Command Palette
Search for a command to run...
After Traversing 100 Million Data Points From the Hubble Space Telescope in 3 Days, the European Space Agency Proposed AnomalyMatch, Discovering Over a Thousand Anomalous Celestial objects.

Currently, large-scale, multi-band, wide-field-of-view, and high-depth sky surveys are propelling astronomy into an unprecedented data-intensive era. With the commissioning of next-generation facilities such as the Euclid Space Telescope, the Rubin Observatory, and the Roman Space Telescope, the universe is being systematically mapped on an unprecedented scale and with unprecedented precision. These observations are expected to generate billions of celestial images and spectroscopic data, one of their core scientific potentials…That is, to systematically discover and identify those rare celestial bodies with special astrophysical value.Examples include strong gravitational lensing, merging galaxies, jellyfish galaxies, and protoplanetary disks with edge orientation.
These rare celestial objects, often referred to as "astrophysical anomalies," play a crucial role in testing galaxy evolution models, gravitational theories, and cosmological parameters. However, their discovery has long relied heavily on accidental visual identification by researchers or manual screening by citizen science projects.These methods are not only highly subjective and inefficient, but also difficult to adapt to the massive scale of data that is about to emerge.
at the same time,Traditional supervised machine learning methods face fundamental challenges due to the extremely limited number of rare celestial object labeled samples and the extreme imbalance of data categories.To address this bottleneck, research has gradually shifted towards unsupervised or weakly supervised anomaly detection frameworks. These methods do not predefine specific target categories; instead, they learn the overall structure or distribution of the data itself through algorithms, thereby automatically identifying "outliers" that significantly deviate from the "normal" group. For example, tools based on algorithms such as isolation forests and local anomaly factors, or techniques that construct representation spaces through self-supervised learning and then perform similarity searches, have demonstrated their effectiveness in tasks such as screening for strong gravitational lensing from large-scale sky survey data.
However, purely unsupervised methods can produce a large number of "noise" anomalies that are irrelevant to astrophysical interests. To compensate for this shortcoming,A research team at the European Space Astronomy Centre (ESAC), a division of the European Space Agency (ESA), has proposed and applied a new method called AnomalyMatch.The rare celestial object detection task is defined as an extremely imbalanced semi-supervised binary classification problem and deeply integrated with active learning loops. It can be started with only a very small number of labeled anomalous samples, less than 10. At the same time, it fully explores and utilizes the value of massive unlabeled data by using semi-supervised learning techniques such as pseudo-labels and consistency regularization. Furthermore, an expert verification mechanism is introduced throughout the process, and the detection performance is gradually improved by making full use of unlabeled data and expert knowledge.
The related research findings, titled "Identifying astrophysical anomalies in 99.6 million source cutouts from the Hubble legacy archive using AnomalyMatch," have been published in Astronomy & Astrophysics.
Research highlights:
* AnomalyMatch was used to perform the first systematic screening of anomalous celestial objects across the entire Hubble Heritage Archive (approximately 100 million image slices).
* The system has released a catalog of newly discovered astrophysical anomalies, significantly expanding the sample library of rare phenomena, including 417 new galaxy mergers, 138 gravitational lensing candidates, 18 jellyfish galaxies, and 2 collision ring galaxies.
* The method's extremely high processing efficiency and accuracy have been successfully verified, with full data analysis completed in just 2 to 3 days, demonstrating its transformative potential in processing future ultra-large-scale sky survey data from Euclidean Telescope and other sources.
Paper address:https://doi.org/10.1051/0004-6361/202555512
Follow our official WeChat account and reply "rare celestial bodies" in the background to get the full PDF.
More AI frontier papers:
https://hyper.ai/papers
Built on a standardized dataset of approximately 100 million Hubble source cut maps
The dataset used in this study originates from source cutouts generated by O'Ryan et al. This work originally aimed to systematically search for interacting and merging galaxies from the Hubble Legacy Archive, processing almost all extended sources within the archive to ultimately construct a large-scale, standardized image set. To ensure data consistency and operability,Researchers selected only the Level 3 calibrated mosaic images acquired by the Hubble Space Telescope's Advanced Camera for Surveys wide-field channel under the F814W filter.In other words, data that has been processed to the point where it can be directly used for scientific analysis.
