HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Skalierung von Mixture-of-Experts-Videovortraining für verkörperte Intelligenz

LAME M-VLA: DUALES LATENTES GEDÄCHTNIS IN VISION-LANGUAGE-ACTION-MODELLEN FÜR ROBOTISCHE MANIPULATION



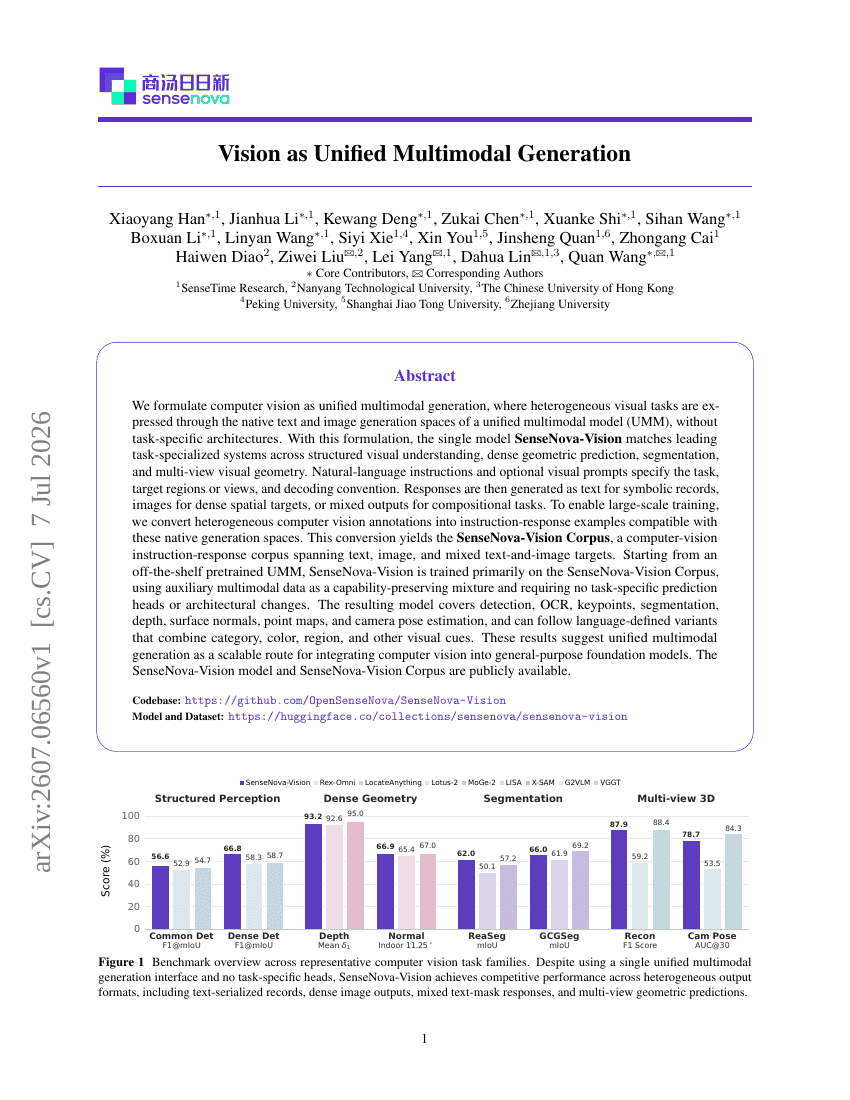
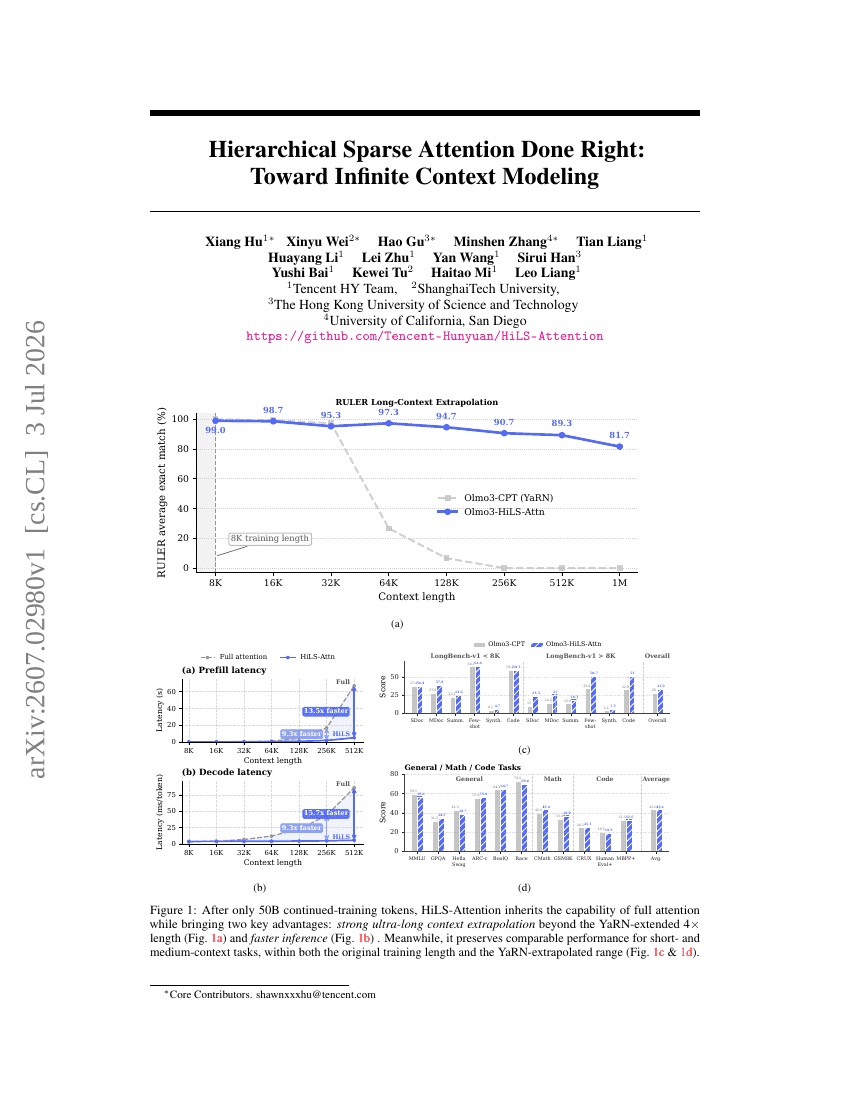



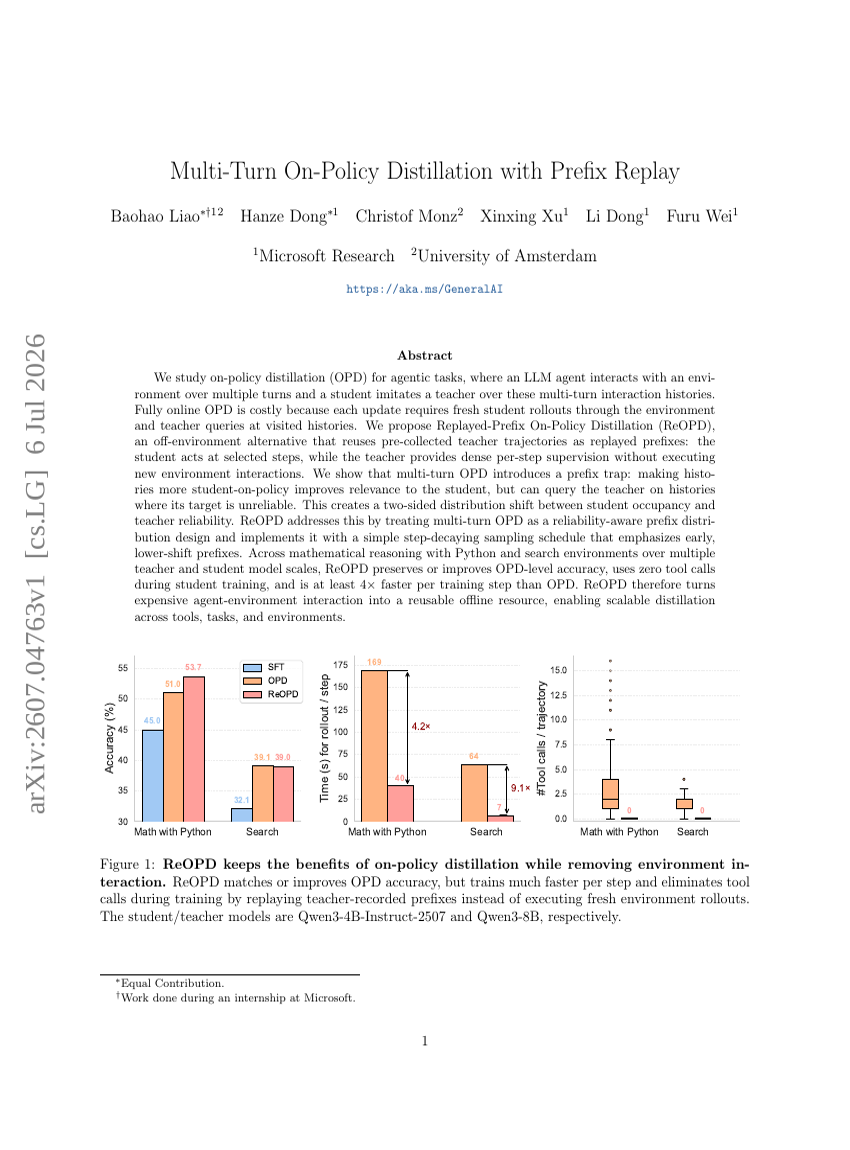





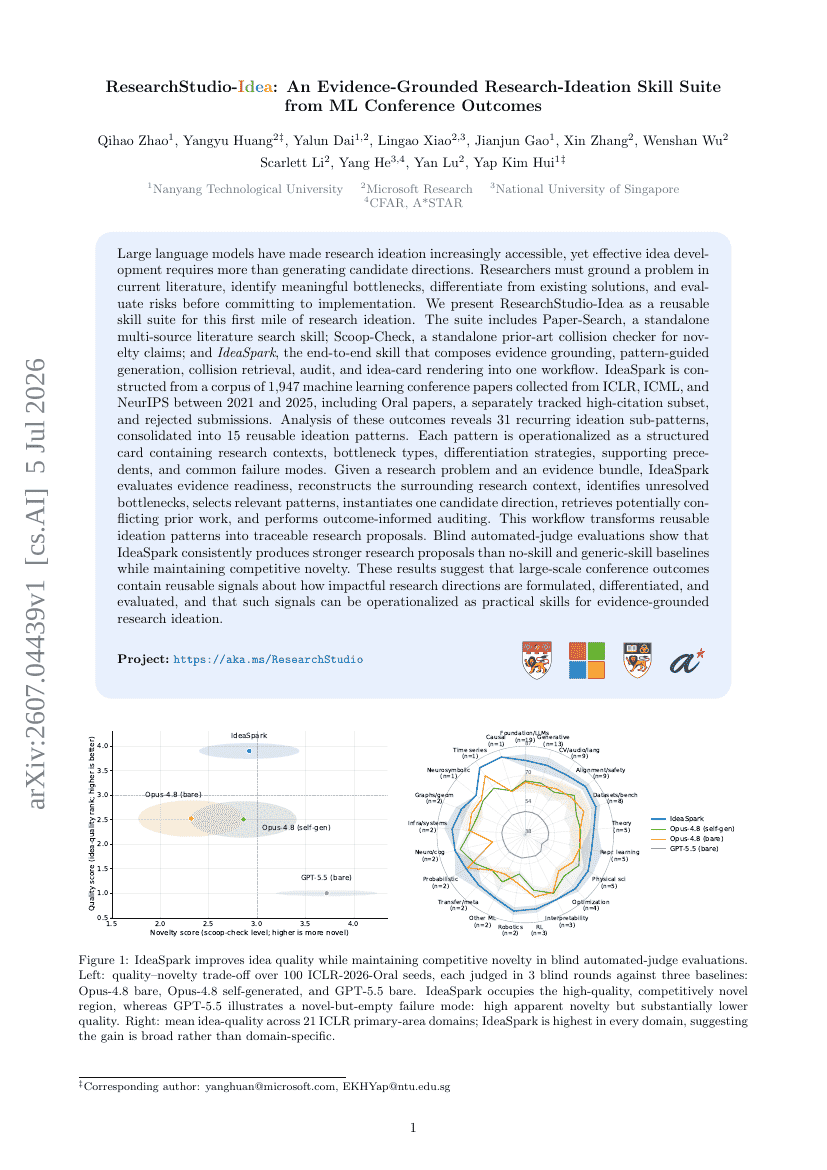







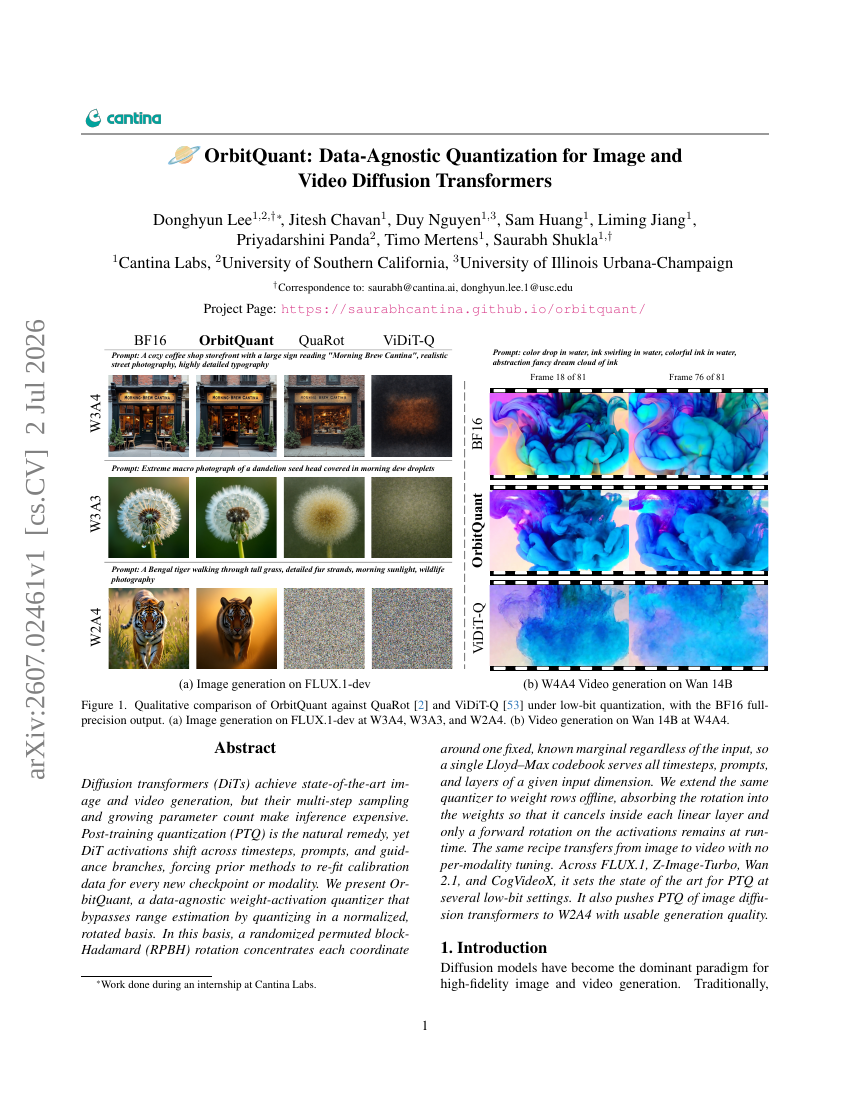







Skalierung von Mixture-of-Experts-Videovortraining für verkörperte Intelligenz
LAME M-VLA: DUALES LATENTES GEDÄCHTNIS IN VISION-LANGUAGE-ACTION-MODELLEN FÜR ROBOTISCHE MANIPULATION
Akkurate, interdisziplinäre und transparente Struktur-Eigenschafts-Verständnis durch tiefes natives strukturelles Reasoning
Parallelisierte autoregressive Dekodierung für omnimodale dichte Videountertitelung
Light-Omni: Reflex statt logisches Denken im agentenbasierten Videoverständnis mit Langzeitgedächtnis
Vision als vereinheitlichte multimodale Generierung
Hierarchische sparse Attention richtig gemacht: Auf dem Weg zur Modellierung unendlicher Kontexte
AlayaWorld: Generierung von Langzeithorizontund spielbaren Videowelten
