Command Palette
Search for a command to run...
Breakthrough in 3D Vision: ByteSeed Launches DA3, Enabling Visual Space Reconstruction From Any Viewpoint; 70,000+ real-world Industrial Environment Data! CHIP Fills the Gap in Industrial Data for 6D Pose estimation.

The ability to perceive and understand three-dimensional spatial information from visual input is the cornerstone of spatial intelligence and a key requirement for applications such as robotics and mixed reality (ML). This fundamental capability has given rise to a variety of three-dimensional vision tasks, such as monocular depth estimation, structure from motion, multi-view stereo vision, and simultaneous localization and mapping.
These tasks often differ only in a few factors, such as the number of input views, and therefore have a high degree of conceptual overlap. However, the current mainstream paradigm is still to develop highly specialized models for each task. Constructing a unified 3D understanding model that can handle multiple tasks has become an important research direction.However, existing solutions typically rely on complex, custom-designed network architectures and require training from scratch through multi-task joint optimization.Therefore, it is difficult to fully absorb and utilize the knowledge and advantages of large-scale pre-trained models.
Based on this,ByteDance's Seed team has launched Depth Anything 3 (DA3).A single Transformer model, specially trained and based on specific ray representations, can jointly estimate depth and pose from any viewpoint. In the pursuit of extreme model simplification, DA3 brings two key findings:
*A single standard Transformer (such as the vanilla DINO encoder) can be used as the backbone network.No task-specific structure customization is required;
*Predicting targets using only a single depth ray.Excellent performance can be achieved without the need for a complex multi-task learning mechanism.
The research team also established a new visual geometry benchmark covering camera pose estimation, arbitrary viewpoint geometry, and visual rendering. In this test,DA3 refreshes the state in all missions.The camera pose accuracy is on average 35.71 TP3T higher than VGGT, the geometric accuracy is improved by 23.61 TP3T, and the monocular depth estimation is superior to the previous model DA2. Experiments show that this minimalist method is sufficient to reconstruct the visual space from any number of images (regardless of whether the camera pose is known).
The HyperAI website now features "Depth-Anything-3: Recovering Visual Space from Any Viewpoint," so give it a try!
Online use:https://go.hyper.ai/MXyML
A quick overview of hyper.ai's official website updates from December 15th to December 19th:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
Top conferences with January deadlines: 11
Visit the official website:hyper.ai
Selected public datasets
1. VideoRewardBench video reward model evaluation dataset
VideoRewardBench, jointly released by the University of Science and Technology of China and Huawei Noah's Ark Lab, is the first comprehensive evaluation benchmark covering four core dimensions of video understanding: perception, knowledge, reasoning, and security. It aims to systematically evaluate the ability of models to make preference judgments and quality assessments of generated results in complex video understanding scenarios. The dataset contains 1,563 labeled samples, involving 1,482 different videos and 1,559 different questions. Each sample consists of a video-text prompt, a preferred response, and a rejection response.
Direct use:https://go.hyper.ai/JIB1B
2. Arena-Write Writing Generation Evaluation Dataset
Arena-Write is a writing task dataset released by the Singapore University of Technology and Design in collaboration with the Knowledge Engineering Lab of Tsinghua University. It's designed to evaluate long text generation models and systematically assess the comprehensive capabilities of large language models in generating long content and complex writing tasks under realistic usage scenarios. The dataset contains 100 user writing tasks, each consisting of a real-world writing prompt and labeled with the corresponding writing scenario type.
Direct use:https://go.hyper.ai/4NQdD
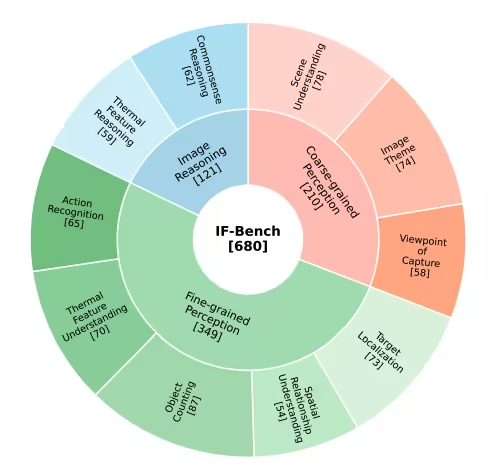
3. IF-Bench Infrared Image Understanding Benchmark Dataset
IF-Bench is a high-quality benchmark for multimodal understanding of infrared images, jointly released by the Institute of Automation, Chinese Academy of Sciences, and the School of Artificial Intelligence, University of Chinese Academy of Sciences. It aims to systematically evaluate the semantic understanding capabilities of multimodal large language models (MLLMs) for infrared images. The dataset contains 499 infrared images and 680 visual question-answering (VQA) pairs. The images are sourced from 23 different infrared image datasets, maintaining a relatively balanced overall distribution.
