is correlated with the digit label. The training set uses a high correlation probability (ρ) to create strong bias alignment, while the test set uses ρ=0.1 to ensure unbiased evaluation.
- Corrupted-CIFAR10: Derived from CIFAR10, this dataset applies specific image corruptions (e.g., fog, brightness) that correlate with the object class. Training sets are generated with bias alignment probabilities ranging from 0.95 to 0.995, whereas the test set remains unbiased with ρ=0.1.
- CelebA: A real-world face dataset containing 202,599 images with 40 attributes. The authors treat "BlondHair" as the target label and "Male" as the bias, exploiting the spurious correlation where blond hair is predominantly associated with women in the data.
- Multi-Color MNIST: A benchmark for handling multiple biases where the image background is split into left and right sides, each with a distinct color correlated to the digit. The training set uses high correlation probabilities for both sides (ρL=0.99,ρR=0.95), while the test set uses low probabilities (0.1 for both).
- CivilComments: A text classification dataset used to predict toxicity. The bias is defined as the presence of any sensitive attribute (e.g., gender, race, religion). The authors utilize the coarse version of the dataset where these eight attributes are aggregated into a single binary bias label.
Usage and Processing Details
The paper employs specific architectures and processing strategies to train and evaluate the model on these datasets.
- Model Architectures: The authors use a convolutional neural network for BiasedMNIST, a ResNet-18 pre-trained on ImageNet-1K for CelebA and Corrupted-CIFAR10, an MLP for Multi-Color MNIST, and a BERT model for CivilComments.
- Training Strategy: The method involves learning masks via SGD with a learning rate of 10−2 and a decaying temperature parameter τ. An auxiliary classifier is trained for 50 epochs to identify bias features.
- Handling Multiple Biases: For Multi-Color MNIST, the authors employ two separate auxiliary classifiers to predict the left and right background colors independently, following a reweighting strategy to manage the dual biases.
- Data Splits: In all image-based experiments, the training data is intentionally biased to force reliance on spurious features, while the test data is constructed to be unbiased to measure true generalization.
- Fine-tuning: After extracting the subnetwork using the BISE method, the authors fine-tune the model using the same optimizer settings as the original vanilla model.
Method
The authors introduce BISE (Bias-Informed Subnetwork Extraction), a debiasing pruning method designed to identify and extract an unbiased subnetwork from a pre-trained, biased model without requiring additional training of the original parameters or access to unbiased data. The method operates under a supervised debiasing setup where the training dataset Dtrain contains spurious correlations between the target label y and a bias attribute b, while the test set Dtest is unbiased.
The overall workflow is illustrated in the framework diagram below, which depicts the transition from a standard biased model to a debiased pruned model.
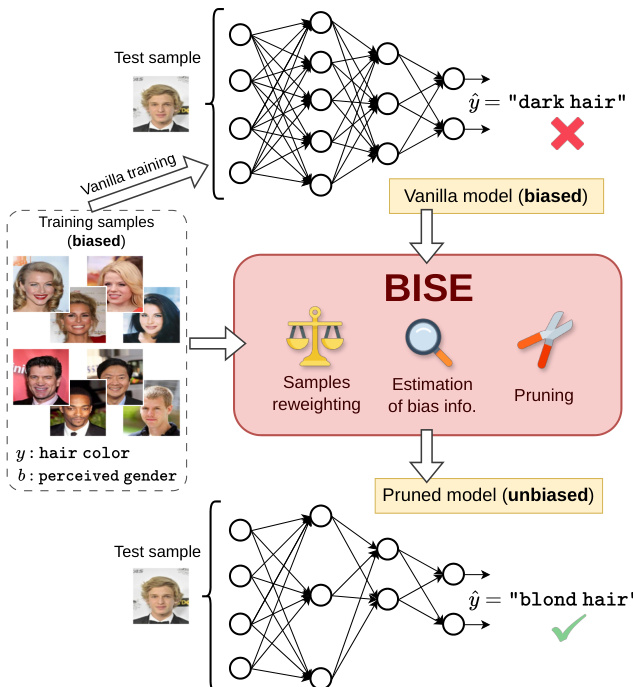
As shown in the figure, the process begins with a vanilla model trained on biased samples, which often fails on unbiased test cases due to reliance on spurious features. BISE intervenes through three core mechanisms: sample reweighting, estimation of bias information, and pruning. The goal is to find a subset of neurons within the original network that maintains accuracy on the target task while minimizing dependence on the bias attribute.