RynnWorld-4D: 4D-verkörperte Weltmodelle für robotische Manipulation
Nemotron-Labs-3-Puzzle-75B-A9B: Komprimierung hybrider MoE-LLMs
Multi-Turn On-Policy Destillation mit Präfix-Wiederholung
Gemma 4 Technischer Bericht
UI-MOPD: Multi-Plattform On-Policy Destillation für kontinuierliches Lernen von GUI-Agenten
Wan-Streamer v0.2: Höhere Auflösung, gleiche Latenz
EVA-Client: Ein einheitliches Framework für Deployment, Evaluation und Datenerfassung auf realen Robotern
GigaWorld-1: Ein Fahrplan zur Entwicklung von Weltmodellen für die Bewertung von Roboterrichtlinien
ResearchStudio-Idea: Eine evidenzbasierte Forschungsideen-Fähigkeitssuite aus ML-Konferenzergebnissen
ResearchStudio-Reel: Automatisierung der letzten Meile der Forschung vom Paper zu Poster, Video und Blog
FINAL Bench: Messung funktionalen metakognitiven Schließens in großen Sprachmodellen
SceneFun3D: Fein granulare Funktionalitätsund Affordanzverständnis in 3D-Szenen
TheoremGraph: Überbrückung formaler und informeller Mathematik
Always-On-Agenten: Ein Überblick über persistenten Speicher, Zustand und Governance in LLM-Agenten
Absicherung des KI-Agenten: Ein einheitliches Rahmenwerk für mehrschichtiges Agenten-Red-Teaming
