Command Palette
Search for a command to run...
MOOSE-Star: Unlocking Tractable Training for Scientific Discovery by Breaking the Complexity Barrier
MOOSE-Star: Unlocking Tractable Training for Scientific Discovery by Breaking the Complexity Barrier
Zonglin Yang Lidong Bing
Abstract
While large language models (LLMs) show promise in scientific discovery, existing research focuses on inference or feedback-driven training, leaving the direct modeling of the generative reasoning process, P(exthypothesis∣extbackground) (P(h∣b)), unexplored. We demonstrate that directly training P(h∣b) is mathematically intractable due to the combinatorial complexity (O(Nk)) inherent in retrieving and composing inspirations from a vast knowledge base. To break this barrier, we introduce MOOSE-Star, a unified framework enabling tractable training and scalable inference. In the best case, MOOSE-Star reduces complexity from exponential to logarithmic (O(logN)) by (1) training on decomposed subtasks derived from the probabilistic equation of discovery, (2) employing motivation-guided hierarchical search to enable logarithmic retrieval and prune irrelevant subspaces, and (3) utilizing bounded composition for robustness against retrieval noise. To facilitate this, we release TOMATO-Star, a dataset of 108,717 decomposed papers (38,400 GPU hours) for training. Furthermore, we show that while brute-force sampling hits a ''complexity wall,'' MOOSE-Star exhibits continuous test-time scaling.
One-sentence Summary
Researchers from the MOOSE-STAR project introduce MOOSE-STAR, a unified framework that enables tractable training for scientific discovery by reducing computational complexity from exponential to logarithmic through hierarchical search and bounded composition, facilitating continuous test-time scaling where brute-force methods fail.
Key Contributions
- Existing research on LLMs for scientific discovery overlooks the direct modeling of the generative reasoning process P(h∣b) because retrieving and composing inspirations from a vast knowledge base creates mathematically intractable combinatorial complexity.
- The proposed MOOSE-STAR framework overcomes this barrier by decomposing the objective into subtasks, employing motivation-guided hierarchical search, and utilizing bounded composition to reduce complexity from exponential to logarithmic.
- To support this approach, the authors release the TOMADO-STAR dataset containing over 108,000 decomposed papers and demonstrate that the method enables continuous test-time scaling where brute-force sampling fails.
Introduction
Large language models hold significant potential for scientific discovery, yet current research primarily relies on inference strategies or feedback-driven training rather than directly modeling the core generative reasoning process. Existing approaches struggle because they depend on external feedback to refine hypotheses instead of learning to generate high-quality ideas directly from research backgrounds, and a theoretical analysis reveals that directly training this probability is mathematically intractable due to exponential combinatorial complexity. To overcome this barrier, the authors introduce MOOSE-STAR, a unified framework that enables tractable training and scalable inference by decomposing tasks, employing motivation-guided hierarchical search to reduce complexity to logarithmic levels, and utilizing bounded composition for robustness.
Dataset
-
Dataset Composition and Sources: The authors construct TOMATO-Star, a large-scale dataset derived from 108,717 open-access scientific papers sourced from the NCBI database. The corpus spans biology, chemistry, and cognitive science, covering publications from January 2020 to October 2025.
-
Key Details for Each Subset:
- Training Set: Includes papers published between January 2020 and September 2025.
- Test Set: Consists of papers published in October 2025 to ensure a strict temporal split and prevent data contamination.
- Filtering Rules: Every sample undergoes four automated quality checks to verify information necessity, sufficiency, disjointness between background and inspirations, and non-redundancy of extracted inspirations.
-
Model Usage and Processing:
- Preprocessing: Raw PDF documents are converted to Markdown using MinerU.
- Decomposition: Locally deployed reasoning models (DeepSeek-R1 and R1-distilled-Qwen-32b) decompose each paper into a structured tuple of Research Background, Hypothesis, and Inspirations.
- Hypothesis Structure: Hypotheses are formatted as "Delta Hypotheses" where each inspiration maps to a specific delta containing Motivation, Mechanism, and Methodology levels.
- Inspirations: Ground-truth inspirations are identified from source citations and augmented with full titles and abstracts retrieved via Semantic Scholar.