Direct use:https://go.hyper.ai/hty3u
4. CHIP Industrial Chair 6D Pose Estimation Dataset
CHIP is a 6D pose estimation dataset for robot manipulation in real-world industrial scenarios, released by FBK-TeV in collaboration with Ikerlan and Andreu World. It aims to fill the data gap in existing benchmarks, which primarily focus on household objects and laboratory setups, lacking data on real-world industrial conditions. The dataset contains 77,811 RGB-D images, covering chair models with seven different structures and materials.
Direct use:https://go.hyper.ai/AR5Xm
5. SSRB Semi-structured Data Natural Language Query Dataset
SSRB is a large-scale benchmark dataset for natural language querying of semi-structured data, jointly released by Harbin Institute of Technology (Shenzhen), Hong Kong Polytechnic University, Tsinghua University and other institutions. It has been selected for NeurIPS 2025 Datasets and Benchmarks, aiming to evaluate and promote the ability of models to retrieve semi-structured data under complex natural language query conditions.
Direct use:https://go.hyper.ai/szsqF
6. INFINITY-CHAT Real-world Open-ended Question Answering Dataset
INFINITY-CHAT, the first large-scale dataset for real-world open-ended user questions released by the University of Washington in collaboration with Carnegie Mellon University and the Allen Institute for Artificial Intelligence, won the NeurIPS 2025 Best Paper (DB track). It aims to systematically study key issues such as the diversity of language models in open-ended generation, differences in human preferences, and the "artificial swarm effect".
Direct use:https://go.hyper.ai/KmH1N
7. MUVR Multimodal Uncropped Video Retrieval Benchmark
MUVR is a benchmark dataset for multimodal unedited video retrieval tasks, jointly released by Nanjing University of Aeronautics and Astronautics, Nanjing University, and Hong Kong Polytechnic University. It has been selected for NeurIPS 2025 Datasets and Benchmarks and aims to promote research on video retrieval in long-form video platforms. The dataset contains approximately 53,000 unedited videos from Bilibili, 1,050 multimodal queries, and 84,000 query-video matching relationships, covering various common video types such as news, travel, and dance.
Direct use:https://go.hyper.ai/NRaSw

8. OpenGU Graph Forgetting Comprehensive Evaluation Dataset
OpenGU is a comprehensive evaluation dataset for graph unlearning (GU) released by Beijing Institute of Technology. It has been selected for NeurIPS 2025 Datasets and Benchmarks and aims to provide a unified evaluation framework, multi-domain data resources and standardized experimental settings for forgetting methods in graph neural networks.
Direct use:https://go.hyper.ai/qqHct
9. FrontierScience Inference Research Task Evaluation Dataset
FrontierScience, released by OpenAI, is a dataset for evaluating inference and scientific research tasks. It aims to systematically assess the capabilities of large models in expert-level scientific reasoning and research subtasks. The dataset employs a design mechanism of "expert-original content + two-layer task structure + automatic scoring mechanism," and is divided into two subsets: Olympiad and Research.
Direct use:https://go.hyper.ai/fUUzF
10. FirstAidQA First Aid Knowledge Question Answering Dataset
FirstAidQA is a domain-specific question-answering dataset for first aid and emergency response scenarios, released by the Islamic University of Science and Technology. It aims to support model training and application in resource-constrained emergency environments. The dataset contains 5,500 high-quality question-answer pairs, covering a variety of typical first aid and emergency response scenarios.
Direct use:https://go.hyper.ai/QQphC
Selected Public Tutorials
1. Depth-Anything-3: Restore visual space from any perspective
Depth-Anything-3 (DA3) is a groundbreaking visual geometry model released by the ByteDance-Seed team. It revolutionizes visual geometry tasks with the concept of "minimalist modeling": it uses only a single ordinary Transformer (such as the vanilla DINO encoder) as the backbone network and replaces complex multi-task learning with "depth ray representation" to predict spatially consistent geometric structures from any visual input (both known and unknown camera poses).
