Command Palette
Search for a command to run...
Generating 18,000 Years of Climate Data, NVIDIA and Others Proposed long-distance Distillation, Enabling long-term Weather Forecasting With Only a single-step calculation.

The accuracy and lead time of weather forecasts directly impact disaster prevention, agricultural production, and global resource allocation. From short-term warnings to seasonal and even longer-term climate predictions, the technological challenges increase exponentially with each step forward. After years of development in traditional numerical weather prediction, AI has brought new momentum to this field. In recent years, AI weather forecasting models have achieved breakthroughs in medium-range forecasts, with performance comparable to or even surpassing advanced traditional dynamical models.
Most mainstream AI weather models currently employ an autoregressive architecture, which works by iteratively extrapolating and learning from historical data on short-term atmospheric variations to predict conditions for the next few hours. This type of model performs well in medium-range forecasts.However, when expanding to long-term scales such as sub-seasonal to seasonal (S2S), it encountered a fundamental bottleneck.
Long-term forecasts rely on probabilistic methods, while autoregressive models can only make predictions through repeated iterations, leading to the continuous accumulation of errors and making calibration difficult. The core contradiction lies in:The training objective is to learn short-term patterns, while long-term forecasting requires building probabilistic models that can characterize the slow rate of climate variability.
To overcome this limitation, researchers began exploring new paths for single-step prediction. However, new problems arose: when training long-term single-step models based on existing reanalysis data, severe overfitting can occur due to the scarcity of data samples, and the reliability of the model cannot be guaranteed.
In this context,A research team from NVIDIA Research, in collaboration with the University of Washington, has developed a new method for long-range distillation.The core idea is to use an autoregressive model, which excels at generating realistic atmospheric variability, as a "teacher" to generate massive amounts of synthetic meteorological data through low-cost and rapid simulation; then, this data is used to train a probabilistic "student" model. The student model only needs to perform a single-step calculation to generate long-term forecasts, avoiding the accumulation of iteration errors and bypassing the complex problem of data calibration.
This approach departs from the autoregressive modeling framework, instead compressing large-scale climate data into a conditional generative model, overcoming the limitations of limited training data in previous studies. The research employed an autoregressive coupled model capable of stably simulating a century of climate as the teacher, generating training samples far exceeding the scale of real-world records. Preliminary experiments show that the student model trained based on this model performs comparably to the ECMWF integrated forecasting system in S2S prediction, and its performance continuously improves with increasing synthetic data volume, promising to achieve more reliable and economical climate-scale predictions in the future.
The related research findings, titled "Long-Range Distillation: Distilling 10,000 Years of Simulated Climate into Long Timestep AI Weather Models," have been published on arXiv.
Research highlights:
* Breaking through the time limit of real observation data, using AI meteorological models to generate synthetic climate data of more than 10,000 years, enabling the model to learn slowly varying climate modes that have not been fully presented in actual observations;
* We propose a long-distance distillation method that can output a long-term probability forecast model with only a single-step calculation, overcoming the error accumulation and instability problems caused by hundreds of iterations in the traditional autoregressive framework;
* After being adapted to real-world data, the model's skill in sub-seasonal to seasonal forecasts has reached a level comparable to that of the European Centre for Medium-Range Weather Forecasts' operational system.
Paper address:https://arxiv.org/abs/2512.22814 Follow our official WeChat account and reply "long-distance distillation" in the background to get the full PDF.
