Command Palette
Search for a command to run...
Meta Stellt KI-Datenwissenschaftler Bereit, Und Autodata Erstellt Hochwertige Trainings-/Evaluierungsdatensätze.

Die kontinuierliche Verbesserung der Leistungsfähigkeit groß angelegter Modelle hat in den letzten Jahren die Entwicklung der künstlichen Intelligenz maßgeblich beeinflusst. Es herrscht jedoch zunehmend Einigkeit darüber, dass sich die Grenzen der Modellleistung von „algorithmusgetrieben“ hin zu „datenqualitätsgetrieben“ verschieben. Angesichts der immer knapper werdenden und kostspieligeren Verfügbarkeit hochwertiger, manuell annotierter Daten gewinnen synthetische Daten in der Nachschulungsphase zunehmend an Bedeutung. Sie können Randfälle und seltene Szenarien generieren, die in realen Korpora relativ selten vorkommen; die manuelle Annotation vereinfachen und beschleunigen; und in manchen Fällen Trainingsdaten mit komplexeren Verteilungen als menschliche Daten erzeugen.
Mit dem Aufkommen großer Sprachmodelle (LLMs) wurde „Selbstinstruktion“ als Methode zur Generierung synthetischer Daten mithilfe von Zero-Shot- oder Few-Shot-Prompts vorgeschlagen. Darauf aufbauend integriert „Grounded Self-Instruction“ zusätzlich externe Quellen wie Dokumente als Randbedingungen, um Illusionen zu reduzieren und die Diversität zu erhöhen. Darüber hinaus führt „CoT Self-Instruction“ kettenartiges Schließen während des Generierungsprozesses ein, um komplexere und präzisere Aufgaben zu erstellen. Schließlich ermöglicht eine Klasse sogenannter „selbstherausfordernder“ Methoden einem herausfordernden Agenten, mit dem Tool zu interagieren, bevor er die Aufgabe und ihre Bewertungsfunktion vorschlägt. Allerdings kann keine dieser Methoden die Schwierigkeit und Qualität der Daten direkt steuern, was zu Verbesserungsstrategien wie Filterung, Evolution und Verfeinerung führt.
In diesem ZusammenhangDas Meta Basic Artificial Intelligence Research Team (FAIR bei Meta) hat eine allgemeine Methode namens Autodata vorgeschlagen.Alle oben beschriebenen Methoden wurden vereinheitlicht und verallgemeinert. In diesem Rahmen ist ein intelligenter Agent, der als „Data Scientist“ agiert, für die Erstellung und Organisation von Daten verantwortlich und ahmt dabei den Arbeitsablauf eines menschlichen Data Scientists nach, um qualitativ hochwertige Daten zu generieren. Dieser Prozess umfasst nicht nur die anfängliche Datengenerierung, sondern auch die Datenanalyse (ähnlich einer menschlichen Überprüfung), die Bewertung der Leistungsfähigkeit, die Zusammenfassung der gewonnenen Erkenntnisse und die iterative Entwicklung besserer Datenlösungen auf Basis dieser Bewertungen.
Forscher führten Experimente zu Aufgaben in der Informatikforschung, im juristischen Denken und im mathematischen Objektdenken durch und erzielten dabei bessere Ergebnisse als mit herkömmlichen Methoden zur Erzeugung synthetischer Daten. Darüber hinaus führte die Meta-Optimierung des Data-Scientist-Agenten selbst zu noch deutlicheren Leistungsverbesserungen.
Die zugehörigen Forschungsergebnisse mit dem Titel „Autodata: Ein agentischer Datenwissenschaftler zur Erstellung hochwertiger synthetischer Daten“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
* Die agentenbasierte Datengenerierungsmethode bietet einen Weg, um Inferenz-Rechenressourcen in qualitativ hochwertigere Modelltrainingsdaten umzuwandeln.
* Der Data-Scientist-Agent selbst kann auch meta-optimiert werden, was zu signifikanten Leistungsverbesserungen führt, ohne dass menschliche Eingaben oder technische Anpassungen erforderlich sind.
* Diese Forschung hat das Potenzial, die Art und Weise zu verändern, wie zukünftige Aufgaben und Benchmarks gestaltet werden, um die KI-Entwicklung voranzutreiben.