Run online:https://go.hyper.ai/MXyML
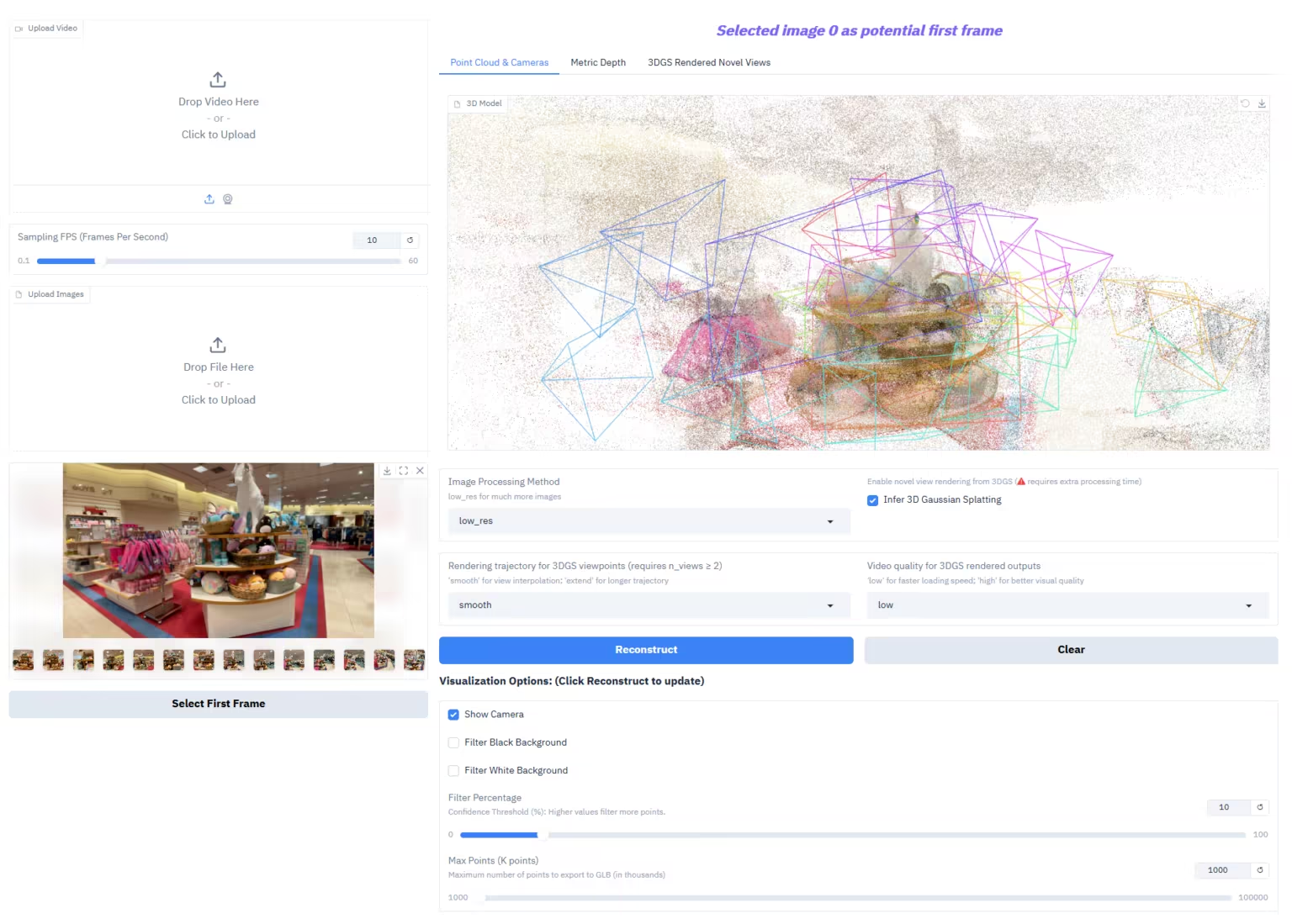
2. MarkItDown, Microsoft's open-source document conversion tool
MarkItDown is a lightweight, plug-and-play Python document conversion tool developed by Microsoft. It aims to efficiently and structurally convert various common document and rich media formats into Markdown, providing an optimized input format specifically for text understanding and analysis pipelines in Large Language Models (LLMs).