More AI frontier papers: https://hyper.ai/papers
Datasets: A Framework for the Generation, Classification, and Evaluation of Synthetic Climate Data
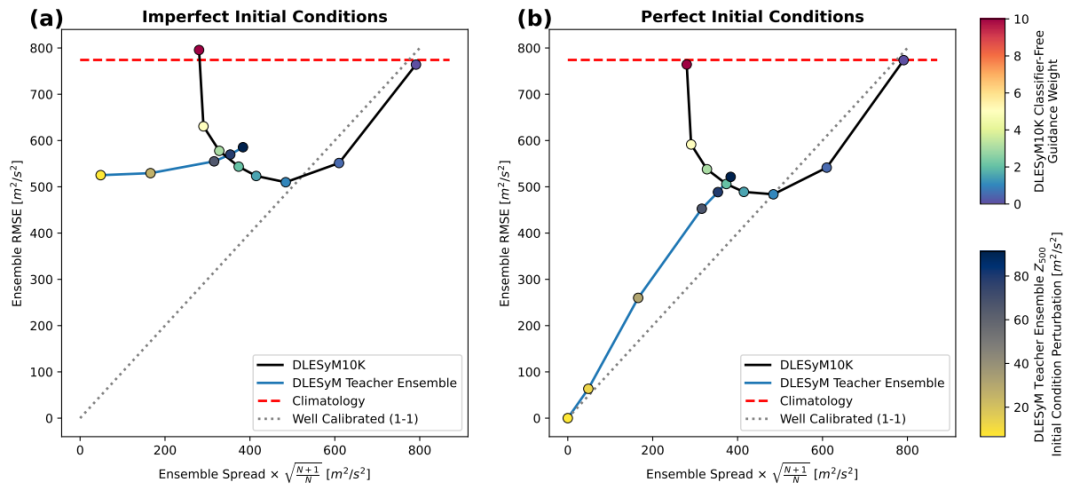
In evaluating the cross-time-dependent integrated forecasting capability of the long-distance distillation model, this study first validated it in controlled ideal model experiments.All evaluation data were taken from the simulation data reserved by the autoregressive teacher model DLESyM (Deep Learning Earth System Model).Furthermore, this setting was never used during the training of the distillation model. The core purpose of this setup was to examine the performance of the long-step distillation model and the DLESyM teacher model in forecasting unseen simulated weather conditions when the initial conditions were not fully determined, thus ensuring the objectivity of the evaluation.
The evaluation not only employed deterministic metrics such as the ensemble root mean square error (RMSE), but also introduced the Continuous Ranking Probability Score (CRPS), a probabilistic forecast evaluation tool, to more comprehensively measure forecast performance. Researchers selected three forecast leads with different predictability mechanisms for testing:
* Mid-term timeframe:
For the 7-day daily average forecast (parameters N=28, M=4), reserved data from January 1, 2017 to March 10, 2019 (simulated year) were used, with an initial date selected every 2 days, resulting in more than 400 samples.
* S2S timeframe:
For the 4-week weekly average forecast (parameters N=112, M=28), data from January 1, 2017 to May 16, 2021 (simulated year) were used, with an initial date every 4 days, and the sample size also exceeded 400.
* Seasonal validity:
For the 12-week monthly average forecast (parameters N=336, M=112), data from January 1, 2017 to September 28, 2025 (simulated year) were used, with an initial date selected every 8 days, resulting in a sample size of approximately 400.
To ensure independence, researchers divided approximately 15,000 years of synthetic climate simulation data generated by DLESYM into a training set (751 TP3T, approximately 11,000 years) and a validation set (251 TP3T) based on ensemble membership, and trained independent distillation models for each forecast lead time. The generation of these synthetic data employed a parallel strategy: 200 initial dates were evenly selected between January 1, 2008, and December 31, 2016, with each date corresponding to a 90-year simulation.This yielded climate data spanning a total of 18,000 years.
The ultimate goal of this research is to apply the trained model to long-term real-world forecasts. It is important to note that the "model climate" generated by long-term operation of DLESyM differs from real-world climate. Therefore, when transferring the model to real-world applications, this "domain transfer" problem needs to be addressed as a key focus.
Long-distance distillation: A dual innovation of "data distillation" and "probabilistic calibration"
The innovative idea behind long-distance distillation methods lies in...It uses a short-step autoregressive model that can run stably for a long time as a "teacher" to train a "student" model that can output long-term forecasts with only a single step of calculation.This fundamentally avoids the error accumulation problem caused by hundreds of iterations in the traditional autoregressive framework.
Specifically, researchers define a long-term forecast target—the average state over a future time window—from the long-term rolling sequence of the teacher model. The student model then directly learns the conditional probability distribution from the initial state to this long-term target. The core value of the teacher model lies in its ability to efficiently generate massive amounts of synthetic data, far exceeding the scale of the original reanalysis data, thus solving the problem of scarce training samples for long-term forecasts.
