Command Palette
Search for a command to run...
Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Zorik Gekhman Roee Aharoni Eran Ofek Mor Geva Roi Reichart Jonathan Herzig
Abstract
While reasoning in LLMs plays a natural role in math, code generation, and multi-hop factual questions, its effect on simple, single-hop factual questions remains unclear. Such questions do not require step-by-step logical decomposition, making the utility of reasoning highly counterintuitive. Nevertheless, we find that enabling reasoning substantially expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable. Why does reasoning aid parametric knowledge recall when there are no complex reasoning steps to be done? To answer this, we design a series of hypothesis-driven controlled experiments, and identify two key driving mechanisms: (1) a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content; and (2) factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval. Importantly, this latter generative self-retrieval mechanism carries inherent risks: we demonstrate that hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer. Finally, we show that our insights can be harnessed to directly improve model accuracy by prioritizing reasoning trajectories that contain hallucination-free factual statements.
One-sentence Summary
Researchers from Google Research, Technion, and Tel Aviv University demonstrate that enabling reasoning in large language models expands parametric knowledge recall for simple questions through computational buffering and factual priming, while revealing that hallucinated intermediate facts significantly degrade final answer accuracy.
Key Contributions
- Enabling reasoning substantially expands the parametric knowledge recall boundary of large language models, unlocking correct answers for simple single-hop questions that are otherwise unreachable.
- Controlled experiments identify two driving mechanisms: a content-independent computational buffer effect and a content-dependent factual priming process where generating related facts acts as a semantic bridge for retrieval.
- A large-scale audit reveals that hallucinated intermediate facts increase the likelihood of final answer errors, while prioritizing hallucination-free reasoning trajectories at inference time significantly improves model accuracy.
Introduction
Reasoning in Large Language Models is well-established for complex tasks like math and coding, yet its value for simple, single-hop factual questions remains counterintuitive since these queries do not require logical decomposition. Prior research has largely focused on how reasoning aids multi-step problem solving or improves probability sharpening for already accessible answers, leaving a gap in understanding how it expands the model's fundamental parametric knowledge boundary. The authors demonstrate that enabling reasoning significantly unlocks correct answers that are otherwise unreachable by leveraging two distinct mechanisms: a content-independent computational buffer effect and a content-dependent factual priming process where the model generates related facts to bridge retrieval gaps. They further reveal that while this generative self-retrieval boosts accuracy, it introduces a risk where hallucinated intermediate facts increase the likelihood of final answer errors, a finding they use to propose inference strategies that prioritize hallucination-free reasoning trajectories.
Dataset
- Dataset Composition and Sources: The authors utilize a subset of the EntityQuestions dataset (Sciavolino et al., 2021), specifically focusing on 24 relations originally categorized by Gekhman et al. (2025).
- Subset Selection Criteria: From the original 24 relations, the team selected only 4 that meet two strict criteria: they must be "Hard to Guess" (where the answer space is large, such as person names) and "Well Defined" (where entity types and answer granularity are unambiguous).