Run online:https://go.hyper.ai/7WIGP
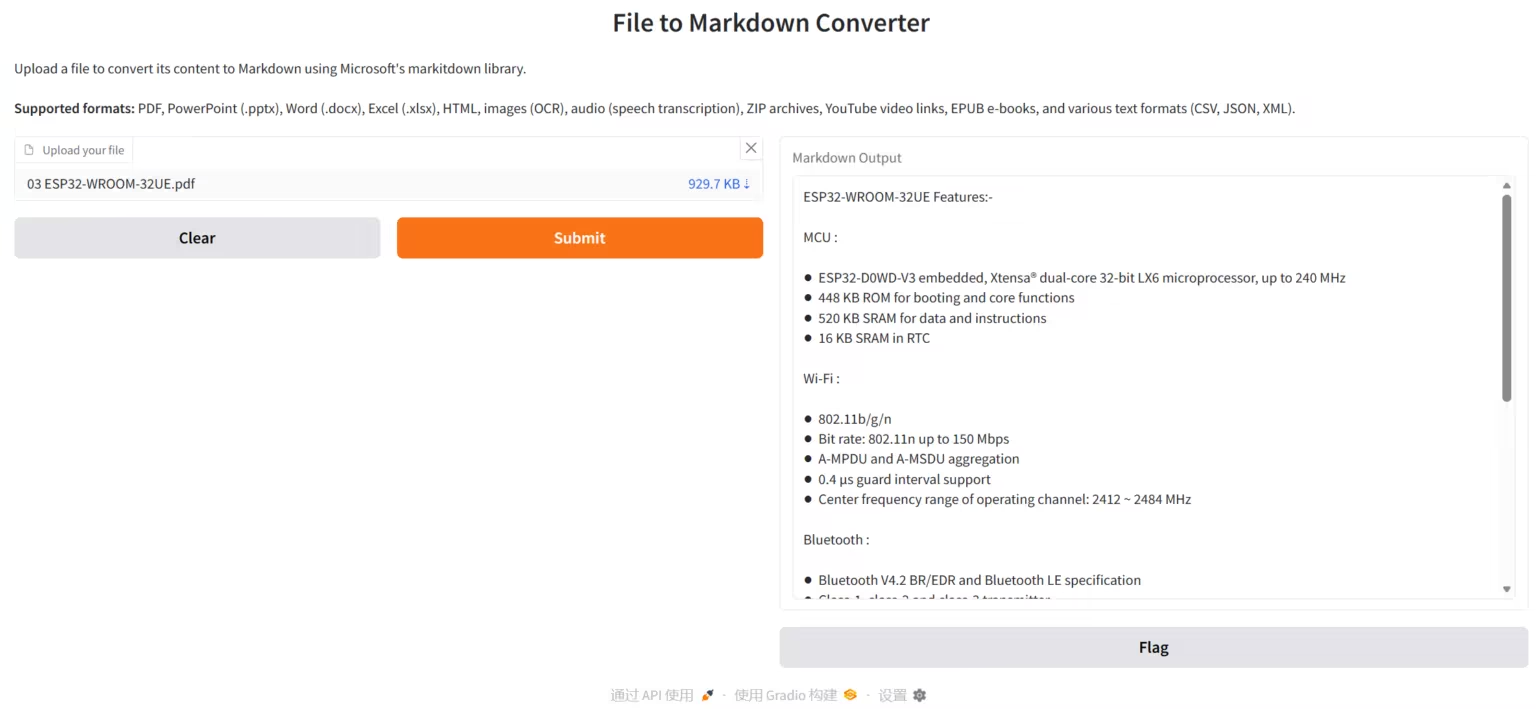
3. Chandra: High-precision document OCR
Chandra is a high-precision document OCR (Optical Character Recognition) system developed by the Datalab-to team, focusing on document layout awareness and text extraction. Chandra can directly process PDF and image files, generating structured text, Markdown, and HTML outputs, while providing visual layout diagrams for easy inspection of OCR results.
