Command Palette
Search for a command to run...
Covering 19 Scenarios Including Astrophysics, Earth Science, Rheology, and Acoustics, Polymathic AI Constructs 1.3B Models to Achieve Accurate Continuous Medium simulation.
In the fields of scientific computing and engineering simulation, how to efficiently and accurately predict the evolution of complex physical systems has always been a core challenge for both academia and industry. Although traditional numerical methods can theoretically solve most physical equations, they are computationally expensive when dealing with high-dimensional, multi-physics scenarios or non-uniform boundary conditions, and lack adaptability to large-scale multi-tasking.Meanwhile, breakthroughs in deep learning in natural language processing and computer vision have prompted researchers to explore the possibility of applying "base models" in physical simulations.
However, physical systems often evolve across multiple time and spatial scales, while most learning models are typically trained only on short-term dynamics. Once used for long-term predictions, errors accumulate in complex systems, leading to model instability.Furthermore, different scales and system heterogeneity mean that downstream tasks have varying requirements for modeling resolution, dimensionality, and physical field types, posing a significant challenge to modern training architectures that prefer fixed input formats. Therefore, most of the foundational models used for simulation to date remain limited to relatively homogeneous data scenarios, such as handling only two-dimensional problems rather than more realistic three-dimensional situations.
Against this backdrop, a research team from the Polymathic AI Collaboration introduced a series of new methods to address the aforementioned challenges, including: Patch jittering, load-balanced distributed training strategies for 2D–3D scenarios, and Adaptive-compute Tokenization mechanisms.Based on this, the research team proposed a fundamental model called Walrus, which has 1.3 billion parameters, uses Transformer as its core architecture, and is mainly oriented towards fluid-like continuum dynamics. Walrus covers 19 highly diverse physical scenarios during its pre-training phase, encompassing multiple fields including astrophysics, earth science, rheology, plasma physics, acoustics, and classical fluid dynamics. Experimental results demonstrate that Walrus outperforms previous baseline models in both short-term and long-term predictions for downstream tasks, and exhibits stronger generalization performance across the entire pre-training data distribution.
The related research findings, titled "Walrus: A Cross-Domain Foundation Model for Continuum Dynamics," have been published as a preprint on arXiv.
Research highlights:
Walrus has a model parameter scale of 1.3B, innovative stabilization techniques, and the ability to adapt computation to problem complexity;
* It addresses several limitations of current fundamental models for continuum dynamics, such as cost adaptation, stability, and efficient training on highly heterogeneous training data at native resolution;
* Walrus is the most accurate foundational model for continuum simulation to date, achieving state-of-the-art results on 56 out of 65 metrics tracked across 26 unique continuum simulation tasks from multiple scientific fields and across multiple timescales.

Paper address:https://arxiv.org/abs/2511.15684
Follow our official WeChat account and reply "media simulation" in the background to get the complete PDF.
More AI frontier papers:
https://hyper.ai/papers
Constructing heterogeneous, multidimensional, high-quality datasets
Walrus's success is inseparable from the diversity and high-quality data. The research team used a hybrid dataset from Well and FlowBench for pre-training. The Well dataset provides a large amount of high-resolution data derived from real scientific problems, while FlowBench introduces geometrically complex obstacles into standard fluid scenarios, providing the model with opportunities to learn complex flow patterns.
The research team used a total of 19 datasets, covering 63 state variables, including different equations, boundary conditions, and physical parameterization settings.The data dimensions encompass both two and three dimensions to ensure the model's generalization ability across different spatial dimensions. To verify the model's transferability, the research team fine-tuned the model using a portion of the reserved datasets, including data from Well, FlowBench, PDEBench, PDEArena, and PDEGym, after pre-training. Data splitting followed standard partitioning strategies, or was divided into an 80/10/10 ratio for training/validation/testing based on trajectories.