This screening process yielded approximately ten thousand observations, covering extended sources in the Hubble source catalog published by Whitmore et al. using the SourceExtractor software.This ultimately resulted in an image library containing approximately 99.6 million single-source crop images.Each slice is fixed at 150×150 pixels, corresponding to a celestial region of approximately 7.5 arcseconds square, and is enhanced using Astropy's linear stretching and ZScaleInterval methods, saved in grayscale JPEG format. Although the Hubble source catalog itself includes MatchID for deduplication, Orion et al. chose to perform deduplication only after classification to preserve structural information of interacting systems or multi-nucleus merging galaxies. The researchers followed the same strategy to ensure that the training set did not contain different slices from the same source.
In addition, in deep observations of certain compact star fields, such as the Andromeda Galaxy, the Magellanic Cloud, or globular clusters, dense point sources may be merged into a single "extended source" by software, thus forming a special type of image artifact.Researchers identified such cases in subsequent active learning and used annotation-guided models to classify them as low-scoring anomalous objects.To improve data access efficiency, all approximately 99.6 million slices are stored in blocks across approximately one thousand HDF5 files.
In constructing the training set, the researchers initially targeted edge-aligned protoplanetary disks. Therefore, as shown in the figure below, the initial training data contained only 3 such anomalous samples, 128 labeled normal samples, and a large number of unlabeled images. The normal samples were obtained through random sampling from the entire database and manual screening, covering isolated galaxies, star fields, and common artifacts.
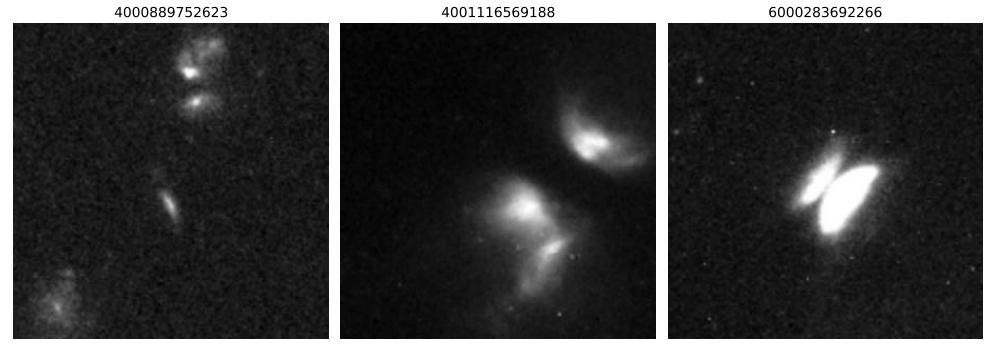
However, with the introduction of active learning,The high-confidence candidate objects given by the model were quickly expanded to other celestial bodies with special shapes and research value.Using this, the researchers gradually built and expanded a more generalized training set, which eventually included 1,400 labeled images, of which 375 were anomalous and 1,025 were normal. The anomalous samples mainly included merging galaxies (178) and gravitational lensing systems (63).

Despite the increasing diversity and size of the training set, researchers failed to discover any new edge-aligned protoplanetary disks in the F814W data. This is primarily due to two reasons: first, such objects are extremely rare in this observation band; and second, as other anomaly types were gradually incorporated into the training set, the few known protoplanetary disk samples became part of the training data, reducing the probability of them being considered "unknown" anomalies and being re-detected. This process also reflects the actual path of this method's evolution from a specific target search tool to a general anomaly detection framework.
AnomalyMatch: An interactive and efficient anomaly detection framework combining semi-supervised and active learning.
AnomalyMatch is a machine learning framework developed by researchers to address the challenge of detecting rare celestial objects in large-scale astronomical datasets. The core innovation of this method lies in…It explicitly defines anomaly detection as an extremely imbalanced binary classification problem and creatively combines semi-supervised learning with an active learning loop.This enables the efficient discovery of potential rare targets in massive amounts of unlabeled data, relying on only a very small number of known anomalous samples.