DataComp-VLM: Verbesserte offene Datensätze für Vision-Language-Modelle
OrbitQuant: Datenunabhängige Quantisierung für Bildund Video-Diffusion-Transformer
VLA-Corrector: Leichtgewichtige Erkennungs-und-Korrektur-Inferenz für adaptiven Aktionshorizont
Embodied.cpp: Eine portable Inferenzlaufzeitumgebung für Embodied-AI-Modelle auf heterogenen Robotern
Die Fata Morgana der Optimierung von Trainingspolicies: Monotone Inferenz-Policies als das eigentliche Ziel für das bestärkende Lernen von LLMs
GeneBench-Pro: Evaluierung mehrstufigen statistischen Denkens in Genomik, quantitativer Biologie und translationaler Biomedizin
Positionspapier: KI/ML-Deepfake-Forschung ist nicht auf KI-generierte nicht-einvernehmliche intime Bildinhalte (AIG-NCII) ausgerichtet
Grokking verstehen: Nachweisbares Grokking in der Ridge-Regression
Eine Perspektive der Zufallsmatrizentheorie auf die Konsistenz von Diffusionsmodellen
Akkurate, interdisziplinäre und transparente Struktur-Eigenschafts-Verständnis durch tiefes natives strukturelles Reasoning
Parallelisierte autoregressive Dekodierung für omnimodale dichte Videountertitelung
Light-Omni: Reflex statt logisches Denken im agentenbasierten Videoverständnis mit Langzeitgedächtnis
