Command Palette
Search for a command to run...
A Compilation of Resources on Embodied Intelligence: Robot Learning Datasets, Online Experience of World Modeling Models, and the Latest Research Papers From NVIDIA, ByteDance, Xiaomi, and others.

If the main battleground for artificial intelligence over the past decade has been "understanding the world" and "generating content," then the core issue of the next stage is shifting to a more challenging proposition:How can AI truly enter the physical world and act, learn, and evolve within it?The term "embodied intelligence" has appeared frequently in related research and discussions.
As the name suggests, embodied intelligence is not a traditional robot.Instead, it emphasizes that intelligence is formed through the interaction between the agent and the environment in a closed loop of perception, decision-making, and action.From this perspective, intelligence no longer exists solely in model parameters or reasoning capabilities, but is deeply embedded in sensors, actuators, environmental feedback, and long-term learning. Discussions of robotics, autonomous driving, agents, and even artificial general intelligence (AGI) are all incorporated into this framework.
This is why embodied intelligence has become a focus of attention for global tech giants and top research institutions in the past two years. Tesla CEO Elon Musk has repeatedly emphasized that the humanoid robot Optimus is no less significant than autonomous driving; Nvidia founder Jensen Huang regards Physical AI as the next wave after generative AI and continues to invest heavily in robot simulation and training platforms; Fei-Fei Li, Yann LeCun, and others continue to produce high-quality cutting-edge analysis and results in sub-fields such as spatial intelligence and world models; OpenAI, Google DeepMind, and Meta are also exploring the learning capabilities of intelligent agents in real or near-real environments based on technologies such as multimodal models and reinforcement learning.
Against this backdrop, embodied intelligence is no longer just a problem of single models or algorithms, but has gradually evolved into a research ecosystem comprised of datasets, simulation environments, benchmark tasks, and systematic methods. To help more readers quickly understand the key threads of this field,This article will systematically organize and recommend a batch of high-quality datasets, online tutorials, and papers related to embodied intelligence, providing a reference for further learning and research.
Dataset Recommendation
1. BC-Z Robot Learning Dataset
Estimated size:32.28 GB
Download address:https://go.hyper.ai/vkRel

This is a large-scale robotics learning dataset developed jointly by Google, Everyday Robots, UC Berkeley, and Stanford University. It contains over 25,877 different operational task scenarios, covering 100 diverse operational tasks. These tasks were collected through expert-level remote operation and shared autonomous processes, involving 12 robots and 7 different operators, accumulating 125 hours of robot operation time. The dataset supports training a 7-DOF multi-task policy that can be adjusted based on the task's verbal description or human operation videos to perform specific operational tasks.
2.DexGraspVLA Robot Grasping Dataset
Estimated size:7.29 GB
Download address:https://go.hyper.ai/G37zQ

This dataset, created by the Psi-Robot team, contains 51 human demonstration data samples to understand the data and format, and to run the code and experience the training process. Its research stems from the need for high success rates in agile grasping in cluttered scenes, particularly achieving a success rate exceeding 901 TP3T under combinations of unseen objects, lighting, and backgrounds. This framework employs a pre-trained visual-language model as a high-level task planner and learns a diffusion-based policy as a low-level action controller. Its innovation lies in leveraging the base model to achieve powerful generalization capabilities and using diffusion-based imitation learning to acquire agile actions.
3.EgoThink: A first-person visual question answering benchmark dataset
Estimated size:865.29 MB
Download address:https://go.hyper.ai/5PsDP

This dataset, proposed by Tsinghua University, is a first-person perspective visual question answering benchmark dataset containing 700 images covering 6 core capabilities, subdivided into 12 dimensions. The images are sampled from the Ego4D first-person video dataset; to ensure data diversity, a maximum of two images were sampled from each video. During dataset construction, only high-quality images that clearly demonstrate first-person perspective thinking were selected. EgoThink has wide applications, particularly in evaluating and improving the performance of Visual Learning Models (VLMs) in first-person perspective tasks, providing valuable resources for future embodied artificial intelligence and robotics research.