As shown in the figure below, the design of this model is based on advanced semi-supervised learning paradigms such as FixMatch. Its backbone uses labeled and unlabeled data from the user dataset to train the EfficientNet architecture in order to balance computational efficiency and feature extraction capability.The overall framework comprises two collaborative learning components: the supervised learning part employs focal loss combined with a dynamic weighting strategy.It also implements intelligent oversampling for rare anomaly categories to effectively alleviate training bias caused by extreme class imbalance;The unsupervised part generates high-confidence pseudo-labels through weakly enhanced images.Furthermore, a consistency regularization constraint is imposed on the strongly enhanced version, forcing the model to learn robust morphological representations in the data, rather than relying on surface artifacts.
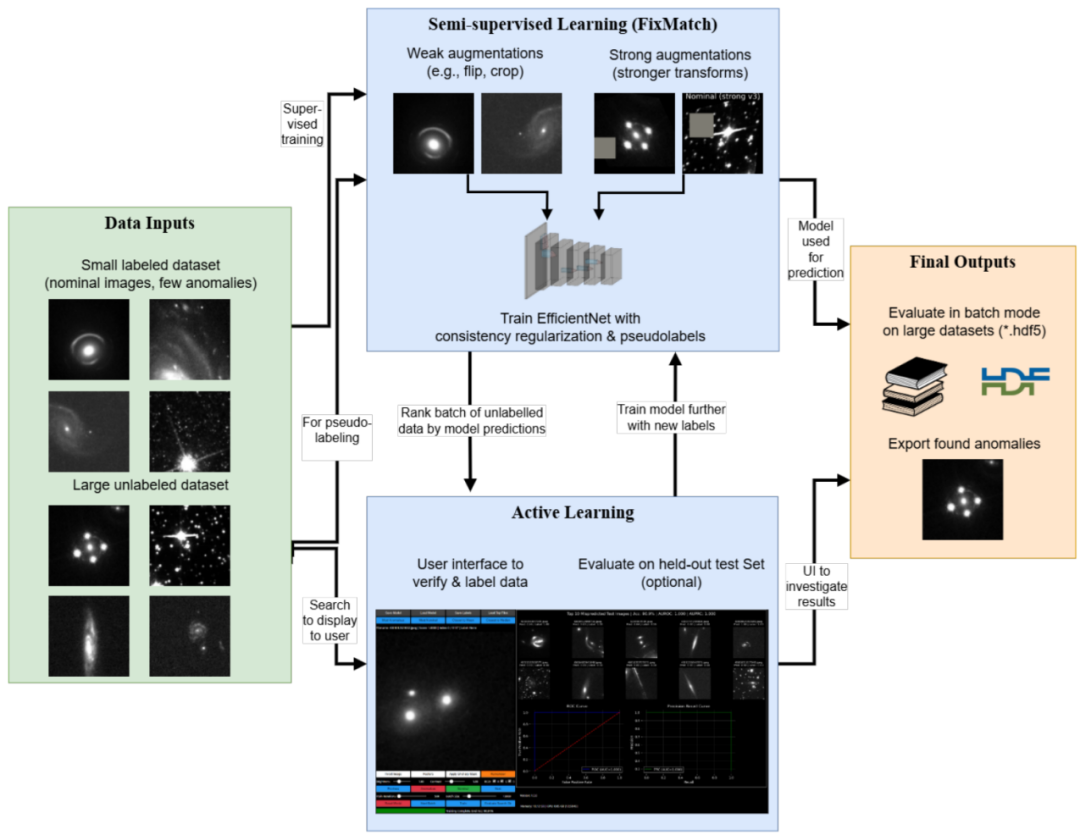
In terms of training mechanism, the model adopts a phased optimization strategy.In the initial stage, a small number of labeled samples are used for supervised warm-up, and then unlabeled data and its pseudo-labels are gradually introduced for semi-supervised training.After each round of training, the model infers the entire unlabeled dataset and outputs an "anomaly score" for each sample. This score is based on the model's prediction confidence in the anomaly category and its ranking reliability is enhanced through a calibration strategy.
Crucially, AnomalyMatch seamlessly integrates an interactive active learning workflow. This workflow presents the candidate samples with the highest model prediction scores to domain experts through a web interface designed specifically for astronomical image review. Experts can quickly classify, label, or eliminate samples, and the validation results are fed back to the training loop in real time. The newly confirmed samples not only expand the label set, but their annotation information is also used to dynamically adjust class weights and pseudo-label thresholds, thus forming a self-reinforcing closed loop of "model recommendation - expert confirmation - model iteration".
