Command Palette
Search for a command to run...
Der Tokenverbrauch Sank Um 30%. Eywa, Ein Heterogenes Intelligentes Agenten-Framework, Das Von "Avatar" Inspiriert Wurde, Kombiniert Auf Effiziente Weise Sprachmodelle Mit Domänenspezifischen Basismodellen.

In den letzten Jahren hat sich agentenbasierte KI zu einer der wichtigsten Entwicklungsrichtungen im Bereich der künstlichen Intelligenz entwickelt. Von automatisierter Programmierung und Wissensabfrage bis hin zur Aufgabenplanung entwickeln sich große Sprachmodelle (LLMs) schrittweise von „Chatbots“ zu intelligenten Agentensystemen mit autonomen Denk-, Handlungs- und Kollaborationsfähigkeiten. Dabei zeichnet sich jedoch ein immer deutlicher werdendes Problem ab –Fast alle gängigen intelligenten Agentensysteme sind im Wesentlichen „sprachzentrierte“ Systeme.Ob Aufgabenplanung, Werkzeugaufruf oder Zusammenarbeit zwischen intelligenten Agenten – sie alle basieren auf der einheitlichen Schnittstelle der natürlichen Sprache.
Dieses Paradigma funktioniert gut in Bereichen wie Online-Fragen und -Antworten sowie Büroautomation. Sobald KI jedoch in die wissenschaftliche Forschung Einzug hält, treten schnell Probleme auf. Denn die wissenschaftliche Welt ist nicht von Natur aus sprachlich fassbar. Zeitreihen, Kristallstrukturen von Materialien, Proteinsequenzen, Wetterdaten, Fernerkundungsdaten … diese Daten sind oft hochstrukturiert und lassen sich unter Umständen gar nicht effektiv „textualisieren“.Eine erzwungene Übersetzung in natürliche Sprache führt nicht nur zu Informationsverlusten, sondern verursacht auch bei großen Modellen einen extrem hohen Tokenverbrauch und Redundanz bei den Schlussfolgerungen.
In diesem ZusammenhangEin Forschungsteam der University of Illinois at Urbana-Champaign (UIUC) hat ein heterogenes Agenten-Framework namens Eywa vorgeschlagen, um Sprachagenten mit domänenspezifischen Basismodellen zu verbinden.Forscher haben einen neuen EywaAgent entwickelt, indem sie ein domänenspezifisches Basismodell mit einem Sprachmodell kombinierten. Dieser Ansatz ermöglicht es dem Sprachagenten, das Basismodell bei seinen Denk-, Planungs- und Entscheidungsprozessen für spezialisierte Aufgaben zu steuern.
Forscher führten eine systematische Evaluierung von Eywa in verschiedenen Bereichen durch, darunter Physik, Lebenswissenschaften und Sozialwissenschaften. Die Ergebnisse zeigten, dass Eywa im Vergleich zu Basissystemen, die ausschließlich auf Sprachmodellen basieren, das Nutzen-Kosten-Verhältnis durchgängig verbesserte. Im Vergleich zum Single-LLM-Agent-Basissystem erzielte EywaAgent bei Aufgaben in Physik, Lebenswissenschaften und Sozialwissenschaften eine durchschnittliche Nutzenverbesserung von ca. 71 TP3T, eine Token-Reduzierung von ca. 301 TP3T und eine Reduzierung der Ausführungszeit um ca. 101 TP3T. Auch in Multiagenten-Szenarien erreichte EywaMAS eine verbesserte Nutzenverbesserung bei gleichzeitig reduziertem Token-Verbrauch und kürzerer Laufzeit.
Die zugehörigen Forschungsergebnisse mit dem Titel „Heterogeneous Scientific Foundation Model Collaboration“ wurden als Preprint auf arXiv veröffentlicht.
Forschungshighlights:
* Bei Aufgaben mit strukturierten Daten und domänenspezifischen Daten kann Eywa die Systemleistung effektiv verbessern.
* Durch die effektive Zusammenarbeit mit einem dedizierten zugrunde liegenden Modell reduziert Eywa seine Abhängigkeit von sprachbasiertem Denken.
* Eywa kann auf Multiagentenszenarien erweitert werden: In EywaMAS kann EywaAgent den Sprachagenten in einem traditionellen Multiagentensystem ersetzen; in EywaOrchestra kann ein Planer den Sprachagenten und EywaAgent dynamisch koordinieren, um komplexe Aufgaben zu lösen.

Lesen Sie das Dokument:
https://hyper.ai/papers/2604.27351
EywaBench: Ein wissenschaftliches Bewertungssystem, das „multitaskingfähig, domänenübergreifend und multimodal“ ist.