In terms of training settings, the Walrus model underwent approximately 400,000 pre-training steps, with about 4 million samples in each 2D dataset and about 2 million samples in each 3D dataset. The AdamW optimizer and learning rate scheduling strategy were used to achieve efficient learning on high-dimensional, multi-task data. The primary evaluation metric used was VRMSE (Standardized Root Mean Square Error), which allows for unified evaluation across datasets and tasks.
This highly diverse training data and strategy enables Walrus to capture rich physical properties during the pre-training phase and lay the foundation for cross-domain generalization for downstream tasks.
Transformer architecture based on spatiotemporal factorization
The Walrus model employs a space-time factorized transformer architecture. When processing spatiotemporal tensor structured data, it performs attention operations along both the spatial and temporal dimensions to achieve efficient modeling. The process is shown in the figure below:
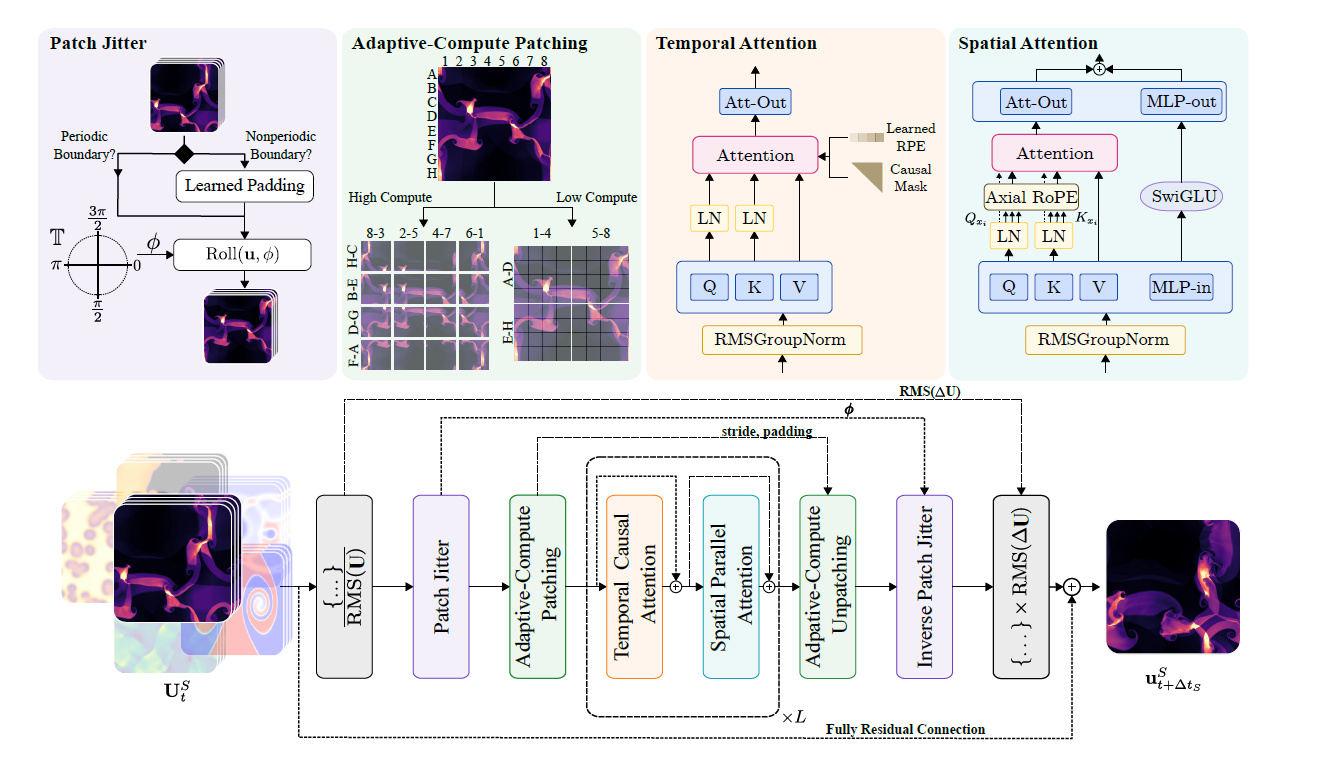
* Space processing:We use parallel attention proposed by Wang and combine it with Axial RoPE for position encoding.