For the Hubble Heritage Archive, which contains approximately 100 million source cuts, the model completes a single round of full data inference in just about 2.5 days, and supports breakpoint resume and incremental updates.In practical applications, this framework has not only successfully discovered a large number of new rare celestial objects such as merging galaxies, gravitational lensing, and jellyfish galaxies, but also identified several unique systems that have not yet been documented in the literature. Its high efficiency and strong generalization ability fully demonstrate the key value of such hybrid intelligent frameworks in processing next-generation ultra-large-scale sky survey data.
1,339 unusual celestial objects discovered in the Hubble Heritage Archive
After completing the model training, the study applied it to the entire Hubble Heritage Archive dataset to systematically search for and classify anomalous celestial objects.
First, the researchers rigorously deduplicated the 5,000 candidate samples with the highest anomaly scores in the model output. Specifically, they cross-matched the samples with their source IDs against the Hubble source catalog, extracted their coordinates, and then performed an aggressive radial matching with a radius of 10 arcseconds. Since the probability of two independent anomalous objects co-occurring within such a small angular distance is extremely low, this method effectively eliminates duplicate image cuts caused by data fragmentation. After this step, the result is shown in the figure below.The researchers obtained 1,339 unique anomalous candidates, which in itself intuitively reflects the high repetition rate problem present in the original dataset.
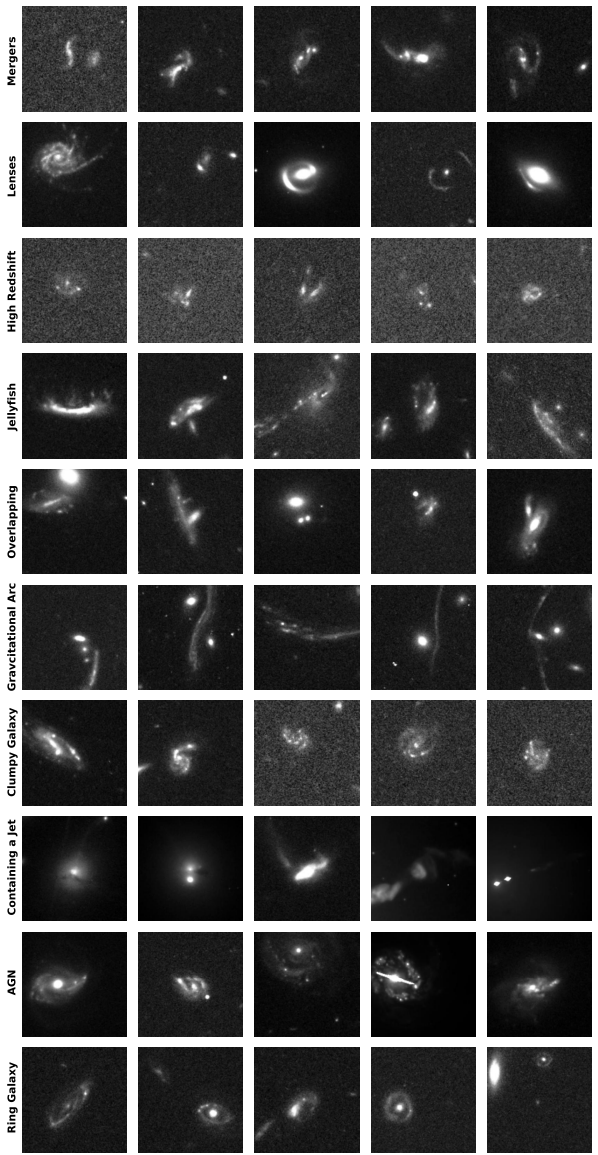
Subsequently, domain experts, based on morphological analysis and literature searches in databases such as SIMBAD and ESASky, meticulously subclassified each of the 1,339 unique samples. The classification results showed that...Merging or interacting galaxies are the most frequently discovered category, totaling 629 independent systems, accounting for approximately 501 TP3T of the total.