- Data Structure and Processing: Each input sample consists of a question generated from a specific relation template paired with original facts provided as a summary.
- Model Usage: These curated relations serve as the foundation for evaluating the model's ability to handle complex, unambiguous entity queries rather than relying on common defaults.
Method
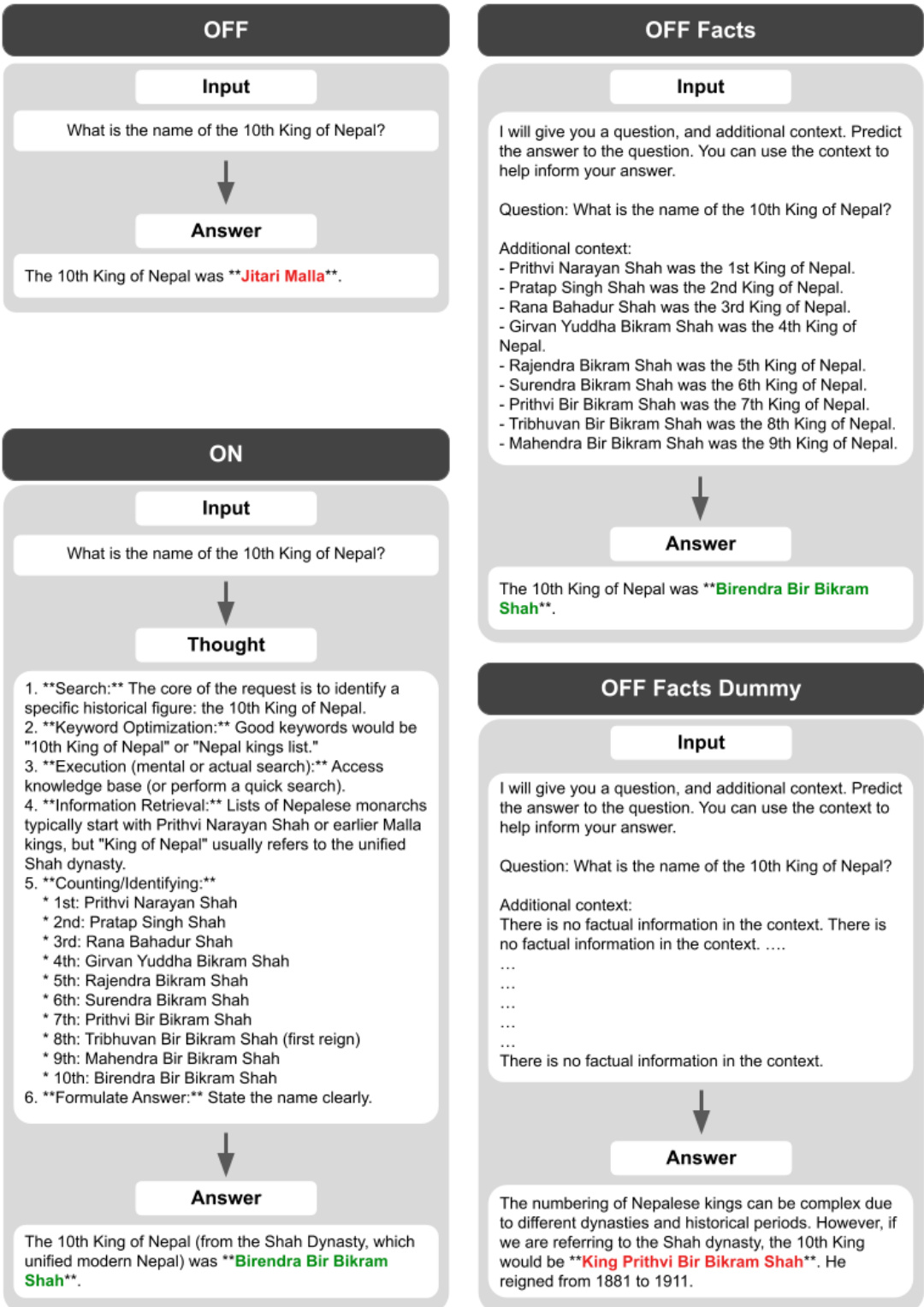
The proposed framework distinguishes between direct answer generation and reasoning-augmented generation. As illustrated in the first figure, the system operates in several modes: "OFF" (direct input to answer), "ON" (input to detailed thought process to answer), and variations involving "Dummy" thoughts which serve as placeholders or control conditions. In the "ON" mode, the model explicitly decomposes the query into steps such as identifying key entities, formulating search queries, and executing a search (simulated or actual) before stating the final answer.

The framework also incorporates scenarios where additional factual context is provided alongside the input question. The second figure demonstrates these variations, including "OFF Facts" where context is given but no thought process is generated, and "ON" where the model performs a detailed retrieval and counting process even when context is available. In the "ON" mode with facts, the reasoning trace includes steps for keyword optimization, information retrieval, and specific counting or identifying of entities (e.g., listing the 1st through 10th King of Nepal) to derive the answer.
Following the generation of these reasoning traces, a specific data processing module is employed to refine the extracted facts. Since reasoning traces often restate information already present in the question, the authors implement an LLM-based filtering step to remove such redundancies. This process utilizes a model (e.g., Gemini-2.5-Flash) to analyze the "Original Facts" against the input question. The filtering logic dictates that a fact is removed only if all the information it contains is explicitly stated in the question. Conversely, a fact is retained if it provides any new information, details, or context not found in the question, even if it partially repeats the question content.
Furthermore, specific rules are applied to prevent the model from simply memorizing the answer. A fact is removed if it states or implies that the target answer is the solution to the specific question. However, facts that mention the answer in an unrelated context or do not mention the answer at all are preserved. This ensures that the training data captures the reasoning path and external knowledge retrieval rather than just the final answer mapping.
Experiment
- Experiments using hybrid models with reasoning toggled ON or OFF on closed-book QA benchmarks demonstrate that reasoning consistently expands the model's parametric knowledge boundary, unlocking correct answers that remain unreachable without it, particularly at higher sampling depths.
- Analysis reveals that these gains are not primarily driven by decomposing complex multi-hop questions, as reasoning effectiveness remains similar for simple and complex question types, indicating the mechanism facilitates direct factual recall rather than task decomposition.
- Controlled tests validate two complementary mechanisms: a computational buffer effect where generating extra tokens enables latent computation independent of semantic content, and factual priming where recalling related facts creates a semantic bridge to the correct answer.
- Investigations into reasoning traces show that hallucinated intermediate facts systematically reduce the likelihood of a correct final answer, whereas traces containing verified factual statements significantly improve accuracy.
- Practical application of these findings through test-time selection strategies that prioritize traces with factual content and avoid hallucinations yields measurable improvements in model accuracy.