Vision als vereinheitlichte multimodale Generierung
Hierarchische sparse Attention richtig gemacht: Auf dem Weg zur Modellierung unendlicher Kontexte
AlayaWorld: Generierung von Langzeithorizontund spielbaren Videowelten
RynnWorld-4D: 4D-verkörperte Weltmodelle für robotische Manipulation
Nemotron-Labs-3-Puzzle-75B-A9B: Komprimierung hybrider MoE-LLMs
Multi-Turn On-Policy Destillation mit Präfix-Wiederholung
Gemma 4 Technischer Bericht
UI-MOPD: Multi-Plattform On-Policy Destillation für kontinuierliches Lernen von GUI-Agenten
Wan-Streamer v0.2: Höhere Auflösung, gleiche Latenz
EVA-Client: Ein einheitliches Framework für Deployment, Evaluation und Datenerfassung auf realen Robotern
GigaWorld-1: Ein Fahrplan zur Entwicklung von Weltmodellen für die Bewertung von Roboterrichtlinien
ResearchStudio-Idea: Eine evidenzbasierte Forschungsideen-Fähigkeitssuite aus ML-Konferenzergebnissen
ResearchStudio-Reel: Automatisierung der letzten Meile der Forschung vom Paper zu Poster, Video und Blog
FINAL Bench: Messung funktionalen metakognitiven Schließens in großen Sprachmodellen
SceneFun3D: Fein granulare Funktionalitätsund Affordanzverständnis in 3D-Szenen