4.EQA Question Answering Dataset
Estimated size:839.6 KB
Download address:https://go.hyper.ai/8Uv1o
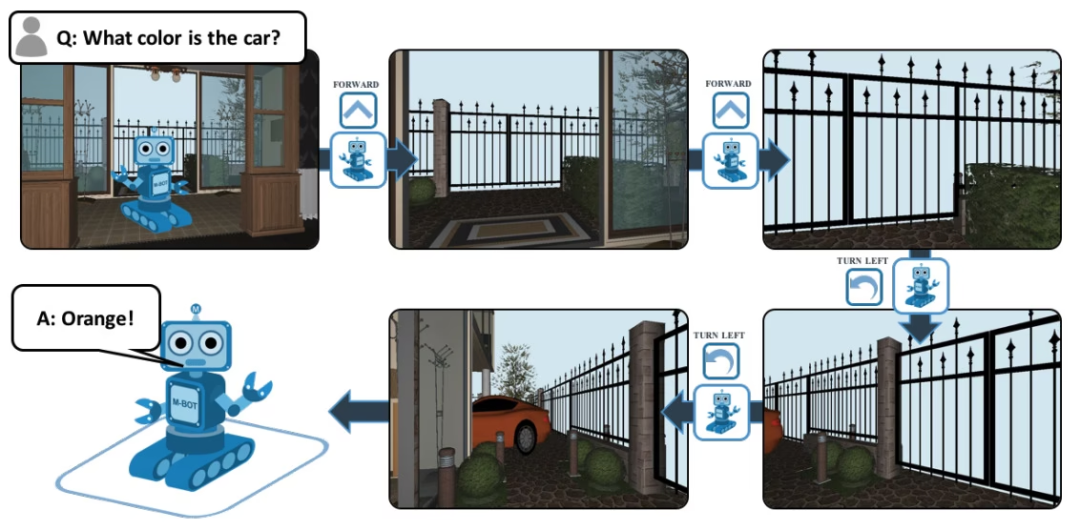
EQA stands for Embodied Question Answering, and is a visual question answering dataset based on House3D. After receiving a question, an agent at any position in the environment can find useful information in the environment and answer the question. For example: Q: What color is the car? In order to answer this question, the agent must first explore the environment through intelligent navigation, collect necessary visual information from a first-person perspective, and then answer the question: orange.
5. OmniRetarget Global Robot
Motion remapping dataset
Estimated size:349.61 MB
Download address:https://go.hyper.ai/IloBI

This is a high-quality trajectory dataset for full-body motion remapping of humanoid robots, released by Amazon in collaboration with MIT, UC Berkeley, and other institutions. It contains the motion trajectories of the G1 humanoid robot interacting with objects and complex terrain, covering three scenarios: robot carrying objects, terrain walking, and hybrid object-terrain interaction. Due to licensing restrictions, the publicly available dataset does not include a remapped version of LAFAN1. It is divided into three subsets, totaling approximately 4 hours of motion trajectory data, as follows:
* robot-object: The trajectory of the object carried by the robot, derived from OMOMO 3.0 data;
* robot-terrain: The robot's movement trajectory on complex terrain, generated by internal MoCap data collection, lasting approximately 0.5 hours;
* robot-object-terrain: This involves the motion trajectory of an object interacting with the terrain, and lasts approximately 0.5 hours.
In addition, the dataset also contains a models directory, which provides visual model files in URDF, SDF, and OBJ formats for display rather than training.
View more high-quality datasets:https://hyper.ai/datasets
Tutorial Recommendations
Research in embodied AI often involves combinations of multiple models and modules to achieve perception, understanding, planning, and action in the physical world. These include world models and reasoning models. This article primarily recommends the following two latest open-source models.