-
Additional Processing Details: The pipeline enforces a strict one-to-one mapping between inspirations and hypothesis deltas. The authors ensure the background section remains strictly independent of the inspirations and hypothesis to maintain logical integrity during training.
Method
The authors address the computational intractability of directly modeling the marginal likelihood P(h∣b), which scales exponentially as O(Nk) due to the combinatorial search over the global knowledge base I. To resolve this, they introduce the MOOSE-STAR framework, which operationalizes a probabilistic decomposition theory. This approach transforms the monolithic generation task into a sequence of k manageable subtasks: Inspiration Retrieval and Hypothesis Composition. By decoupling the search from the composition, the complexity is reduced from exponential to linear O(k×N).
To further optimize the linear retrieval term O(N), the framework employs Bounded Composition. Instead of requiring the model to retrieve the exact ground-truth inspiration i∗ from the entire database, the authors introduce a semantic tolerance space. This allows the composition module to function robustly even when provided with a proxy inspiration i that is semantically similar to i∗.
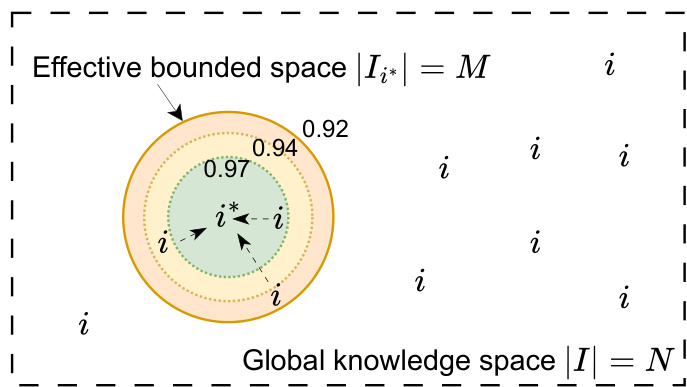
As illustrated in the figure above, the global knowledge space ∣I∣=N contains the exact inspiration i∗. The effective bounded space ∣Ii∗∣=M represents a semantic neighborhood centered on i∗, defined by concentric similarity thresholds. By training the model to compose hypotheses using inspirations within this bounded window, the retrieval complexity is effectively reduced to O(N/M), while the composition cost increases only linearly with M. Since N≫M, this trade-off yields a significant net reduction in total complexity.
Building on this, the authors implement Hierarchical Search to replace the linear scan of the knowledge base. They construct a semantic search tree via bottom-up clustering of paper embeddings. During inference, a Best-First Search strategy navigates this tree, pruning irrelevant branches and achieving logarithmic complexity O(logN) in the best-case scenario. Finally, Motivation Planning is introduced as a high-level generative root. By appending a motivation variable m to the research background, the search is guided towards specific semantic subspaces, further reducing the effective search space to Nm<N. The entire framework is trained using a teacher-based Rejection Sampling Fine-Tuning pipeline on the TOMADO-STAR dataset, which contains over 100,000 processed scientific papers.
Experiment
- Decomposed Sequential Training validates that fine-tuning specialized models for inspiration retrieval and hypothesis composition significantly outperforms baselines, with exposure to bounded training data further enhancing reasoning robustness against noisy inputs.
- Bounded Composition experiments confirm that incorporating data generated from noisy inspirations improves hypothesis quality across all levels of semantic similarity to ground truth.
- Hierarchical Search demonstrates superior efficiency over exhaustive baselines by reducing inference calls by approximately three times while maintaining high retrieval accuracy through effective pruning of irrelevant branches.
- Motivation Planning analysis shows that detailed, strategic directives derived from delta hypotheses significantly improve search efficiency compared to simple requirement translations.
- Scaling studies reveal that decomposing the task into retrieval and composition sub-problems overcomes the training deadlock inherent in end-to-end brute-force sampling, enabling high success rates even for complex multi-step discoveries.
- Data scaling experiments indicate that while retrieval models improve log-linearly, hypothesis composition requires a minimum data threshold to achieve significant gains, yet both tasks support scalable training paradigms.
- Test-time scaling results highlight that the guided, structured approach of the proposed method achieves near-perfect coverage as compute increases, whereas unguided brute-force sampling fails catastrophically as problem complexity rises due to combinatorial explosion.