This is partly due to the fact that such celestial bodies are relatively common anomalous types, and partly due to their strong tidal interactions, which give them a very unique morphology that is easily captured by models. It is worth noting that researchers have limited field of view for their plots, so some highly perturbative late-stage merger systems may appear as single objects in the images, and their merger properties need to be further confirmed by adjusting the field of view or consulting the literature.
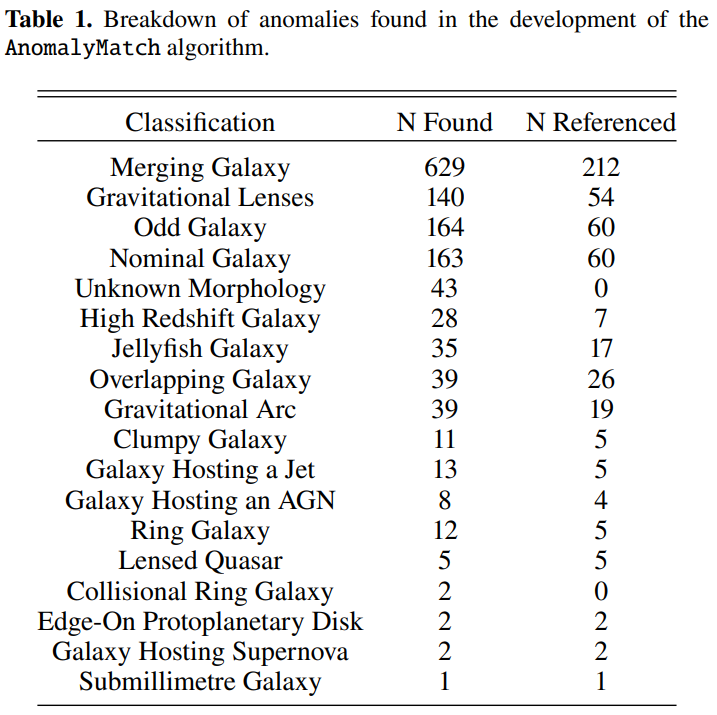
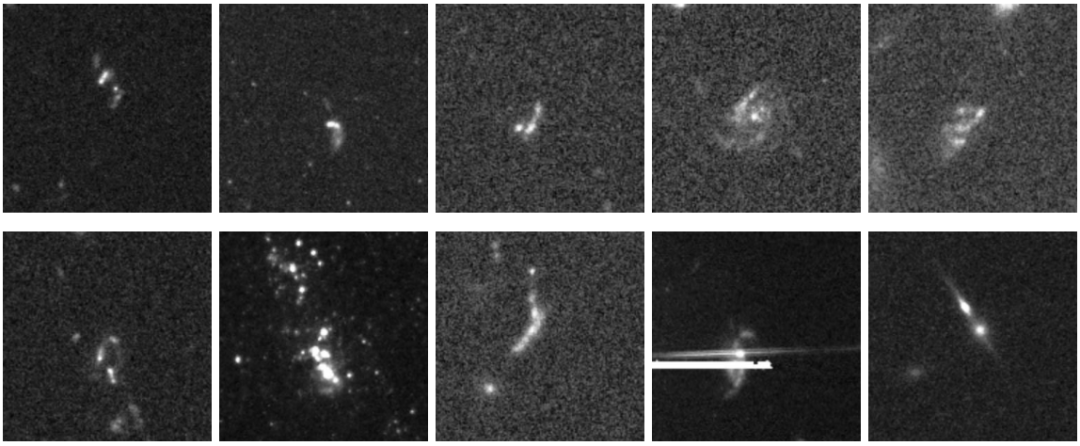
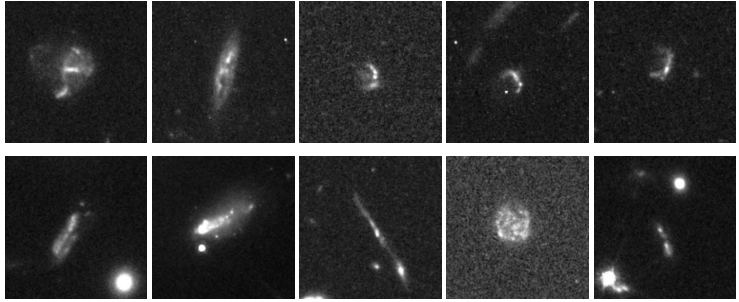
Gravitational lensing and related phenomena constitute the second major category of anomaly discoveries. Researchers identified a significant number of strong gravitational lensing candidates, including several known lensing systems and a large number of new potential candidates. Furthermore, they distinguished 39 gravitational arcs, typically generated by foreground galaxy clusters, whose scale often exceeds the scope of a single tilde and appears in the data as only a fragment of a giant arc of light. The model also successfully detected a group of high-redshift galaxies, which appear in the images as low signal-to-noise ratio, dense, and slightly disordered blotches, consistent with the observational characteristics of such objects.