TheoremGraph: Überbrückung formaler und informeller Mathematik
Always-On-Agenten: Ein Überblick über persistenten Speicher, Zustand und Governance in LLM-Agenten
Absicherung des KI-Agenten: Ein einheitliches Rahmenwerk für mehrschichtiges Agenten-Red-Teaming
DataComp-VLM: Verbesserte offene Datensätze für Vision-Language-Modelle
OrbitQuant: Datenunabhängige Quantisierung für Bildund Video-Diffusion-Transformer
VLA-Corrector: Leichtgewichtige Erkennungs-und-Korrektur-Inferenz für adaptiven Aktionshorizont
Embodied.cpp: Eine portable Inferenzlaufzeitumgebung für Embodied-AI-Modelle auf heterogenen Robotern
Die Fata Morgana der Optimierung von Trainingspolicies: Monotone Inferenz-Policies als das eigentliche Ziel für das bestärkende Lernen von LLMs
GeneBench-Pro: Evaluierung mehrstufigen statistischen Denkens in Genomik, quantitativer Biologie und translationaler Biomedizin
Positionspapier: KI/ML-Deepfake-Forschung ist nicht auf KI-generierte nicht-einvernehmliche intime Bildinhalte (AIG-NCII) ausgerichtet
Grokking verstehen: Nachweisbares Grokking in der Ridge-Regression
Eine Perspektive der Zufallsmatrizentheorie auf die Konsistenz von Diffusionsmodellen