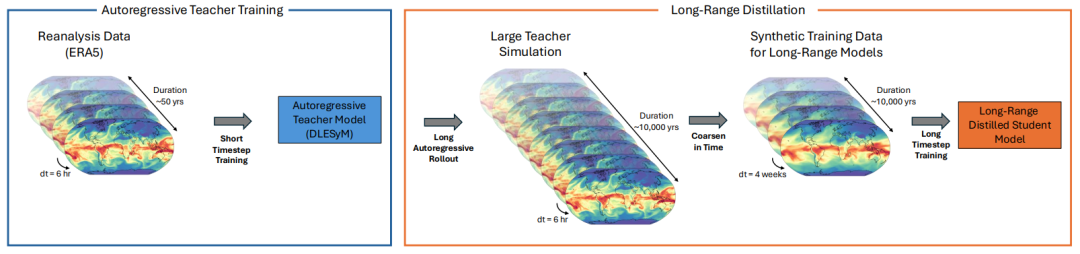
To achieve this goal,This study uses the DLESYM model as the "teacher".The model is initialized based on ERA5 reanalysis data and forecasts key variables such as sea surface temperature, air temperature, and geopotential height. Researchers designed an efficient data generation strategy: 200 initial dates were evenly selected between 2008 and 2016, and simulations were conducted in parallel over a 90-year period, resulting in a total of 18,000 years of synthetic climate data. With powerful computing capabilities, the data generation process took only a few hours, fully demonstrating the efficiency advantages of AI climate simulation. After quality screening, approximately 15,000 years of valid data were used for subsequent model training and validation.
The "Student" model employs a conditional diffusion model architecture and is specifically designed for probabilistic forecasting.The goal is to model the complex relationship between future long-term weather conditions and input conditions (such as the daily average conditions of the previous four days). The model architecture is based on an improved UNet network adapted to the HEALPix grid, which effectively captures the spatiotemporal dependencies of the global weather field by introducing learnable spatial embeddings and periodic temporal embeddings. During training, researchers employed a specific noise scheduling strategy to ensure that the model learns features at all scales in the data.
To accurately calibrate the uncertainty of probabilistic predictions, this study innovatively introduces "classifier-free guidance."It allows for flexible control of the dispersion of the forecast ensemble by adjusting a simple weight parameter during the model inference phase.This allows for an optimal balance between forecasting error and accurate prediction, thus facilitating the generation of well-calibrated probability forecasts.
To enable the model to perform real-world forecasting tasks, this study implemented a dual strategy to address the "domain shift" problem. First, climate bias corrections were applied to rectify systematic differences between simulated data and real observations at the mean state. Second, the model was fine-tuned using limited ERA5 reanalysis data, updating only some key parameters in the network. This allowed the model to retain the patterns learned from massive synthetic data while better adapting to the characteristics of the real atmosphere. Finally, the model's competitiveness in real-world scenarios was evaluated through comparison with leading operational systems such as the European Centre for Medium-Range Weather Forecasts (ECMWF).
