HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Deep Learning in der Fernerkundung: Ein Überblick

Ein regressionsbasierter Ansatz zur Sprachverbesserung mittels tiefer neuronaler Netze

























Deep Learning in der Fernerkundung: Ein Überblick
Ein regressionsbasierter Ansatz zur Sprachverbesserung mittels tiefer neuronaler Netze
Tiefe neuronale Netze für die akustische Modellierung in der Spracherkennung
RoboTTT: Kontextskalierung für Roboterrichtlinien
SWE-agent: Agent-Computer-Schnittstellen ermöglichen automatisierte Softwareentwicklung
Effiziente Schätzung von Wortrepräsentationen im Vektorraum
Tiefenkartenvorhersage aus einem Einzelbild mit einem mehrskaligen tiefen Netzwerk
TabNet: Aufmerksames interpretierbares tabellarisches Lernen
AudioPaLM: Ein großes Sprachmodell, das sprechen und zuhören kann
SQuAD: Über 100.000 Fragen für maschinelles Textverständnis
DeepPose: Schätzung menschlicher Körperhaltungen mittels tiefer neuronaler Netze
Selbstverbesserungen in modernen agentischen Systemen: Ein Überblick
Single-Rollout Asynchrone Optimierung für agentisches Reinforcement Learning
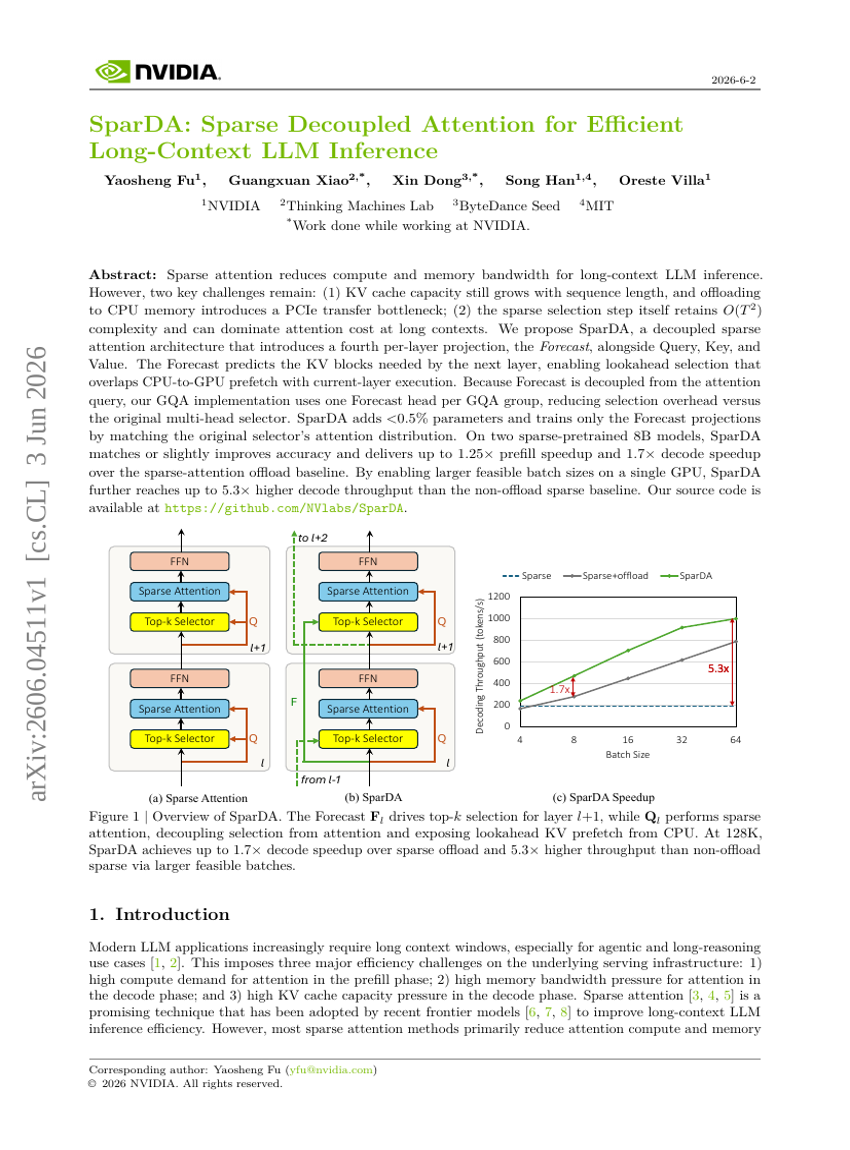
SparDA: Sparse Decoupled Attention für effiziente Inferenz bei langen Kontexten in LLMs
MetaView: Monokulare Neuansichtssynthese mit maßstabsbewussten impliziten Geometrie-Priors
PolicyShiftGuard: Benchmarking und Verbesserung von policy-adaptiven Bildschutzmechanismen
KnowAct-GUIClaw: Tief verstehen, perfekt handeln – Persönlicher GUI-Assistent mit selbstentwickelndem Gedächtnis und Fertigkeiten
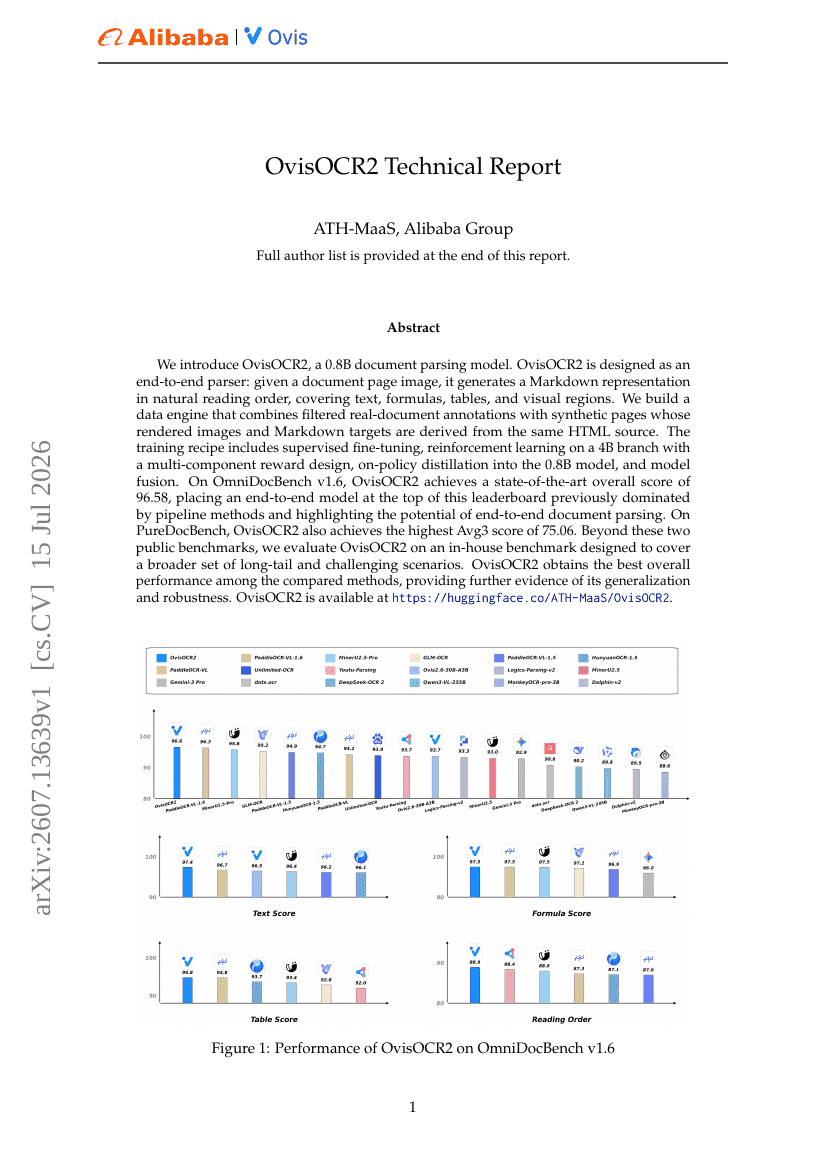
OvisOCR2 Technischer Bericht
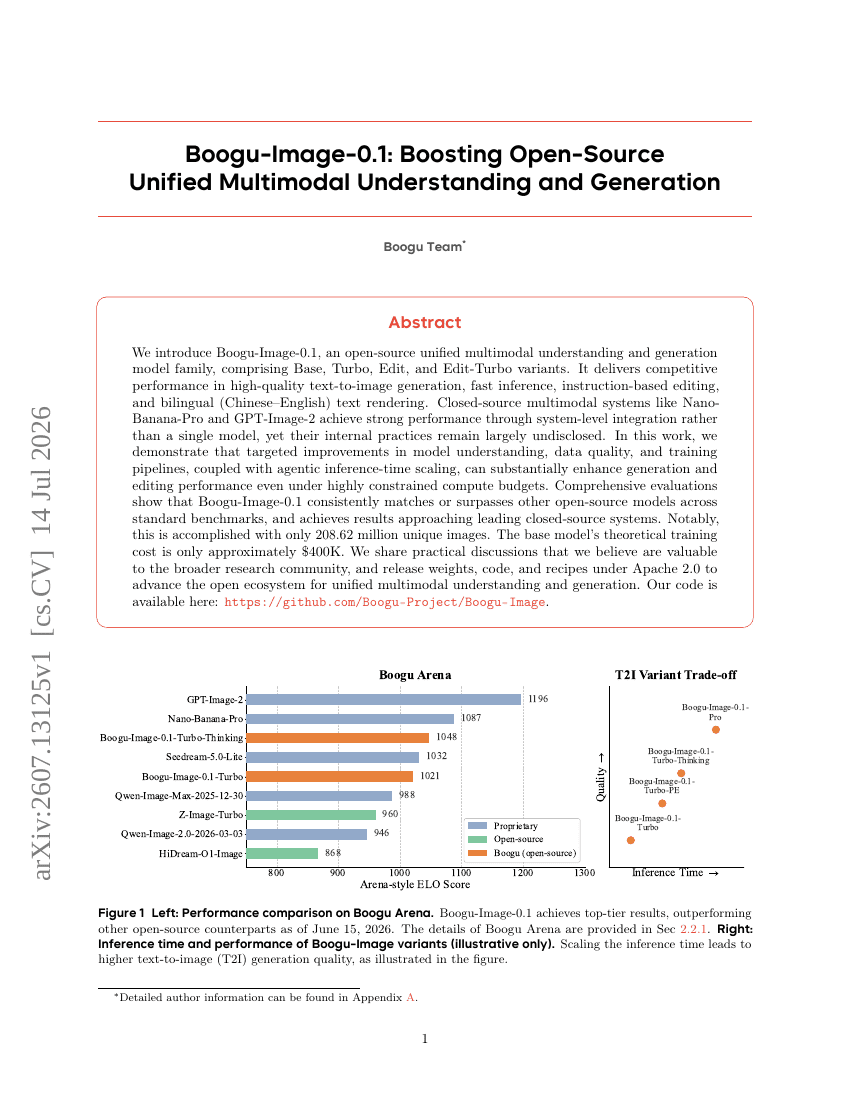
Boogu-Image-0.1: Förderung quelloffener, vereinheitlichter multimodaler Verständnisund Generierungsmodelle
Harness Handbook: Entwicklung von Agenten-Harnesses lesbar, navigierbar und editierbar machen
Qwen-Music Technischer Bericht
Spektrale Neuverdrahtung für Exploration, Bereinigung und Modellfusion
Die Evaluation der Harness-Evolution für Agenten neu denken
Ring-Zero: Skalierung von Zero RL auf eine Billion Parameter für emergentes Reasoning