In other categories, researchers discovered 35 jellyfish galaxies that met strict criteria (all located in galaxy clusters and exhibiting leading-edge bow shocks and stripping trails), 11 clump galaxies, and a similar number of overlapping galaxies. Notably, the model, without any specific training, demonstrated remarkable generalization ability in recognizing morphological features.Several quasar lenses (characterized by structures such as the "Einstein cross") and 13 relativistic jet host galaxies, which are quite rare in the optical band, were successfully discovered.This demonstrates that AnomalyMatch can transfer learned knowledge and detect anomalous subtypes that have not appeared in the training set.
In addition to the clearly categorized members mentioned above, the final catalog also includes three general categories: "Special Galaxies" refers to celestial objects with significantly irregular shapes that do not conform to any existing subcategories; "Normal Galaxies" represents false positives (approximately 10%) where the model's judgment is incorrect, mainly including isolated galaxies with slight structural perturbations, dense star fields, or instrument artifacts; and "Unknown Galaxies" covers 43 peculiar targets that cannot currently be classified based on existing knowledge, leaving open room for future research.
AI is reshaping modern astronomy
Faced with the data tsunami brought about by the next generation of large-scale sky surveys, global astronomical research is undergoing a profound paradigm shift.
In academia, one of the research focuses is on how to enable machines to more intelligently understand the complex temporal and state changes in astronomical data. For example, a research team from the University of Toronto, Imperial College London, and the Harvard-Smithsonian Centre for Astrophysics has developed a new method based on continuous-space hidden Markov models to automatically identify and separate different physical states of astronomical sources.
In simple terms, this method models stellar activity as a series of hidden, continuously changing states. AI By analyzing the multi-band light change curves captured by the telescope, it is possible to intelligently infer the physical state of a celestial body at every moment.The research team applied this algorithm to an active flare star called EV Lac. The AI successfully distinguished between different states, such as "quiet" and "flare," from its X-ray data and accurately quantified the characteristics of the eruptive events.
Paper Title:
Separating states in astronomical sources using hidden Markov models: with a case study of flaring and quiescence on EV Lac
Paper link:https://doi.org/10.1093/mnras/stae2082
At the same time, the business community is participating in this astronomical data revolution in unprecedented ways, no longer merely as a technology provider, but as a designer, builder, and operator of scientific missions. A prime example is Open Cosmos, a leading European space technology company. In 2024, the company partnered with the Catalan Space Institute...The company formally designed and built its first satellite platform dedicated to astrophysical research, "PhotSat".This small but powerful CubeSat will carry two telescopes and is planned to scan the entire sky in the visible and ultraviolet bands every two days, continuously monitoring the changes in tens of millions of the brightest stars. Its scientific goals are very clear: to provide a valuable data stream for key research such as the search for exoplanets, characterizing stellar properties, and capturing supernova explosions.
Whether it's the Hidden Markov Models developed in university laboratories that can gain insights into the deep state of data, or the astrophysical satellites built by commercial space companies dedicated to achieving specific scientific goals, their core driving force is coping with the exponential growth in data scale and complexity. It is foreseeable that with the commissioning of new-generation facilities such as the Rubin Observatory and the Roman Space Telescope, this dual-engine model of "intelligent algorithms + innovative platforms" will become more prevalent, propelling astronomy from hypothesis-driven to a new era driven by both data and algorithms, enabling more efficient discovery of rare and precious cosmic mysteries in the vast universe.
Reference Links:
1.https://www.electronicsweekly.com/news/business/open-cosmos-to-develop-astrophysical-satellite-2024-10/