Breakthroughs in multiple dimensions: scalable data, calibrable forecasts, and skills comparable to top-tier business systems.
Through a series of experiments, this study systematically verified the performance and potential of the long-distance distillation model in four areas: the impact of training data scale, calibration of forecast uncertainty, multi-time forecasting skills, and benchmarking with operational systems.
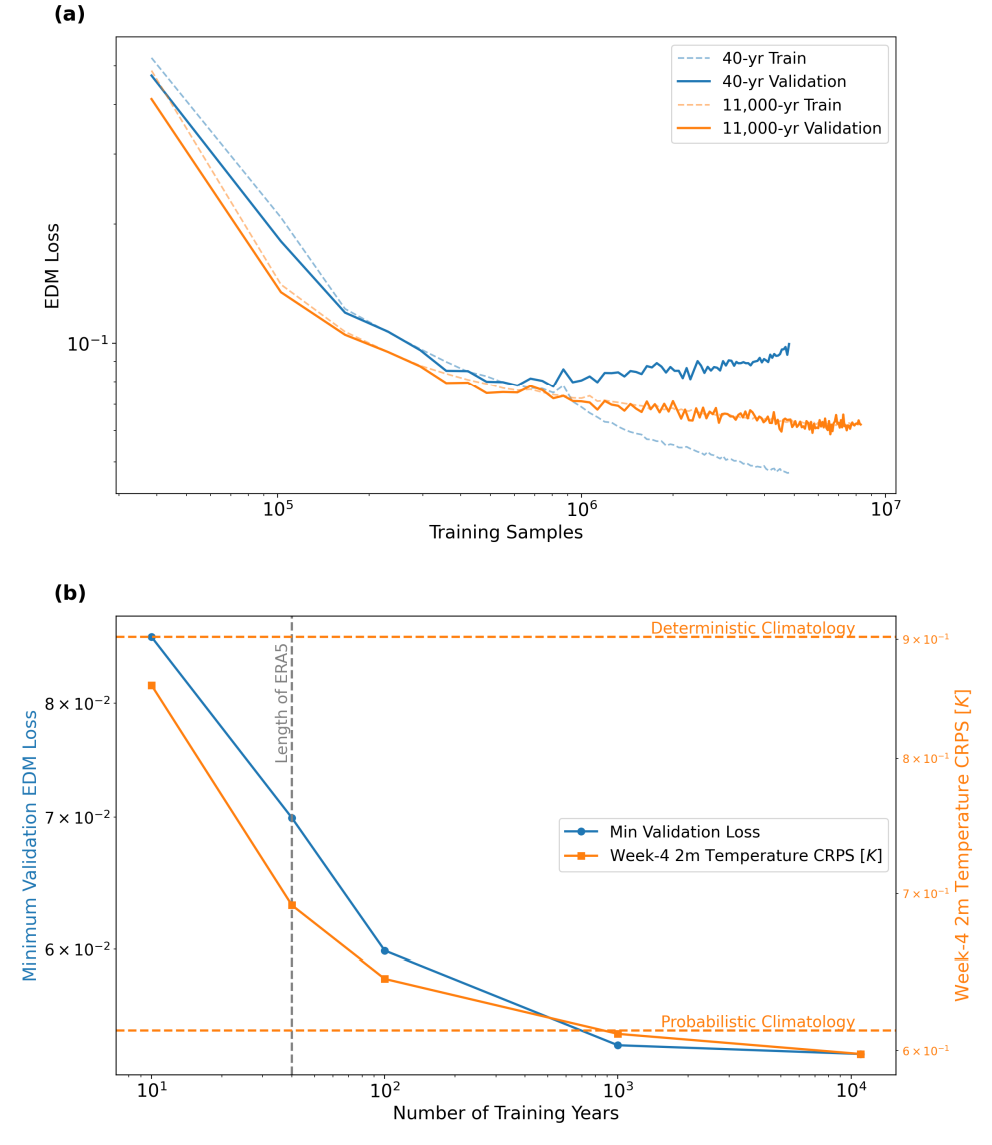
First, this study validated the core hypothesis—increasing the amount of synthetic training data can significantly improve the model's predictive ability. As shown in the figure below, the model trained using only 40 years of simulated data quickly overfitted, while the model trained on approximately 11,000 years of synthetic data (DLESyM10K) exhibited a stable learning curve. More importantly,The increase in data volume directly translates into an improvement in forecasting skills:In the 4-week temperature forecast, the CRPS score decreased by 14%. This demonstrates for the first time that using autoregressive models to generate large-scale synthetic data can effectively construct more robust long-term forecast models.
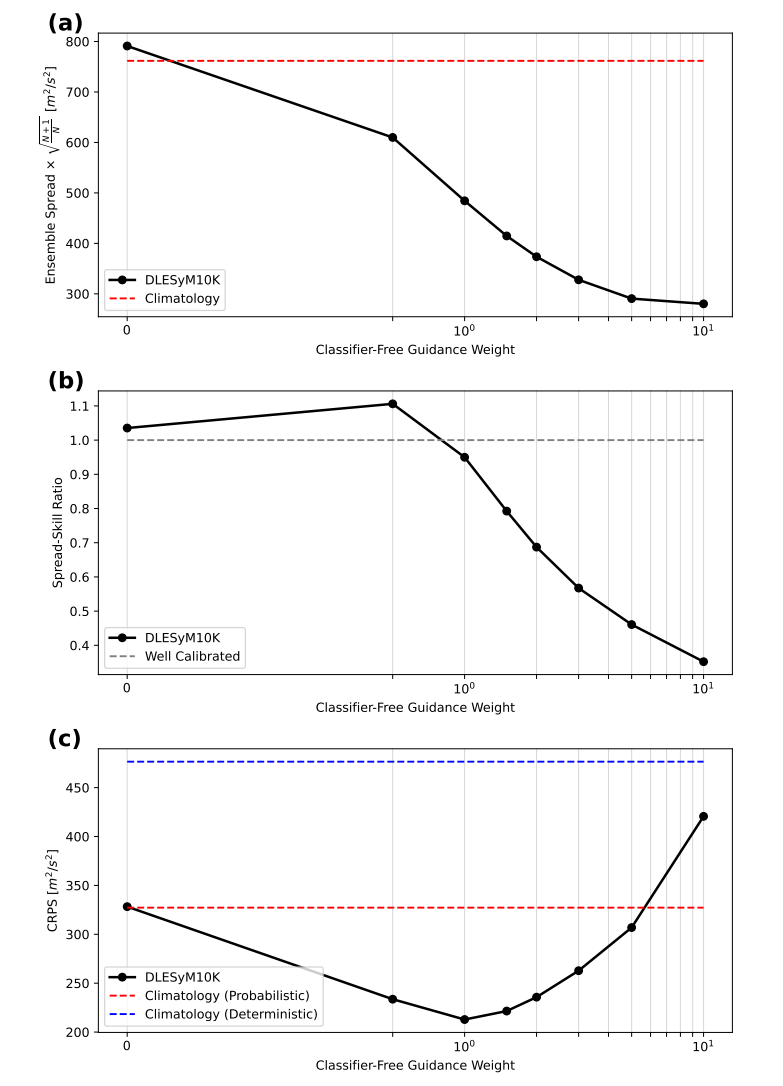
This study employs a "classifier-free guidance" technique to calibrate the dispersion of probabilistic forecasts. By adjusting the guidance strength, the dispersion of the forecast ensemble can be controlled, achieving an optimal balance with forecast errors. Experiments show that...When the guidance strength is set to 1, the model can automatically achieve good calibration;If adjustments are needed, the parameter can be simply adjusted during the inference phase. This provides an efficient and flexible calibration method for probabilistic forecasting.
The model demonstrates robust performance in medium-term, sub-seasonal to seasonal (S2S), and seasonal forecasts.In medium-range forecasts, the model demonstrates strong robustness to initial errors, and its probabilistic modeling characteristics help mitigate uncertainties in initial conditions. In more challenging S2S and seasonal forecasts, DLESyM10K significantly outperforms climatological benchmarks, particularly in highly predictable regions such as the tropics and oceans. Notably,It achieves a skill level comparable to that of an autoregressive teacher model with hundreds of iterations through a single-step computation.This demonstrates the efficiency of the framework.