View more high-quality tutorials:https://hyper.ai/notebooks
1.HY-World 1.5: Framework for an Interactive World Modeling System
HY-World 1.5 (WorldPlay) is the first open-source real-time interactive world model with long-term geometric consistency released by Tencent's Hunyuan team. This model achieves real-time interactive world modeling through streaming video diffusion technology, resolving the trade-off between speed and memory in current methods.
Run online:https://go.hyper.ai/qsJVe
2.vLLM+Open WebUI Deployment Nemotron-3 Nano
The Nemotron-3-Nano-30B-A3B-BF16 is a large-scale language model (LLM) trained from scratch by NVIDIA. It is designed as a unified model applicable to both reasoning and non-reasoning tasks, and is mainly used to build AI agent systems, chatbots, RAG (retrieval augmented generation) systems, and other various AI applications.
Run online:https://go.hyper.ai/6SK6n
Paper Recommendation
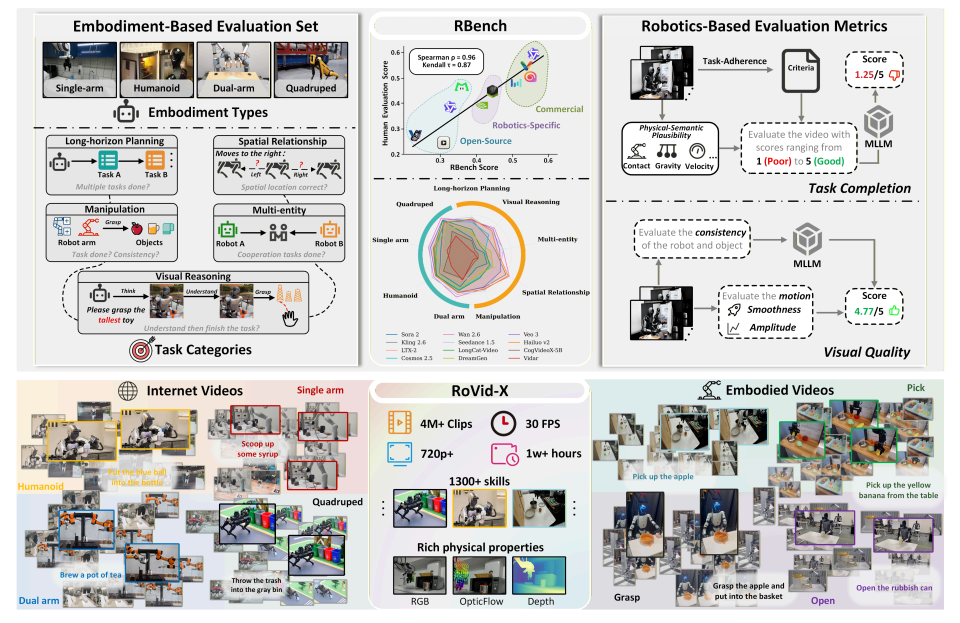
- RBench
Thesis Title:Rethinking Video Generation Model for the Embodied World
Research Team:Peking University, ByteDance Seed
View the paper:https://go.hyper.ai/k1oMT
Research Summary:
The team proposed a comprehensive benchmark for robot video generation, RBench, covering five task domains and four different robot forms. It evaluates robot video generation from two dimensions: task-level correctness and visual fidelity, using a series of reproducible sub-indicators, specifically including structural consistency, physical plausibility, and motion completeness. Evaluation results on 25 representative video generation models show that current methods still have significant shortcomings in generating physically realistic robot behaviors. Furthermore, the Spearman correlation coefficient between RBench and human evaluation reaches 0.96, validating the benchmark's effectiveness in measuring model quality.
In addition, the study also built RoVid-X—the largest open-source robot video generation dataset to date, containing 4 million annotated video clips covering thousands of tasks, supplemented by comprehensive physical attribute annotations.