Die Kluft zwischen latentem und explizitem Denken mit geloopten Transformern überbrücken
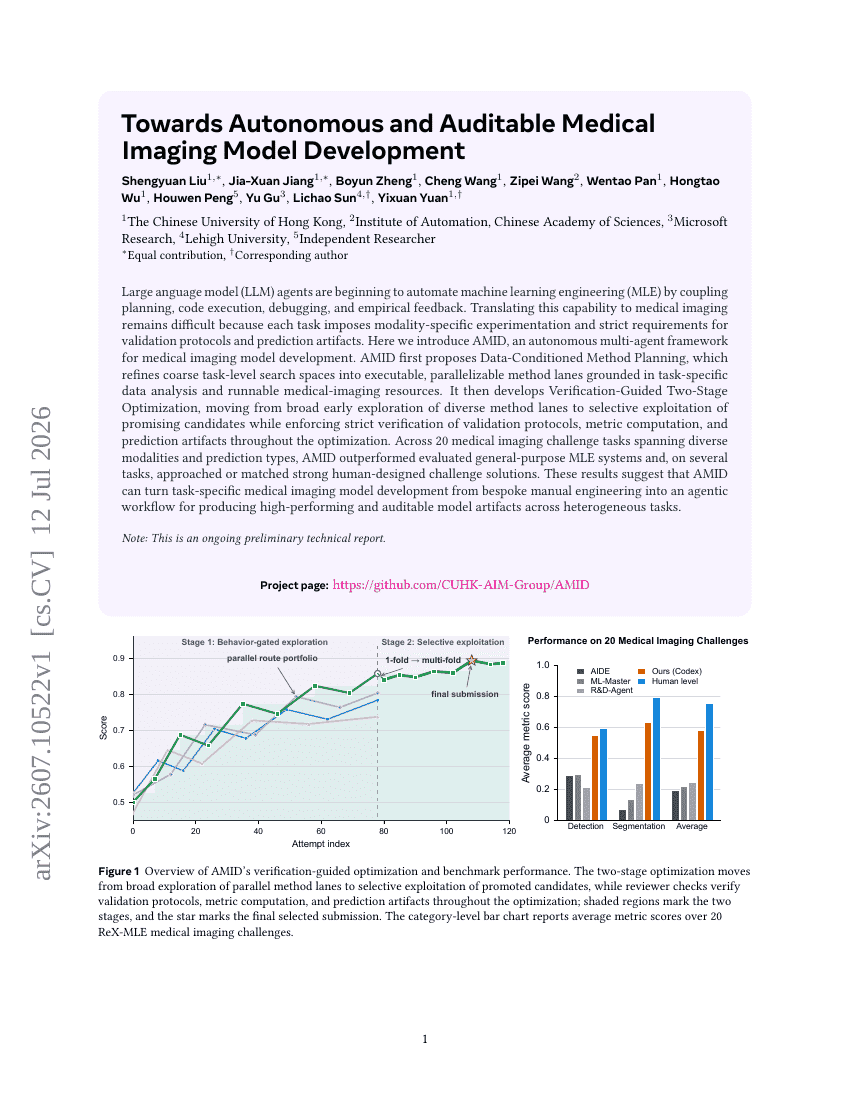
Auf dem Weg zu autonomer und prüfbarer Entwicklung medizinischer Bildgebungsmodelle
MUSCRIPTOR: EIN OFFENES MODELL FÜR DIE TRANSKRIPTION VON MUSIK MIT MEHREREN INSTRUMENTEN
Prinzipiengeleitete Analyse von Evaluationsund Designparadigmen des tiefen bestärkenden Lernens
Wissen vor der Lösung: QA-gesteuerte Wissensakquise aus Repositories für die Behebung von Softwareproblemen
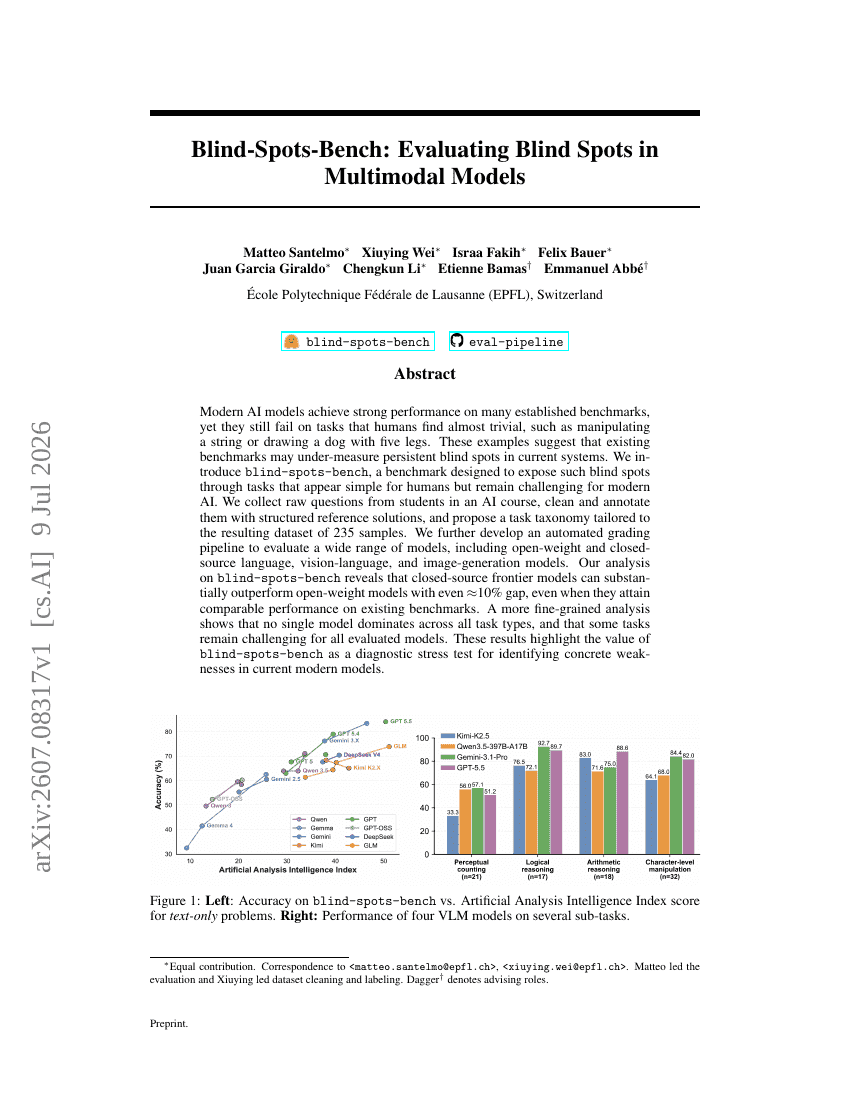
Blind-Spots-Bench: Evaluierung blinder Flecken in multimodalen Modellen
Read It Back: Vortrainierte MLLMs sind Zero-Shot-Belohnungsmodelle für die Text-zu-Bild-Generierung
Die Rolle der Strenge in der Künstlichen Intelligenz
Tiefe neuronale Netze für die akustische Modellierung in der Spracherkennung
RoboTTT: Kontextskalierung für Roboterrichtlinien
SWE-agent: Agent-Computer-Schnittstellen ermöglichen automatisierte Softwareentwicklung