Run online:https://go.hyper.ai/nZhF5
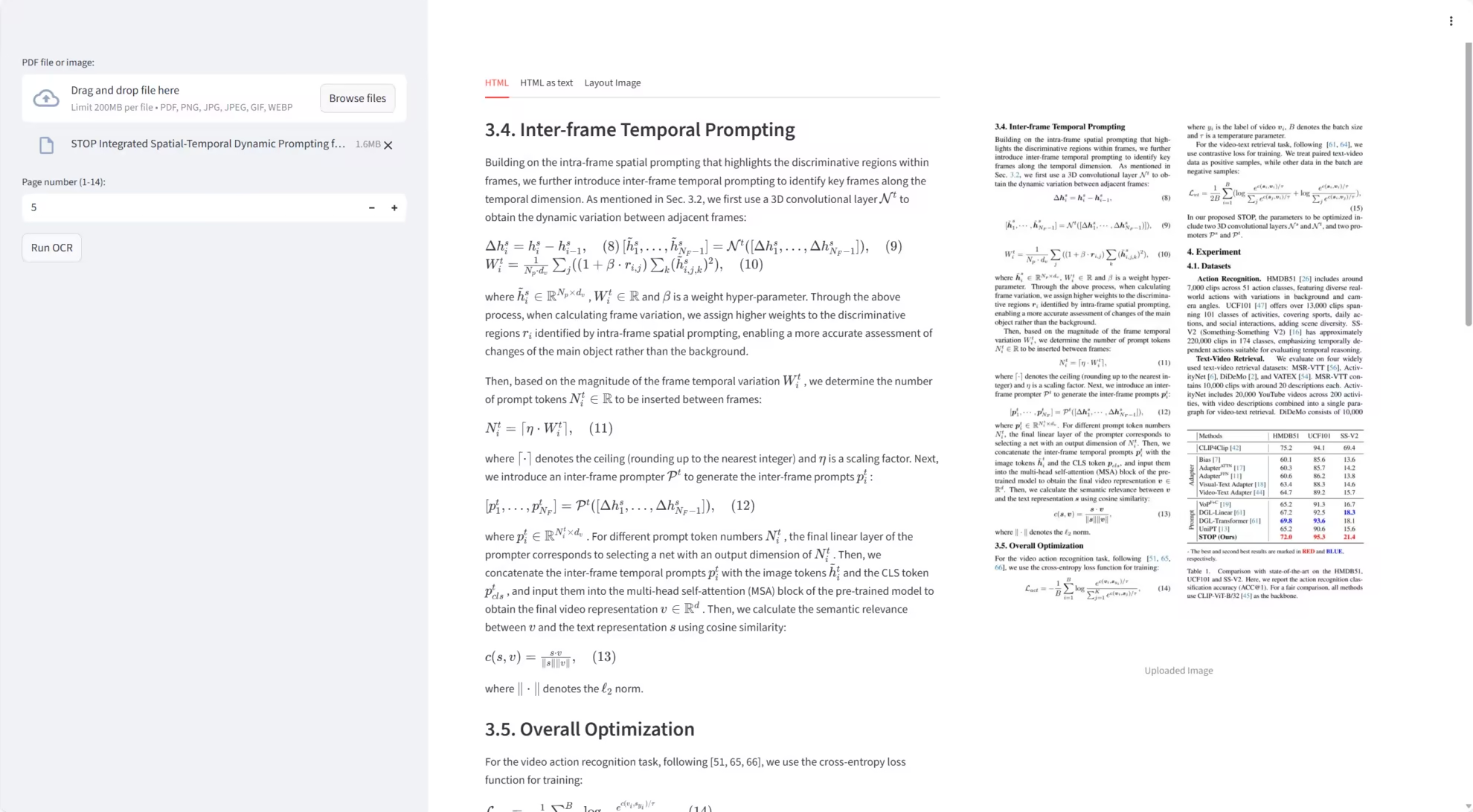
This week's paper recommendation
1. LongVie 2: Multimodal Controllable Ultra-Long Video World Model
This paper proposes LongVie 2, an end-to-end autoregressive framework that achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports the generation of continuous videos up to five minutes long, marking a key step toward modeling a unified video world.
Paper link:https://go.hyper.ai/toK8K
2. MMGR: Multi-Modal Generative Reasoning
This paper proposes the Multimodal Generative Reasoning Evaluation and Benchmarking Framework (MMGR), a systematic evaluation system based on five core reasoning capabilities: physical reasoning, logical reasoning, 3D spatial reasoning, 2D spatial reasoning, and temporal reasoning. MMGR evaluates the reasoning capabilities of generative models in three key areas: abstract reasoning (ARC-AGI, Sudoku), embodied navigation (real-world 3D navigation and positioning), and physical commonsense understanding (sports scenarios and complex interactive behaviors).
Paper link:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
This paper introduces QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. Based on the Qwen3-30B-A3B-Thinking architecture, QwenLong-L1.5 performs close to GPT-5 and Gemini-2.5-Pro in long-context reasoning benchmarks, with an average improvement of 9.90 points compared to its baseline models. In ultra-long tasks (1 million to 4 million tokens), its memory-agent framework achieves a significant improvement of 9.48 points compared to the baseline agent.