2. Being-H0.5
Paper title:Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
Research Team:BeingBeyond
View the paper:https://go.hyper.ai/pW24B
Research Summary:
The team proposed a foundational Vision-Language-Action (VLA) model, Being-H0.5, designed to achieve strong generalization and embodiment capabilities across multiple robotic platforms. Existing VLA models are often limited by issues such as significant differences in robot morphology and scarcity of available data. To address this challenge, they proposed a human-centered learning paradigm that treats human interaction trajectories as a universal "mother language" in the field of physical interaction.
Simultaneously, the team also released UniHand-2.0, one of the largest embodied pre-training solutions to date, encompassing over 35,000 hours of multimodal data across 30 different robot forms. At the methodological level, they proposed a Unified Action Space, mapping heterogeneous control methods of different robots to semantically aligned action slots, enabling low-resource robots to rapidly transfer and learn skills from human data and high-resource platforms.

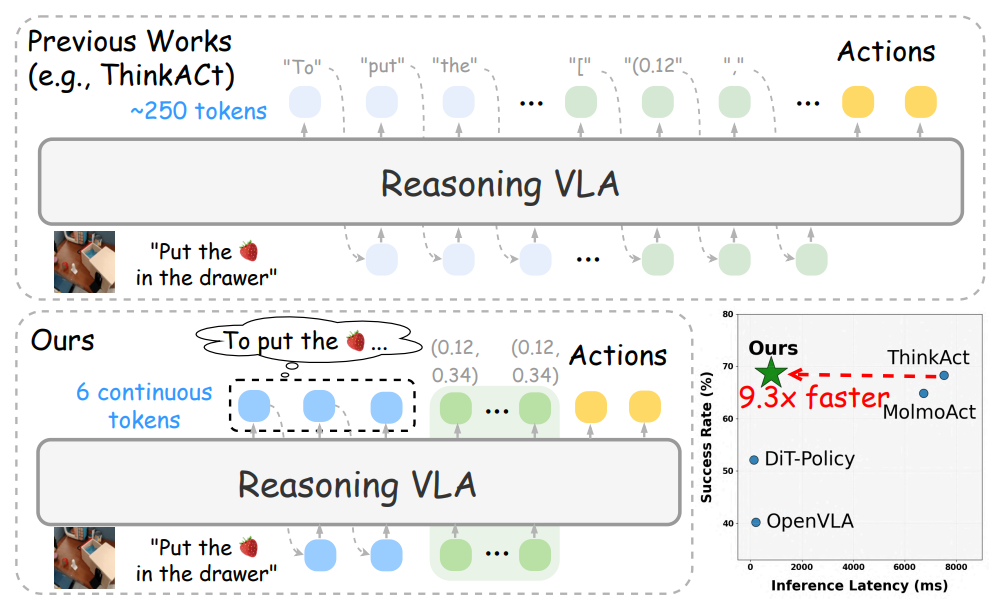
3. Fast-ThinkAct
Paper title:Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Research Team:Nvidia
View the paper:https://go.hyper.ai/q1h7j
Research Summary:
The team proposed an efficient reasoning framework, Fast-ThinkAct, which achieves a more compact planning process while maintaining performance through a linguistic latent reasoning mechanism. Fast-ThinkAct learns efficient reasoning capabilities by distilling latent CoTs from teacher models and aligns operation trajectories under the guidance of a preference-guided objective function, thereby transferring both linguistic and visual planning capabilities to embodied control.
Extensive experimental results covering various embodied operations and inference tasks demonstrate that Fast-ThinkAct, while maintaining long-term planning capabilities, few-sample adaptability, and failure recovery capabilities, achieves a significant performance improvement by reducing inference latency by up to 89.31 TP3T compared to the current state-of-the-art inference-based VLA models.