* Timeline processing:We use causal attention combined with T5-style relative position coding. QK normalization is applied in both spatial and temporal modules to improve training stability.
* Compute-Adaptive Compression:In the encoder and decoder modules, Convolutional Stride Modulation (CSM) is used to natively process data at different resolutions. Flexible resolution handling is achieved by adjusting the downsampling/upsampling levels in each encoder/decoder block. Previous simulation models often used fixed compression encoders, which were not flexible enough to meet the varying resolution requirements of downstream tasks. CSM allows researchers to adjust the convolutional stride for downsampling, thereby selecting a spatial compression level that matches the task.
* Shared Encoder-Decoder:All physical systems of the same dimension share a single encoder and decoder to learn common features. Two-dimensional and three-dimensional data correspond to two encoders and two decoders, respectively, and are encoded and decoded using a lightweight hierarchical MLP (hMLP).
* RMS GroupNorm and asymmetric input/output normalization:RMSGroupNorm is used for normalization within each Transformer block to improve training stability. Asymmetric normalization is used for incremental predictions of inputs and outputs to ensure numerical stability across different scenarios.
* Patch Jittering:By randomly shifting the input data and then processing it in reverse at the output, the accumulation of high-frequency artifacts is reduced, significantly improving long-term prediction stability, especially in ViT-style architectures.