Effiziente Schätzung von Wortrepräsentationen im Vektorraum
Tiefenkartenvorhersage aus einem Einzelbild mit einem mehrskaligen tiefen Netzwerk
TabNet: Aufmerksames interpretierbares tabellarisches Lernen
AudioPaLM: Ein großes Sprachmodell, das sprechen und zuhören kann
SQuAD: Über 100.000 Fragen für maschinelles Textverständnis
DeepPose: Schätzung menschlicher Körperhaltungen mittels tiefer neuronaler Netze
Selbstverbesserungen in modernen agentischen Systemen: Ein Überblick
Single-Rollout Asynchrone Optimierung für agentisches Reinforcement Learning
SparDA: Sparse Decoupled Attention für effiziente Inferenz bei langen Kontexten in LLMs
MetaView: Monokulare Neuansichtssynthese mit maßstabsbewussten impliziten Geometrie-Priors
PolicyShiftGuard: Benchmarking und Verbesserung von policy-adaptiven Bildschutzmechanismen
KnowAct-GUIClaw: Tief verstehen, perfekt handeln – Persönlicher GUI-Assistent mit selbstentwickelndem Gedächtnis und Fertigkeiten
OvisOCR2 Technischer Bericht
Boogu-Image-0.1: Förderung quelloffener, vereinheitlichter multimodaler Verständnisund Generierungsmodelle