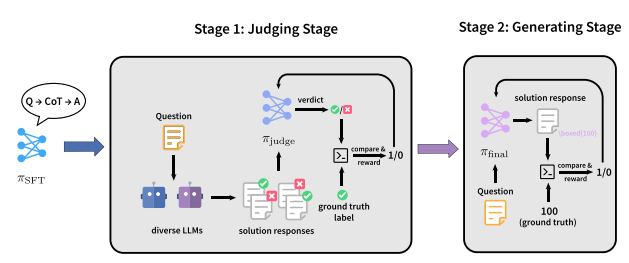
4. JudgeRLVR
Paper title:JudgeRLVR: Judge First, Generate Second for Efficient Reasoning
Research Team:Peking University, Xiaomi
View the paper:https://go.hyper.ai/2yCxp
Research Summary:
The team proposed a two-stage training paradigm, JudgeRLVR, which involves "discriminating first and then generating." In the first stage, the team trains a model to discriminate and evaluate problem-solving responses with verifiable answers. In the second stage, the same model is fine-tuned using standard generative RLVR, with the discriminative model as the initialization.
Compared to Vanilla RLVR, which is used on training data in the same mathematical domain, JudgeRLVR achieves a better quality-efficiency tradeoff on Qwen3-30B-A3B: on in-domain mathematical tasks, the average accuracy is improved by approximately 3.7 percentage points while the average generation length is reduced by 42%; on out-of-domain benchmarks, the average accuracy is improved by approximately 4.5 percentage points, demonstrating stronger generalization ability.
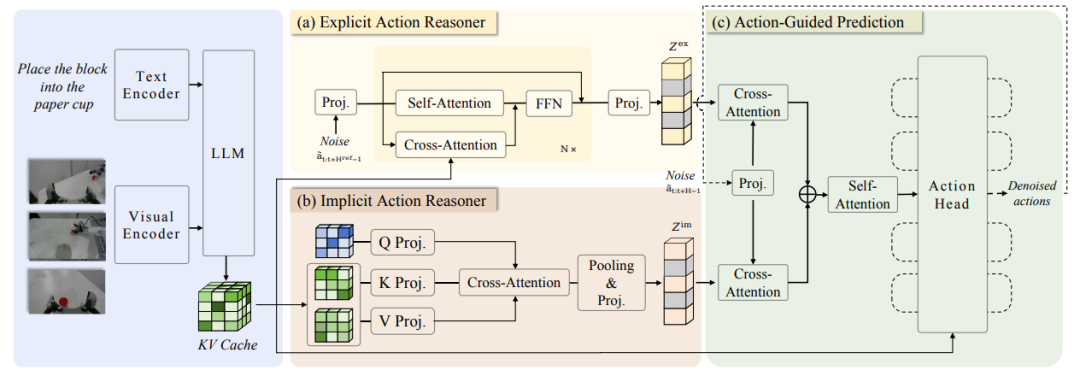
5. ACoT-VLA
Paper title:ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
Research Team:Beijing University of Aeronautics and Astronautics, AgiBot
View the paper:https://go.hyper.ai/2jMmY
Research Summary:
The team first proposed Action Chain-of-Thought (ACoT), which models the reasoning process itself as a series of structured, coarse-grained action intentions to guide the final policy generation. They then further proposed ACoT-VLA, a novel model architecture that concretizes the ACoT paradigm.
In its specific design, it introduces two complementary core components: the Explicit Action Reasoner (EAR) and the Implicit Action Reasoner (IAR). The EAR proposes a coarse-grained reference trajectory in the form of explicit action-level reasoning steps, while the IAR extracts latent action priors from the internal representations of multimodal inputs. Together, they constitute the ACoT and act as conditional inputs to the downstream action head, thereby achieving policy learning with landing constraints.
Extensive experimental results in both real-world and simulation environments demonstrate the significant advantages of this method, achieving scores of 98.51 TP3T, 84.11 TP3T, and 47.41 TP3T on the LIBERO, LIBEROPlus, and VLABench benchmarks, respectively.
View the latest papers:https://hyper.ai/papers