When transferring the model to real-world forecasts, fine-tuning and bias correction addressed the discrepancy between "model climate" and actual climate. A comparison with the European Centre for Medium-Range Weather Forecasts (ECMWF) operational system shows:After fine-tuning, DLESyM10K's 4-week temperature forecast skill is very close to that of the ECMWF system, and both are significantly better than the climatological benchmark.Regional analysis reveals that each model has its strengths in different geographical regions; for example, DLESyM10K performs better in parts of the Americas and Central Africa. This demonstrates the AI model's potential to compete with advanced business systems, while highlighting its differentiated value.
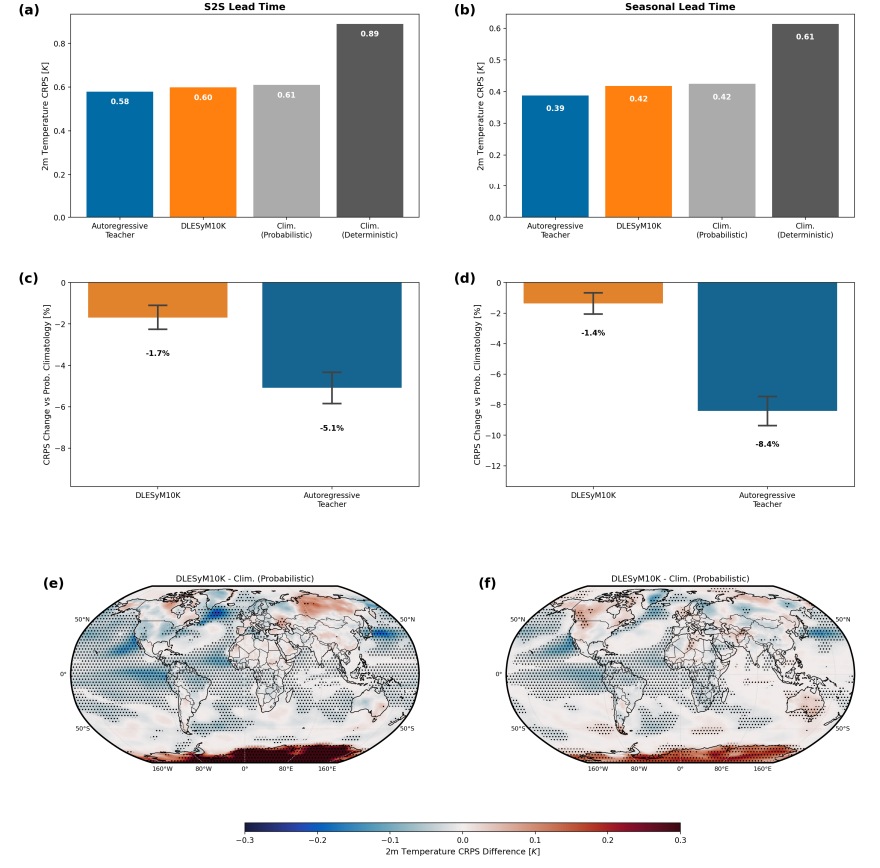
In summary, the long-range distillation method, through a combination of data scaling and single-step probabilistic modeling, trains a conditional diffusion model capable of single-step output of long-term probabilistic forecasts, and achieves flexible uncertainty calibration by incorporating classifier-free guidance techniques. Experiments show that...This method has achieved performance comparable to the European Centre for Medium-Range Weather Forecasts (ECMWF) operational system in sub-seasonal to seasonal forecasts.This paradigm not only provides a new approach to long-term weather forecasting, but also lays the foundation for building a general generative model that serves climate science exploration.
Global industry-academia-research collaboration accelerates meteorological technology transformation
Using AI to generate synthetic data to address data bottlenecks in long-term forecasting is becoming an important direction for academics and industry to jointly promote innovation in weather forecasting. A series of cutting-edge research and engineering practices have emerged, continuously driving long-term weather forecasting from theoretical exploration to operational application.
In academia, interdisciplinary collaboration is becoming key to overcoming core technological challenges. For example,The University of Chicago's "AI Climate Initiative (AICE)"This organization, bringing together experts from climate science, computer science, and statistics, is dedicated to significantly reducing the computational costs of climate forecasting. Their technology has enabled the generation of high-level forecasts using ordinary laptops, and is expected to help narrow the gap in weather forecasting capabilities between different regions.