Harness Handbook: Entwicklung von Agenten-Harnesses lesbar, navigierbar und editierbar machen
Qwen-Music Technischer Bericht
Spektrale Neuverdrahtung für Exploration, Bereinigung und Modellfusion
Die Evaluation der Harness-Evolution für Agenten neu denken
Ring-Zero: Skalierung von Zero RL auf eine Billion Parameter für emergentes Reasoning
Die Kluft zwischen latentem und explizitem Denken mit geloopten Transformern überbrücken
Auf dem Weg zu autonomer und prüfbarer Entwicklung medizinischer Bildgebungsmodelle
MUSCRIPTOR: EIN OFFENES MODELL FÜR DIE TRANSKRIPTION VON MUSIK MIT MEHREREN INSTRUMENTEN
Prinzipiengeleitete Analyse von Evaluationsund Designparadigmen des tiefen bestärkenden Lernens
Wissen vor der Lösung: QA-gesteuerte Wissensakquise aus Repositories für die Behebung von Softwareproblemen
Blind-Spots-Bench: Evaluierung blinder Flecken in multimodalen Modellen
Read It Back: Vortrainierte MLLMs sind Zero-Shot-Belohnungsmodelle für die Text-zu-Bild-Generierung
Die Rolle der Strenge in der Künstlichen Intelligenz