* High-efficiency multi-task training:Hierarchical sampling and normalized loss function are employed to ensure that predictions of rapidly changing fields are not dominated by slowly changing fields. At the same time, micro-batch and adaptive tokenization strategies are combined to solve the problem of uneven load in training high-dimensional heterogeneous data.
* Unified representation of two-dimensional and three-dimensional representations:By adding a single dimension to two-dimensional data and zero-filling it, embedding it into three-dimensional space, and then using symmetry enhancement (rotation, reflection) for diversified amplification, cross-dimensional training capability is achieved.
Overall, the Walrus architecture not only efficiently processes tensor data in both spatial and temporal dimensions, but also addresses the challenges of multi-task and multi-physical scenarios through diverse strategies and efficient distributed training.
Walrus demonstrates significant advantages in multiple 2D and 3D downstream tasks.
To verify the performance of Walrus as a base model and its performance in downstream tasks, the researchers designed a series of experiments:
① Downstream task performance
Compared with existing baseline models such as MPP-AViT-L, Poseidon-L, and DPOT-H, Walrus reduces the average VRMSE by approximately 63.61 TP3T in single-step prediction, 56.21 TP3T in short-term trajectory prediction, and 48.31 TP3T in medium-term trajectory prediction, as shown in the figure below:
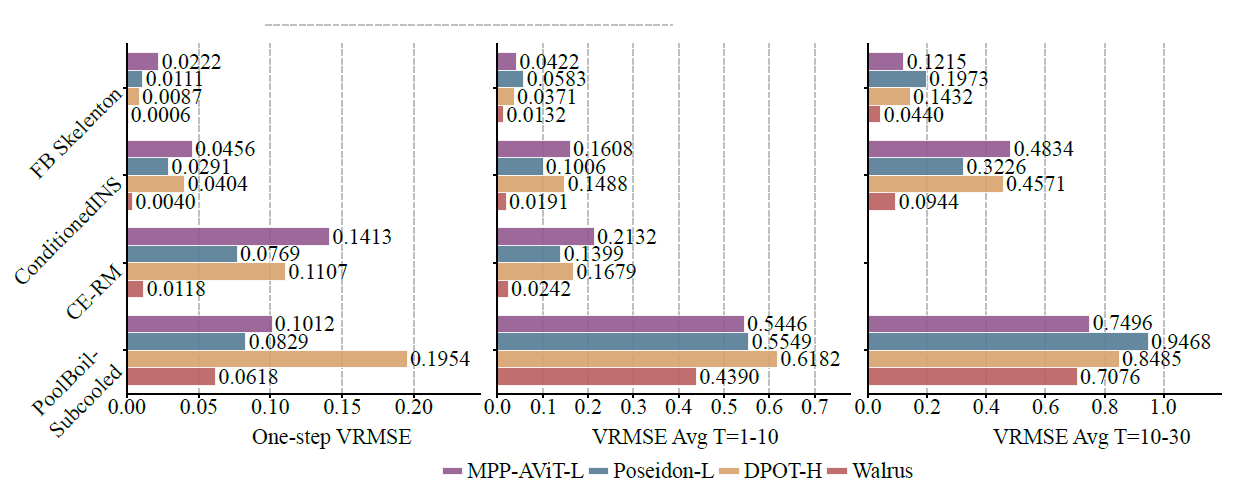
In non-chaotic systems, the low artifact generation brought about by patch jittering makes the model's long-term prediction performance stable; in more stochastic systems (such as Pool-BoilSubcool in BubbleML), although Walrus initially leads, its long-term rolling prediction advantage is weakened because short-term historical information cannot fully reflect the characteristics of materials and burners.
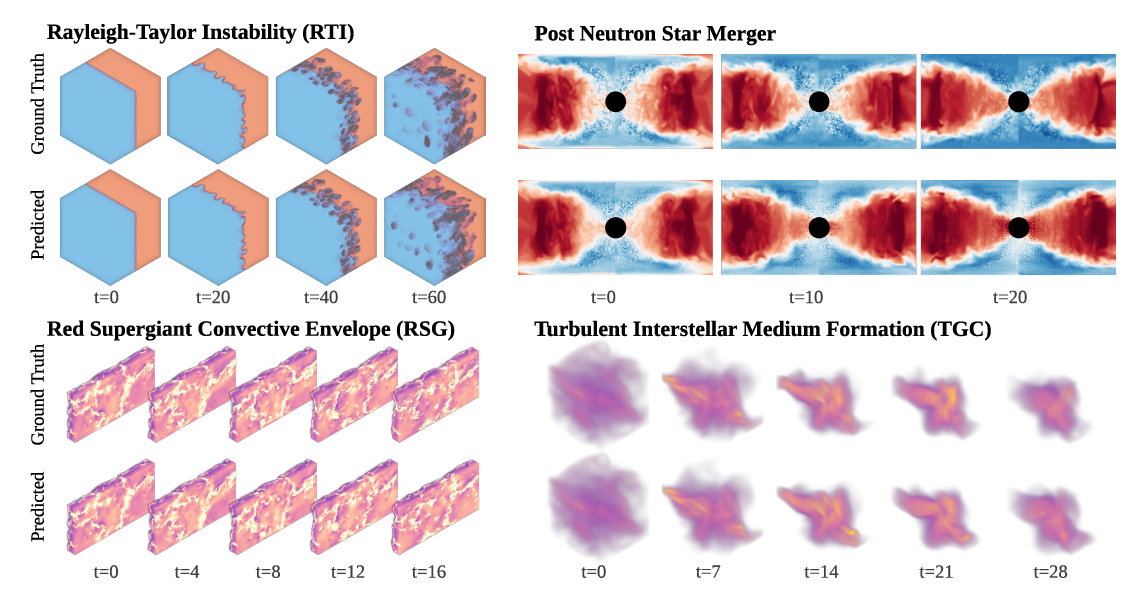
Three-dimensional tasks are particularly important because most real-world physics simulations are three-dimensional systems. Walrus performs exceptionally well on the PNS (post-neutron star merger) and RSG (red supergiant troposphere) datasets, even though these datasets cost millions of core hours to generate, as shown in the figure below:
② Cross-domain capabilities
Walrus's cross-domain capabilities were also validated; compared to the optimal baseline, Walrus reduced the average loss by 52.21 TP3T in single-step prediction.After fine-tuning on 19 pre-trained datasets, Walrus achieved the lowest single-step loss on 18/19 tasks, and average advantages of 30.5% and 6.3% in mid-term rolling predictions at 20 and 20-60 steps, respectively, as shown in the table below:
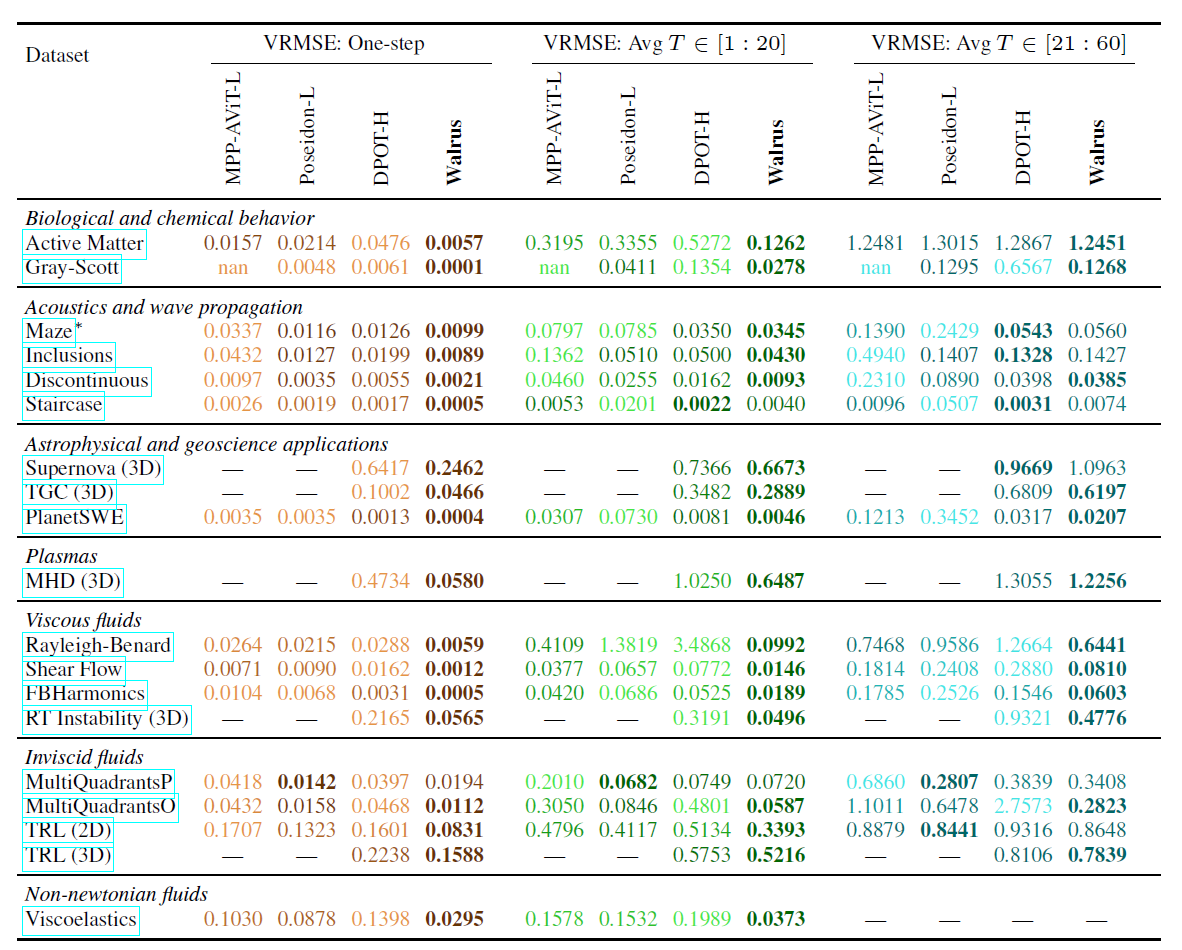
In comparison, DPOT performs close to Walrus in acoustic and linear wave propagation tasks, while Poseidon excels in inviscid flow tasks. However, Walrus achieves competitive or even better results on most tasks through extensive pre-training and a general architecture.
③ Impact of pre-training strategies
Ablation experiments show that Walrus's diverse pre-training strategies are crucial to downstream performance. Even on the half-size model (HalfWalrus) using only two-dimensional data, the pre-training strategy with comprehensive spatial and temporal augmentations significantly outperforms models trained from scratch or with simple two-dimensional pre-training strategies on completely unseen new tasks.
In 3D CNS tasks, HalfWalrus can achieve a slight improvement even with a very small amount of data, even without having seen 3D data. The full Walrus model, through pre-training with 3D data, has achieved a significant advantage, highlighting the importance of multi-dimensional and diverse data.
Polymathic AI accelerates the implementation of interdisciplinary artificial intelligence applications.
In the fields of scientific computing and engineering modeling, the potential of foundational models is triggering a new paradigm shift. Polymathic AI is a noteworthy open-source research project whose core goal is to build general-purpose foundational models for scientific data to accelerate the implementation of interdisciplinary artificial intelligence applications.
Unlike general-purpose large models for natural language or vision tasks, Polymathic AI focuses on typical scientific computing problems such as continuous dynamic systems, physical field simulation, and engineering system modeling.Its core idea is to train a unified model through large-scale, multi-physics, and multi-scale data, enabling it to have cross-domain transfer capabilities, thereby reducing the cost of building a model from scratch for each scientific problem—this "cross-domain generalization capability" is considered a key breakthrough in scientific AI.
Polymathic AI reportedly brings together a team of pure machine learning researchers and domain scientists, receives guidance from a scientific advisory group of world-leading experts, and is advised by Turing Award winner and Meta's chief scientist Yann LeCun. It also receives support from several academic luminaries, including Miles Cranmer, Assistant Professor of AI+ Astronomy/Physics at the University of Cambridge, with the aim of focusing on developing fundamental models for scientific data and using interdisciplinary shared concepts to solve industry challenges in AI for Science.
In 2025, members of the Polymathic AI Collaboration showcased two new artificial intelligence models trained on real-world scientific datasets, designed to address problems in astronomy and fluid-like systems. One was Walrus, mentioned earlier, and the other was AION-1 (Astronomical Omni-modal Network), the first large-scale multimodal foundational model family for astronomy. AION-1 integrates and models heterogeneous observational information such as images, spectra, and star catalog data through a unified early fusion backbone network. It not only performs exceptionally well in zero-shot scenarios but also boasts linear detection accuracy comparable to task-specific models, demonstrating superior performance across a wide range of scientific tasks. Even with simple forward detection, its performance reaches state-of-the-art (SOTA) levels, and it significantly outperforms supervised baselines in low-data scenarios.
Paper Title:AION-1: Omnimodal Foundation Model for Astronomical Sciences
Paper address:https://arxiv.org/abs/2510.17960
Overall, Polymathic AI represents a cutting-edge exploration of the emerging technological paradigm of "basic models of scientific AI." Its long-term significance lies not only in performance improvement, but also in building a general computing foundation for cross-disciplinary knowledge transfer, laying the foundation for "AI for Science" to move from tool-level applications to infrastructure-level capabilities.
References:
1.https://arxiv.org/abs/2511.15684
2.https://www.thepaper.cn/newsDetail_forward_32173693
3.https://polymathic-ai.org
4.https://arxiv.org/abs/2510.17960
5.https://www.163.com/dy/article/KGMRMMQM055676SU.html