The University of Cambridge, in collaboration with the Turing Institute, the European Centre for Medium-Range Weather Forecasts, and other institutions, has jointly developed Aardvark Weather, an end-to-end data-driven forecasting system.This system can integrate multiple observational data and simultaneously output global grid forecasts and local station forecasts, demonstrating performance comparable to optimized operational numerical models in 10-day forecast lead times. Its end-to-end modeling approach aligns closely with the original intention of simplifying the forecasting process through long-distance distillation, providing a technical model for improving the accuracy of long-term forecasts.
* Click to view Aardvark Weather In-depth analysis:Nature, Cambridge University and others released the first end-to-end data-driven weather forecasting system, which increases the prediction speed by dozens of times
* Paper Title: End-to-end data-driven weather prediction
* Paper address:
https://www.nature.com/articles/s41586-025-08897-0
In industry, innovative practices focus more on the engineering implementation and scenario-based application of technologies. Technology companies are continuously expanding the technological boundaries of AI meteorology through deep involvement in industry-academia-research collaborations and independent research and development. For example,Microsoft, Google DeepMind, and other organizations were deeply involved in the development of the Aardvark Weather system.Google DeepMind's strengths in large-scale data processing and deep learning architecture can be translated into improvements in the efficiency and accuracy of meteorological models. Furthermore, Google DeepMind's expertise in generative models and probabilistic forecast calibration provides important insights for solving problems such as ensemble dispersion control in long-distance distillation.
At the same time, businesses are actively promoting the application of AI meteorological technology in specific scenarios. For example, by collaborating with park management and emergency departments, they are integrating precise long-term forecasting technology into smart disaster prevention systems. Through full-process simulation of disaster evolution, they are providing customized forecasting services for scenarios such as park safety, water conservancy scheduling, and agricultural production, ensuring that the value of long-term weather forecasts truly benefits end users.
These explorations from academia and industry have not only verified the feasibility of technical approaches represented by data distillation and single-step modeling, but have also gradually formed a virtuous cycle of "academic breakthroughs leading the direction and engineering innovation driving implementation," jointly promoting the continuous development of global AI weather forecasting towards a more accurate, efficient, and inclusive direction.
Reference Links:
1.https://climate.uchicago.edu/entities/aice-ai-for-climate/