Bevor das Forschungsteam den Modellrahmen vorschlug, wies es zunächst auf ein seit langem bestehendes Problem mit den aktuellen wissenschaftlichen KI-Benchmarks hin:Mit anderen Worten: Die meisten aktuellen wissenschaftlichen Benchmarks decken typischerweise entweder nur einen einzigen Aufgabentyp ab, konzentrieren sich nur auf einen einzigen Bereich oder unterstützen nur ein einziges Datenformat.Daher spiegelt es oft nicht vollständig die Fähigkeiten wider, die von wissenschaftlichen agentenbasierten Systemen tatsächlich benötigt werden.
Das Forschungsteam hebt insbesondere hervor, dass die aktuellen Benchmarks zwei zentrale Datentypen – Zeitreihen- und Tabellendaten – lange Zeit unzureichend bewertet haben. Diese beiden Datentypen bilden die Grundlage für wissenschaftliches Rechnen und industrielle Systeme in der Praxis. Daher schlägt die Arbeit einen neuen Bewertungsrahmen vor:EywaBench ist ein skalierbarer Benchmark für heterogenes, multitaskingfähiges und domänenübergreifendes wissenschaftliches Denken.
EywaBench basiert auf mehreren bestehenden Datensätzen, darunter unter anderem:
* DeepPrinciple
* MMLU-Pro
* fev-bench
* TabArena
EywaBench verfügt über Multitasking- und Multi-Domain-Abdeckungsfunktionen.Es umfasst drei zentrale Datenmodalitäten: natürliche Sprache, Zeitreihendaten und tabellarische Daten.Alle Aufgaben sind in drei wissenschaftliche Bereiche unterteilt: Der erste Bereich umfasst die physikalischen Wissenschaften, darunter Materialwissenschaften, Energiewissenschaften und Luft- und Raumfahrtwissenschaften; der zweite Bereich umfasst die Lebenswissenschaften, darunter Biologie, klinische Studien und Arzneimittelentwicklung; und der dritte Bereich umfasst die Sozialwissenschaften, die Bereiche wie Wirtschaft, Unternehmen und Infrastruktur abdecken.
Noch wichtiger ist jedoch, dass EywaBench selbst skalierbar ist und es Forschungsteams ermöglicht, den Umfang ihrer Aufgaben kontinuierlich zu erweitern, indem sie neue Zeitfenster, Variablenkombinationen und Kontextkonfigurationen hinzufügen; es kann auch auf neue Zeitreihendatensätze und tabellarische Datensätze zugreifen, um in neue wissenschaftliche Bereiche vorzudringen.
Eywa: Verbindung von Sprachagenten mit domänenspezifischen Fundamentmodellen
Eywas Hauptinspiration stammt vom „Tsaheylu“-Konzept aus dem Film Avatar. Auf Pandora können die Na'vi über neuronale Verbindungen direkte Kooperationsbeziehungen mit verschiedenen Spezies wie Drachen und Kriegspferden aufbauen und so unterschiedliche Kreaturen zu einer gemeinsamen Handlungsfähigkeit befähigen.
Das Forschungsteam ist der Ansicht, dass auch die aktuellen Agentensysteme mit ähnlichen Problemen konfrontiert sind. LLMs besitzen zwar ausgeprägte Denk- und Planungsfähigkeiten, sind aber im Umgang mit rohen wissenschaftlichen Daten nicht versiert; domänenbasierte Modelle verfügen über starke fachliche Kompetenzen, sind aber nicht in der Lage, komplexe Aufgaben zu lösen.Daher schlägt die Arbeit die FM–LLM-Schnittstelle „Tsaheylu“ vor, die im Wesentlichen einen bidirektionalen Kommunikationsmechanismus zwischen dem Sprachmodell und dem Domänenfundamentmodell etabliert, wie in der folgenden Abbildung dargestellt:
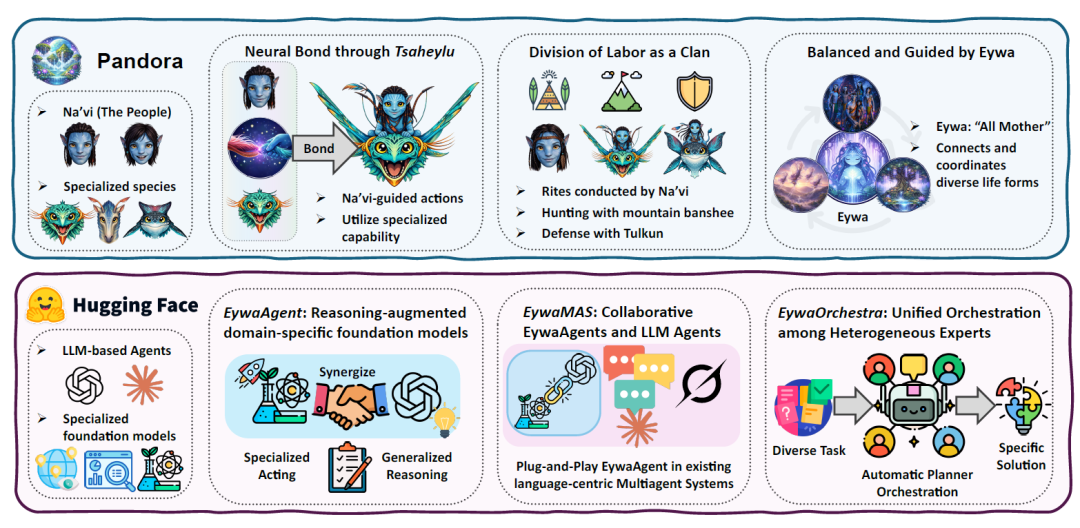
Schritt 1: EywaAgent erstellen
Der erste Schritt hin zum Eywa-Agenten-Framework besteht in der Entwicklung von EywaAgent – einem einheitlichen abstrakten Framework, das dem Basismodell eine sprachbasierte Schlussfolgerungsschnittstelle hinzufügt und es ihm ermöglicht, an übergeordneten Schlussfolgerungsprozessen innerhalb von Agentensystemen teilzunehmen.Die Kernidee besteht darin, eine starke Verbindung zwischen dem Sprachmodell für die Durchführung von übergeordneter Planung und Steuerung und dem domänenspezifischen Basismodell herzustellen, das professionelle Fähigkeiten bereitstellt.
EywaAgent kombiniert sprachbasiertes Schließen mit domänenspezifischer Berechnung über eine bidirektionale Kommunikationsschnittstelle, die als FM-LLM "Tsaheylu"-Kette bezeichnet wird.Durch diese Verknüpfung kann das Sprachmodell korrekt konfiguriert und das zugrunde liegende Modell für spezielle Berechnungen aufgerufen werden.Gleichzeitig wird das Ergebnis nahtlos wieder in den Inferenzprozess integriert.
Die Tsaheylu-Schnittstelle ist als Funktionspaar formalisiert: Der Abfragecompiler ϕk übersetzt Aufgabenzustände in strukturierte Aufrufe des Basismodells, und der Antwortadapter ψk konvertiert die Ausgabe des Basismodells in eine Repräsentation in einer kompatiblen Sprache. Diese Kommunikationspipeline ermöglicht es dem Agenten, dynamisch zu entscheiden, ob er Berechnungen intern durchführt oder an das Basismodell delegiert, und so flexibel zwischen allgemeiner Inferenz und spezialisierter Ausführung zu wechseln.
Schritt 2: Erweiterung auf das Eywa-Agentensystem
Nachdem EywaAgent als Plug-and-Play-Agentenmodul definiert wurde, erweiterte das Forschungsteam dieses Paradigma auf Multiagentenszenarien, um komplexere und heterogenere kollaborative Kooperationen zu unterstützen. Zu diesem Zweck schlägt die Arbeit zwei komplementäre Abstraktionen auf Systemebene vor:
EywaMAS
EywaAgent wurde für verteilte Multiagentenumgebungen erweitert und ermöglicht die Interaktion und Zusammenarbeit mehrerer spezialisierter Agenten. Die Kommunikations- und Zustandsaktualisierungsdynamik von EywaMAS folgt dem Standardmodell von Multiagentensystemen, in dem Agenten ihren Zustand aktualisieren und Nachrichten basierend auf empfangenen Informationen generieren. Die Interaktionen werden durch die Kommunikationstopologie gesteuert. Diese Methode unterstützt flexible Kombinationen verschiedener Sprachmodelle, Basismodelle und Agententypen.
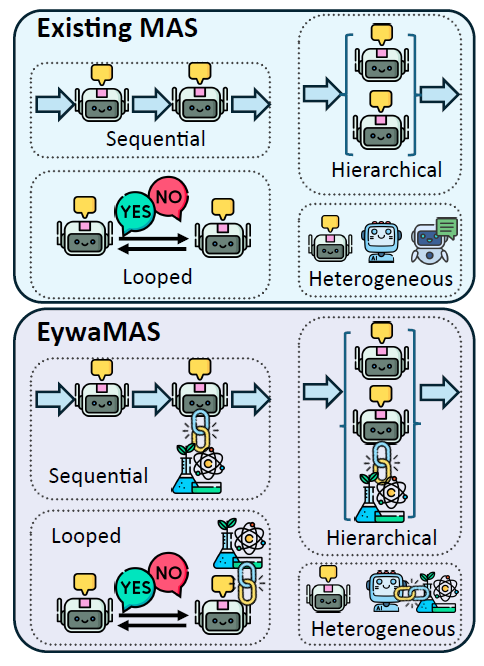
EywaMAS ist eine Erweiterung bestehender Multiagentensysteme.
EywaOrchestra
Um den vielfältigen Anforderungen realer Aufgaben hinsichtlich unterschiedlicher Agenten- und Topologiekonfigurationen gerecht zu werden, führt das Framework EywaOrchestra ein, ein dynamisches Orchestrierungssystem. EywaOrchestra fungiert als Direktor und instanziiert dynamisch heterogene Multiagentensysteme basierend auf der jeweiligen Aufgabe, indem es geeignete Sprachmodelle, Basismodelle und Kommunikationstopologien auswählt. Diese adaptive Orchestrierung ermöglicht es dem System, die Einschränkungen statischer Entwürfe zu überwinden und die Anpassungsfähigkeit von Modell und Struktur zu nutzen, um für jede Aufgabe die optimale Konfiguration zu wählen.
Eywa erzielt eine kontinuierliche Verbesserung im Hinblick auf das Verhältnis von Nutzen und Kosten.
Das Forschungsteam testete alle Methoden mithilfe von EywaBench nach einem einheitlichen Versuchsprotokoll. Die folgende Tabelle zeigt die Gesamtleistung aller Methoden bei der wissenschaftlichen Aufgabe mit EywaBench, und die Versuchsergebnisse lassen mehrere wichtige Schlussfolgerungen zu:
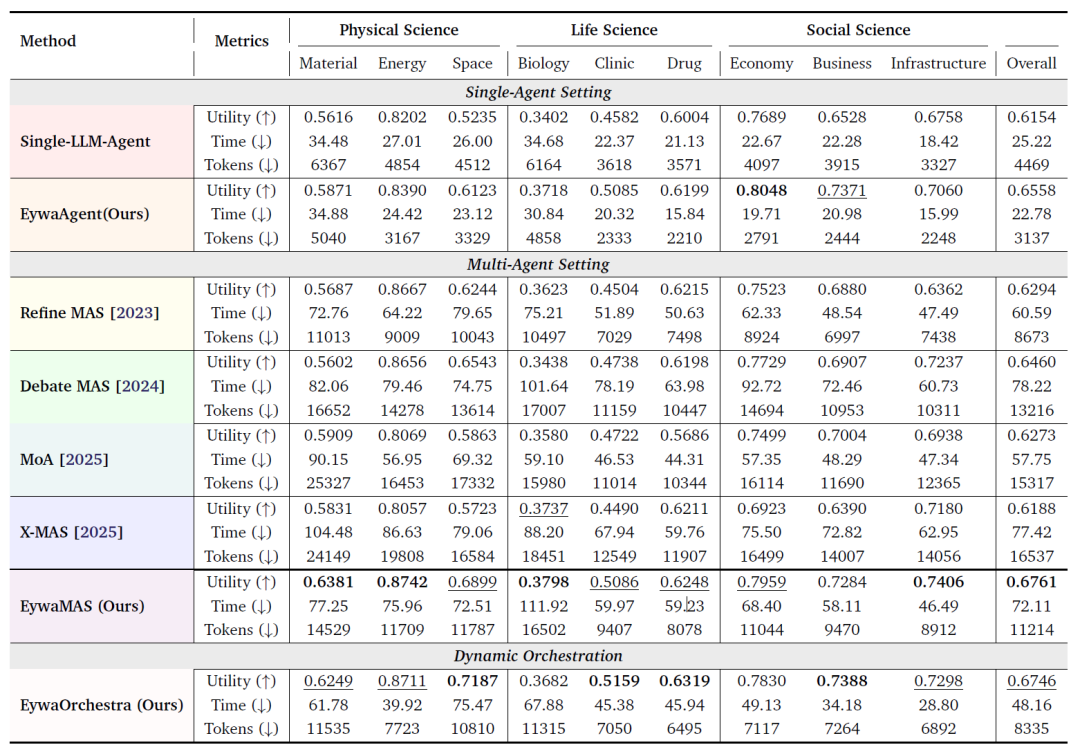
Gesamtleistungsvergleich von EywaBench bei wissenschaftlichen Missionen
Hinweis: Die Tabelle vergleicht alle Methoden anhand dreier Dimensionen: Nutzen (↑ höher, besser), Inferenzzeit (↓ niedriger, besser) und Tokenverbrauch (↓ niedriger, besser). Optimale Ergebnisse sind fett, zweitbeste unterstrichen dargestellt.
Erstens verbessert EywaAgent sowohl die Systemqualität als auch die Effizienz unter den gleichen Backbone-Bedingungen.Im Vergleich zur entsprechenden Single-Agent-LLM-Baseline verbessert EywaAgent den durchschnittlichen Nutzen um 6,61 TP3T. Gleichzeitig wird durch die signifikante Delegierung von Berechnungen an das domänenspezifische zugrunde liegende Modell die Inferenzlatenz deutlich reduziert und der Tokenverbrauch um fast 301 TP3T gesenkt.
Zweitens ist EywaMAS in wissenschaftlichen Szenarien herkömmlichen isomorphen Multiagentensystemen deutlich überlegen.Experimente zeigen, dass EywaMAS die höchste Gesamtnutzen aller Methoden erzielt. Im Vergleich zu Refine bietet EywaMAS einen deutlichen Leistungsvorteil; und im Vergleich zu Debate weist EywaMAS nicht nur einen höheren Nutzen auf, sondern benötigt bei gleicher Debattenstruktur auch weniger Token.
Die dritte wichtige Erkenntnis ist, dass es nicht ausreicht, sich ausschließlich auf „heterogene Sprachmodelle“ zu stützen, um wissenschaftliche Aufgaben zu lösen.Die in der Arbeit vorgestellten heterogenen Multiagentensysteme, die ausschließlich auf Sprachmodellen basieren (wie MoA und X-MAS), konnten die stark homogene Multiagenten-Baseline nicht durchgängig übertreffen. Dies deutet darauf hin, dass für wissenschaftliche Aufgaben nicht die Kombination mehrerer verschiedener Sprachmodelle entscheidend ist, sondern vielmehr die Einführung von modalitätsübergreifender Heterogenität. Anders ausgedrückt: Ein Finanzzeitreihenmodell oder ein biologisches Vorhersagemodell ist oft wertvoller als die Hinzunahme eines Sprachmodells.
Die Studie weist zudem darauf hin, dass nicht alle Anwendungsbereiche von komplexerer Multiagenten-Kollaboration profitieren können. In Teilbereichen wie Wirtschaft und Management ist der Einzelagent EywaAgent bereits sehr wettbewerbsfähig. Dies bedeutet, dass komplexe Multiagenten-Topologien nicht immer die optimale Wahl darstellen. Bei manchen Aufgaben kann übermäßige Kollaboration sogar zusätzlichen Aufwand verursachen.
Das Experiment zeigte auch, dass EywaOrchestra bei geringeren Kosten und einem höheren Automatisierungsgrad im Vergleich zum von Experten entwickelten EywaMAS eine nahezu perfekte Leistung erzielt. Im Gegensatz zu EywaMAS, das eine manuelle Konfiguration erfordert,Die Systemarchitektur des EywaOrchestra wird vollständig automatisch vom Dirigenten erstellt.Dennoch nähert sich der Nutzen des Systems dem manuell entworfener Systeme an und übertrifft diese in einigen Teilbereichen sogar. Gleichzeitig reduziert der dynamische Orchestrierungsmechanismus die Inferenzlatenz und den Tokenverbrauch signifikant. Dies beweist, dass die aufgabenadaptive Systemorchestrierung nicht nur den Automatisierungsgrad erhöht, sondern auch die Inferenzkosten effektiv optimiert.
Abschluss
In den letzten Jahren drehte sich das Hauptthema der KI-Branche fast immer um „große Modelle“ – größere Parameter, längerer Kontext und stärkere Schlussfolgerungsfähigkeiten. Die gesamte Branche versucht, „ein allgemeines Modell zu entwickeln, das alle Probleme lösen kann“.
Die von Eywa eingeschlagene Richtung verdeutlicht jedoch, dass „modalitätsnative Zusammenarbeit“ die Fähigkeiten von Multiagentensystemen in wissenschaftlichen Szenarien effektiv verbessern und einen neuen Entwicklungspfad für das kollaborative Schließen heterogener Basismodelle in der Zukunft eröffnen kann. Anders ausgedrückt: Entscheidend für die Zukunft wird nicht eine allmächtige KI sein, sondern ein KI-System, das heterogene Experten zur kollaborativen Zusammenarbeit befähigen kann.
Quellen:
https://arxiv.org/abs/2604.27351
https://hyper.ai/cn/papers/2604.27351