Papieradresse:
https://hyper.ai/papers/2606.25996
Datensatz: Umfasst drei zentrale Aufgabenszenarien
Das Autodata-Framework deckte in den Experimenten drei zentrale Aufgabenszenarien ab: Forschungsprobleme der Informatik, Aufgaben zum juristischen Denken und Aufgaben zum wissenschaftlichen Denken auf der Grundlage mathematischer Objekte.Diese Aufgaben basieren auf unterschiedlichen Datenquellensystemen, um die Generalisierungsfähigkeit des Frameworks unter verschiedenen kognitiven Strukturen zu testen.
Bei Aufgaben im Bereich Informatik,Die Forscher werteten über 10.000 Informatik-Artikel aus dem S2ORC-Korpus (ab 2022) aus.Mithilfe von Agentic Self-Instruct wurden 2.800 akzeptierte Beispiele generiert.Nach Abschluss der Schleife werden diese Stichproben mithilfe eines auf Kimi-K2.6 basierenden Qualitätsvalidators weiter gefiltert, um solche mit Problemen wie dem Durchsickern papierspezifischer Informationen, unzureichendem Kontext oder einem fehlerhaften Bewertungskriterienformat zu entfernen. Schließlich werden 1.300 qualitativ hochwertige Stichproben als Agentic Self-Instruct-Datensatz für das Training von Reinforcement Learning (RL) beibehalten.
Bei Aufgaben zum juristischen Denken,Die Daten stammen aus öffentlich zugänglichen juristischen Dokumenten wie der „Pile of Law“, darunter Gerichtsurteile und Rechtsgutachten, und werden mit PRBench-Legal und dessen schwieriger Unterkategorie PRBench-Legal-Hard ausgewertet. Im Gegensatz zu wissenschaftlichen ArbeitenRechtstexte unterliegen stärkeren strukturierten logischen Zwängen und einer stärkeren Abhängigkeit von der Rechtsprechung, daher liegt der Schwerpunkt bei der Generierungsaufgabe stärker auf der Fähigkeit, Fakten zu extrahieren und Regeln anzuwenden.
Bei Aufgaben zum wissenschaftlichen DenkenDie Forschung basiert auf dem Principia-Datensatz. Dieser wurde mithilfe der CoT-Selbstlernmethode erstellt und deckt ein breites Spektrum an Kursinhalten der MSC2020- und PHYS-Taxonomie ab. Der Principia-Benchmark besteht aus einer von Menschen annotierten Teilmenge bestehender mathematischer und physikalischer Benchmarks. Die Fragen wurden daraufhin überprüft, ob die Antworten mathematische Objekte beinhalten.
Bei allen Aufgaben geht es Autodata nicht einfach nur darum, Frage-Antwort-Paare zu generieren, sondern Trainingsdaten zu erzeugen, die effektiv zwischen schwachen und starken Modellen unterscheiden können.
Autodata: Einsatz autonomer intelligenter Agenten zur Simulation der Rolle von Datenwissenschaftlern.
Der Aufbau von Autodata auf oberster Ebene ist in der folgenden Abbildung dargestellt.Das Framework nutzt einen autonomen intelligenten Agenten, um die Rolle eines Datenwissenschaftlers zu simulieren.Durch iterative Datengenerierung, Durchführung qualitativer Prüfungen und quantitativer Leistungsbewertungen, umfassende Analyse der gewonnenen Erkenntnisse und entsprechende Aktualisierung der Datengenerierungsmethode können auf dieser Vorlage verschiedene Implementierungsformen aufgebaut werden.
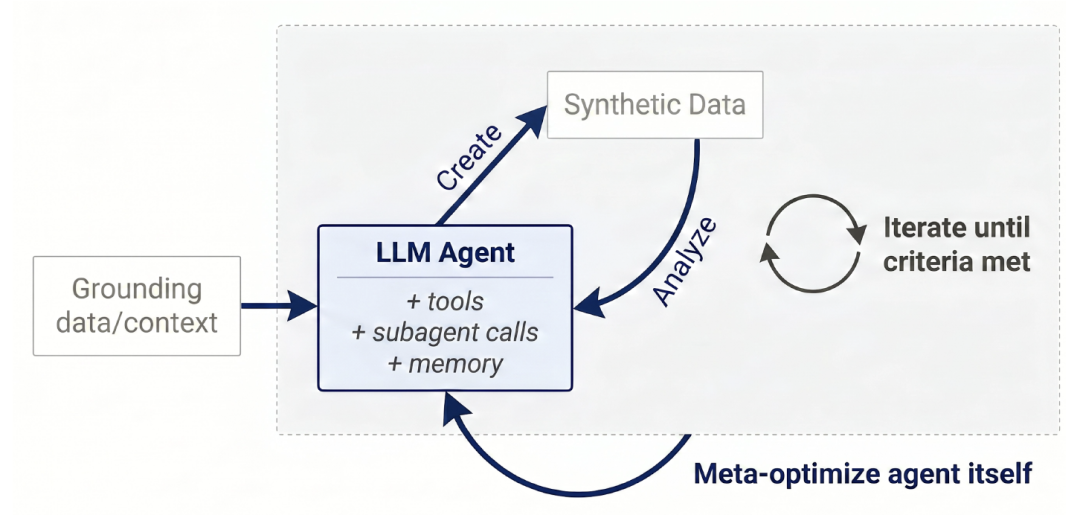
Autodata-Workflow
Der gesamte Kreislauf besteht aus folgenden Komponenten:
① Datenerstellung
Der Autodata-Agent nutzt bereitgestellte Daten (z. B. spezifische Dokumente aus Bereichen wie Mathematik, Recht oder Programmierung oder andere aufgabenspezifische Datenquellen), um die Datengenerierung zu unterstützen. Dieser Agent kann Werkzeuge oder seine vorhandenen Fähigkeiten und Erfahrungen einsetzen und Rechenressourcen aus der Inferenzphase nutzen, um Trainings- und Benchmark-Daten für das Modelltraining oder die Evaluierung zu generieren. Dieser Datengenerierungsschritt kann nach der anschließenden Analyse und dem Lernprozess wiederholt werden, wodurch die Datenqualität kontinuierlich verbessert wird.
② Datenanalyse
Nachdem das System die vom Agenten generierten Daten erhalten hat, analysiert es diese, um zusammenzufassen, was gut und was schlecht lief und wie es weiter verbessert werden kann. Diese Analyse kann auf verschiedenen Ebenen erfolgen: auf der Ebene eines einzelnen Beispiels (z. B. Beurteilung, ob ein Beispiel korrekt, qualitativ hochwertig oder ausreichend anspruchsvoll ist) oder auf der Ebene des gesamten Datensatzes (z. B. ob die Beispiele vielfältig sind und ob sie als Trainingsdaten die Modellleistung verbessern können). Die Ergebnisse dieser Analysen fließen zurück in die Datengenerierungsphase, wodurch in der nächsten Iteration bessere Daten generiert werden, bis die Abbruchbedingung erfüllt ist.
③ Gesamtprozess für Datenwissenschaftler
Der Agent durchläuft kontinuierlich einen Zyklus aus Datengenerierung und Datenanalyse, bis er mit der Datenqualität zufrieden ist und schließlich einen hochwertigen Trainingsdatensatz oder Benchmark generiert. Spezielle Sicherheits- oder Beschränkungsmechanismen können in die äußere Schleife integriert werden, um das System vor Hackerangriffen zu schützen. Diese agentenbasierte Schleife ermöglicht es dem Modell, seine Lernergebnisse während des gesamten Prozesses kontinuierlich zu sammeln und zu nutzen.
④ Meta-Optimierung des Datenwissenschaftlers
Der Agent selbst kann zudem weiter optimiert werden, um ihn besser für die Rolle eines Data Scientists geeignet zu machen. Ein Ansatz besteht darin, das Agenten-Framework mithilfe von Methoden ähnlich wie Autoresearch oder Meta-Harness zu optimieren und dasselbe innere Ziel (d. h. „bessere Daten generieren“) zur Steuerung der äußeren Optimierung zu nutzen, wodurch das gesamte Agentensystem verbessert wird.
In seiner Implementierung schlägt das Paper Agentic Self-Instruct als Instanziierungsmethode von Autodata vor, wie in der folgenden Abbildung dargestellt:
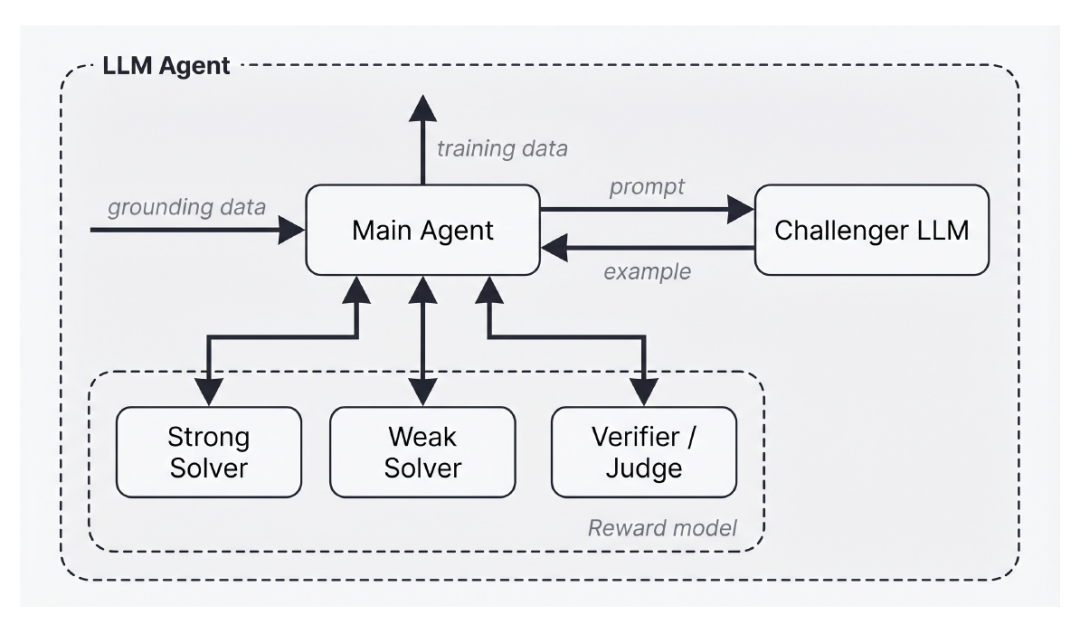
Schwach-starker Kontrast Agentische Selbstinstruktionsmethode
Der Haupt-Orchestrierungsagent dieser Methode kann auf vier Subagenten zugreifen, die auf dem Large Language Model (LLM) basieren:
* Herausforderer: Generiert Trainingsbeispiele auf der Grundlage detaillierter Anweisungen des Hauptagenten;
* Schwacher Löser: Ein Modell, das typischerweise Schwierigkeiten hat, die generierten Trainingsdaten zu lösen;
* Leistungsstarker Löser: Ein Modell, das die generierten Trainingsdaten typischerweise erfolgreich lösen kann;
* Prüfer/Beurteiler: Nach Bereitstellung von Beispielen und Modelllösungen prüft der Prüfer/Beurteiler die Qualität der Lösungen und gibt die Lernergebnisse an den Hauptagenten zurück.
Ziel dieses Systems ist es, Trainingsdaten zu generieren, die es leistungsstarken Lösern ermöglichen, Aufgaben erfolgreich zu lösen, während schwächere Löser Schwierigkeiten haben. Das Master-LLM analysiert das Feedback von Gutachtern und aktualisiert die an die Herausforderer gesendeten Hinweise entsprechend. Dieser Zyklus wird kontinuierlich wiederholt, um anspruchsvolle Beispiele für das Training der schwächeren Löser zu generieren.
Ergebnispräsentation: Im Vergleich zu herkömmlichen Methoden zur Erstellung synthetischer Daten wurden überlegene Ergebnisse erzielt.
Die Experimente der Forscher umfassten drei Aufgabenbereiche und bestätigten damit die Effektivität des Autodata-Frameworks über mehrere Dimensionen hinweg.
Aufgaben im Bereich Informatik
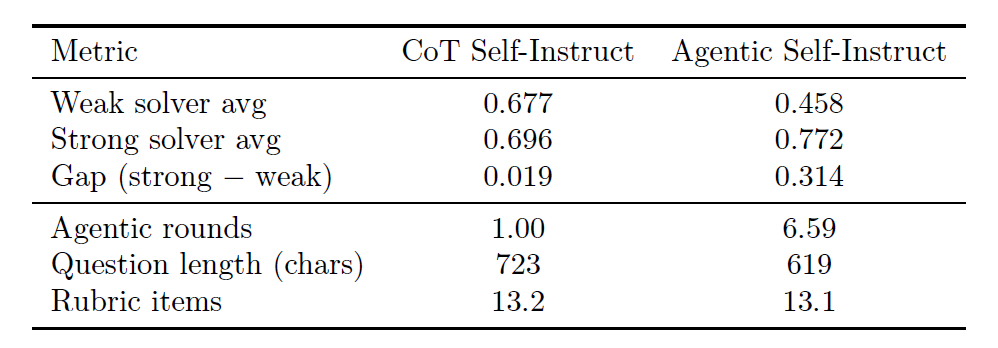
Bei Aufgaben in der Informatik reduziert die Datengenerierung durch Agentic Self-Instruct die Verwechslungsrate zwischen schwachen und starken Modellen erheblich und macht das Trainingssignal dadurch klarer.
Bei Aufgaben, die mit der Basismethode CoT Self-Instruct generiert wurden, erzielte der schwache Löser einen Durchschnittswert von 0,677. Bei Aufgaben mit demselben Ausgangsmaterial (wissenschaftlichen Artikeln), die mit Agentic Self-Instruct generiert wurden, sank der Wert des schwachen Lösers jedoch um 22 Prozentpunkte (0,677 → 0,458), während der Wert des starken Lösers um 8 Prozentpunkte stieg (0,696 → 0,772), wie in der folgenden Tabelle dargestellt.Dies deutet darauf hin, dass die endgültig akzeptierte Frage einen größeren Anreizeffekt auf die Fähigkeit zum tiefen Denken des starken Modells hat.
Beim RL-Training verbessert das Training mit CoT-Daten auf dem einfacheren CoT-Selbstlern-Testdatensatz (linke Seite der Tabelle unten) den Mittelwert bei drei Messungen (mean@3) des Basismodells 4B von 0,630 auf 0,727, während das Training mit Agentic-Daten ihn weiter auf 0,774 steigert. Auf dem schwierigeren Agentic-Testdatensatz (rechte Seite der Tabelle unten) ergeben sich folgende Ergebnisse: 0,366 (Basismodell) → 0,500 (CoT-Training) → 0,632 (Agentic-Training). Der Unterschied zwischen den beiden Methoden ist auf diesem Testdatensatz deutlich größer (mehr als doppelt so groß wie auf dem CoT-Testdatensatz), und auch die Metrik best@3 zeigt dieselbe Rangfolge.
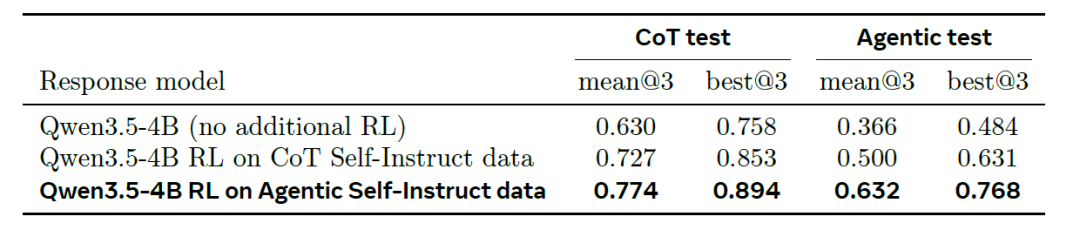
Das mit Agentic trainierte Modell zeigte eine Übertragbarkeit in beide Richtungen (+0,05 auf dem CoT-Testdatensatz und +0,13 auf dem anspruchsvolleren Agentic-Testdatensatz). Dieser signifikante Vorteil deutet darauf hin, dass die durch die Agentic-Pipeline generierten, differenzierteren Trainingsdaten zu stärkeren Inferenzfähigkeiten führen können.
