HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics

Memory in the Age of AI Agents



























Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics
Memory in the Age of AI Agents
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
FirstAidQA: A Synthetic Dataset for First Aid and Emergency Response in Low-Connectivity Settings
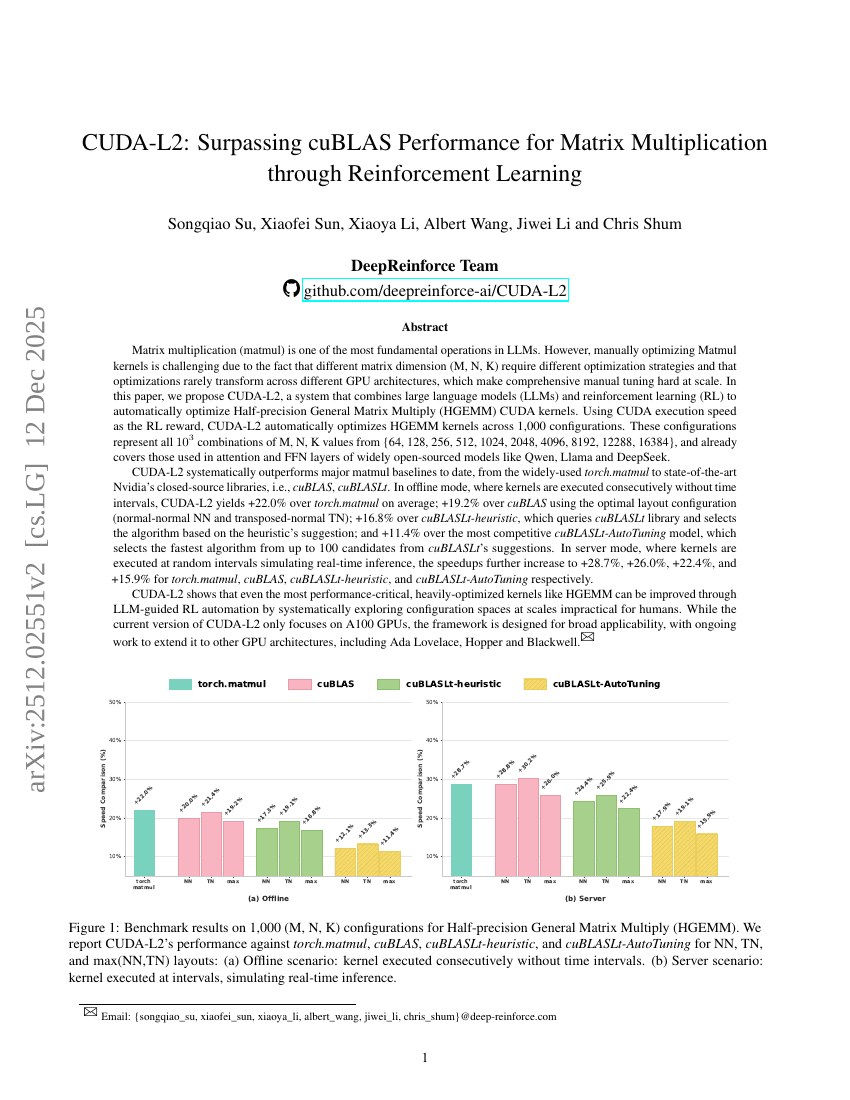
CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
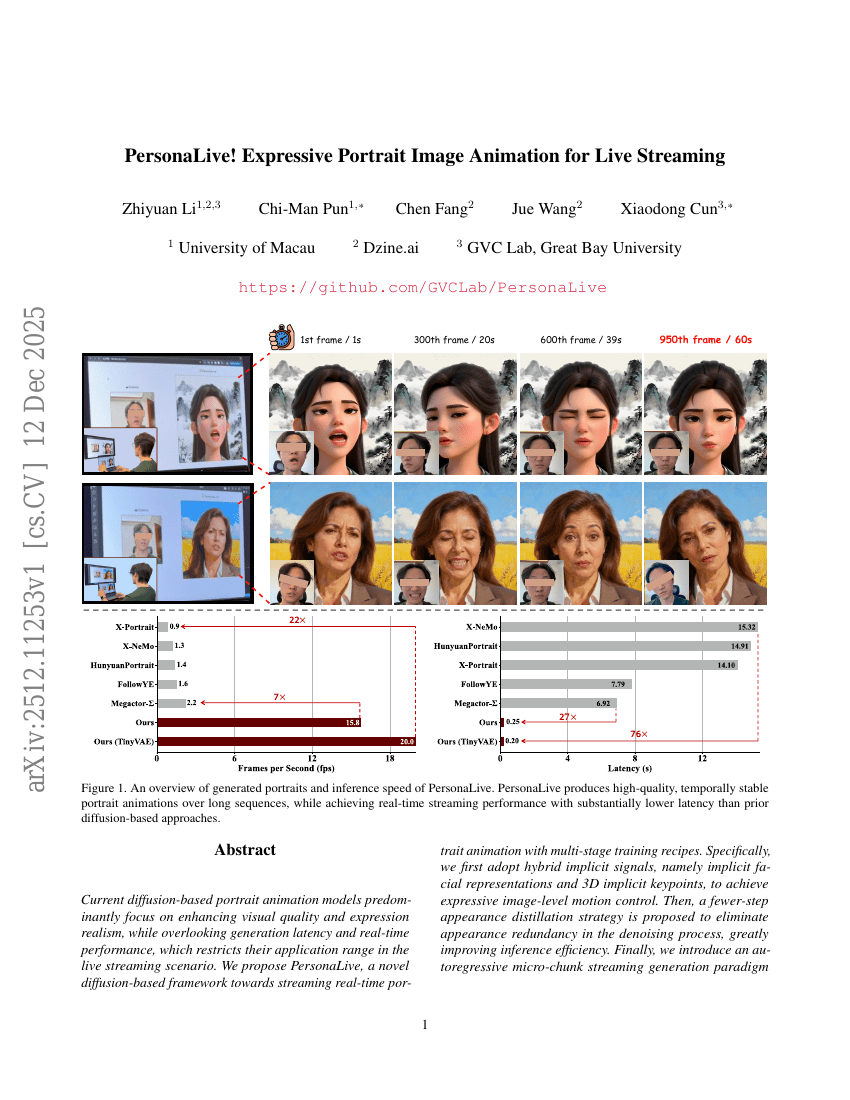
PersonaLive! Expressive Portrait Image Animation for Live Streaming
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
SSRB: Direct Natural Language Querying to Massive Heterogeneous Semi-Structured Data
MUVR: A Multi-Modal Untrimmed Video Retrieval Benchmark with Multi-Level Visual Correspondence
Evaluating Gemini Robotics Policies in a Veo World Simulator
MotionEdit: Benchmarking and Learning Motion-Centric Image Editing
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
OPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground
AutoGLM: Autonomous Foundation Agents for GUIs
OpenGU: A Comprehensive Benchmark for Graph Unlearning
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
DeepCode: Open Agentic Coding
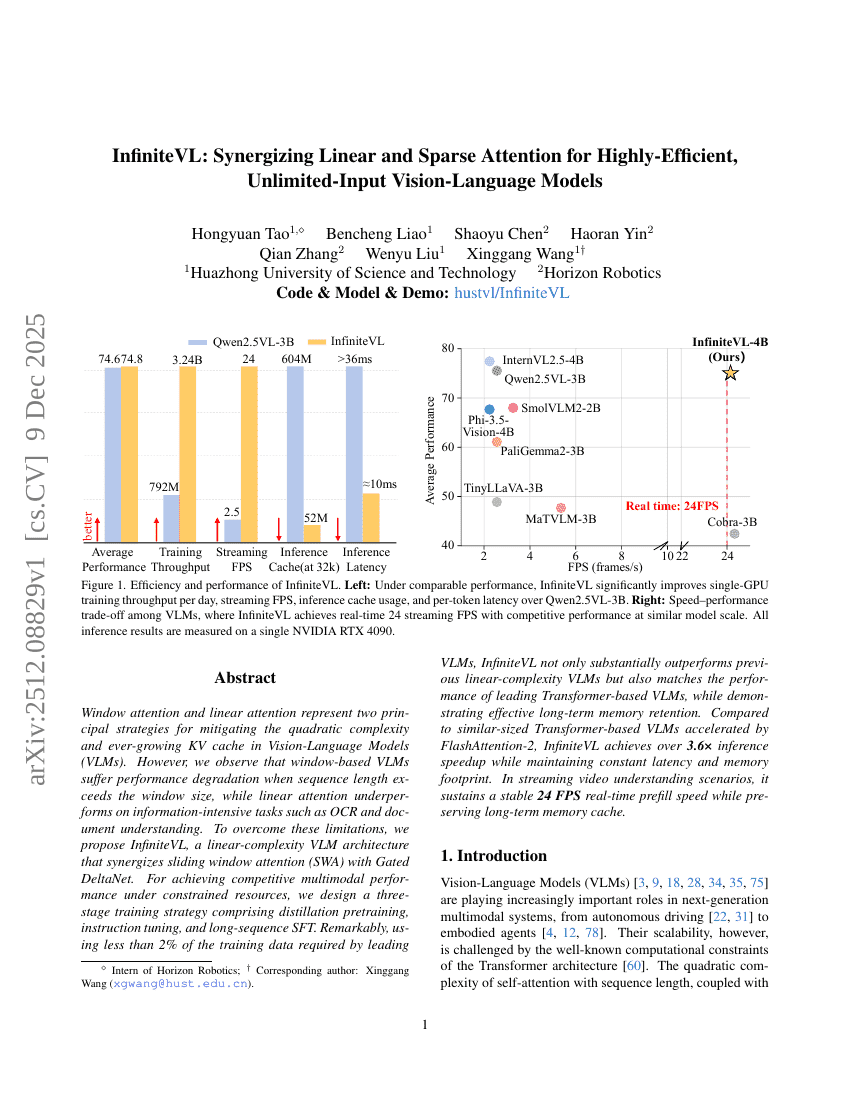
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
OmniPSD: Layered PSD Generation with Diffusion Transformer
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Arbitrage: Efficient Reasoning via Advantage-Aware Speculation
Composing Concepts from Images and Videos via Concept-prompt Binding
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
FirstAidQA: A Synthetic Dataset for First Aid and Emergency Response in Low-Connectivity Settings
CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
PersonaLive! Expressive Portrait Image Animation for Live Streaming
V-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
SSRB: Direct Natural Language Querying to Massive Heterogeneous Semi-Structured Data
MUVR: A Multi-Modal Untrimmed Video Retrieval Benchmark with Multi-Level Visual Correspondence
Evaluating Gemini Robotics Policies in a Veo World Simulator
MotionEdit: Benchmarking and Learning Motion-Centric Image Editing
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
OPV: Outcome-based Process Verifier for Efficient Long Chain-of-Thought Verification
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Long-horizon Reasoning Agent for Olympiad-Level Mathematical Problem Solving
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground
AutoGLM: Autonomous Foundation Agents for GUIs
OpenGU: A Comprehensive Benchmark for Graph Unlearning
On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
DeepCode: Open Agentic Coding
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
OmniPSD: Layered PSD Generation with Diffusion Transformer
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Arbitrage: Efficient Reasoning via Advantage-Aware Speculation
Composing Concepts from Images and Videos via Concept-prompt Binding
StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation