Command Palette
Search for a command to run...
TRELLIS.2: Employs O-Voxel Technology for Efficient Generation of Complex 3D Geometry and Materials; Patient Churn Prediction Dataset: Helps Identify Patients at Risk of attrition.

Currently, generating usable 3D models from images remains time-consuming and labor-intensive, with traditional processes heavily reliant on manual operation by professional modelers. Even with AI assistance,When dealing with complex shapes, transparent materials, or open surfaces, the models often produce poor results or abnormal structures, and it is difficult to generate finished products with realistic materials that can be directly used in games and e-commerce.
Against this backdrop, the Microsoft team released TRELLIS.2, an open-source project in December 2025, for generating high-quality 3D assets and texturing tasks from single images.The project provides an end-to-end process from input images to 3D shapes and materials, and comes with an interactive web demo for quick experience and asset export. TRELLIS.2 focuses on improving geometric details and texture consistency, supports multiple resolutions and cascaded inference configurations, and balances speed and quality through controllable inference parameters, making it suitable for scenarios such as 3D content production, rapid prototyping, and creative exploration.
The HyperAI website now features the "TRELLIS.2 3D Generation Demo," so come and try it out!
Online use:https://go.hyper.ai/drI7I
A quick overview of hyper.ai's official website updates from January 19th to January 23rd:
* High-quality public datasets: 5
* A selection of high-quality tutorials: 9
* This week's recommended papers: 5
* Community article interpretation: 4 articles
* Popular encyclopedia entries: 5
Top conferences with January deadlines: 3
Visit the official website:hyper.ai
Selected public datasets
1. Patient Segmentation Dataset
Patient Segmentation is a patient classification dataset for healthcare analytics and marketing. It aims to segment patients into meaningful groups by analyzing their demographics, health status, insurance type, and healthcare usage patterns to improve the effectiveness of personalized care and marketing.
Direct use:https://go.hyper.ai/Wp8LS
2. CCTV Incident Fall Detection Dataset
CCTV Incident is an open synthetic dataset specifically designed for fall detection, pose estimation, and accident monitoring in computer vision tasks. It is designed to analyze from a CCTV overhead view, enabling models to understand human postures and accurately distinguish between individuals who are standing and those who have fallen.
Direct use:https://go.hyper.ai/q60Dm

3. Patient Churn Prediction Dataset
The Patient Churn Prediction dataset is a categorical dataset for the healthcare field containing 2,000 patient records designed to help identify patients at risk of churn so that retention measures can be taken in advance.
Direct use:https://go.hyper.ai/QAeYw
4. RealTimeFaceSwap-10k Video Call Spoofing Dataset
The RealTimeFaceSwap-10k video call deepfake detection dataset is a dataset used to detect deepfake videos in video conferencing scenarios. This dataset includes various application scenarios and data types, aiming to provide fundamental data support for video spoofing detection.
Direct use:https://go.hyper.ai/SGZRO
5. TransPhy3D Transparent Reflection Synthesis Video Dataset
TransPhy3D is a synthetic video dataset developed by the Beijing Academy of Artificial Intelligence in collaboration with the University of Southern California, Tsinghua University, and other institutions, focusing on transparent and reflective scenes. The dataset consists of 11,000 sequences rendered using Blender/Cycles, providing high-quality RGB frames along with physically based depth and normal labels.
Direct use:https://go.hyper.ai/5ExjE
Selected Public Tutorials
1.vLLM+Open WebUI deploy Nemotron-3 Nano
Nemotron-3-Nano-30B-A3B-BF16 is a large-scale language model (LLM) trained from scratch by NVIDIA, designed as a unified model applicable to both reasoning and non-reasoning tasks. This model is suitable for developers designing AI agent systems, chatbots, RAG systems, and other AI applications.
Run online:https://go.hyper.ai/VUuDA
2. MedGemma 1.5 Multimodal AI Medical Model
MedGemma 1.5 is a model that excels in medical multimodal tasks. It demonstrates outstanding capabilities in image classification, visual question answering, and medical knowledge reasoning, making it suitable for various clinical scenarios and effectively supporting medical research and practice. This model is built upon the SigLIP image encoder and a high-performance language module, and is pre-trained on diverse datasets including medical images, text, and laboratory reports. This enables efficient processing of tasks such as high-dimensional medical images, whole-section pathology images, longitudinal image analysis, anatomical localization, medical document understanding, and electronic health record parsing.
Run online:https://go.hyper.ai/dZRn9
3. Nemotron-Speech-Streaming-ASR: Automatic Speech Recognition Demo
Nemotron Speech Streaming ASR is a streaming automatic speech recognition model released by the Nemotron Speech team at NVIDIA. Designed for low-latency, real-time speech transcription scenarios, it also boasts high-throughput batch inference capabilities, making it suitable for applications such as voice assistants, real-time captioning, conference transcription, and conversational AI. The model employs a cache-aware FastConformer encoder and RNN-T decoder architecture, achieving efficient processing of continuous audio streams while significantly reducing end-to-end latency while maintaining recognition accuracy.
Run online:https://go.hyper.ai/SDEBI
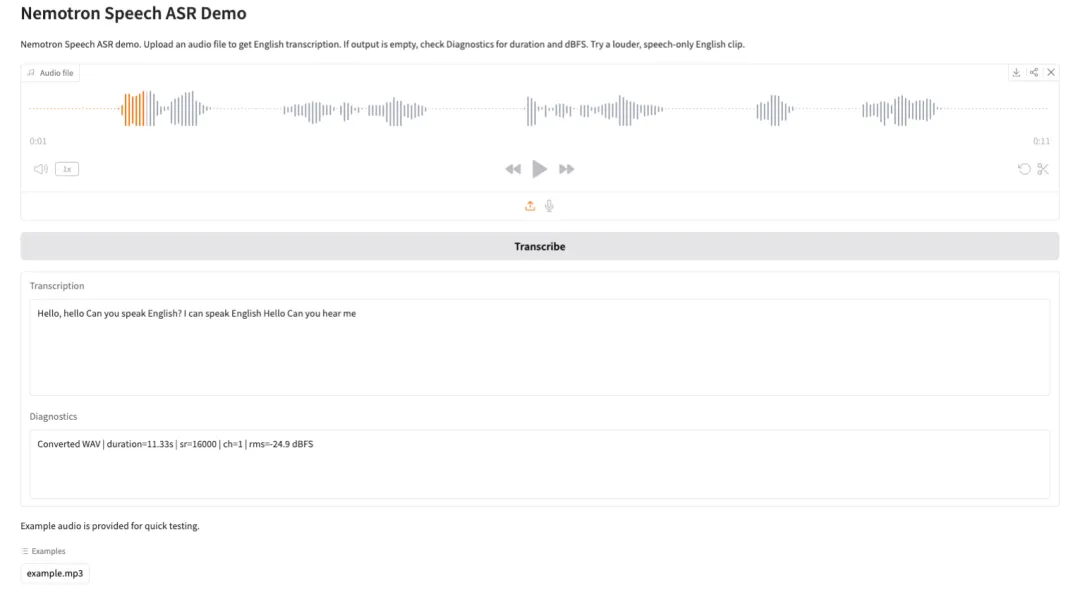
4. TranslateGemma-4B-IT: A series of open-source translation models from Google.
TranslateGemma is a lightweight, open-source translation model family released by the Google Translate team. Built upon the Gemma 3 model family, it is specifically designed for multilingual text translation and real-world deployment scenarios. This family provides stable and usable translation capabilities with a compact parameter scale, making it suitable for loading and inference in environments with limited GPU memory or requiring rapid deployment.
Run online:https://go.hyper.ai/FRy35
5. GLM-Image: A high-fidelity image generation model with accurate semantics
GLM-Image is an open-source image generation model developed by Zhipu AI, which integrates autoregressive decoding and diffusion decoding. This model supports both text-to-image and image-to-image generation, and is built upon a unified visual-language representation. This allows the same model to understand both text prompts and input images, and also to perform refined image generation through a DiT (Diffusion Transformer) style diffusion backbone network.
Run online:https://go.hyper.ai/2bcfV

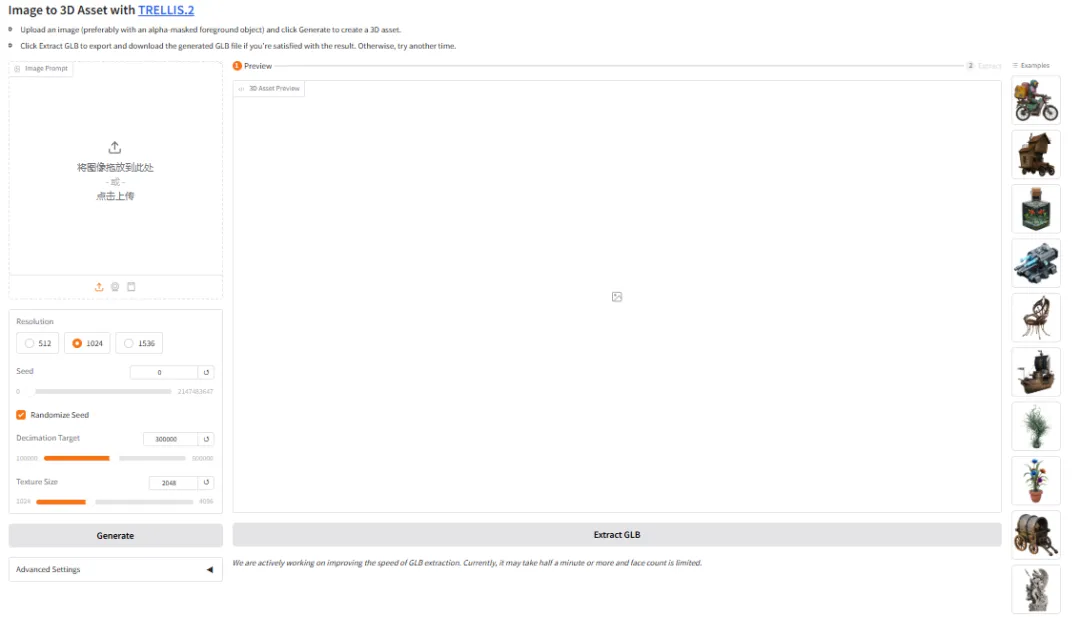
6. TRELLIS.2 3D Demo Generation
TRELLIS.2 is an open-source project released by Microsoft, a large model with 4 billion parameters, focused on generating fully textured, ready-to-use 3D assets directly from a single image. This model unifies high-quality geometry and material generation, completing high-fidelity geometry reconstruction and full-dimensional PBR material synthesis within a single workflow.
Run online:https://go.hyper.ai/drI7I
7.vLLM+Open WebUI Deployment FunctionGemma-270m-it
FunctionGemma-270m-it is a lightweight, dedicated function call model released by Google DeepMind, with 270 million parameters. Built on the Gemma 3 270M architecture, it is trained using the same research techniques as the Gemini series. Specifically designed for function call scenarios, this model utilizes 6TB of training data up to August 2024, covering public tool definitions and tool usage interaction data. FunctionGemma supports a maximum context length of 32KB and has undergone rigorous content security filtering and a responsible AI development process.
Run online:https://go.hyper.ai/pdN7q

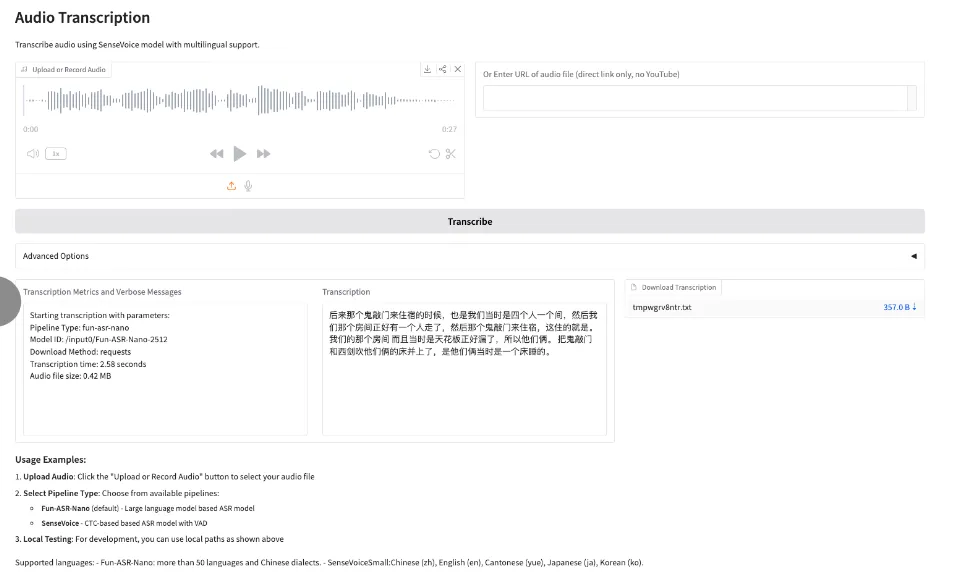
8. Fun-ASR-Nano: A large-scale end-to-end speech recognition model
Fun-ASR-Nano is an end-to-end large-model speech recognition solution launched by Alibaba Tongyi Labs, and is part of the Fun-ASR series. This solution is designed for low-computing-power deployment scenarios, aiming to achieve low-latency speech-to-text transcription, and focusing on performance on real-world evaluation sets. Its features include multilingual free speech recognition (free code-switching), customizable hotwords, and hallucination suppression.
Run online:https://go.hyper.ai/j7OdD
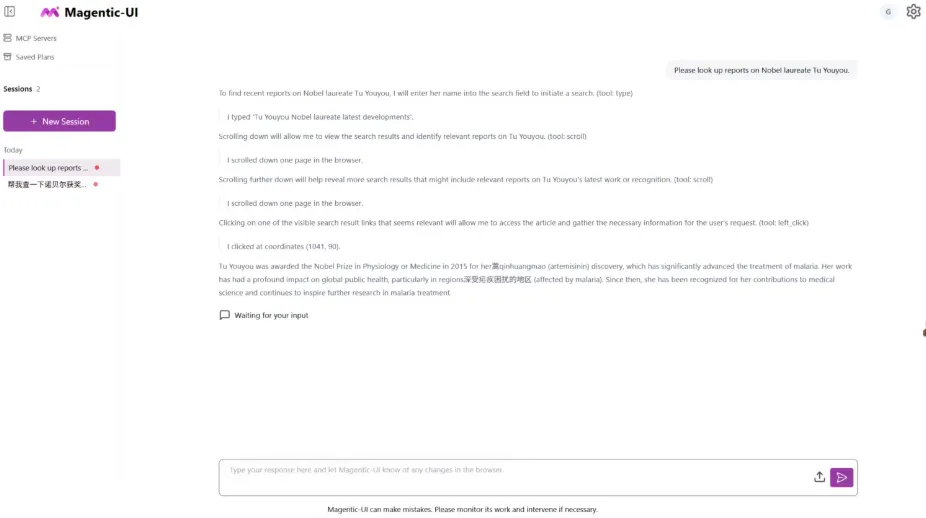
9. Fara-7B: An efficient web-based intelligent agent model
Fara-7B is the first agentic SLM (Small Language Model) for computer use, released by Microsoft Research. With only 7 billion parameters (7B), it performs exceptionally well in real-world web page manipulation tasks, achieving state-of-the-art (SOTA) performance in multiple Web Agent benchmarks and approaching or even surpassing larger-scale models on some tasks.
Run online:https://go.hyper.ai/2e5rp
This week's paper recommendation
1. Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
This paper constructs the first video deep learning benchmark, VideoDR, which requires models to extract visual anchors from videos, perform interactive retrieval, and conduct multi-hop inference based on multi-source evidence. Evaluation of different large models reveals that the agent paradigm is not always superior to the workflow paradigm; its effectiveness depends on the model's ability to maintain initial visual anchors in long retrieval chains. The study identifies target drift and long-term consistency as key bottlenecks.
Paper link:https://go.hyper.ai/uB9jE
2. BabyVision: Visual Reasoning Beyond Language
This study found that existing MLLMs rely excessively on linguistic priors and lack the core visual abilities possessed by young children. The research team's BabyVision benchmark test showed that top-performing models (such as Gemini at 49.7) scored significantly lower than adult levels (94.1), even falling short of 6-year-old children, demonstrating a fundamental deficiency in basic visual comprehension. This research aims to advance MLLMs towards human-level visual perception and reasoning.
Paper link:https://go.hyper.ai/cjtcE
3. STEP3-VL-10B Technical Report
This paper proposes STEP3-VL-10B as a high-performance open-source multimodal foundation model. Through unified pre-training, reinforcement learning, and an innovative parallel coordinated inference mechanism, it achieves outstanding performance with only 10 billion parameters. It rivals or surpasses giant models 10 to 20 times larger and top-tier closed-source models in multiple benchmark tests, providing the community with a powerful and efficient benchmark for visual language intelligence.
Paper link:https://go.hyper.ai/q6kmv
4. Thinking with Map: Reinforced Parallel Map-Augmented Agent for Geolocalization
This paper proposes to enable the model to "think using a map." Through agent-map loops and two-stage optimization, reinforcement learning and parallel testing-time scaling are employed, significantly improving image geolocation accuracy. On the newly constructed real-world image benchmark MAPBench, this method surpasses existing open-source and closed-source models, dramatically increasing the accuracy within 500 meters from 8.01 TP3T to 22.11 TP3T.
Paper link:https://go.hyper.ai/Fn9XT
5. Urban Socio-Semantic Segmentation with Vision-Language Reasoning
This study proposes the SocioSeg dataset and the SocioReasoner framework, utilizing a visual language model for reasoning to address the challenge of segmenting social semantic entities in satellite imagery. This method simulates the human annotation process through cross-modal recognition and multi-stage reasoning, and is optimized using reinforcement learning. Experimentally, it outperforms existing state-of-the-art models, demonstrating strong zero-shot generalization capabilities.
Paper link:https://go.hyper.ai/PW7g4
Community article interpretation
1. Integrating protein sequence, 3D structure, and functional characteristics data, a German team constructed a "panoramic view" of the human E3 ubiquitin ligase based on metric learning.
In organisms, the timely degradation and renewal of cellular proteins is crucial for maintaining protein homeostasis. The ubiquitin-proteasome system (UPS) is a core mechanism regulating signal transduction and protein degradation. Within this system, E3 ubiquitin ligases serve as key catalytic units, and to date, studied E3 ligases have exhibited high heterogeneity. Against this backdrop, a research team from Goethe University in Germany classified the "human E3 ligome." Their classification method is based on a metric-learning paradigm, employing a weakly supervised hierarchical framework to capture the true relationships between the E3 family and its subfamilies.
View the full report:https://go.hyper.ai/zyM1F
2. Yale University proposed MOSAIC, which builds a team of over 2,000 AI chemistry experts, enabling efficient specialization and identification of optimal synthetic routes.
Modern synthetic chemistry is facing a prominent contradiction between the rapid accumulation of knowledge and the efficiency of its application and transformation. Currently, the field's development is mainly limited by two factors: firstly, expert experience struggles to cover the ever-expanding reaction space, often resulting in high trial-and-error costs in interdisciplinary synthetic tasks; secondly, despite the rapid development of artificial intelligence technology, the reliability of general-purpose models in chemistry remains insufficient. Against this backdrop, a research team at Yale University recently proposed the MOSAIC model, transforming a general-purpose large-language model into a collaborative system composed of numerous specialized chemical experts.
View the full report:https://go.hyper.ai/oatBT
3. Online Tutorial | GLM-Image: Accurately Understanding Instructions and Writing Correct Text Based on a Hybrid Architecture of Autoregressive + Diffusion Decoder
In the field of image generation, diffusion models have gradually become mainstream due to their stable training and strong generalization capabilities. However, when faced with "knowledge-intensive" scenarios, traditional models suffer from a weakness in simultaneously handling instruction understanding and detailed characterization. To address this, Zhipu, in collaboration with Huawei, has open-sourced a new generation image generation model, GLM-Image. This model is trained entirely on the Ascend Atlas 800T A2 and the MindSpore AI framework. Its core feature is the adoption of an innovative hybrid architecture of "autoregressive + diffusion decoder" (9B autoregressive model + 7B DiT decoder), combining the deep understanding capabilities of language models with the high-quality generation capabilities of diffusion models.
View the full report:https://go.hyper.ai/LTojo
4. Latest Nature findings from Tsinghua University and the University of Chicago! AI enables scientists to be promoted 1.37 years earlier and reduces the scope of scientific exploration by 4.631 TP3T
Recently, a research team from Tsinghua University and the University of Chicago published their latest research findings in Nature entitled "Artificial intelligence tools expand scientists' impact but contract science's focus," providing unprecedented systematic evidence for the industry to understand the fundamental impact of AI on science.
View the full report:https://go.hyper.ai/0NhLI
Popular Encyclopedia Articles
1. Frames per second (FPS)
2. Reverse sort fusion RRF
3. Visual Language Model (VLM)
4. HyperNetworks
5. Gated Attention
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
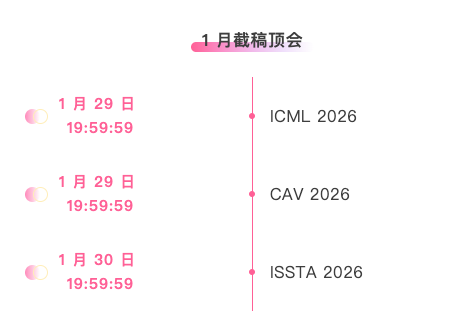
A one-stop platform for tracking top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