Paper link:https://go.hyper.ai/DxYGd
4. Memory in the Age of AI Agents
This paper aims to systematically review the latest developments in agent memory research. First, it clarifies the scope of agent memory, clearly distinguishing it from related concepts such as Large Language Model (LLM) memory, Retrieval-Augmented Generation (RAG), and context engineering. Then, it analyzes agent memory from three unified perspectives: form, function, and dynamics.
Paper link:https://go.hyper.ai/zfHTr
5. ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
This paper proposes ReFusion, a novel mask diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher "slot" level. Each slot is a fixed-length, continuous subsequence. ReFusion not only achieves an average performance improvement of 341 TP3T compared to previous MDMs and an average inference speed improvement of over 18 times, but also significantly narrows the performance gap with strong autoregressive models while maintaining an average speedup advantage of 2.33 times.
Paper link:https://go.hyper.ai/YosaF
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
1. Using fewer than 100,000 structured data points for training, the Swiss Federal Institute of Technology in Lausanne (EPFL) has proposed PET-MAD, achieving atomic simulation accuracy comparable to professional models.
The PET-MAD model proposed by the Swiss Federal Institute of Technology in Lausanne (EPFL) achieves comparable accuracy to dedicated models with a dataset covering a wide range of atomic diversity and using far fewer training samples than traditional models, providing a powerful demonstration for the development of atomic simulation towards greater efficiency and universality.
View the full report:https://go.hyper.ai/cpeR5
2. Online Tutorial | Microsoft Open Sources VibeVoice, Enabling 90 Minutes of Natural Dialogue Between 4 Roles
Microsoft has open-sourced VibeVoice, designed to enable scalable long-form, multi-speaker speech synthesis. The model can synthesize up to 90 minutes of speech with up to four speakers within a 64K context window, offering richer timbre, more natural intonation, and capturing realistic conversational atmosphere. It demonstrates stronger transferability in cross-language applications, and its overall performance surpasses existing open-source and proprietary dialogue models.
View the full report:https://go.hyper.ai/YfDjq
3. CUDA's initial team members sharply criticize cuTile for "specifically targeting" Triton; can the Tile paradigm reshape the competitive landscape of the GPU programming ecosystem?
In December 2025, nearly two decades after the release of CUDA, NVIDIA launched "cuTile," a new GPU programming entry point. This new cuTile refactors the GPU kernel using a tile-based programming model, enabling developers to efficiently write kernels without needing in-depth knowledge of CUDA C++, sparking considerable discussion within the community. Although still in its early stages, the abstract advantages of the tile-based approach, community exploration of migration tools, and practical attempts suggest that cuTile has the potential to become a new paradigm for GPU programming. Its future depends on ecosystem maturity, migration costs, and performance.
View the full report:https://go.hyper.ai/H1b0n
4. Dario Amodei, who prioritizes proactive oversight, incorporated AI safety into the company's mission after leaving OpenAI.
As the global AI race accelerates, Dario Amodei, with his minority stance on "early regulation," has become an undeniable force in Silicon Valley. From promoting Constitutional AI to influencing regulatory frameworks in Europe and the US, he is attempting to establish a "governance protocol" similar to TCP/IP for the AI era. This is not only about security, but also about whether AI can move from rapid technological advancement to stable applications in the next decade. Amodei's strategy is reshaping the underlying logic of the global AI industry.
View the full report:https://go.hyper.ai/SwyNW
5. A team led by Li Yong at Tsinghua University proposed a neural symbolic regression method that can improve prediction accuracy by 60%, automatically deriving high-precision network dynamics formulas.
Professor Yong Li and his team from the Department of Electronic Engineering at Tsinghua University have proposed a neural symbolic regression method, ND², which characterizes system dynamics by automatically deriving mathematical formulas from data. This method simplifies the search problem on high-dimensional networks to a one-dimensional system and utilizes a pre-trained neural network to guide high-precision formula discovery.
View the full report:https://go.hyper.ai/wVktJ
Popular Encyclopedia Articles
1. Nuclear Norm
2. Bidirectional Long Short-Term Memory (Bi-LSTM)
3. Ground Truth
4. Embodied Navigation
5. Frames Per Second (FPS)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
January deadline for the top conference

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