Aufgabe zum juristischen Denken
Bei Aufgaben zum juristischen Denken hat die Forschung ein gegensätzliches, aber ebenso wichtiges Phänomen aufgedeckt: Die von traditionellen CoT-Modellen generierten Daten sind oft zu komplex, sodass schwache Modelle kaum effektive Gradientensignale liefern (was zu einer großen Anzahl von Nullwerten führt). Autodata führt durch einen differenzierteren Bewertungsmechanismus die Datenkomplexität wieder in den „lernbaren Bereich“ zurück und verbessert so die Stabilität und Effektivität des GRPO-Trainings signifikant.
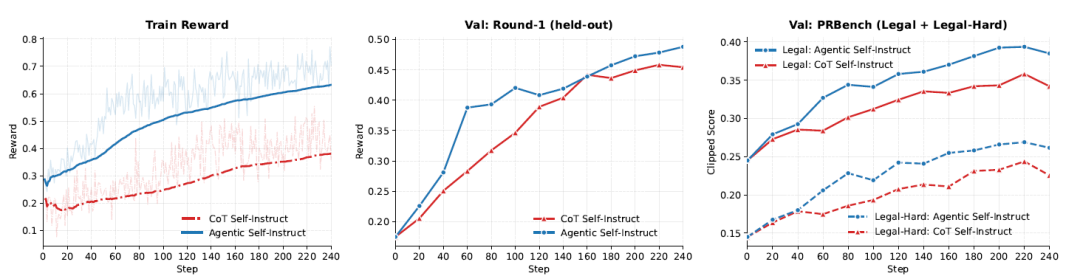
Die Forscher nutzten GRPO, um Qwen3.5-4B mit zwei Datenquellen zu trainieren: 2.800 juristischen Frage-Rubrik-Paaren (Agentic Self-Instruct und CoT Self-Instruct). Während des Trainings wurde der Datensatz alle 20 Schritte anhand zweier Evaluierungsdatensätze getestet: einem CoT-Holdout-Datensatz mit 100 Prompts und einer PRBench-Aufteilung in „Legal“ und „Legal-Hard“. Alle Belohnungen und Bewertungen wurden mit Kimi-K2.6 ausgewertet. Die Trainingskurve in der folgenden Abbildung zeigt, dass an jedem Evaluierungs-Checkpoint…Agentische Methoden führen durchweg bei Trainingsbelohnungen, CoT-Validierungssets und PRBench-Legal.
Aufgabe zum wissenschaftlichen Denken
Auch bei Aufgaben zum wissenschaftlichen Denken zeigt Agentic Self-Instruct einen durchgängigen Vorteil. Auf dem kombinierten Validierungsdatensatz (siehe Tabelle unten) erzielte das Training mit Agentic Self-Instruct-Daten die größte Gesamtverbesserung (+3,20% avg@8) und übertraf damit die direkte Verwendung von CoT Self-Instruct (+2,42%) und die kombinierten Daten (+2,70%).
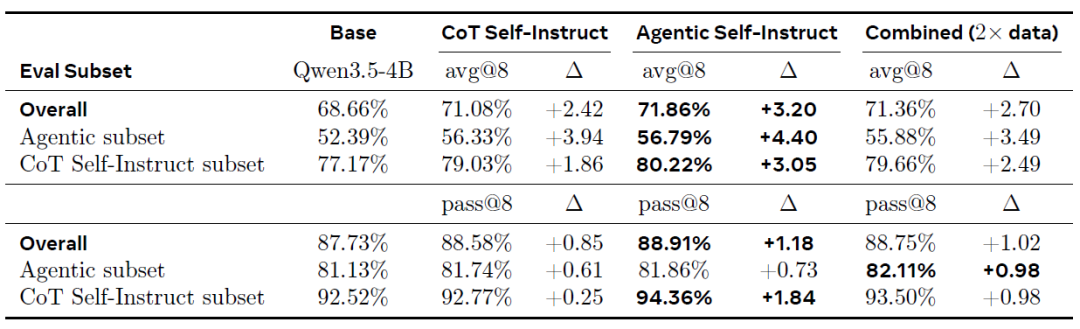
Bewertung der Ergebnisse des Reinforcement-Learning-Trainings bei Aufgaben zum wissenschaftlichen Denken
Ein zentrales Ergebnis ist, dass Agentic Self-Instruct selbst auf der nicht optimierten CoT-Validierungs-Teilmenge eine höhere Leistungsverbesserung erzielt (+3,05% gegenüber +1,86% bei CoT). Dies deutet darauf hin, dass…Das Training an schwierigeren Aufgaben kann auf einfachere Aufgaben übertragen werden: Durch die Iteration über schwierige Beispiele, die durch einen agentenbasierten Prozess generiert wurden, können verallgemeinerbare Denkfähigkeiten erlernt werden, anstatt auf eine bestimmte Schwierigkeitsverteilung beschränkt zu sein.