The detailed architecture and training dynamics are presented in the figure below.
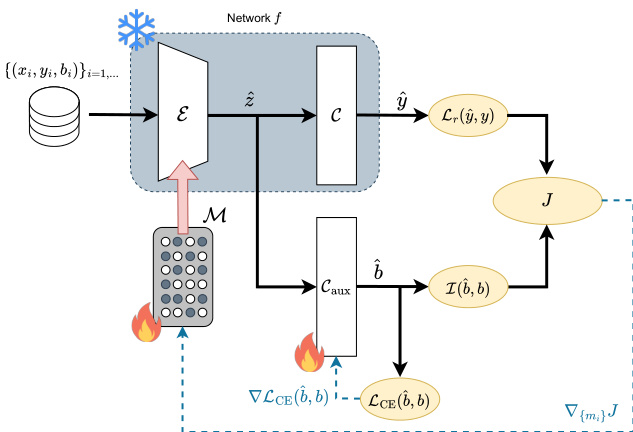
The network f is decomposed into an encoder E and a classifier C. The authors introduce a learnable pruning mask M applied to the encoder's parameters. Specifically, for each structural component (e.g., a neuron or filter) i in the encoder, a masking parameter mi is learned. The output hi is modified as:
h^i=hi⋅1{m^i≥0.5}, with m^i=σ(τmi)where σ(⋅) is the sigmoid function and τ is a temperature parameter annealed to zero during training. This gating mechanism enforces confidence in the pruning decision, where mi<0 indicates pruning and mi≥0 indicates preservation.
To optimize the mask, the authors define a composite objective function J that balances task performance and bias reduction:
J(y^,y,b^,b)=Lr(y^,y)+γI(b^,b)The first term, Lr(y^,y), is a reweighted cross-entropy loss. To counteract the prevalence of bias-aligned samples in Dtrain, the contribution of bias-conflicting samples is amplified by assigning weights inversely proportional to their group sizes. The second term, I(b^,b), estimates the mutual information between the predicted bias b^ and the true bias b. This is achieved by attaching an auxiliary classifier Caux to the bottleneck representation z^, as seen in the architecture diagram. The auxiliary head is trained to predict b from z^, and minimizing I(b^,b) ensures the latent representation contains less information about the bias attribute.
The training process involves an iterative loop where the mask parameters {mi} and the auxiliary classifier Caux are updated jointly. The temperature τ is annealed periodically to sharpen the mask decisions. Once the temperature drops below a threshold τmin, the final binary mask is extracted, yielding a pruned subnetwork that is robust to the spurious correlations present in the original training data.
Experiment
- Main experiments across BiasedMNIST, Corrupted-CIFAR10, CelebA, Multi-Color MNIST, and CivilComments validate that BISE extracts subnetworks with higher unbiased accuracy than vanilla dense models, effectively mitigating spurious correlations even under strong bias.
- Comparative studies demonstrate that BISE outperforms other debiasing approaches and random or magnitude-based pruning by identifying unbiased substructures without requiring retraining of the original parameters.
- Ablation studies confirm that the mutual information term in the loss function is critical for achieving high sparsity and reducing the retention of bias-related features, while the method shows low sensitivity to hyperparameter variations.
- Experiments in unsupervised settings and under noisy bias labels show that BISE remains competitive and robust, successfully extracting improved subnetworks even without ground-truth bias information.
- Analysis of latent representations indicates that the pruned subnetworks make bias features harder to predict, confirming a reduction in bias reliance, though performance is limited when biases are extremely severe or multiple biases interact without subsequent finetuning.