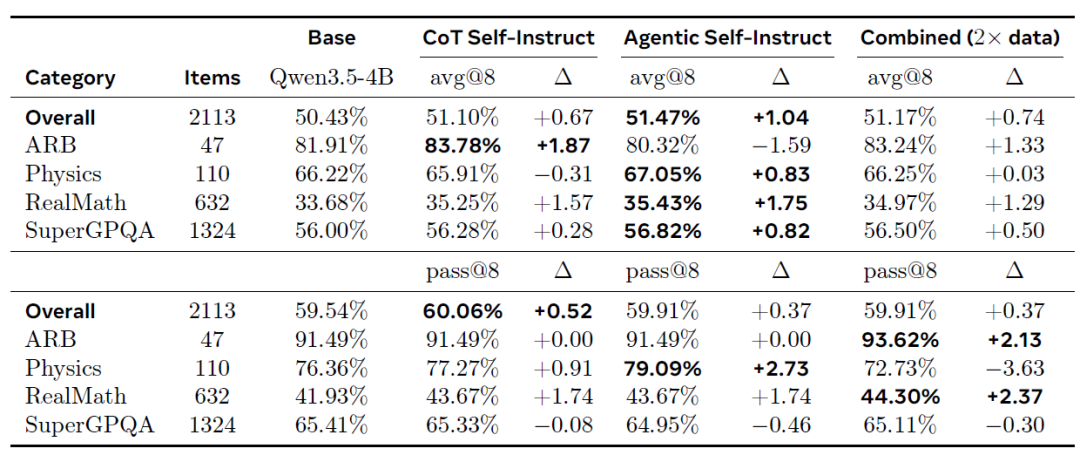
Im externen Principia-Benchmark (siehe Tabelle unten) erzielte Agentic Self-Instruct die beste durchschnittliche Verbesserung (+1,041 TP3T avg@8) und führte in mehreren Kategorien durchweg, insbesondere in RealMath (+1,751 TP3T) und SuperGPQA (+0,821 TP3T). Dieser Transfereffekt belegt zudem, dass die von Agentic Self-Instruct generierten, komplexeren Aufgaben die Leistungsfähigkeit im Bereich des robusten Denkens verbessern können.
Abschluss
Zusammenfassend schlägt Autodata ein neuartiges Datengenerierungsparadigma vor: die Modellierung des Datengenerierungsprozesses als datenwissenschaftlichen Kreislauf, der von einem intelligenten Agenten gesteuert wird. In diesem Rahmen werden Datengenerierung, -auswertung, Fehleranalyse und Richtlinienoptimierung in einem einzigen geschlossenen System vereint. Weiterführende Meta-Optimierungsexperimente zeigen, dass auch der datenwissenschaftliche Agent selbst optimiert werden kann, wodurch die Datenqualität ohne menschliches Eingreifen verbessert wird.
Zusammenfassend besteht der Kernbeitrag dieser Forschung darin, einen Mechanismus bereitzustellen, der die in der Inferenzphase eingesetzten Rechenressourcen in die Fähigkeit umwandelt, qualitativ hochwertigere Trainingsdaten zu generieren. Zukünftig bietet dieser Ansatz noch erhebliches Entwicklungspotenzial, beispielsweise durch die Anpassung umfangreicherer Aufgaben, die komplexere, mehrstufige Zusammenarbeit von Agenten und die globale Optimierung auf Datensatzebene. Darüber hinaus wird die Wiedereinführung menschlichen Feedbacks in den Optimierungsprozess zur Bildung eines kollaborativen Optimierungsmechanismus mit dem Agenten als wichtiger Ansatzpunkt für die zukünftige Entwicklung angesehen.








